
DIAL团队 投稿
量子位 | 公众号 QbitAI
机器人的大脑架构之争,正在从二选一走向融合。
VLM路线擅长语义推理,VAM路线擅长预测物理世界,但两者各有短板。前者对物理规律缺乏直觉,后者训练和推理成本居高不下。
最近的折中方案,是给VLM外挂一个视频生成模型来预测未来帧。但额外模块带来的计算开销和工程复杂度依旧不小。
有没有可能,在一个统一的端到端框架里,既保留VLM的语义推理能力,又让它拥有预测未来的物理直觉,还不用额外生成像素级视频?
香港大学、小鹏机器人及北卡罗来纳大学教堂山分校的研究团队,刚刚给出了他们的答案:
一个名为DIAL (Decoupling Intent and Action via Latent World Modeling)的全新端到端VLA框架。
核心思路,是让VLM在自己原生的特征空间里做隐式世界建模,不外挂模型,不生成像素,直接在RoboCasa仿真基准和真实人形机器人部署中拿到优异性能。

让VLM在决策中发挥更大作用
在现有的端到端VLA架构中,一个普遍存在的局限是:往往将VLM主要视作一个大型的多模态特征提取器,直接将其输出的视觉-语言特征映射到底层的连续动作上。
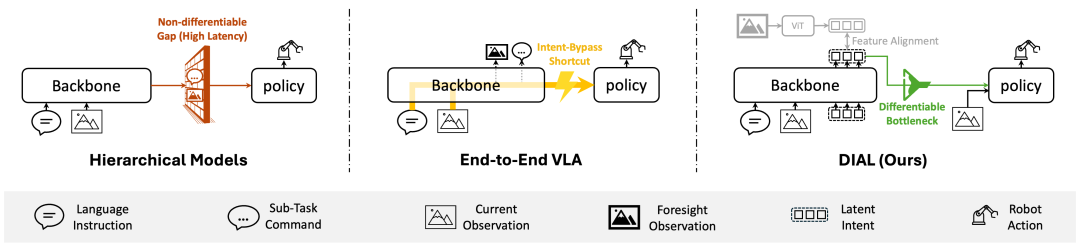
这种范式带来了两个挑战:
认知潜力利用不充分。 未能充分发挥VLM在高级逻辑决策中的核心作用。
训练稳定性不足。 直接使用底层的高频动作信号端到端地更新庞大的VLM参数,容易导致训练不稳定,甚至引发语义表征的退化。模型易于陷入视觉表象与动作之间的浅层统计关联,而未能真正建模交互背后的物理因果。
面对这一困境,DIAL框架提出了一种更为彻底且优雅的解耦思路。
借鉴认知科学中的双系统理论,不仅让强大的VLM直接在其原生的ViT特征空间中进行轻量化的隐式世界建模(Latent World Modeling),更关键的是,它将这种隐式视觉预见构建为一个可微的结构化瓶颈。
通过这一设计,DIAL严格地将底层运动控制锚定在了VLM的高级意图之上。
这种架构有效缓解了联合优化过程中的表征崩溃,使得模型能够高效吸收跨具身的人类数据以实现强大的泛化,并在真实的物理世界中更为稳健地驾驭复杂的多阶段协同任务。
双系统协同、可微意图与两阶段优化
DIAL架构将复杂的具身控制任务合理分解为两个协同工作的模块,并通过连续的特征空间将其连结:
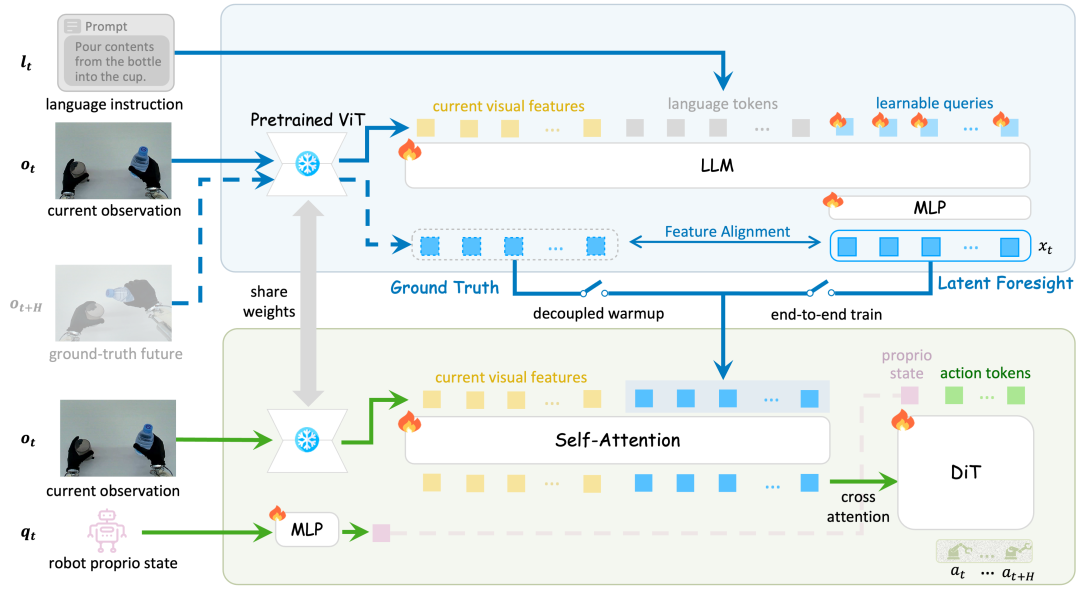
System-2(大脑):原生特征空间中的意图预见
在接收到当前观测画面和语言指令后,基于VLM的System-2不再直接输出底层动作,而是去预测任务完成后的隐式视觉特征。
由于这种预测是在VLM原生的ViT空间中进行的,它天然适配VLM的语义表征,不仅降低了预测的难度,而且这些特征本身就保留了丰富的语义结构信息。这一预测过程显式地编码了VLM的高级意图。
System-1(小脑):基于隐式逆动力学的动作生成
System-1是一个轻量级的动作策略网络。
目标非常明确:作为隐式逆动力学模型(Latent Inverse Dynamics Model),对比当前的视觉特征与大脑预测的未来特征,计算出为了实现这一状态转移所需的精确运动指令。
从解耦预热到端到端协同的两阶段训练
为了避免直接联合优化带来的梯度干扰,DIAL采用了一种稳定的两阶段训练策略:
第一阶段,解耦预热。
System-2和System-1分别独立训练。
System-2仅通过真实未来画面的特征作为监督,学习预测物理动态;System-1则在真实未来特征的指导下,专心学习从感知到精准动作的映射。
第二阶段,端到端协同。
打通管线,System-1开始使用System-2预测的隐式意图生成动作。
动作执行的误差梯度能够稳定地回传至VLM,促使VLM预测的特征进一步演变为真正服务于下游执行的面向动作感知(Action-aware)的隐式意图表征。
复杂任务的稳定执行与泛化适应
研究团队将DIAL部署至高自由度的小鹏IRON-R01-1.11人形机器人上,验证了模型在两类任务中的表现:
1、跨具身学习任务。
包含抓放(Pick & Place)与倒水(Pouring)两个基础操作任务,混合利用人类演示及机器人本体数据进行训练。
2、多阶段协调任务。
包含双手交接与放置(Handover & Shelving)以及垃圾清扫与倾倒(Trash Collection & Emptying)两个长程任务,仅使用机器人本体轨迹进行训练。
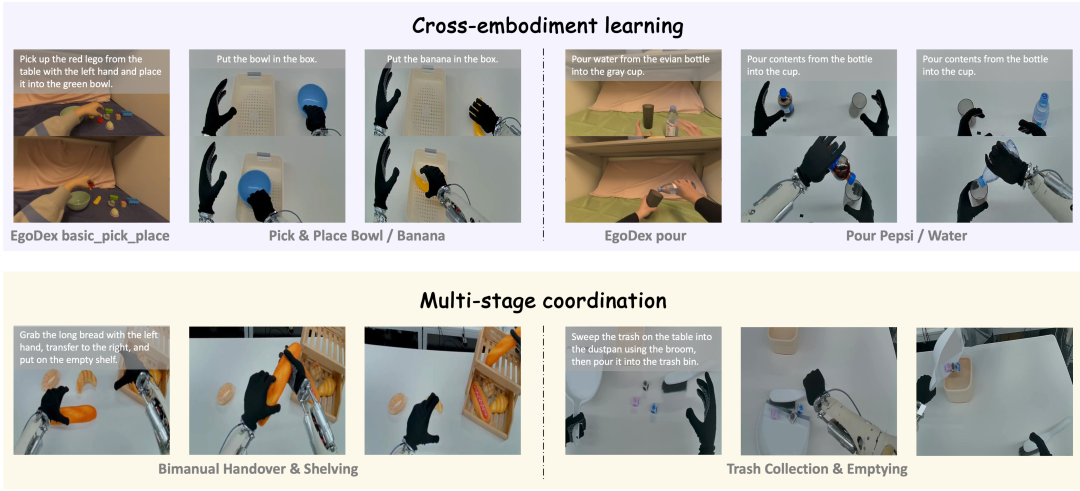
在真机部署中,这种基于隐式视觉预见的结构化引导机制展现出了极强的鲁棒性。
特别是在多阶段任务中,隐式意图为模型提供了清晰的视觉路线图,引导机器人顺畅完成子任务切换,有效避免了传统模型容易出现的动作死循环(例如在垃圾已扫入簸箕后仍重复清扫动作却不倒垃圾)。
此外,模型在抗背景干扰、组合目标消歧等OOD场景下也表现出了良好的适应能力。
实验分析:数据效率、规模扩展与可解释性
为了深度剖析DIAL架构为何能取得上述优异的部署效果,研究团队进行了详尽的定量与定性分析。
分为三个层面——
显著提升的数据利用效率
在包含24个任务的RoboCasa GR1人形机器人桌面仿真基准测试中,DIAL取得了平均70.2%的任务成功率,超越了该基准上公开的最优基线模型。
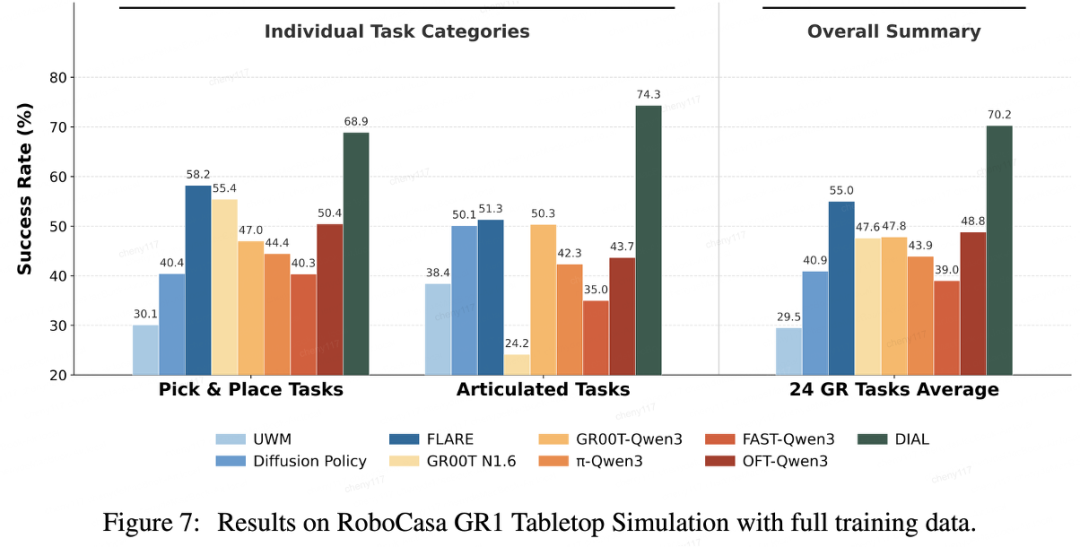
更为突出的是在严格的少样本设置下,DIAL仅需10%的训练数据量,即可达到58.3%的成功率,击败了使用全量数据训练的最优基线方法,展现了结构化隐式意图瓶颈所带来的强归纳偏置,极大提升了模型的数据学习效率。
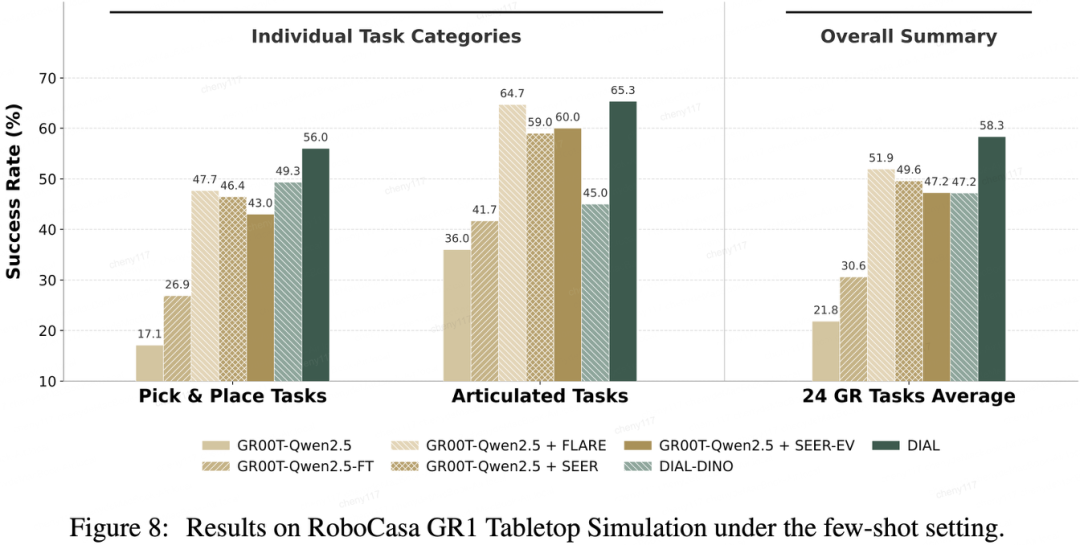
借助人类数据实现系统级规模扩展
利用人类数据来扩展模型能力是当前具身智能领域的热点方向。得益于功能解耦的设计,DIAL能够有效跨越异构数据,实现强大的全系统规模扩展。
通过将人类的姿态对齐到机器人的动作空间,双系统能够共同从多样的人类动作数据(如EgoDex)中汲取养分:System-2负责从人类视频中提取通用的任务逻辑,而System-1则从人类动作标签中蒸馏通用的运动先验。
将这种操作知识从人类迁移到机器人身上后,DIAL在分布外泛化能力上获得了巨大的提升:
1、仿真环境增益。
引入多样的抓放(pick & place)任务人类数据后,模型应对未见过的物体类型成功率从34.8%提升至41.1%;应对未见过的容器组合成功率从53.0%提升至58.7%。
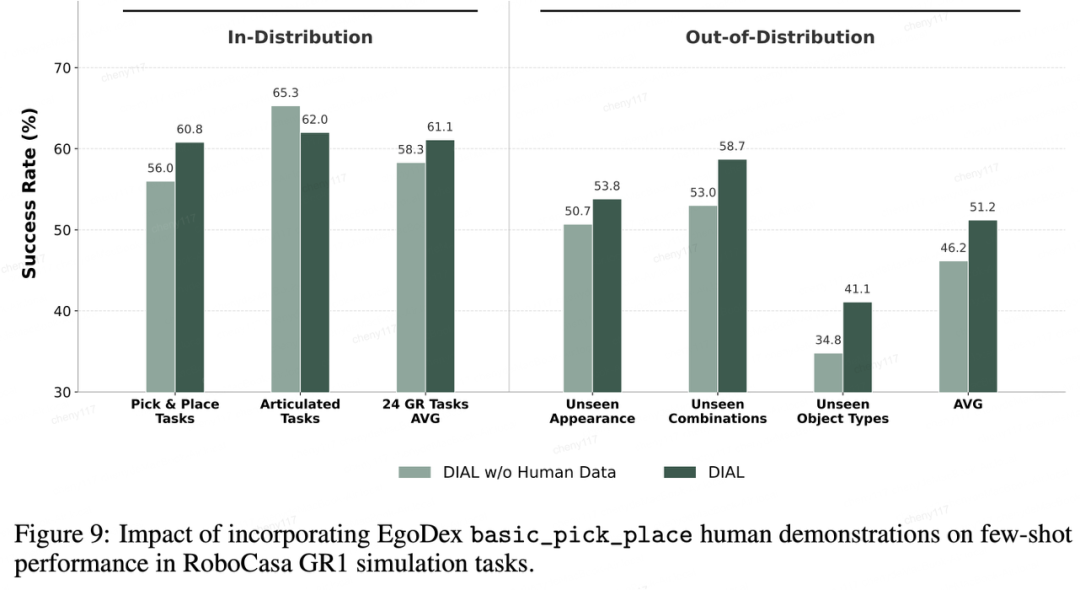
2、真机环境增益。
在真实世界中,人类数据的价值更加凸显。
消融实验显示,如果去除相关任务的人类数据,机器人在面临实例级迁移(例如抓取倒水任务中未见过的异形瓶子)时,成功率会直接从60%骤降至10%。
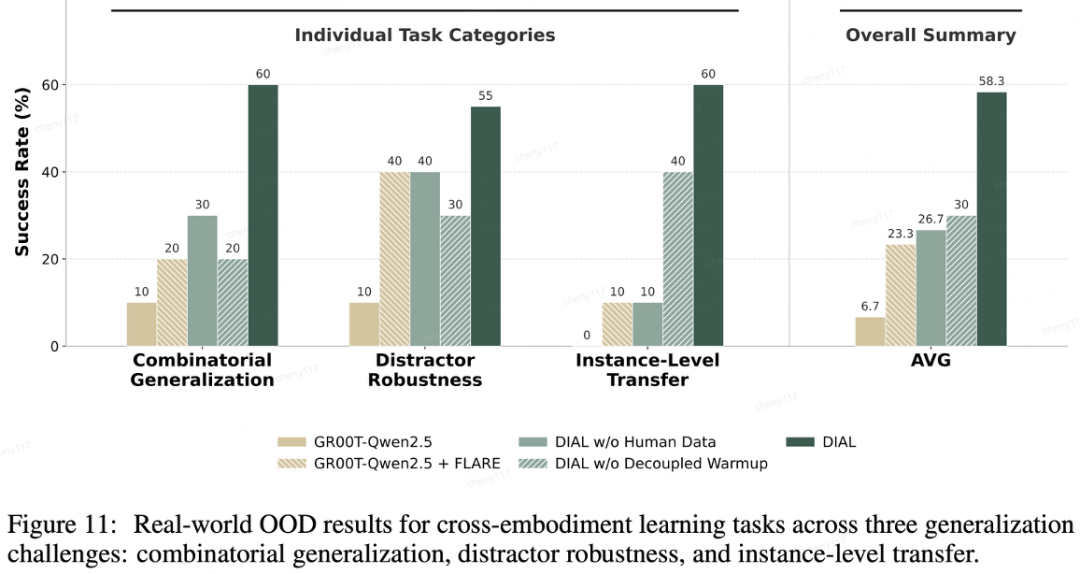
这一对比充分证实:通过吸收跨具身的人类操作数据,是帮助模型建立稳健物理常识、提升泛化上限的有效路径。
可解释性:验证隐式预见的有效性
为了理解System-2(大脑)与System-1(小脑)之间究竟传递了怎样的信息,研究人员利用PCA(主成分分析)降维,对隐式特征进行了可视化分析。

将高维特征映射为RGB颜色后可以发现,System-2预测的特征图(Predicted Foresight)在任务相关区域(如目标物体和目标容器),与真实未来状态(Ground-Truth Future)展现出了高度的结构一致性。
进一步观察特征差异热力图(Predicted Change),预测特征与当前观测特征的差异区域,精确锁定了即将发生物理交互的部位。
这表明,DIAL是真正在其原生语义空间中,生成了一份具有实际物理导向的连贯视觉路线图。
总结与展望
DIAL框架通过可微隐式意图瓶颈,提出了一种解耦认知决策与底层执行的VLA新范式。
长远来看,DIAL揭示了构建通用底座模型的一条极具潜力的路径:
如果能将这种隐式世界建模机制直接融入VLM的原生预训练任务中,利用海量的互联网人类视频,我们将有望培育出天生具备物理动力学直觉的视觉语言大模型。
这不仅能从底层弥合语义推理与实体控制之间的鸿沟,更为具身智能提供了一个真正理解物理规律的认知底座。
以此为基础,DIAL的解耦设计为这种演进提供了一条高度模块化的迭代路径。
在这种即插即用的范式下,一旦底层动作专家训练成熟,未来就可以随着VLM能力的进化而无缝升级机器人的大脑,而无需重训复杂的运动管线。
这种模块化的协同,将为构建新一代通用、可扩展且持续进化的具身智能体铺平道路。
项目主页:https://xpeng-robotics.github.io/dial/
代码下载:https://github.com/xpeng-robotics/DIAL
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢