

大型语言模型(LLM)和视觉语言模型(VLM)的迅速崛起彻底改变了语义理解,然而这些系统仍然只是“旁观者”——通过2D投影观察世界,缺乏真正的物理基础。本论文《利用空间智能构建世界模型》旨在弥补这一关键缺陷,为具备空间智能的人工智能系统构建蓝图:即感知、想象、交互和推理3D世界的能力。我们认为,实现这一目标需要一种共生架构,将2D基础模型的丰富语义知识与显式3D/4D表示(特别是高斯散射)的几何精度相结合。
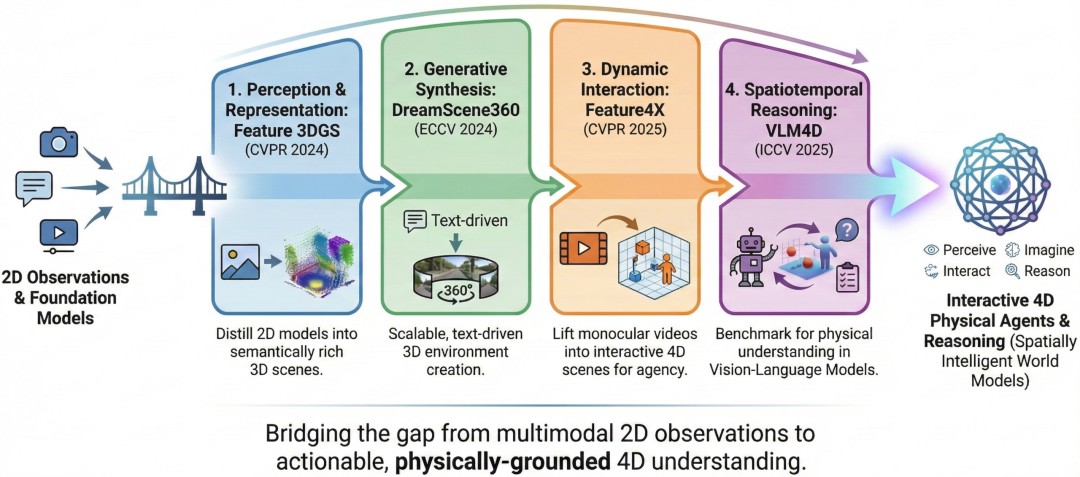
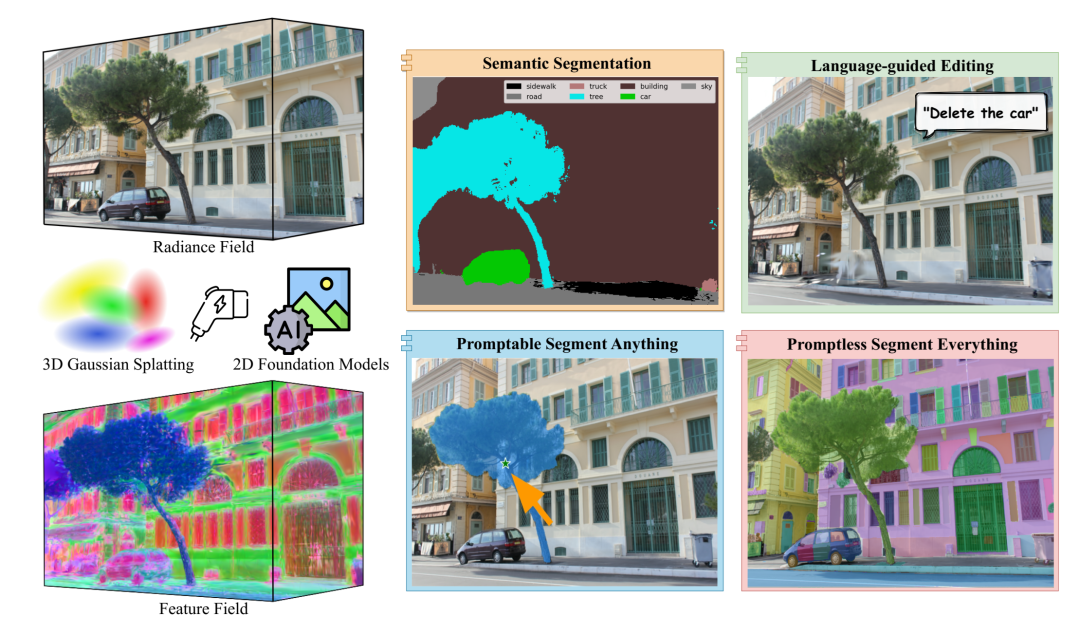
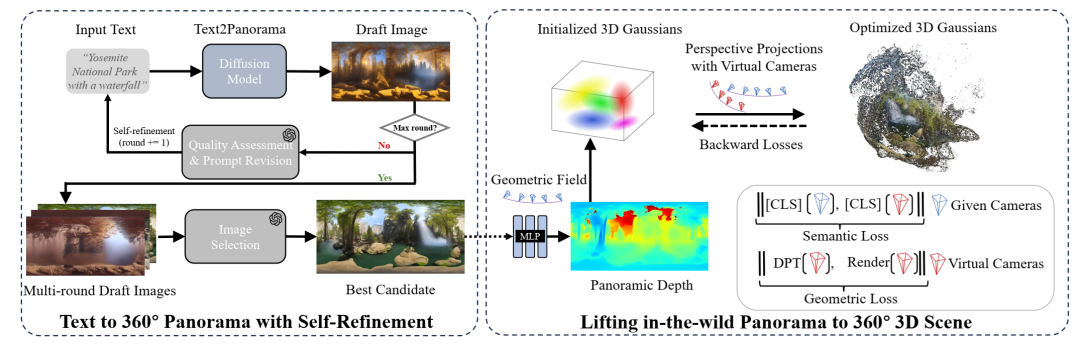
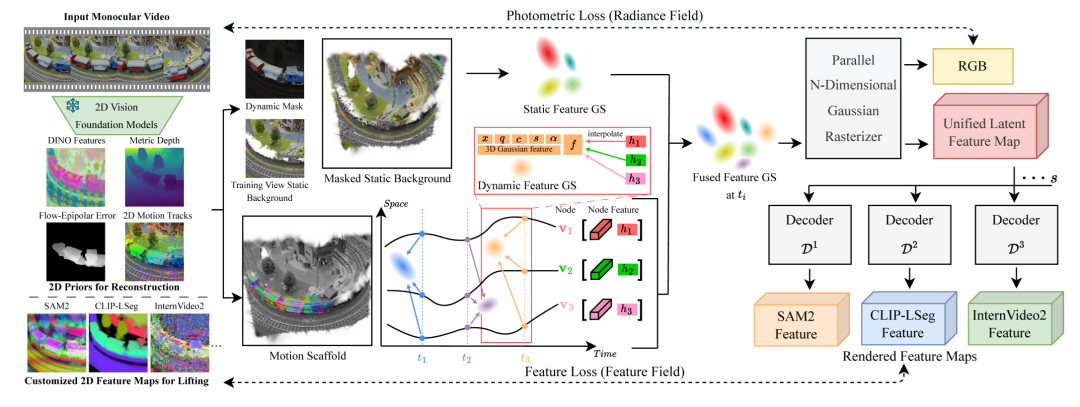
本研究通过四个核心贡献来呈现,分别对应于世界模型的基本功能。首先,我们提出了 Feature 3DGS,这是一个感知框架,可以将2D观测结果转换为语义化的、可编辑的、可提示的3D场景表示。通过将2D基础模型(例如 SAM、CLIP)中的高维特征提炼为显式3D高斯场,该方法实现了基于空间的多模态世界建模。其次,为了解决缺乏直接2D观测的场景,我们提出了 DreamScene360,这是一个用于 Imagination 的引擎,它通过将合成的 360° 全景图提升为显式3D高斯场,从自然语言描述中生成沉浸式、全局一致的3D环境。第三,考虑到真实的物理世界本质上是动态的而非静态的,我们致力于构建一个更通用的交互世界建模框架。我们引入了 Feature4X,它通过统一的时空潜在特征场将单目视频转换为动态的、多模态的、交互式的4D世界。这种显式表示为基于 VLM 的智能体提供了执行复杂任务(例如4D场景编辑(4D scene editing)和时空视觉问答 (spatiotemporal Visual Question Answering,SVQA))所需的空间和时间基础。然而,前沿人工智能是否真的能够在真实、动态的物理世界中解决复杂的高级认知任务,仍然是一个悬而未决的问题。为了探究这个问题,我们最终提出了VLM4D,这是一个严格的推理基准测试,它揭示了当前虚拟世界模型在理解动态物理交互方面的根本局限性,从而推动了物理人工智能(physical AI)的未来发展。这些工作共同展示了一条构建世界模型的路径,这些模型不仅能够识别像素模式,还能理解物理世界的几何形状和动态特性,为下一代空间计算(Spatial Computing)和具身人工智能(Embodied AI)奠定了基础。

论文题目:Building World Models with Spatial Intelligence
作者:Shijie Zhou
类型:2026年博士论文
学校:University of California, Los Angeles(美国加州大学洛杉矶分校))
下载链接:https://t.zsxq.com/rF30J
请索引第135篇博士论文
 |  |








内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢