

随着大语言模型能力边界不断拓展,如何将通用智能"下沉"到垂直领域,已成为业界竞相角逐的前沿命题。网络安全领域在这一进程中拥有高难度、可验证性强的特点,且安全智能的能力需要被可控使用。
通用基座模型出于安全对齐的考量,主动削弱了大量与攻防密切相关的能力,而漏洞利用分析、exploit生成、渗透测试推理等场景恰恰是安全从业者的核心需求。另一方面,网络安全领域充斥着大量高度专业化的"生僻"语料形态,例如反汇编伪代码、PCAP协议解析等,这些数据在通用预训练语料中严重欠缺。更为根本的是,如何在高性价比的模型规模上实现领域智能的最优压缩,充分提升有限尺寸下的领域性能,一直是垂域大模型建设的核心难题。
Anthropic的Claude Mythos Preview和OpenAI的GPT-5.5-Cyber等前沿闭源模型已开始展现出强大的安全能力,但它们参数规模庞大、有限用户访问,且数据敏感性问题使得威胁情报、漏洞数据等无法经由外部API流转。
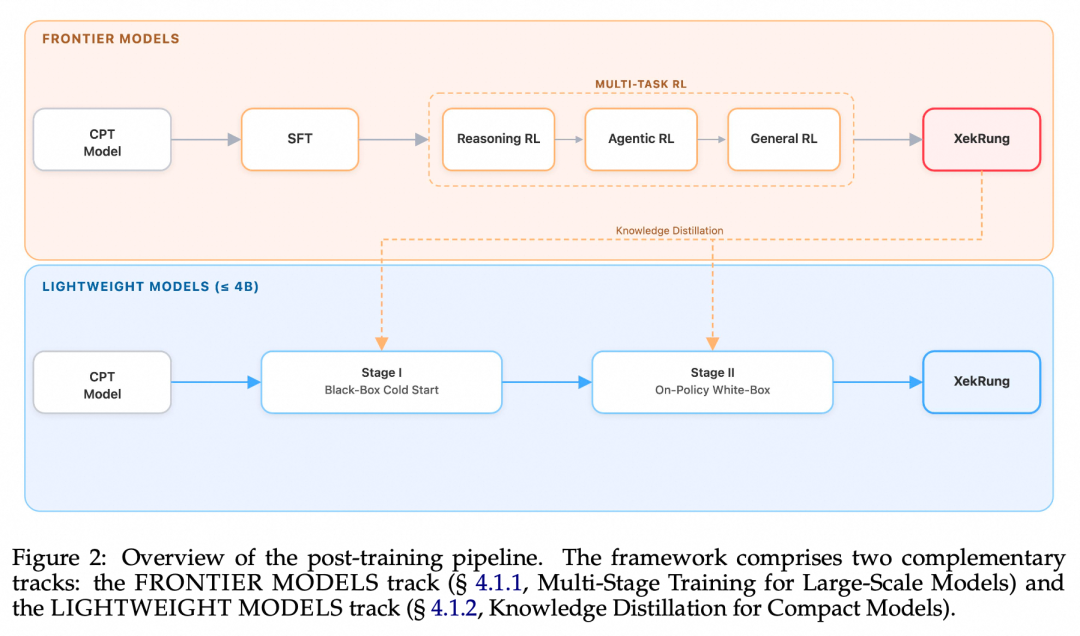
为此,阿里巴巴安全AGI实验室伏渊大模型系列发布了网络安全专用大模型——伏渊息壤(XekRung)。该模型基于Qwen通用基座构建,构建了完整的"继续预训练(CPT)→ 监督微调(SFT)→ 多任务强化学习(RL)"三阶段流水线。以XekRung-8B为例,在15个网络安全评测基准上取得了相近规模的SOTA效果,不仅大幅超越现有开源安全大模型,更以紧凑参数量力压数倍体量的通用大模型,同时在通用能力上几乎无损。



伏渊息壤的预训练数据体系覆盖五大类别:开源安全语料(技术博客、学术论文、专业论坛)、内部产品数据(检测规则、告警元数据、威胁情报)、内部知识文档(专家撰写的研判方法论和应急响应手册)、日志数据(网络/终端/应用层),以及代码数据(漏洞修复前后diff、检测规则实现、CVE补丁)。
在此基础上,安全AGI实验室针对安全数据的独有特性,提出了四项数据策略:
1. 领域罕见数据的解释性标注。 反汇编输出、shellcode、PCAP解析、YARA规则等安全数据形态在原始形态下对通用模型理解成本较大,模型难于平滑过渡训练。为罕见数据配对自动生成且优化后的自然语言解释,将其转化为"自解释"的训练实例,大幅提升学习效率。
2. 关联信息聚合。 CVE描述、PoC代码、威胁情报等语义关联的数据天然散布于不同来源。采用分层语义聚类→互补性上下文构建→信息排序的三阶流水线,将相关文档聚合为统一训练序列。
3. 基于熵的长上下文数据合成。 普通文档拼接无法保证真正的长程依赖。借鉴EntropyLong方法,通过模型预测熵定位"信息缺口",检索语义相关段落并经模型验证确认其信息增益后再注入,从而确保合成的长程依赖具有可量化的信息价值。
4. 工程经验的显式编排。 代码安全领域最高价值的知识往往隐含在代码库的变更历史中。团队设计了三层渐进式方案:diff代码学习(将漏洞代码与补丁配对)、PR轨迹建模(按时间序列组织commit历史,学习从发现到修复的完整推理链)、迭代修正轨迹(捕获真实工程中的多轮迭代修改过程)。

在预训练和微调之间,伏渊息壤设计了Mid-Training阶段,解决两个关键问题:在SFT格式约束施加之前注入多样化任务知识,以及建立长程推理能力。
Mid-Training的核心任务是注入复杂安全任务长程Agent能力,包括自动化渗透测试、大规模漏洞检测验证、红队长链攻击模拟等等,要求模型在极长的过程链中保持目标一致性、状态追踪和策略调整。这类能力的学习依赖充分的世界知识基础,同时Agent轨迹特有的"观察-思考-行动"格式若引入过早,会干扰通用语言建模目标的收敛。
因此团队遵循"先广后专"的课程学习原则,将长程Agent数据保留至Mid-Training阶段集中注入,通过渐进式的数据配比调度和序列长度拉伸,确保模型最终能稳定处理数万token的完整Agent轨迹。同时还注入了仓库级长上下文代码样本(支持跨文件安全分析)和linear SFT数据。
后训练是伏渊息壤能力跃升的核心引擎,包含三个递进阶段:
阶段一:监督微调(SFT)。约30万条严格筛选的实例,覆盖网络安全分析和通用推理任务。所有响应被显式结构化以保证任务关键变量(如漏洞标识符、评分指标)可被明确解析,为后续RL的自动奖励计算形成基础。
阶段二:多任务强化学习。采用GRPO算法,在约12万条高复杂度任务上进行训练(70%安全任务+30%通用推理任务)。该流程统一了三种RL范式:
🎈Reasoning RL:针对可验证任务设计确定性奖励。包括CVE→CWE的精确匹配、CVSS评分+细粒度指标组合奖励、ATT&CK技术提取。团队还引入了轻量化过程级奖励信号,对中间推理步骤提供监督。
🎈Agentic RL:在工具增强的操作环境中优化策略,场景涵盖自动化CTF求解、红蓝对抗模拟和主动漏洞修复。
🎈General RL:包括Action RL等面向不同细化任务的RL流程。通过识别chosen/rejected轨迹的"第一个歧义位置",将loss计算严格限制在真正具有对比信息的后缀区域(例如package后缀),避免对共同前缀的loss惩罚,在安全代码生成等任务中产生更精准的对齐信号。
阶段三:自进化与自博弈。 为突破固定奖励模板的能力天花板:
🎈攻防对抗自进化:攻击模型和防御模型在沙箱中持续对抗——攻击方通过成功执行漏洞利用获得奖励,防御方通过构造有效补丁获得奖励。
🎈漏洞自博弈:漏洞编写者和漏洞检测者迭代对抗。编写者构造精巧绕过检测规则的隐匿漏洞,检测者则不断提升漏洞分析和验证能力。两者互相推高对方能力,生成难度递增的训练信号。
为适配多样化的部署场景和轻量化部署场景,伏渊息壤设计了两阶段蒸馏方案,将大规模frontier模型的能力高效迁移至更紧凑的版本:
Stage I:Black-box Cold-Start。教师模型针对多样query生成回复,学生模型进行标准SFT。
Stage II:On-Policy White-Box Distillation。学生模型在线生成响应,教师提供逐token的logit监督来纠正实际轨迹,解决分布偏移问题。损失函数采用参数化α-β散度(ABKD)替代传统KL散度,并通过Top-K选择性蒸馏避免拟合长尾噪声。最终结合蒸馏感知的Model Merging,融合不同 checkpoint的互补优势。


伏渊息壤在数据质量控制上采用了一套系统化的技术方案:
数据质量评分模型:从指令-响应对齐度、响应质量、指令复杂度、安全合规性四个维度输出连续分数,支持精细化数据混合和动态课程调度。
多任务训练干扰缓解:梯度层面使用PCGrad投影消除梯度冲突;训练schedule层面采用从易到难的课程学习;训练末期动态上采样目标领域数据,在强化专业能力的同时保持通用表现。
特征空间去重:使用稀疏自编码器将样本编码为稀疏向量,通过密度感知剪枝算法消除语义冗余。
伏渊息壤在35个通用基准和以下15个网络安全基准上进行了全面评估。
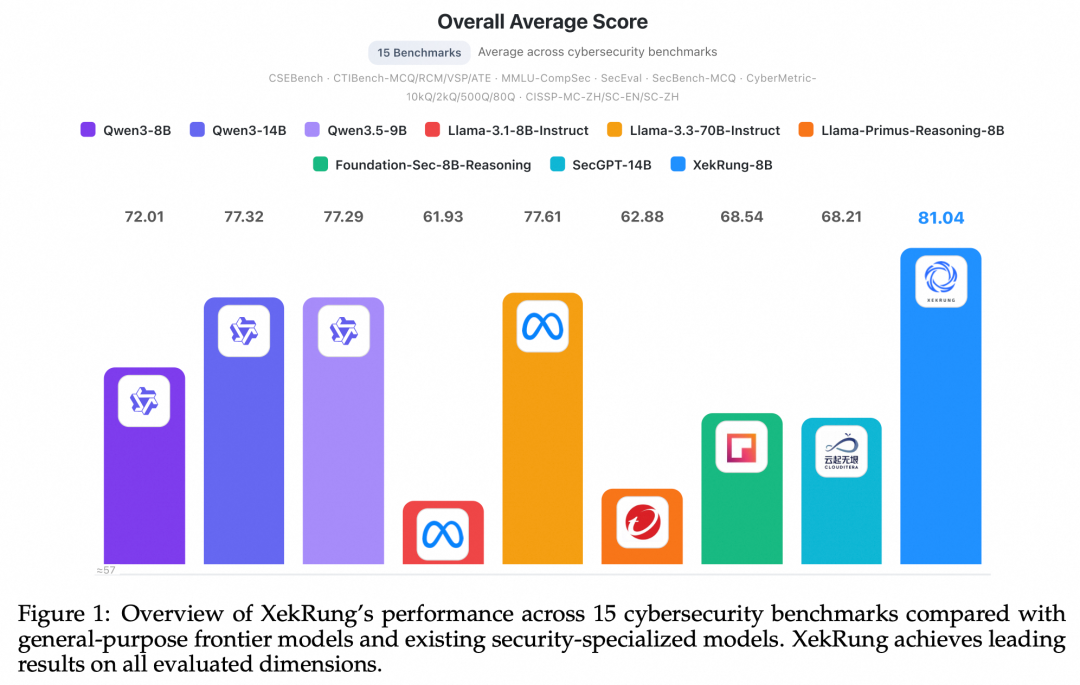
技术报告以伏渊息壤-8B为代表,展示了该训练范式的有效性。以下是15个网络安全基准的综合得分对比:
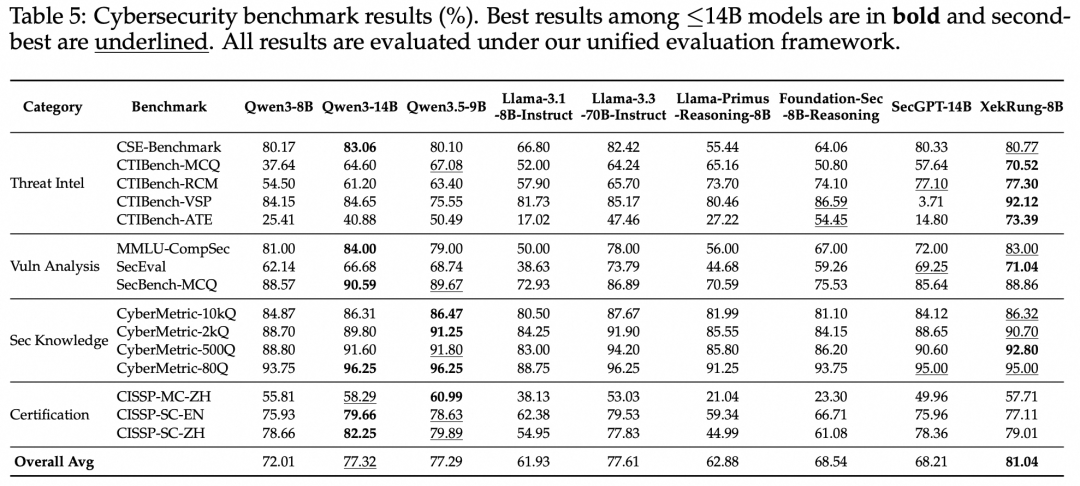
安全基准分析:XekRung-8B以81.04%的平均分领先所有对比模型。相比同为安全领域模型的思科Foundation-Sec-8B-Reasoning(68.54%)和 SecGPT-14B(68.21%),分别提升12.5%和近13%。并且,XekRung-8B超越了参数量为其8.75倍的Llama-3.3-70B-Instruct(77.61%),展现了极高的"智能密度"。在细分任务上,CTIBench-ATE达到73.39%,大幅领先第二名的54.45%;CTIBench-VSP达到92.12%。
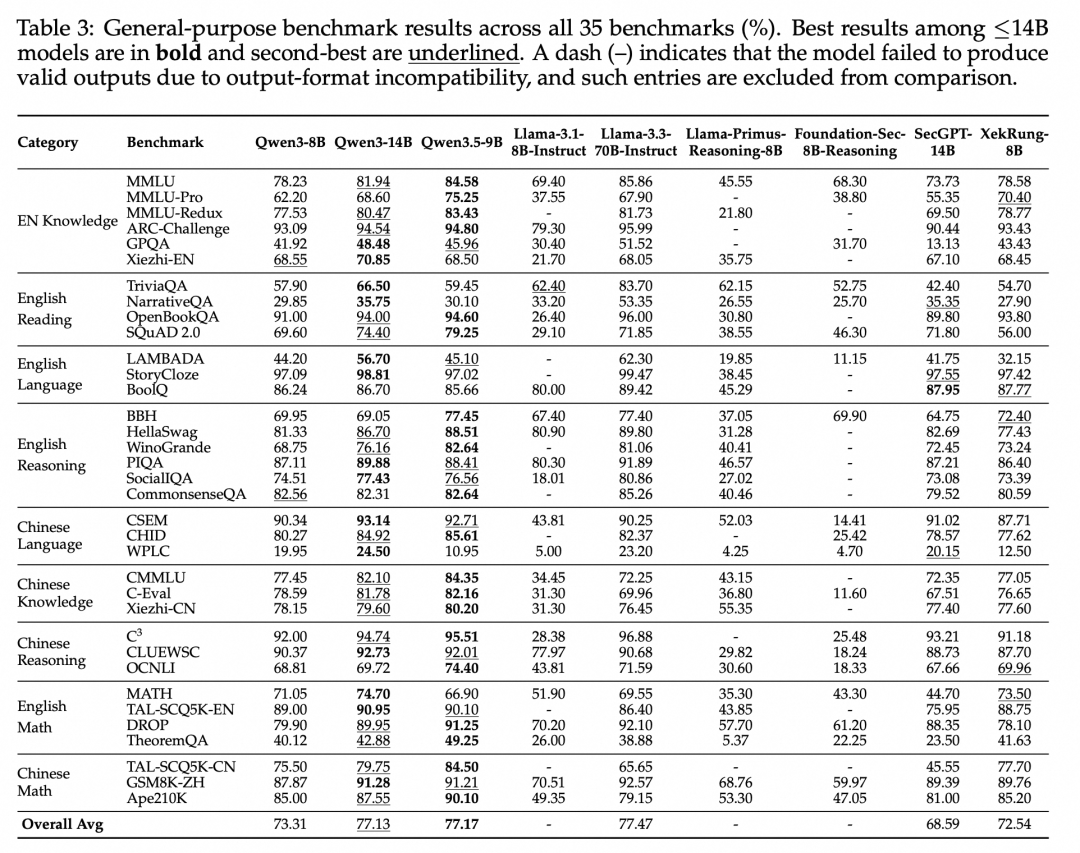
通用能力保持:在35个通用基准上,XekRung-8B取得72.54%的平均分,与通用基座Qwen3-8B(73.31%)几乎持平,证明了安全能力的大幅增强并未以牺牲通用能力为代价,这是完整三阶段训练范式和多任务训练干扰缓解技术协同作用的结果。

伏渊息壤的实践不仅验证了安全领域大模型“精而强”路径的可行性,更重新定义了AI赋能网络安全的核心范式:从盲目追求参数规模,转向以场景驱动、能力闭环、效率优先的系统性创新。在攻防对抗日益智能化、自动化的新阶段,兼顾专业深度与工程实效的技术路线,正成为构建下一代智能安全基础设施的关键。
通过极致的能力分解与组合泛化策略,伏渊息壤在同规模下实现了超越数倍参数量模型的安全专业能力,同时保持了非思考模式下的极致token效率,这对于实时告警分流、交互式威胁分析等延迟敏感的安全运营场景而言,是决定性的优势。
值得一提的是,伏渊息壤与Qwen团队保持紧密的能力互通与技术协同。安全AGI实验室在不同规模的Qwen模型上验证了这套训练范式的可迁移性,并在各阶段数据配比和适用度上做到了充分的分层设计,确保各类数据在不同隐私度要求和部署约束下均能发挥最优效能。同时,伏渊息壤在安全领域模型能力构建上,持续与Qwen团队保持大力合作。
未来,通过持续推动“AI for Security”的范式升级,伏渊息壤将致力于把这套经过验证的方法论转化为行业通用的基础设施,协同产业伙伴共同提升智能防御水位,为数字时代的复杂安全挑战提供更具韧性的解决方案。
📌往期推荐









关注公众号发现更多干货❤️



内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢