



请索引第97篇论文
 |  |
跨界破局!港科大等推出MOFMeld:当晶体结构“读懂”文献,AI如何重塑碳捕捉材料发现?
在人工智能赋能科学发现(AI for Science, AI4S)的浪潮中,多模态融合正成为打破单一数据壁垒的杀手锏。
近期,香港科技大学(广州)等机构的研究团队在《npj Artificial Intelligence》上发表了一项极具启发性的工作——MOFMeld。这项研究聚焦于全球瞩目的碳捕捉(Carbon Capture)领域,提出了一种巧妙的结构-语言融合框架,成功将“冷冰冰”的晶体拓扑结构与“浩如烟海”的文献语义知识结合在一起。
对于广大奋战在 AI+材料学、AI+分子设计等领域的本硕博学子和老师们来说,MOFMeld 不仅是一项新的 SOTA(最优结果),其背后的跨模态对齐思路和知识增强机制,更是一套可以直接复用的“交叉学科研究心法”。
今天,「图科学实验室」就带大家剥丝抽茧,深度解读这篇硬核论文!
01 为什么我们需要“多模态”的 MOF 筛选模型?
金属有机框架(MOF)被誉为“未来的多孔材料”,在碳捕捉方面极具潜力。然而,MOF 的筛选与设计却面临一个典型的“数据孤岛”困境:
结构派(GNNs)的局限:图神经网络擅长捕捉原子间的拓扑关系,能通过 CIF 文件精准计算孔隙率等几何特征。但它缺乏对化学文献中“暗数据”(如合成条件、水解稳定性、官能团改性经验)的理解。
语言派(LLMs)的局限:大语言模型虽然通过海量文献预训练掌握了丰富的化学知识,甚至能回答合成步骤,但它们对晶体结构的空间拓扑、配位环境等几何特征天生“视而不见”。
破局之道呼之欲出:能不能让 GNN 的“结构感知力”与 LLM 的“文献理解力”强强联合?
这正是 MOFMeld 的核心出发点。研究团队巧妙地引入了一个轻量级跨模态模块,将物理感知的结构嵌入对齐到了语言模型的特征空间中。
02 MOFMeld 是如何工作的?
MOFMeld 的整体架构非常优雅,主要由两个核心组件构成:领域专家级大语言模型(MOFLLaMA) 和 结构-文本跨模态桥接器(MOF-Bridge)。
1. MOFLLaMA:拒绝“幻觉”,做扎根文献的领域专家
通用的 LLM(如 ChatGPT)在回答专业化学问题时,容易出现“一本正经的胡说八道”(幻觉)。为了让模型真正懂行,研究团队对 LLaMA-3.1-8B-Instruct 进行了监督微调(SFT):
高质量指令集:从 1500 余篇 MOF 文献中蒸馏出约 20000 个 QA 对。
知识图谱加持(KG-RAG):构建了包含 3 万余个三元组的 MOF 知识图谱(MOFLLaMA-KG),在推理时进行检索增强,确保回答有据可查。
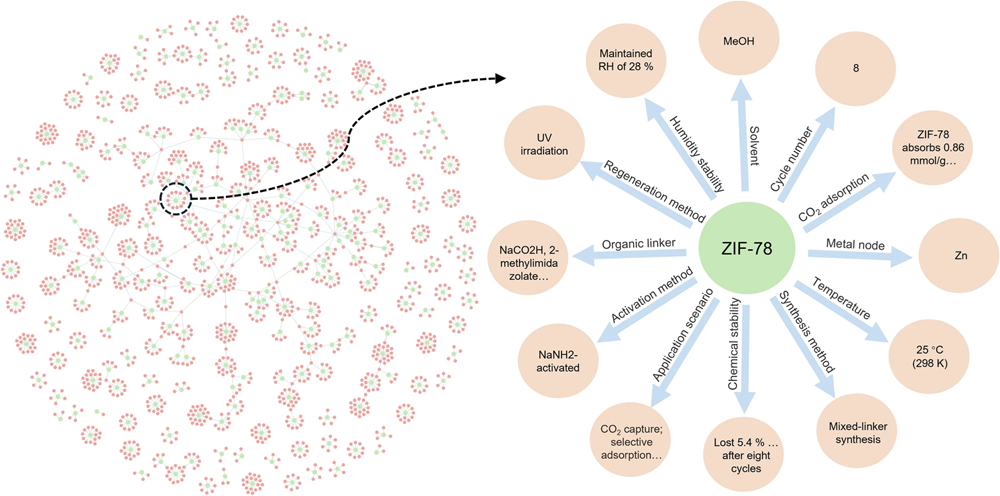
图 1:MOFLLaMA-KG 知识图谱示意图。通过将非结构化的文献转化为结构化的三元组,模型实现了可溯源的事实推理。
2. MOF-Bridge:让文本模型“看懂”晶体结构
这是本文最精妙的交叉学科创新点。为了将 GNN 提取的晶体结构特征输入给冻结参数的 LLM,作者借鉴了多模态大模型中的 Querying Transformer 思想:
从 CIF 文件中提取晶体图,利用预训练的物理感知 GNN(CHGNet)生成固定维度的结构嵌入。
通过一个轻量级的 MOF-Bridge 模块,将这些连续的结构嵌入转换为少量的
结构查询 Token。将这些 Token 拼接到文本词的 Embedding 序列中,从而使得冻结的 MOFLLaMA 能够在生成时能够“关注”到结构特征。
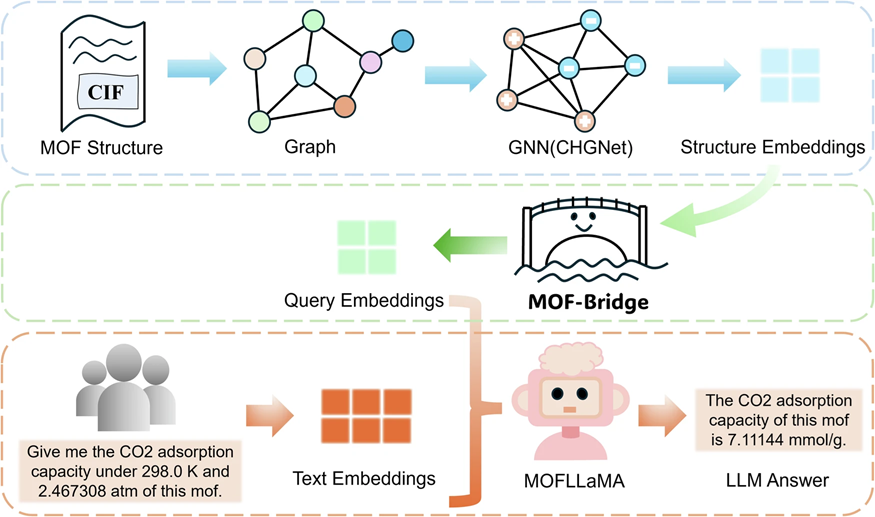
图 3:MOFMeld 框架总览。通过 MOF-Bridge 将 CIF 结构特征转化为 Token,与文本 Embedding 拼接,实现结构条件下的属性预测与问答。
03 凭什么说它 SOTA?
MOFMeld 的表现可以说是“降维打击”,我们来重点看几个关键实验及其背后的学术启示。
启示一:领域微调 + RAG,小模型也能战胜 GPT-4o
在构建的 MOF-MCQ(多选题)和 MOF-QA(自由问答)基准上,仅有 80 亿参数的 MOFLLaMA 击败了参数量庞大的 GPT-4o 以及未经微调的 LLaMA 底座。
表 1:不同模型在 MOF-MCQ 基准上的准确率对比 (%)
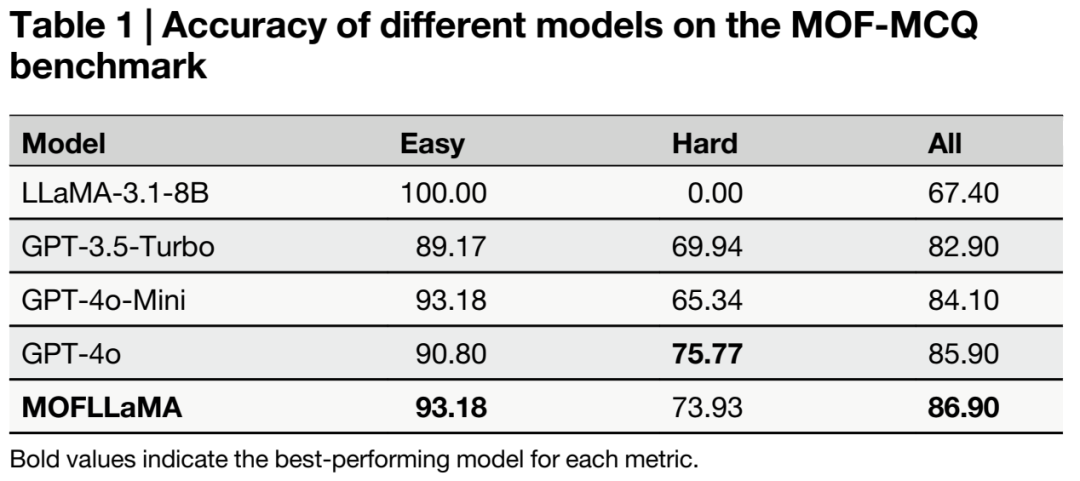
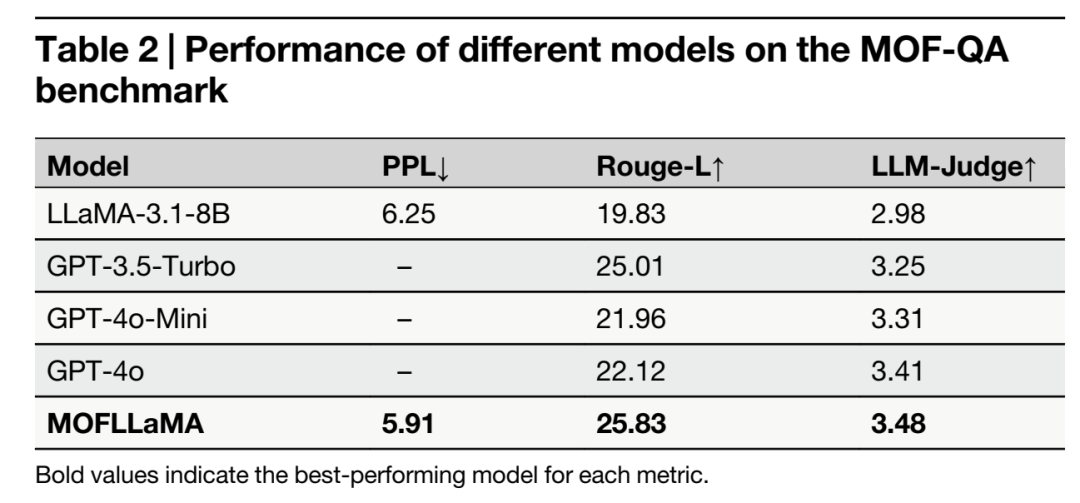
表 2:不同模型在 MOF-QA 基准上的性能对比
不仅如此,在具体的 Case Study(以著名材料 HKUST-1 为例)中,MOFLLaMA 能够提供带有文献出处、包含具体电化学窗口和复合材料变体的专业级回答,而通用 ChatGPT 只能给出泛泛而谈的维基百科式介绍。

图 2:MOFLLaMA 与 ChatGPT 对同一问题回答的对比。MOFLLaMA 展现了极强的领域专业度与溯源能力。
Lab 洞察:这再次印证了在垂直交叉领域,“通用大模型 + 精准微操(SFT+RAG)”远比盲目追求更大参数量更有效。对于初入交叉领域的课题组,这是一种极高性价比的 AI 落地范式。
启示二:跨模态融合,实现“1+1 > 2”的属性预测
在 hMOF 测试集上,作者预测了 6 种关键属性(包括 PLD、LCD、比表面积、孔隙率和不同压力下的 CO2 吸附量)。在仅使用了 30,000 个结构(不到完整数据集的三分之一)进行训练的情况下,MOFMeld 竟然达到了与使用全量数据训练的强基线 GNN(如 ALIGNN)相当甚至更优的性能!
表 3:MOFMeld 与基线模型在 hMOF 测试集上的预测性能对比
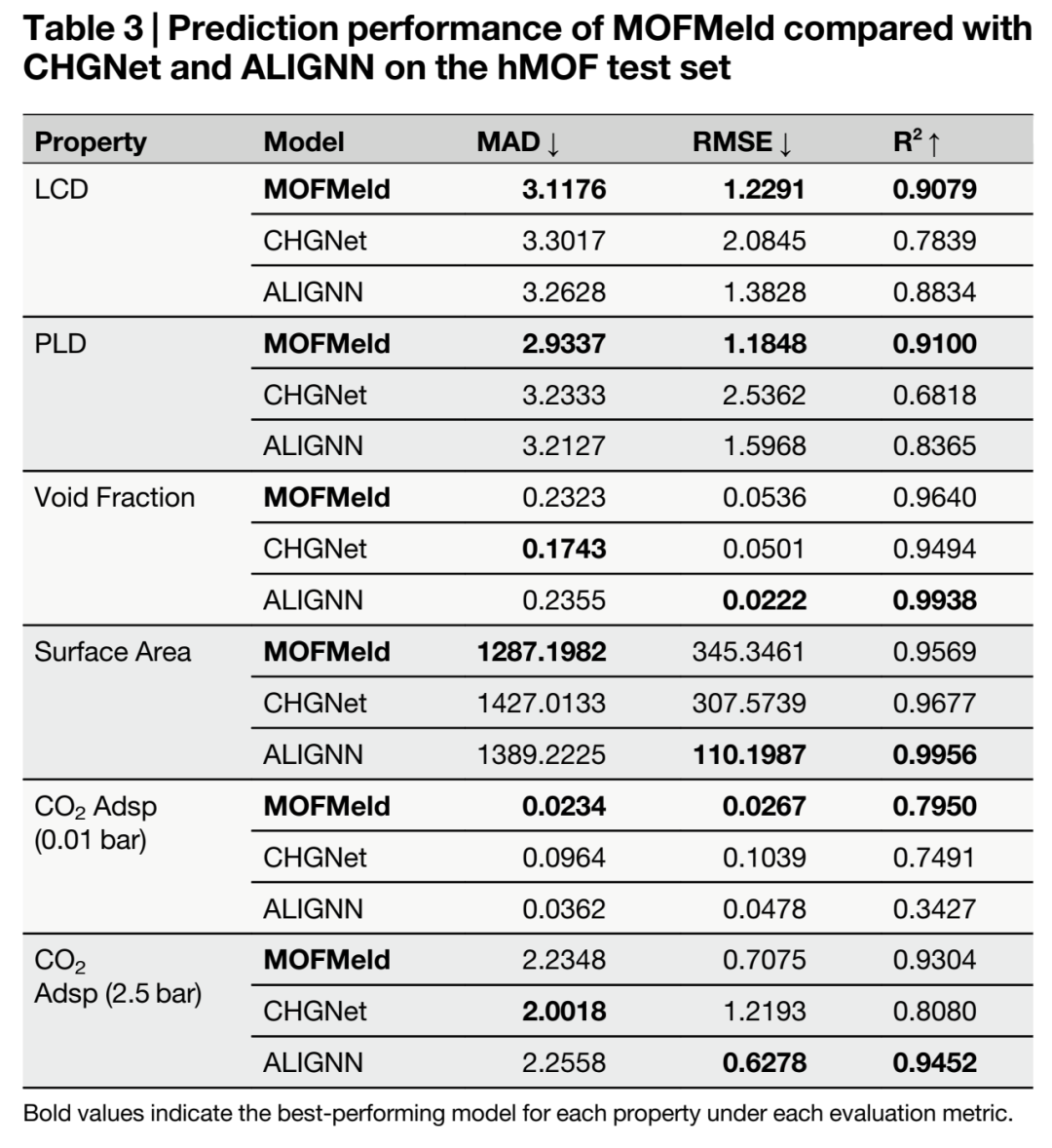
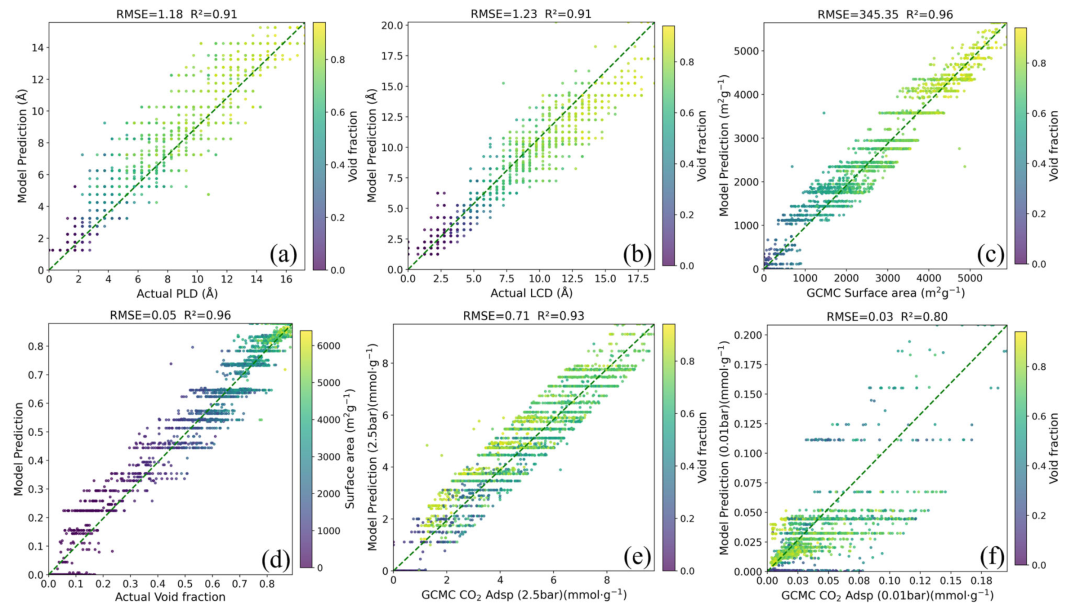
图 4:MOFMeld 在六个目标属性上的预测值与真实值对比(奇偶图)。模型在几何描述符和低/高压 CO2 吸附量上均展现出极高的拟合优度()。
Lab 洞察:为什么加入文本信息后,对纯几何属性(如孔径)的预测也提升了?这说明文献中蕴含的“化学直觉”(比如特定官能团对孔径的拉伸作用)弥补了纯结构 GNN 在有限数据下的过拟合风险。在训练数据稀缺的交叉学科场景,引入文本模态是一种极佳的正则化手段。
04 模型真的学到了化学规律吗?
一个优秀的 AI 交叉学科模型,绝不能是黑盒。MOFMeld 在可解释性方面同样给出了漂亮的答卷。
1. 真实的材料筛选能力验证
作者将 MOFMeld 应用于真实的实验性 MOF 数据库(CoRE-MOF 2024),筛选出预测的 top 50 候选材料并进行严格的巨正则蒙特卡洛(GCMC)模拟验证。结果显示,其中 36 个材料的 CO2 吸附量超过了 8 mmol/g 的实用阈值。
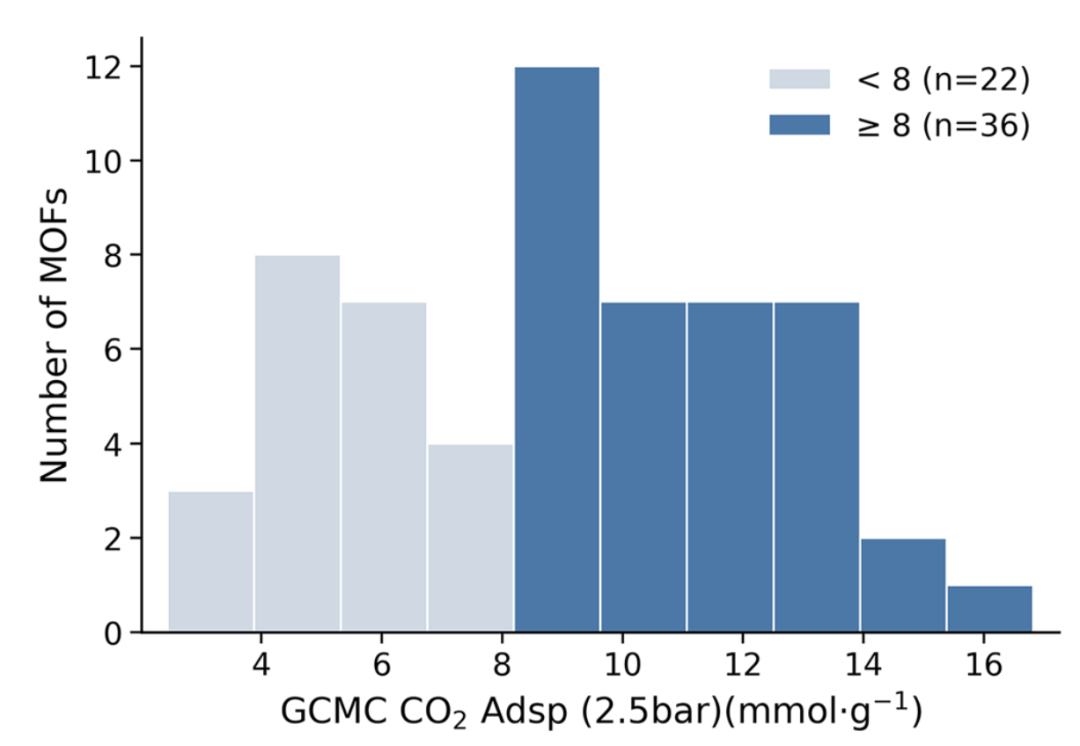
图 5:对 MOFMeld 筛选出的高潜力材料进行 GCMC 模拟验证的 CO2 吸附量分布。模型成功富集了高性能材料。
2. 潜空间揭示了清晰的“结构-属性”流形
通过对 MOF-Bridge 提取的 1000 个测试结构嵌入进行 UMAP 降维可视化,研究人员发现,这些高维向量在二维平面上自然地聚成了三类,且颜色(代表孔隙率)呈现出极其平滑的梯度变化。
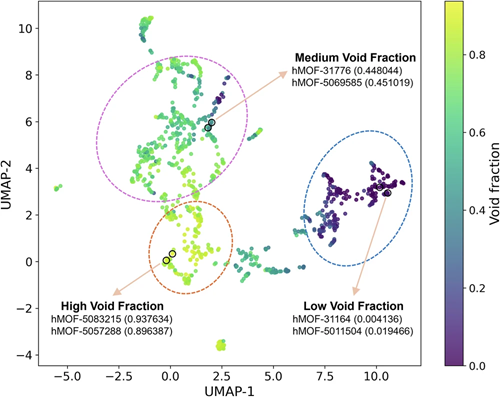
图 6:MOF-Bridge 结构嵌入的 UMAP 可视化。相似的孔隙率聚集在一起,证明了模型潜空间对物理属性的高度敏感性。
Lab 洞察:这不仅证明了 MOF-Bridge 成功保留了晶体几何特征,更向我们展示了多模态大模型内部潜空间的物理意义。这为后续基于梯度的材料逆向设计(Inverse Design)奠定了坚实基础。
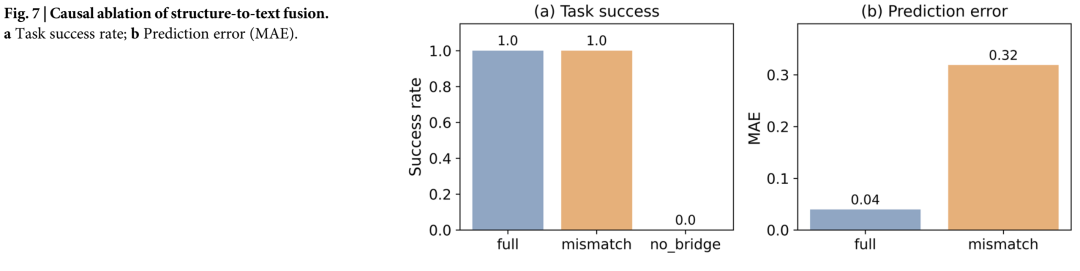
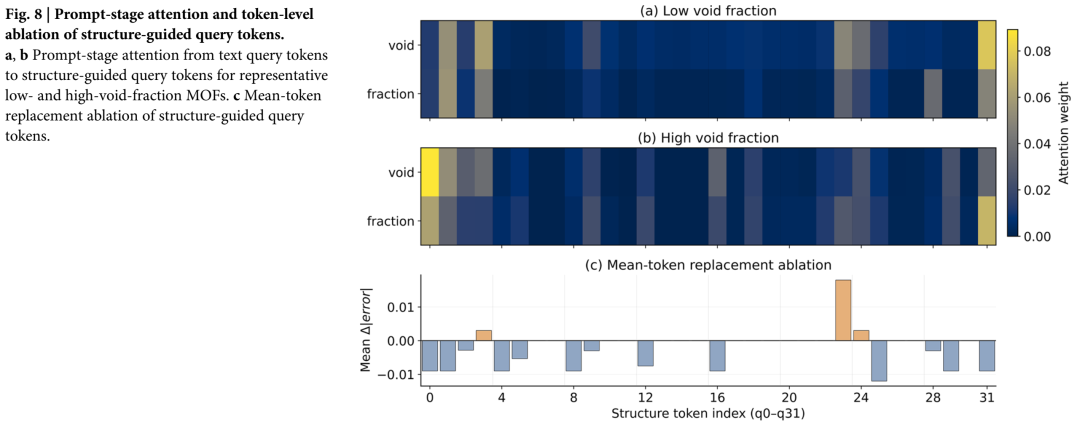
05 三点启示
MOFMeld 的成功,绝不仅仅是为多模态 MOF 属性预测提供了一个新工具,它更像是一个方法论的灯塔,为我们指明了 AI 赋能科学发现的三个重要方向:
打破数据壁垒需要“双管齐下”:在面对复杂的科学问题时,单一的 AI 架构往往具有局限性。像 BLIP-2 一样,用一个轻量级的 Bridge 连接强大的预训练专家模型(GNN + LLM),是实现高效多模态融合的黄金法则。
垂直领域的“小数据”大有可为:通过注入高质量的领域文献(Text),可以极大提升模型在数据稀缺(Small Data)情况下的泛化能力。这对于那些获取成本高昂的实验科学来说,无异于雪中送炭。
可信 AI 始于可追溯的知识:通过构建领域知识图谱(KG)并与生成模型结合,可以有效遏制 AI 在科学领域的“幻觉”,让模型的每一步推理都有据可查。
交叉学科的魅力就在于此——当图神经网络的严谨遇上大语言模型的广博,科学的边界便再一次被拓宽。
互动话题
各位同仁,你们在研究中是否也尝试过将 GNN 与 LLM 结合?遇到了哪些挑战(如模态对齐困难、计算资源不足等)?欢迎在评论区留言讨论!
喜欢今天的硬核解读吗?别忘了点赞、在看并分享给更多的朋友,我们下期再见!



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢