
Hy-MT2 是支持 33 种语言互译的多语言模型,其中7B 和 30B-A3B模型在各类翻译任务上达到了开源模型最佳效果,超越了几十倍参数量的模型。轻量级的 1.8B 模型也超越了微软和豆包等主流商业 API,且得益于 AngelSlim 1.25-bit 极端量化,仅需 440MB 存储空间,可以轻松部署在苹果、高通、联发科等手机芯片上支持本地推理,相比Hy-MT1.5推理速度提升 1.5 倍。基于Hy-MT2模型的“腾讯Hy翻译”小程序已经上线,IOS和安卓APP即将上线(支持本地推理)。
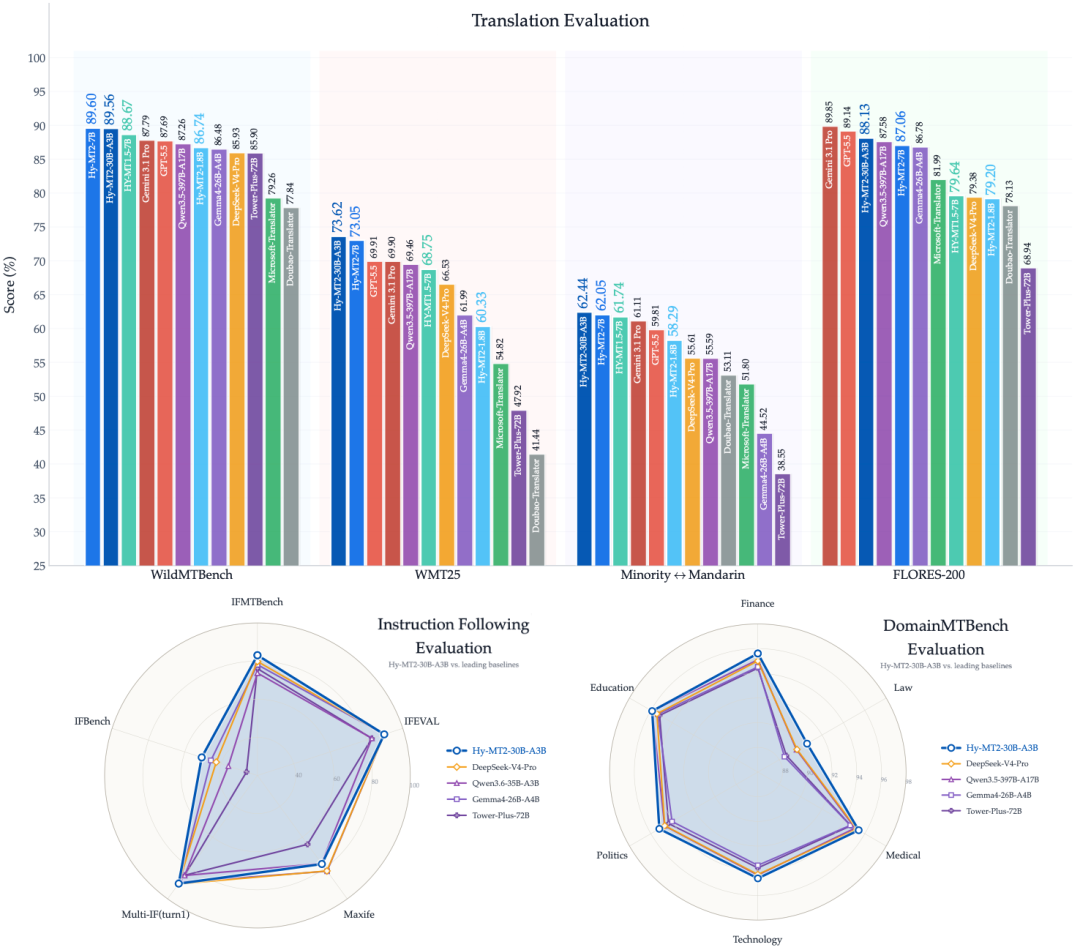
图 1:HY-MT2 模型与前沿基线模型的性能对比。
从 Hy-MT1.5 到 Hy-MT2
Hy-MT1.5[1] 发布后,在开源社区和实际业务使用中受到广泛关注。随着模型被应用到更多真实翻译场景中,社区和业务反馈也暴露出其在专业领域翻译、真实业务场景翻译、翻译指令遵循以及端侧高效部署等方面仍有提升空间。与此同时,Hy3-preview 所取得的显著提升启发我们将其作为强教师模型,从而提升 Hy 翻译模型的性能。为进一步解决这些问题,我们提出了 Hy-MT2 系列模型。
首先,Hy-MT1.5 在专业领域和真实业务场景中的翻译能力仍有提升空间。金融、法律、医疗等专业领域包含大量术语和行业固定译法,对译文准确性和一致性提出了更高要求;网页、会议、社交等真实业务场景则具有更加多样的文本形态和使用需求。针对这些问题,Hy-MT2 重点加强了专业领域和真实应用场景下的翻译能力,以更好适应不同领域、来源和文本形态的翻译需求。
其次,在实际使用中,用户往往会提出额外约束,例如保持特定词语不翻译、控制译文风格,或按照指定模板输出结果。Hy-MT1.5 在这类场景中容易出现忽略约束或不符合指定要求等问题。为此,Hy-MT2 重点加强了多语言翻译指令的理解与执行能力,使模型能够更稳定地遵循用户在风格、格式等方面的具体要求。
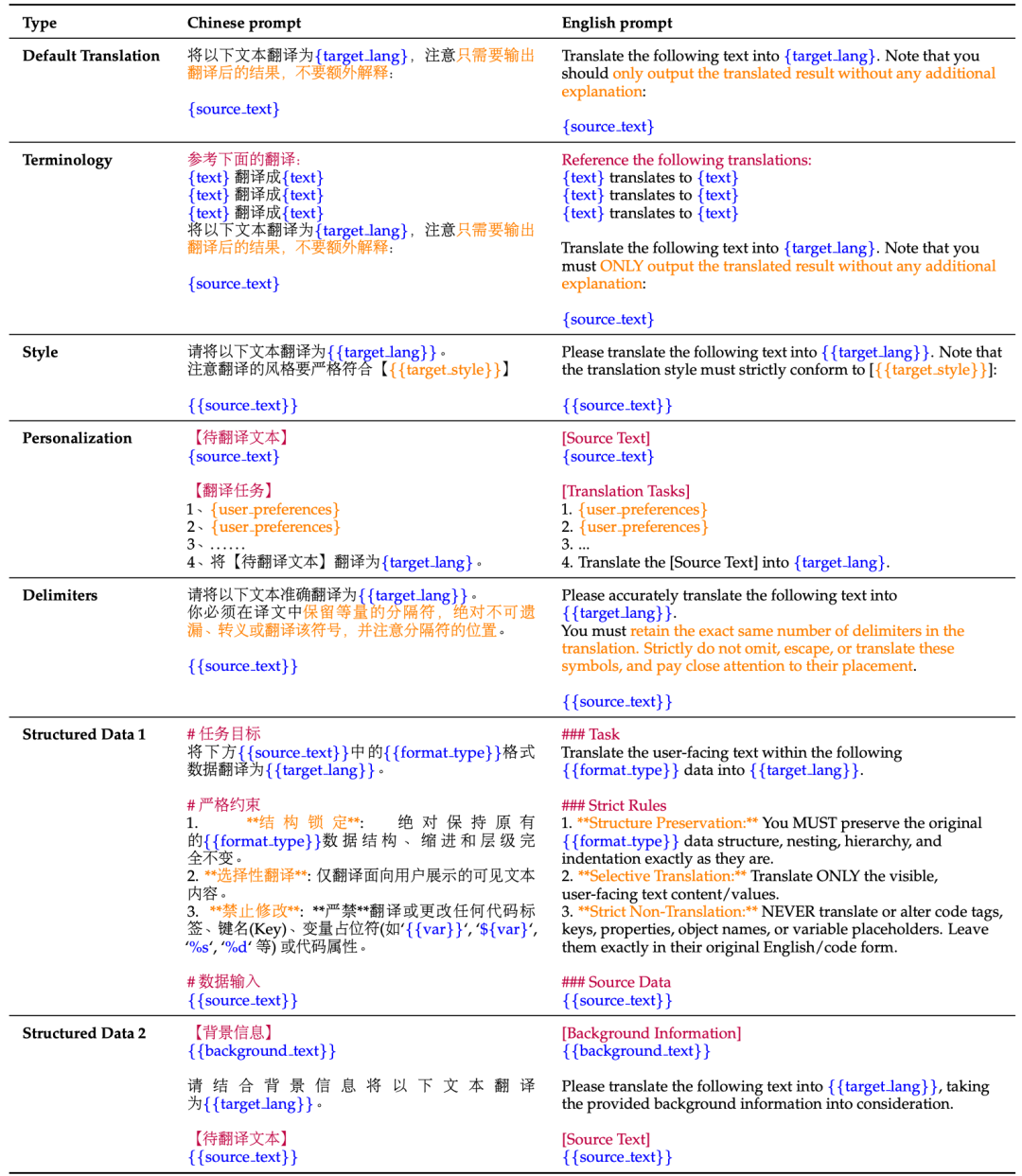
图 2:Hy-MT2 在中英文翻译任务中的指令示例。
此外,社区反馈指出,Hy-MT1.5-7B 在翻译质量上与 Gemini 3.1 Pro[2]、GPT-5.5[3] 等最强闭源模型仍存在明显差距。已有研究和模型实践表明,扩大模型规模通常有助于提升复杂翻译场景下的理解、表达和指令遵循能力。然而,现有代表性大尺寸翻译模型,如 TransGemma-27B 等,多采用稠密架构,具有较高推理成本,不利于实际服务部署。因此,Hy-MT2 引入混合专家架构,推出 Hy-MT2-30B-A3B,以在翻译效果和推理效率之间取得更好平衡。
最后,实际业务部署也暴露出 Hy-MT1.5 在端侧效率上的不足。Hy-MT1.5-1.8B 的 4-bit 量化版本仍需要 1GB 以上的存储空间,推理速度也难以充分满足部分低延迟翻译场景的需求。为此,Hy-MT2 进一步探索极低比特量化方案,并基于混元自研的 AngelSlim 技术实现了 1.25-bit 极致量化。该版本仅需约 440MB 存储空间即可部署,并且在苹果 A15 上的推理速度相比 Hy-MT1.5 的 4-bit 量化版本提升了 1.5 倍,显著降低了端侧部署成本并提升了推理效率。
总体而言,Hy-MT2 针对 Hy-MT1.5 在专业领域翻译、真实场景翻译、翻译指令遵循、与最强闭源模型的性能差距以及端侧高效部署等方面的不足,进行了系统改进,构建了一个更适合真实应用场景的高质量、高效率、多能力的多语翻译模型族。
Hy-MT2 训练框架
本节主要介绍 Hy-MT2 的整体方法论。Hy-MT2 专为多语言机器翻译而设计,遵循阶段式的流水线架构,包含MT-oriented Mid-training 和 Family-Centric Post-training (FCPT) 以及模型量化。具体而言,我们从通用的 Hy 系列预训练模型出发,进行面向机器翻译的Mid-training,以获得具备基础翻译能力的统一模型。随后,通过 FCPT 对该模型进行进一步优化。如图所示,FCPT 包含三个核心流程:Reference-Guided On Policy Distillation (RG-OPD)、Family-specific RL Training 以及 Cross-family On Policy Distillation,(Cross-family OPD)。前两个流程围绕语系组织训练,并构建了多个特定语系的强导师模型;随后,Cross-family OPD 将这些模型的能力迁移到统一的学生模型中,并融入通用的指令遵循数据,以保留模型在翻译之外的通用指令遵循能力。
面向机器翻译的中期训练
在面向机器翻译的中期训练阶段,我们从 Hy 系列预训练模型出发,使用约 1T tokens 的大规模多语言翻译相关数据对其进行持续训练。该阶段旨在强化模型的翻译能力,并为随后的“以语系为核心的后期训练”提供统一的基础。
具体而言,训练数据从两个维度进行组织:
数据格式:我们同时使用多语言单语语料库和双语平行翻译语料库,以帮助模型捕捉不同语言之间的语言特性,并加强跨语言的语义映射与源语-目标语对齐。
场景覆盖:数据涵盖了通用翻译、特定领域翻译、真实场景以及指令遵循示例,从而提高了翻译质量、领域适应性、实际翻译的鲁棒性,以及遵循翻译相关指令的能力。
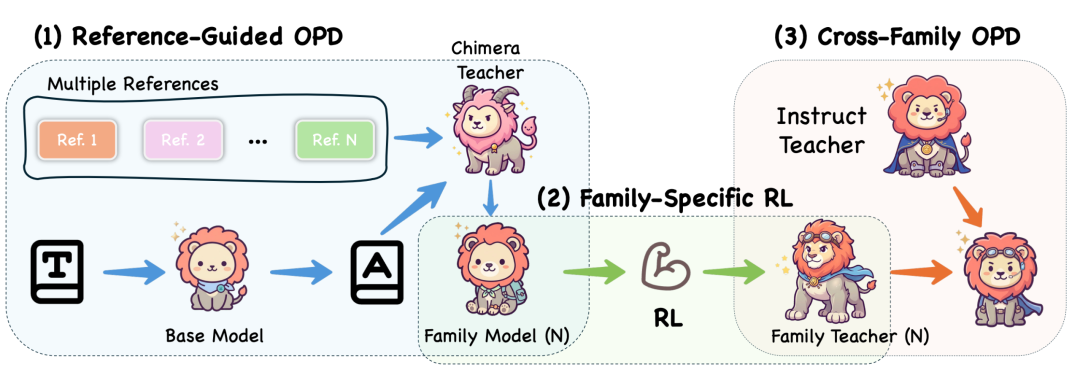
图 3: Hy-MT2 以语系为核心的后期训练流水线
以语系为中心的后训练
FCPT 并没有直接混合所有语系的数据,而是将训练划分为多个语系分支,涵盖不同的语言群体,例如西欧语系、东亚语系以及中东地区的从右向左书写语系。在每个分支内部,我们融入了通用翻译数据、特定领域翻译数据、真实商业场景数据以及翻译指令遵循数据,以此来构建一个特定语系的导师模型。这种以语系为核心的设计使每个导师模型都能在更一致的语言分布下进行学习,从而减少了不同语系之间的相互干扰。
参考引导的 On-policy 蒸馏
Reference-Guided On Policy Distillation 是 FCPT 的第一阶段。在这一阶段中,我们对每个语系分支分别进行 On policy distillation,旨在获得一个特定语系的翻译策略,从而更好地捕捉对应语系的语言特性和翻译偏好。得到的模型将进一步为后续的 Family-specific RL Training 提供更强的初始化基础。
RG-OPD 的核心在于构建一个更强的 Chimera Teacher。与依赖单一导师模型的传统蒸馏方法不同,Chimera[4] Teacher 不需要额外训练一个大规模的翻译专用导师模型。对于每个源句,它将多个 Hy 系列参考模型生成的候选翻译与原始数据集标签相整合。虽然并非所有标签都是人工标注的,但它们仍然可以作为有用的参考信号。通过融合这些多源参考,Chimera Teacher 提供了更丰富的评分信号,有助于在蒸馏过程中引入更大的多样性,并为 On policy distillation 构建了更强的监督信号。
RG-OPD 的核心在于构建一个更强的 Chimera Teacher。与依赖单一导师模型的传统蒸馏方法不同,Chimera Teacher 不需要额外训练一个大规模的翻译专用导师模型。对于每个源句,它将多个 Hy 系列参考模型生成的候选翻译与原始数据集标签相整合。虽然并非所有标签都是人工标注的,但它们仍然可以作为有用的参考信号。通过融合这些多源参考,Chimera Teacher 提供了更丰富的评价信号,有助于在蒸馏过程中引入更大的多样性,并为 On policy distillation 构建了更强的监督信号。
RG-OPD 的核心在于构建一个更强的 Chimera Teacher。与依赖单一导师模型的传统蒸馏方法不同,Chimera Teacher 不需要额外训练一个大规模的翻译专用导师模型。对于每个源句,它将多个 Hy 系列参考模型生成的候选翻译与原始数据集标签相整合。虽然并非所有标签都是人工标注的,但它们仍然可以作为有用的参考信号。通过融合这些多源参考,Chimera Teacher 提供了更丰富的评价信号,有助于在蒸馏过程中引入更大的多样性,并为 On policy distillation 构建了更强的监督信号。
具体而言,给定源句子 x 及其参考答案集 R(x)(其中 R(x) 由多个候选参考译文组成),当前语系分支中的学生模型首先基于其当前的策略 πθ 生成翻译 yθ。随后,Chimera 导师根据多源参考答案集 R(x) 对学生的输出进行评估,并产生一个导师策略目标分布:πT(· | x, R(x))
通过最小化从导师策略到学生策略的前向 KL 散度(forward KL divergence),从而对学生模型进行优化。其训练目标可表示为:
L_RG-OPD = D_KL ( πT(· | x, R(x)) || πθ(· | x) )
在此,πT 表示由 Chimera Teacher 构建的蒸馏目标分布,而 πθ 表示当前学生模型的输出策略。我们采用前向 KL 散度作为蒸馏目标,使学生模型能够以在线方式从 Chimera Teacher 中学习融合后的翻译偏好,并逐步提升其在对应语言家族(language family)中的翻译策略能力。
在 RG-OPD 之后,每个语言家族分支都会获得一个特定于该家族的学生模型,该模型已经适应了对应语言家族的翻译偏好和表达模式。
面向特定语言家族的强化学习训练
在 Family-specific RL Training 中,每个语系分支以 RG-OPD 输出的模型作为初始化,通过组相对策略优化(Group Relative Policy Optimization, GRPO)得到进一步优化。为了提供更细粒度且更严格的奖励信号,我们引入了一套混合评估系统,该系统将基于规则的预过滤与基于大语言模型的多维度质量度量(MQM)裁判相结合。
基于规则的预过滤
在将翻译结果传给 LLM 评估器之前,先使用基于规则的过滤器来拦截严重的文本退化现象。对于表现出严重重复或语系混杂的翻译结果,会直接给予 0 分奖励。这确保了退化输出能在早期受到惩罚,并避免了不必要的 LLM 计算。
LLM 裁判评估系统
对于通过预过滤的翻译结果,基于 LLM 的裁判会根据 5 个维度的错误类型学进行评估,而不是直接给出一个整体分数。这五个维度分别是:
术语:识别术语错误、与术语资源的不一致,或整篇文本中的术语使用不一致。
准确性:检测误译、过译、欠译、内容添加或省略、无根据的翻译、漏译以及语系混杂的现象。
语言规范:检查语法错误、标点错误、拼写错误、语篇规范错误以及违反地域文化惯例的情况。
风格:评估与外部参考资料的不一致、语言语体不当、表达晦涩、句式不自然以及风格不一致。
指令遵循:评估对任务约束的遵守情况,标记错误的语言、未执行的翻译任务,以及未能遵循术语、格式、风格或上下文指南的情况。
评分规则
评估从 100 分的基准分开始。LLM 裁判会识别翻译错误并根据其严重程度进行扣分。致命错误(例如使用错误的语言或未能执行翻译任务)将直接导致整体得分为 0。重度错误每出现一次扣 10-20 分,而轻度错误每出现一次扣 2-5 分。整体得分
长度惩罚
为了防止模型通过生成简短、截断或过长且冗余的句子来钻奖励系统的空子,我们引入了长度惩罚机制。给定源句 x、长度为 L_gt 的真实翻译(ground-truth translation)以及长度为 L_y 的模型生成翻译 y,长度惩罚 P_len 的计算公式如下:
P_len = min( 0.5 × |L_gt - L_y| / L_gt , 0.5 )
最终奖励 r(x, y) 的计算方法是将整体 MQM 分数归一化至 [0,1] 区间,减去长度惩罚项 P_len,并将结果截断至 0。
跨语系 On-policy 蒸馏
Cross-family On Policy Distillation 是 FCPT 的最终训练流程,旨在将多个特定语系的强导师模型所学到的特定语系翻译能力,迁移到一个统一的学生模型中。同时,为了提高模型的指令遵循能力,我们在该阶段引入了通用指令遵循数据,并使用 Hy Instruct 模型作为相应的指令导师来提供蒸馏信号。因此,Cross-family OPD 可以被视为一个统一的多导师蒸馏过程。
具体而言,给定一个输入样本 x,我们将它的导师策略表示为 πT(· | x),统一学生模型的输出策略表示为 πθ(· | x)。在这一阶段,我们采用逆向 KL 散度(reverse KL divergence)作为蒸馏目标,其定义为:
L_Cross-OPD = D_KL ( πθ(· | x) || πTτ(x)(· | x) )
其中 πθ(· | x) 表示从面向机器翻译的中期训练初始化的学生模型的输出策略,而 πTτ(x)(· | x) 表示所选择导师模型的输出策略。对于翻译样本,τ(x) 会根据 x 的语系选择相应的 Family-specific RL Training 强导师模型;对于通用指令遵循样本,τ(x) 则选择 Hy Instruct 导师模型。
量化
为了适应不同资源约束下的部署需求,我们对获得的 Hy-MT2 模型系列进行了模型量化,提供了包括 FP16、8-bit、4-bit、2-bit 和 1.25-bit 在内的多种精度变体。
对于 8 位和 4 位变体,我们主要采用训练后量化(PTQ)流水线。该方法无需重新训练模型,而是利用一小部分校准数据来估计模型权重或激活值的分布,从而降低存储和计算开销。具体而言,8 位量化采用更高精度的低比特表示以最大程度减少性能退化,而 4 位量化则进一步压缩权重表示,并通过专门的校准策略来减轻量化误差。
对于 2 位版本,我们采用了来自 AngelSlim[5] 框架的超低比特量化感知训练(QAT)方案。与 PTQ 相比,2 位量化施加了更严格的表示约束。因此,它需要在训练过程中显式模拟低比特量化行为,从而让模型权重逐步适应低精度表示。该 2 位方案利用了拉伸弹性量化(Stretched Elastic Quantization, SEQ),将权重固化(quantize)到 {−1.5,−0.5,+0.5,+1.5} 中。通过优化量化映射和缩放因子,该方法提高了模型在 2 位约束下的稳定性和性能恢复能力。
针对极端压缩场景,我们进一步实现了 Sherry,一种 1.25 位的稀疏三值量化方法。Sherry 将模型权重固化到 {−1,0,+1} 的三值空间中,并引入了 3:4 的细粒度稀疏模式,即约束每 4 个权重构成的分块中必须精确包含一个零和三个仅带符号的权重。这种结构使得 4 个权重可以打包到 5 个比特中,从而在实现规则化 1.25 位表示的同时,保持了更利于单指令多数据(SIMD)计算模式的硬件对齐。与传统的 2 位打包或 1.67 位不规则打包相比,Sherry 在压缩率和推理效率之间取得了更优的平衡。
对于 1.25 位和 2 位的 QAT,我们采用了基于蒸馏的训练策略。具体而言,低精度模型作为学生模型,而高精度模型作为教师模型。整体优化目标将标准语言模型损失与基于 KL 散度的蒸馏损失相结合。对于 KL 部分,受到启发,我们同时引入了正向和反向 KL 散度。与以往使用固定的、人工选择的权重系数的方法不同,我们计算了教师模型对每个 token 的置信度得分,并据此动态调整正向和反向 KL 项的相对权重。
最终,凭借这些多样化的精度变体,Hy-MT2 可以灵活部署于广泛的场景中,包括高精度业务服务、低资源设备推理以及极端边缘端压缩。
实验验证
为了全面评估 Hy-MT2 的翻译能力,我们从四个维度构建了评估基准:通用翻译、实际商业场景翻译、特定领域翻译以及翻译指令遵循。
通用翻译评测
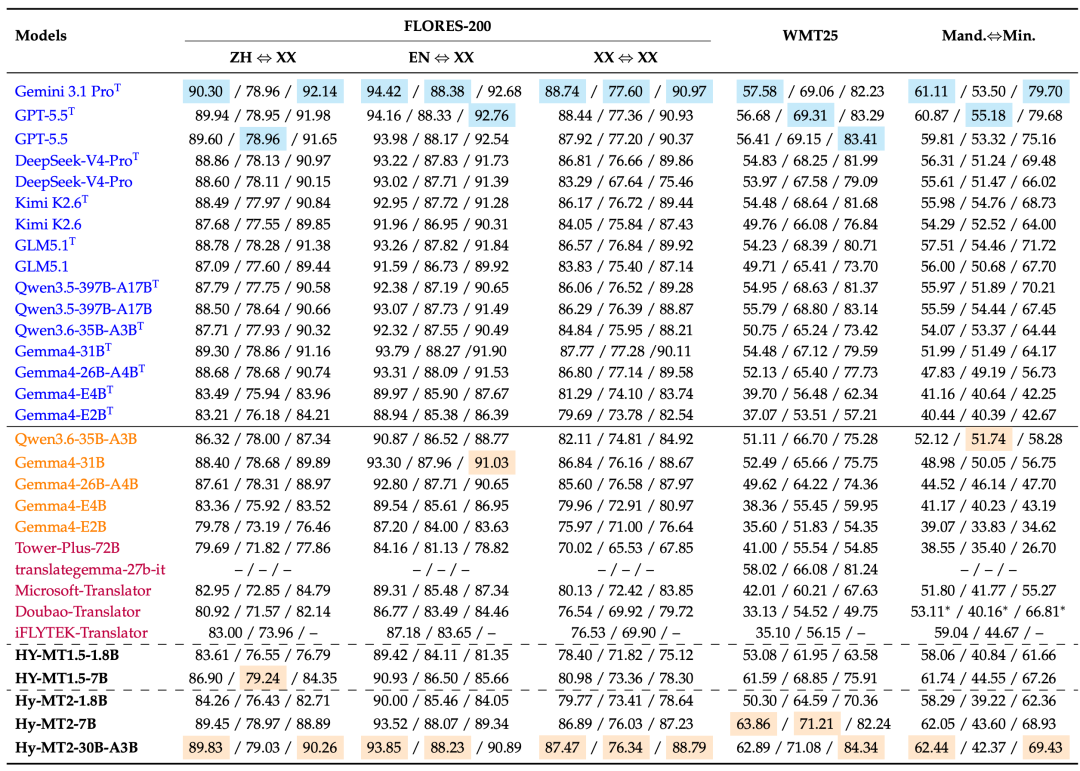
图 4:在通用翻译基准上的性能对比。每个单元格中报告了 XCOMET-XXL/CometKiwi/GEMBA 的得分,且所有得分均已乘以 100。T 表示思考模式(thinking mode)。在 FLORES-200 中,XX⇔XX 表示所有评估翻译方向的平均性能,包括 ZH⇔XX 和 EN⇔XX。Mand.⇔Min. 表示普通话⇔少数民族语言翻译(Mandarin⇔Minority)。带有 * 标记的数值仅在支持的语言对上计算。基线模型被分为 大规模模型和所有思考模式(Think-mode)模型、非思考模式下的中小尺寸通用模型,以及 翻译专用模型。我们的模型以粗体显示。每列中大规模模型和所有思考模式模型中的最佳结果用蓝色背景突出显示,而非思考模式中小尺寸模型中的最佳结果则用浅橙色背景突出显示。
在通用翻译评估中,Hy-MT2 相比 Hy-MT1.5 在通用翻译基准测试上取得了显著的提升。在 FLORES-200 的 XX⇔XX 设置下,Hy-MT2-1.8B、Hy-MT2-7B 和 Hy-MT2-30B-A3B 分别达到了 79.77、86.89 和 87.47,分别相当于 Gemini 3.1 ProT 的 89.9%、97.9% 和 98.6%。特别是在该设置下,Hy-MT2-7B 和 Hy-MT2-30B-A3B 表现优于 DeepSeek-V4-Pro、Kimi K2.6、Qwen3.5-397B-A17B 和 Gemma4-26B-A4B 等强劲的基线模型。与 Hy-MT1.5-7B 相比,Hy-MT2-7B 将 XCOMET-XXL 评分从 80.98 提升至 86.89,展示出在整体多语言翻译性能上的明显优势。
在 WMT25 上,Hy-MT2-7B 和 Hy-MT2-30B-A3B 同样表现强劲。Hy-MT2-7B 取得了 63.86/71.21/82.24 的成绩,而 Hy-MT2-30B-A3B 达到了 62.89/71.08/84.34。相比于评分为 61.59/68.85/75.91 的 Hy-MT1.5-7B,Hy-MT2-7B 在所有三项指标上均有提升,其中在 GEMBA 上的增幅尤为显著。Hy-MT2-30B-A3B 则在所有对比系统中斩获了最佳的 GEMBA 评分,超越了 Gemini 3.1 ProT 和 GPT-5.5T,这表明它在具有挑战性的 WMT 设置中拥有更强的整体翻译质量和可读性。在普通话⇔少数民族语言翻译(Mandarin⇔Minority translation)方面,Hy-MT2-7B 和 Hy-MT2-30B-A3B 的 XCOMET-XXL 评分分别达到 62.05 和 62.44,均优于 Gemini 3.1 Pro 和 Hy-MT1.5-7B。这表明 Hy-MT2 在普通话与少数民族语言的翻译中保持了强劲的性能,并进一步提升了低资源语言场景下的翻译质量。
在轻量化设置下,Hy-MT2-1.8B 相比 Hy-MT1.5-1.8B 展现出持续的进步,并且在面对更大规模的开源模型及商业翻译系统时依然保持极高的竞争力。尽管其体量较小,但它的表现超越了 Tower-Plus-72B,并与微软翻译和豆包翻译打得互有胜负。在 WMT25 上,Hy-MT2-1.8B 在所有三项指标上均超越了这两款商业系统,证明了其在效率与质量之间取得了极佳的平衡。
领域特定与真实场景翻译评测
WildMTBench: 我们构建了 WildMTBench,以评估模型在实际商业输入上的性能。该数据集涵盖网页、会议、书籍、社交内容、新闻和文档等六种场景,共包含 2,000 个样本。它专注于评估模型对多样化文本形式、真实世界输入分布以及复杂应用需求的鲁棒性和适应能力。
DomainMTBench: 我们构建了 DomainMTBench,以评估专业领域的翻译质量。该数据集涵盖金融、法律、政治、科技、医疗和教育等六个领域。数据收集自开源语料库,并通过清洗、过滤、领域分类和人工翻译标注进行处理,最终获得 24,000 个样本。该基准测试专注于评估模型处理领域术语、专业表达以及行业既定翻译的能力。
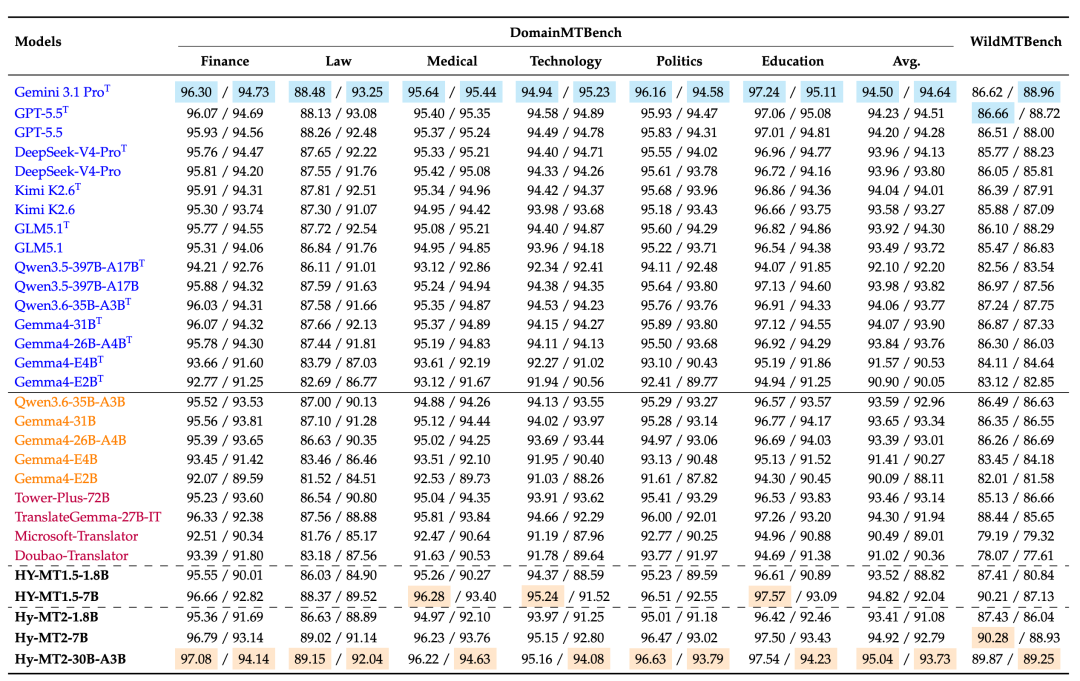
图 5:在 DomainMTBench 和 WildMTBench 上的性能对比。每个单元格报告了 XCOMET/GEMBA 分数,所有分数均已乘以 100。Avg. 表示 DomainMTBench 上的整体平均分数。
领域特定翻译
在特定领域翻译评估中,我们使用 DomainMTBench 来评估模型在多个专业领域中的性能。我们汇报了 XCOMET 和 GEMBA 的评分,其中 XCOMET 用于衡量基于参考答案的翻译质量,而 GEMBA 则提供基于大语言模型的整体翻译质量评估。 总体而言,Hy-MT2 在 DomainMTBench 上表现强劲,且在 GEMBA 评分中相比 Hy-MT1.5 取得了持续的提升。在平均分方面,与 Hy-MT1.5-1.8B 相比,Hy-MT2-1.8B 将 GEMBA 评分从 88.82 提升至 91.08;而 Hy-MT2-7B 相比 Hy-MT1.5-7B,则从 92.04 提升至 92.79。Hy-MT2-30B-A3B 进一步在平均分上达到了 95.04/93.73,在所有对比系统中获得了最佳的 XCOMET 结果,并在开源和翻译专用模型中获得了最佳的 GEMBA 结果。在各个具体领域中,Hy-MT2-30B-A3B 在金融、法律和政治领域的 XCOMET 评分分别达到了 97.08、89.15 和 96.63,均位列第一。同时,它在医疗、科技和教育领域也保持了极高的竞争力。这些结果表明,更大参数量的 MoE 模型在保持各专业领域强劲表现的同时,有效强化了特定领域的翻译能力。Hy-MT2-7B 同样展现出强劲的领域翻译质量,其平均分相比 Hy-MT1.5-7B 从 94.82/92.04 提升至 94.92/92.79,并且在多个领域的 GEMBA 评分上都有明显的涨幅。对于轻量化模型,Hy-MT2-1.8B 相比 Hy-MT1.5-1.8B 在 GEMBA 上取得了显著提升,平均分从 88.82 增加到 91.08。它在平均分上还超越了微软翻译和豆包翻译等商业系统,尤其是在 GEMBA 评分中表现突出。
真实场景翻译
在 WildMTBench 上,Hy-MT2 在真实世界翻译场景中也展现出明显的优势。Hy-MT2-7B 取得了 90.28/88.93 的成绩,在 XCOMET 和 GEMBA 上均超越了 Hy-MT1.5-7B。Hy-MT2-30B-A3B 进一步达到了 89.87/89.25,在所有对比系统中获得了最佳的 GEMBA 评分,并在基于 LLM 的评估中超越了 Gemini 3.1 Pro。在轻量化配置下,Hy-MT2-1.8B 的 GEMBA 评分相比 Hy-MT1.5-1.8B 实现了大幅提升,从 80.84 增至 86.04,同时保持了相近的 XCOMET 评分。此外,它在 WildMTBench 上的表现也明显优于微软翻译和豆包翻译等商业翻译系统。
综合来看,这些结果表明,Hy-MT2 不仅提高了标准特定领域的翻译水平,还增强了在真实世界商业场景中的鲁棒性和实用性。相比 Hy-MT1.5 的持续提升(特别是在 GEMBA 评分上)意味着,无论是在专业领域还是在真实世界的环境下,Hy-MT2 都能输出更自然、更可靠的翻译。
指令遵循评测
IFMTBench: 我们构建了 IFMTBench,用于评估多语言环境下面向翻译的指令遵循能力。该基准包含 7,344 个高质量的人工对齐样本,指令涵盖中文、德文、日文、法文、英文、西班牙文和韩文,覆盖了术语、格式和风格等工业级翻译约束。其中包含 4,506 个单约束样本和 2,838 个多约束样本,用以评估基础约束的执行能力以及在复杂指令组合下的鲁棒性。
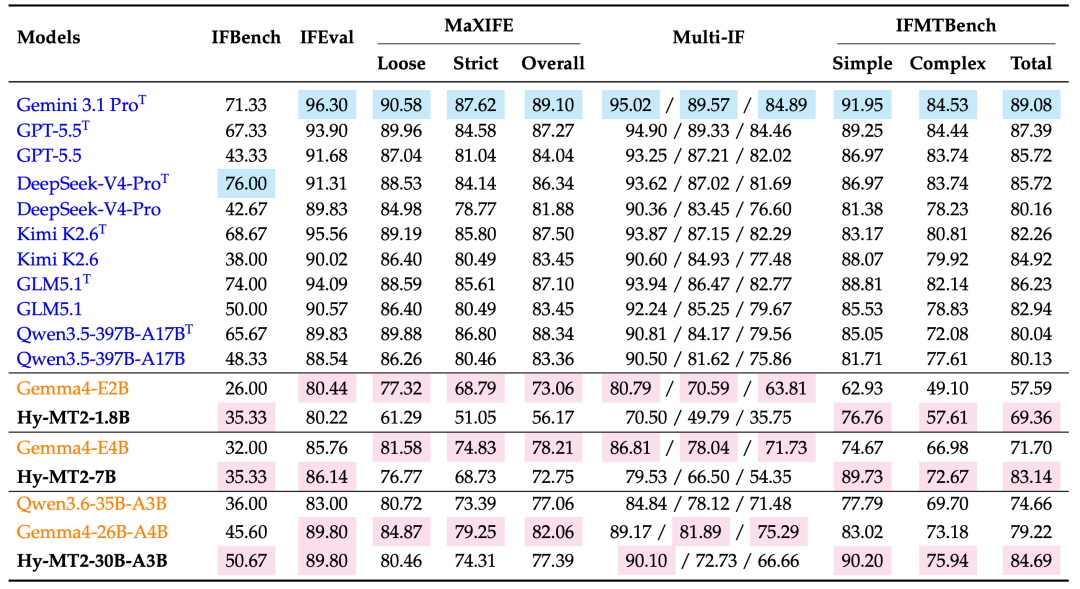
图 6:在指令遵循基准测试上的性能对比。所有分数均以百分比形式报告。对于 Multi-IF,每个单元格报告了第一轮/第二轮/第三轮(turn1/turn2/turn3)的分数。超大型模型中的最佳结果以蓝色背景高亮显示,而中小型模型在各自对应参数规模组别中的最佳结果则以粉色背景高亮显示。
我们在通用指令遵循基准测试以及我们专门针对翻译的 IFMTBench 上评估了指令遵循能力。Hy-MT2 在 IFMTBench 上展现出了强大的翻译专用指令遵循能力。Hy-MT2-7B 在 Simple、Complex 和 Total 维度上分别达到了 89.73、72.67 和 83.14 的得分,超越了 Gemma4-E4B 和其他中型开源基线模型。Hy-MT2-30B-A3B 进一步提升至 90.20、75.94 和 84.69,在中小模型中取得了最佳的 IFMTBench 综合得分。与 Qwen3.6-35B-A3B 和 Gemma4-26B-A4B 相比,Hy-MT2-30B-A3B 获得了持续的提升,尤其是在 Complex(复杂)指令上,展现出处理多约束翻译请求时更强的能力。
Hy-MT2 的表现与规模大得多的通用模型相比也颇具竞争力。在 IFMTBench 上,Hy-MT2-30B-A3B 的总分接近 Kimi K2.6、GPT-5.5 和 Gemini 3.1 Pro,甚至在 Simple 指令上超越了数个超大型模型。这表明,针对翻译指令遵循进行定向优化,可以有效提升模型对约束条件的理解与执行能力。
在通用指令遵循基准测试中,Hy-MT2-30B-A3B 依然保持了扎实的高水平表现,在 IFEval 上达到 89.80,在 MaXIFE 上的综合得分达到 77.39,在这两项指标上均超越了 Qwen3.6-35B-A3B。然而,它在 Multi-IF 后续轮次中的得分低于一些同类基线模型,这表明 Hy-MT2 的主要优势在于翻译专用的指令遵循,而非通用的多轮指令遵循。
量化实验
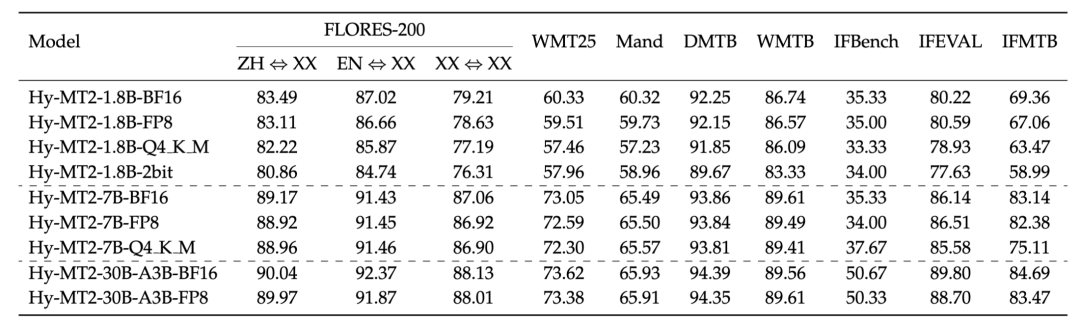
我们评估了各种量化版本 Hy-MT2 模型在通用翻译、特定领域翻译以及指令遵循基准测试中的模型大小和性能表现。总体而言,量化在保持强大翻译质量的同时,大幅降低了部署成本。对于 Hy-MT2-1.8B 和 Hy-MT2-7B,FP8 在大多数基准测试中实现了非常接近 BF16 的性能,这表明低精度推理可以在极小的质量损失下得以应用。Q4_K_M 也保持了颇具竞争力的性能,尤其是在 FLORES-200 和领域基准测试上,不过在 IFMTBench 等指令遵循任务上出现了更明显的下滑。2-bit 版本的 Hy-MT2-1.8B 则表现出更显著的性能下降,这表明极致量化在效率与准确率之间引入了更权衡的取舍。对于基于 MoE 架构的 Hy-MT2-30B-A3B,FP8 相比于 BF16 保持了高度稳定,这证明了更大的架构对量化具有更强的鲁棒性。这些结果表明,Hy-MT2 提供了灵活的部署选项,涵盖从高效的紧凑型模型到高质量的大型模型,同时保持了强大的多语言翻译能力。
翻译指令遵循案例分析
下面是 Hy-MT2 处理翻译特定指令的代表性示例。这些案例涵盖了常见的真实世界需求,包括风格控制、分隔符保留、法律修订、成语解释、具有文化保留的字幕翻译、法律文件匿名化以及面向语言学习的注释。
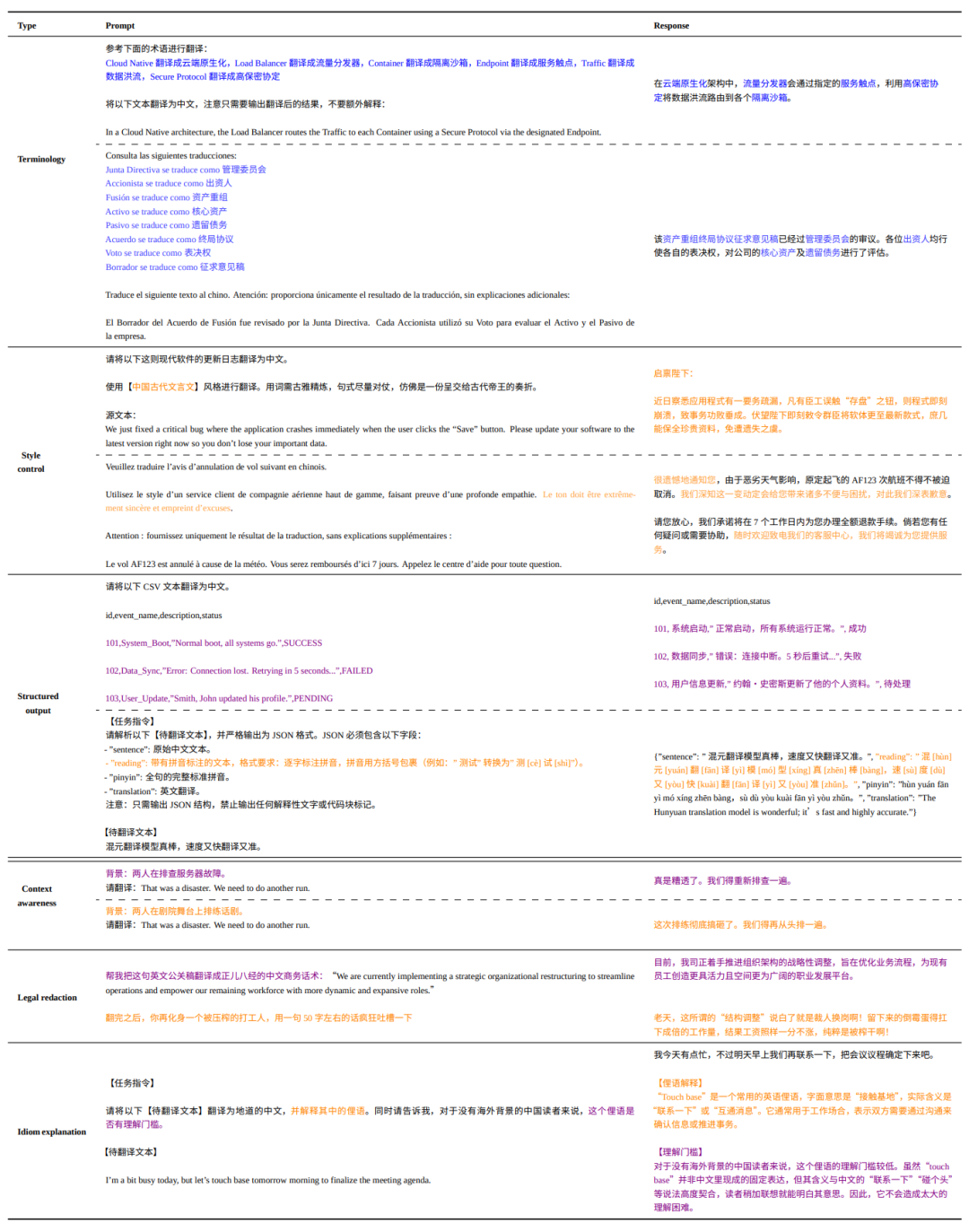

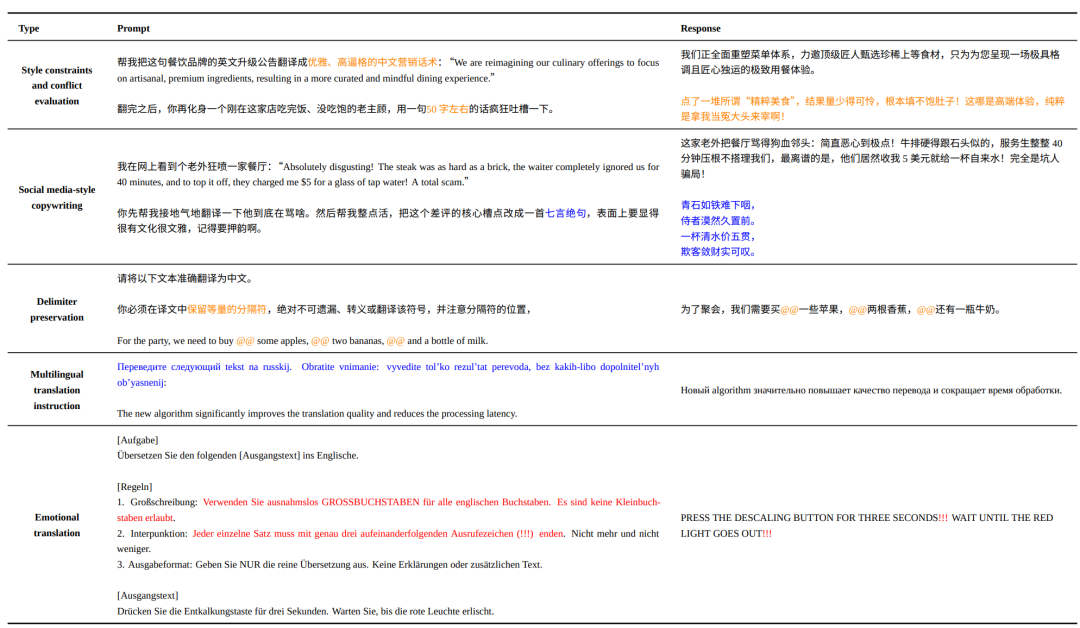
这些示例表明,Hy-MT2 能够同时处理显式的翻译约束和复合的用户需求。在风格控制的案例中,模型将现代软件更新日志改写为了具有正式、奏折般语气的文言文。在分隔符保留方面,它在翻译周围内容的同时,能够准确地保留特殊标记(例如 ##),展现出精准的格式感知能力。
Hy-MT2 在更复杂的场景中同样表现出色。在法律条文修订与去隐私化任务中,它在进行翻译的同时,还能应用所需的修订、段落重组以及编号规则。在成语解释和语言学习案例中,它不仅提供翻译,还能提供振假名、罗马字输出以及解释性批注,满足了多样化的教学与指令需求。
此外,在字幕翻译中,Hy-MT2 在遵循 SRT 格式规则的同时,还能保留具有特定文化特征的元素(如敬语),这体现了其管理多语言指令并保持文化忠实度的能力。
总体而言,这些示例证实了 Hy-MT2 能够可靠地执行各种翻译指令,并兼顾语言、风格、格式、文化背景以及辅助解释性需求等方面的约束。
总结
在本文中,我们推出了 Hy-MT2,这是一个专为真实翻译场景设计的多语言机器翻译模型家族。Hy-MT2 涵盖了稠密与混合专家两种架构,包括 Hy-MT2-1.8B、Hy-MT2-7B 和 Hy-MT2-30B-A3B。所有这些模型都支持 33 种语言之间的相互翻译,并且能够有效遵循多种语言的翻译指令。与 Hy-MT1.5 相比,Hy-MT2 在特定领域翻译、真实场景翻译、翻译指令遵循、模型规模扩展以及高效端侧部署方面带来了系统性的提升。Hy-MT2-7B 和 Hy-MT2-30B-A3B 的表现超越了诸如 Kimi K2.6 等强劲的开源翻译基线模型,并在多个基准测试中达到了接近甚至超越诸如 Gemini 3.1 Pro 等领先闭源模型的性能。轻量级的 Hy-MT2-1.8B 同样展现出了强大的小模型翻译能力,其表现优于数个商业翻译 API。为了支持多样化的部署场景,Hy-MT2 发布了多种精度格式,包括 1.25-bit、2-bit、4-bit、8-bit 和 FP16。其中,1.25-bit 和 2-bit 版本基于腾讯混元自研的量化技术构建,在提升推理效率的同时,显著降低了模型的资源消耗。总的来说,Hy-MT2 为实际应用提供了一个高质量、高效且具备多维能力的多语言翻译模型家族。
Core Contributor:
Mao Zheng, Zheng Li, Tao Chen, Bo Lv, Mingrui Sun, Mingyang Song, Jinlong Song, Hong Huang, Decheng Wu, Hai Wang, Yifan Song
Contributor:
Guanghua Yu, Yi Su, Hong Liu, Jinxiang Ou, Keyao Wang, Weile Chen, Haozhao Kuang, Kai Wang, Nuo Chen, Zihao Zheng, Chenhao Wang, Bin Xing, Chengcheng Xu, Tinghao Yu, Binghong Wu, Long Xu, Jiacheng Shi, Yunhao Wang, Baifang Chen, Lei Zhang, Qi Yang, Zhao Wu, Jiacheng Li, Lan Jiang, Yanfeng Chen, Lanrui Wang, Kai Zhang, Shuaipeng Li, Zhongzhi Chen, Weixuan Sun, Jiaqi Zhu, An Wang, Guanwei Zhang, Wei Li, Jun Xia, Weidong Han, Wutian Yang, Litong Hui, Luoguo Jia, Jiajia Wu, Hongchuan Zeng, Xinpeng Zhou, Tianxiang Fei
[1]HY-MT1.5 Technical Report
[2]Gemini 3.1 Pro: A smarter model for your most complex tasks
[3]Introducing GPT-5.5
[4]The name Chimera is inspired by the mythological creature composed of multiple animals. In our setting, it refers to a teacher signal constructed by fusing multiple reference sources.
[5]AngelSlim: A more accessible, comprehensive, and efficient toolkit for large model compression
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢