
DRUGONE
科学研究中的许多关键突破,都依赖于高质量的“实证软件(empirical software)”。这类软件的核心目标并非证明理论,而是通过不断优化可量化指标来提升预测、建模或分析能力。然而,开发这类科研软件往往需要研究人员耗费数月甚至数年时间,严重限制了科学探索效率。
为解决这一问题,研究人员开发了名为 ERA 的 AI 科研编程系统。ERA 结合大语言模型(LLM)与树搜索(Tree Search),能够自动生成、修改并持续优化科研软件代码。与传统“一次性代码生成”不同,ERA 会不断尝试新的代码方案,并利用可量化评分作为反馈信号,在巨大的解空间中寻找高性能方案。
研究人员在多个不同领域验证了 ERA 的能力。在单细胞 RNA 测序批次校正任务中,ERA 自动发现了 40 种超过当前公开排行榜最佳方法的新算法;在 COVID-19 住院预测任务中,ERA 构建了 14 种优于美国 CDC 官方集成模型的新预测策略。此外,该系统还在遥感图像分析、时间序列预测、神经活动预测以及数值积分等任务中实现了专家级表现。
研究人员认为,ERA 展示了一种新的 AI 科学编程范式,即通过“可评分任务(scorable task)”驱动 AI 自动探索、重组并优化科学软件,从而显著加速科研进程。

现代科学研究越来越依赖复杂软件系统。例如,分子动力学、蛋白结构预测、天气模拟、流体力学以及流行病传播预测等领域,本质上都依赖实证软件来建立模型与生成预测。
然而,开发这些软件极其耗时。研究人员往往依赖经验、直觉与反复试验来设计算法与调节参数,而很少能够系统性搜索所有可能方案。这使得大量潜在高性能方法永远无法被探索。
与此同时,大语言模型正在改变代码生成领域。从 AlphaCode 到 Codex,AI 已经能够根据自然语言自动生成复杂程序。但现有系统大多仍停留在“一次生成”模式,即根据提示词输出一段代码,而缺乏持续优化能力。
研究人员因此提出 ERA,希望将软件开发过程转化为一个可自动搜索的问题。只要任务能够通过某种指标进行评分,例如预测准确率、误差大小或排行榜分数,ERA 就能够自动生成代码、执行实验、分析结果,并不断优化解决方案。
研究人员认为,这种模式能够让 AI 不再只是“代码补全工具”,而是真正参与科研算法设计与科学软件开发。
方法
ERA 的核心由大语言模型与树搜索算法共同构成。系统首先接收一个“可评分任务”,包括任务描述、评价指标以及相关数据。随后,大语言模型会自动生成 Python 代码,并在沙盒环境中执行。
系统并不会只生成一次代码,而是利用 Tree Search 持续探索不同代码变体。每个代码版本都会根据实际运行结果获得一个质量评分,例如预测精度或排行榜成绩。树搜索算法则根据历史表现决定下一步应该探索哪些代码方向。
研究人员采用了类似 AlphaZero 的 PUCT 搜索策略,使系统能够在“利用已有高分方案”与“探索新方案”之间保持平衡。与传统遗传编程不同,ERA 的“变异”并不是随机修改代码,而是由 LLM 进行语义级代码重写,因此能够生成更复杂、更具有科研意义的新算法。
此外,ERA 还能够主动引入外部研究思想。例如,系统可自动读取论文摘要、教材内容或搜索引擎结果,并将其中的方法描述加入提示词,进一步指导代码生成。ERA 甚至还能将两个已有算法进行“思想重组(recombination)”,从而创造新的混合策略。
结果
ERA 在 Kaggle 基准测试中展现强大代码搜索能力
研究人员首先利用 2023 年 Kaggle Playground 竞赛构建基准测试,用于评估 ERA 的代码生成能力。这些任务覆盖分类、回归等不同机器学习问题,并能够通过排行榜分数直接评价性能。
结果显示,ERA 明显优于单次 LLM 代码生成以及“Best-of-1000”策略。即使连续生成 1000 个候选代码,传统方法仍然无法达到 ERA 的性能。
研究人员发现,ERA 的优势来自其树搜索结构。系统能够同时保留大量不同方向的代码分支,因此即使某条优化路径陷入停滞,仍然能够回溯并探索其他方案。
在搜索过程中,ERA 经常会突然发现能够显著提升性能的新策略,从而形成“性能跃迁(breakthrough)”。这些跃迁不断累积,最终形成远超普通 LLM 的高性能方案。
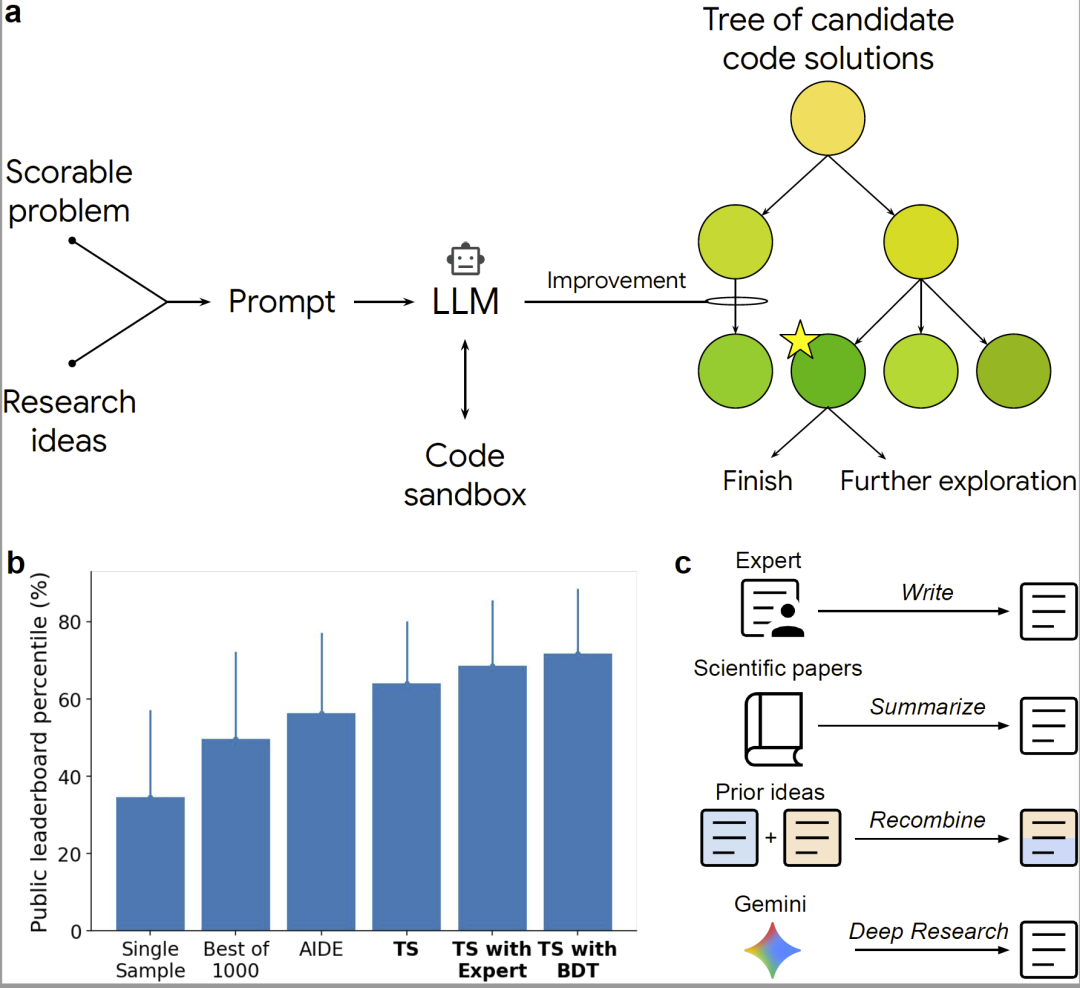
图1:ERA 系统架构、树搜索流程及 Kaggle 基准测试表现。
ERA 在单细胞 RNA 测序批次校正中超越现有最佳方法
研究人员随后测试 ERA 在单细胞 RNA 测序批次校正任务中的能力。该任务需要同时消除不同实验批次带来的技术偏差,并保留真实生物学差异,是单细胞分析中的核心难题。
研究人员利用 OpenProblems v2.0 基准,对 15 种现有方法进行比较。令人惊讶的是,即使不提供任何额外指导,ERA 自动生成的方法就已经超过公开排行榜最佳方法。随后,研究人员进一步将已有论文中的方法摘要输入 ERA,让系统尝试重新实现并优化这些算法。结果显示,在 9 种代表性算法中,ERA 有 8 种实现超过了原始论文结果。其中表现最好的方法是 ERA 改进版 BBKNN。该方法在总体性能上相比最佳公开方法 ComBat 提升约 14%。
深入分析发现,ERA 并不仅仅是在“复现”算法,而是在主动融合不同思想。例如,ERA 将 ComBat 的全局批次校正与 BBKNN 的局部邻域图方法结合,从而获得更优性能。进一步实验表明,ERA 还能够系统性“重组”不同方法。研究人员共生成了 55 种算法重组方案,其中 44% 同时超过两个原始父算法。
此外,研究人员还结合 Gemini Deep Research 与 AI Co-Scientist 自动生成研究思路。最终,ERA 共生成了 40 个超过当前公开排行榜最佳方法的新方案。
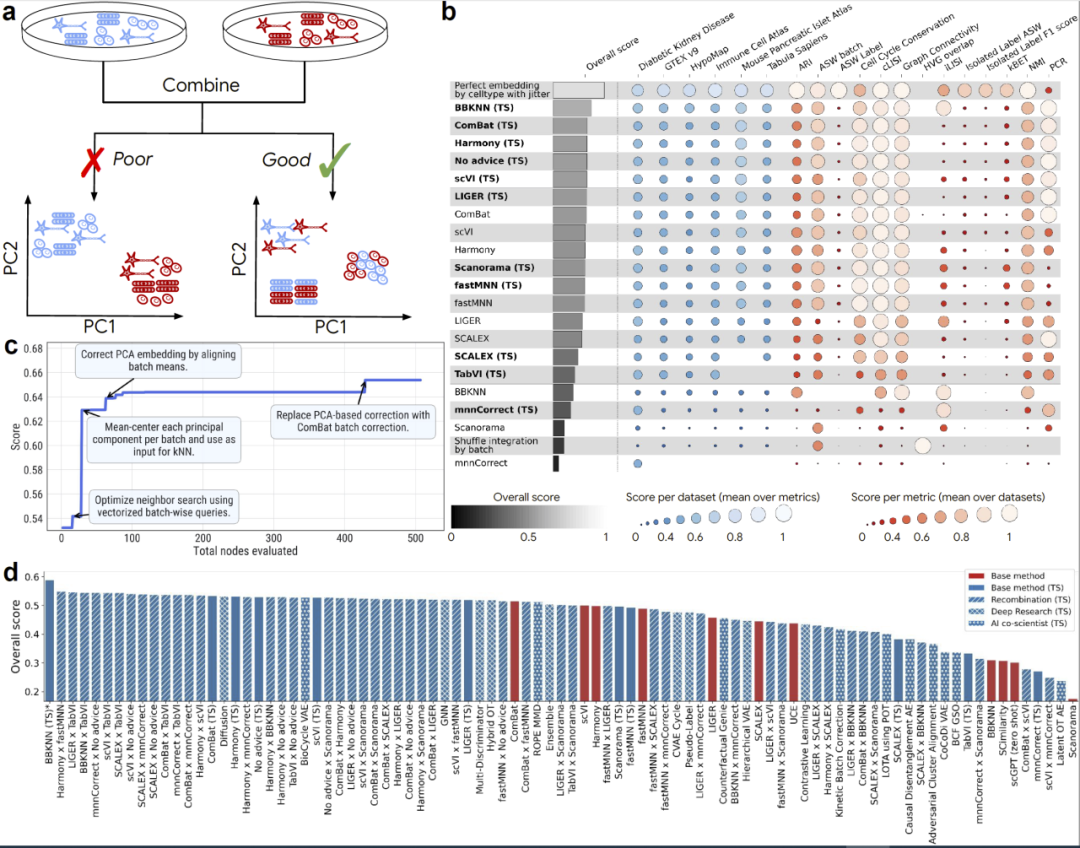
图2:ERA 在 scRNA-seq batch integration 任务中的性能比较。
ERA 在 COVID-19 预测中超过 CDC 官方集成模型
研究人员进一步将 ERA 应用于美国 COVID-19 住院人数预测任务。该任务是 CDC Forecast Hub 的核心基准,长期以来由多个学术机构与政府团队共同参与。
研究人员构建了一个“Google Retrospective”模型,并利用 ERA 自动优化预测算法。结果显示,该模型在整体 Weighted Interval Score(WIS)上优于 CDC 官方 Ensemble 模型。ERA 模型在美国多数州都实现了更低预测误差,说明其优势并非局限于少数地区。更重要的是,ERA 不仅能够复现现有预测模型,还能够主动融合不同预测思想。例如,系统会自动将经典流行病学模型与时间序列模型结合,或者将机器学习模型与气候基线模型结合,从而形成更强预测系统。
研究人员发现,ERA 自动生成的混合模型往往比单一建模范式更加稳定,也更容易兼顾长期趋势与短期波动。最终,ERA 共生成了 14 个超过 CDC 官方 Ensemble 的预测策略,其中包括 10 个“思想重组”模型、2 个 Deep Research 模型以及 1 个 AI Co-Scientist 模型。
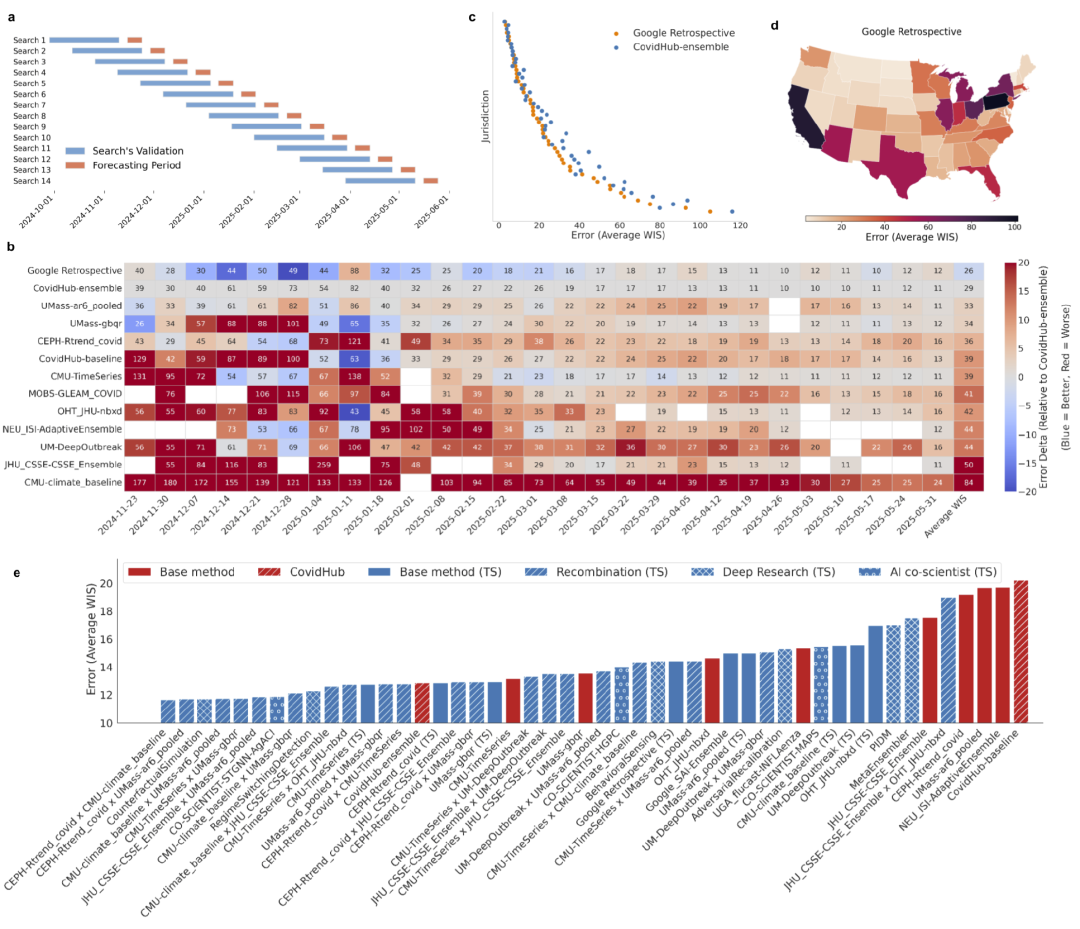
图3:ERA 在 COVID-19 住院预测任务中的表现。
ERA 能够自动构建通用时间序列预测系统
研究人员还利用 ERA 参与 GIFT-Eval 时间序列预测基准测试。该任务覆盖金融、交通、天气等多个领域,并包含 28 个不同数据集。
在“按数据集单独优化”模式下,ERA 超过了包括 foundation model 在内的所有公开排行榜模型。更有趣的是,研究人员进一步要求 ERA 从零开始构建一个“统一预测系统”,并限制只能使用最基础 Python 库。
ERA 最终自动生成了一套具有自适应配置能力的通用预测框架。该系统会自动分解时间序列中的趋势、季节性、日期特征以及残差部分,并针对不同数据集动态调整策略。研究人员发现,ERA 会主动引入节假日特征、日期编码以及趋势阻尼机制等复杂策略,而这些设计并非人工明确指定。
ERA 在遥感、神经科学与数值分析中达到专家水平
研究人员最后测试了 ERA 在多个完全不同领域中的泛化能力,包括遥感图像分割、斑马鱼全脑神经活动预测以及复杂积分数值求解。结果显示,ERA 在这些任务中均达到了专家级性能。这一结果说明,ERA 并不局限于机器学习建模,而是一种更通用的“科学软件自动优化系统”。
讨论
研究人员认为,ERA 的核心创新在于首次将“科学软件开发”系统性转化为可搜索、可评分的问题。
与传统遗传编程相比,ERA 不再依赖随机代码突变,而是利用 LLM 进行语义级代码重写,从而能够生成更加复杂、更具有科研意义的新算法。相比传统 AutoML,ERA 的能力也更广泛。它不仅能够优化模型超参数,还能够修改预处理流程、数学启发式规则以及复杂算法结构。
研究人员尤其强调了“思想重组”能力的重要性。许多最优方案并非完全原创,而是通过组合已有算法中的关键思想形成。这与真实科学研究中的创新方式高度相似。研究人员还指出,ERA 与 AlphaEvolve、FunSearch 等系统相比,更强调“科研思想探索”,而不仅仅是寻找代码层面的局部优化。
不过,研究人员也强调,目前 ERA 主要解决的是“可自动评分”的经验型问题,而非真正完整的科学发现。真正的科学突破仍需要对理论、因果关系以及数学机制进行深入推理。此外,研究人员也指出,能够自动生成专家级科研软件的 AI 系统同时存在潜在风险。例如,它可能降低复杂建模技术的使用门槛,从而在敏感领域带来安全隐患。
总体而言,ERA 展示了 AI 自动科研编程的重要潜力。研究人员认为,随着 foundation model 与推理能力持续提升,许多“可评分科学问题”的研究速度可能会在未来几年出现显著加速。
整理 | DrugOne团队
参考资料
Aygün, E., Belyaeva, A., Comanici, G. et al. An AI system to help scientists write expert-level empirical software. Nature (2026).
https://doi.org/10.1038/s41586-026-10658-6

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢