
【论文标题】Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers 【作者团队】Sixiao Zheng,Jiachen Lu,Hengshuang Zhao,Xiatian Zhu,Zekun Luo,Yabiao Wang,Yanwei Fu,Jianfeng Feng,Tao Xiang,Philip H.S. Torr,Li Zhang 【发表时间】2020/12/31 【机构】复旦大学、牛津大学、萨里大学、腾讯优图、Facebook 【论文链接】https://arxiv.org/abs/2012.15840 【代码链接】https://github.com/fudan-zvg/SETR
【推荐理由】 本文来自复旦大学、牛津大学、萨里大学、腾讯优图、Facebook 联合团队,作者将语义分割任务看做一个序列到序列的转化问题,提出了一种基于 Transformer 的语义分割架构 SETR,改模型在诸多对比基准上取得了目前最优的性能。
近年来的大多数语义分割方法都采用了全卷积网络(FCN)和编码器-解码器架构。编码器会逐步降低空间分辨率,并且通过更大的感受野学习到更加抽象的语义的视觉概念。由于上下文建模对于分割任务来说至关重要,最近有一些研究工作着眼于通过空洞卷积或插入注意力模块来增大感受野。然而,基于「编码器-解码器」的 FCN 架构仍然是无法改变的。
在本文分钟,作者旨在通过将予以分割作为一种序列到序列的预测任务来提供一种替代方法。具体而言,作者采用了一种纯 Transformer 的架构将图像编码为一个图块序列。通过在 Transformer 的每一层中对全局上下文建模,这种编码器可以与一个简单的解码器组合,从而构建强大的分割模型 SETR。
为了验证模型的性能,作者进行了大量的实验。实验结果标记名,SETR 在 ADE20K、Pascal Context 数据集上都取得了目前最佳的分割性能,并且在 Cityscape 数据集上性能也相当可观。值得一提的是,SETR 在竞争激烈的 ADE20K 竞赛中位列榜首。
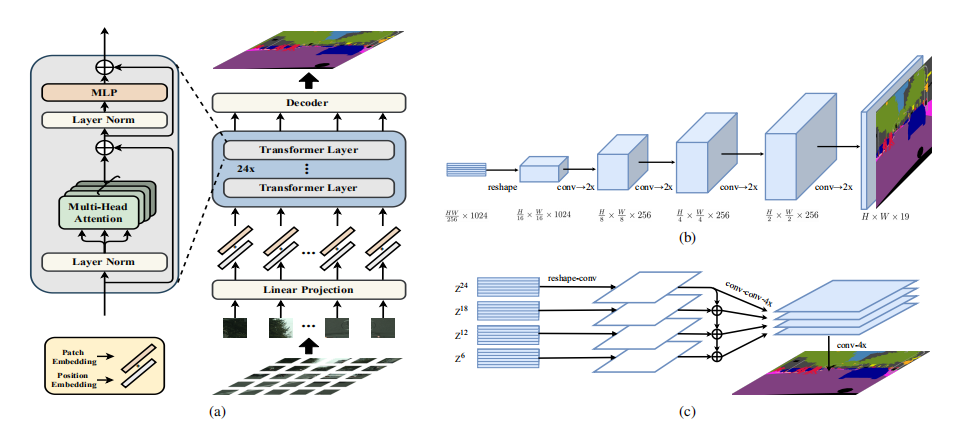
本文贡献如下: (1)将图像语义分割任务重新定义为了一个序列到序列的学习问题,对目前主流的编码器解码器 FCN 模型提出了一种替代方案。 (2)探索了将 Transformer 框架用于通过将图像序列化实现全注意力特征表征。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢