

请索引第98篇论文
 |  |
AI正在"数字孪生"生命的基本单元
01 为什么这篇论文值得你认真读?
如果你做 GNN / 几何深度学习 / 生成模型 / 基础模型,并且一直在寻找那个"下一个NLP级别"的落地方向——这篇Cell Perspective给出的答案是:细胞。不是抽象的数学对象,而是活生生的、多尺度的、带噪声的、非平衡的、真正复杂的生物信息系统。
这篇由 Stanford、EPFL、CZI、Arc Institute、Microsoft Research、Google Research 等机构联署的Perspective,提出了一个极其宏大的愿景:
构建一个 AI Virtual Cell(AIVC)——一个基于大规模神经网络的"通用细胞模拟器",它能学习从分子→细胞→组织的统一表示,并在其中做 in silico 实验(计算机里的"培养皿")。
这不是传统的基于ODE/PDE的机制建模(那是老派whole-cell modeling的路子),而是一篇旗帜鲜明地站在数据驱动+基础模型立场上的宣言书。
02 一句话概括AIVC:它到底想干什么?
论文给出了一个非常清晰的定义:
AIVC = 一个 learned simulator,用多尺度、多模态的 foundation model,把"细胞状态"压进一个连续的 embedding space(Universal Representation, UR),然后用神经网络模块(Virtual Instruments)在这个空间里做操作和解码。
拆开来看,AIVC要做三件事:
核心能力 | 做什么 | 为什么难(也是机会所在) |
|---|---|---|
Universal Representation (UR) | 把跨物种、跨条件、跨模态(转录组/蛋白组/图像/空间组学…)的生物数据映射到同一个连续向量空间 | 异质性爆炸 + 技术噪声与真实生物学信号纠缠 + 不同平台间batch effect |
预测细胞行为与机制推断 | 给定当前细胞UR,预测扰动后"下一个状态"(分化、药物响应、突变致瘤…)并反推可能因果通路 | 细胞是非平衡动力系统,时间尺度横跨ps到数十年,组合扰动空间指数爆炸 |
In Silico 实验 + 指导数据生成 | 用"虚拟仪器"(VI)在UR空间里做computational screening,输出"下一步该做哪个湿实验"的active learning策略 | 需要校准置信度/不确定性,否则就是"幻觉式生物学" |
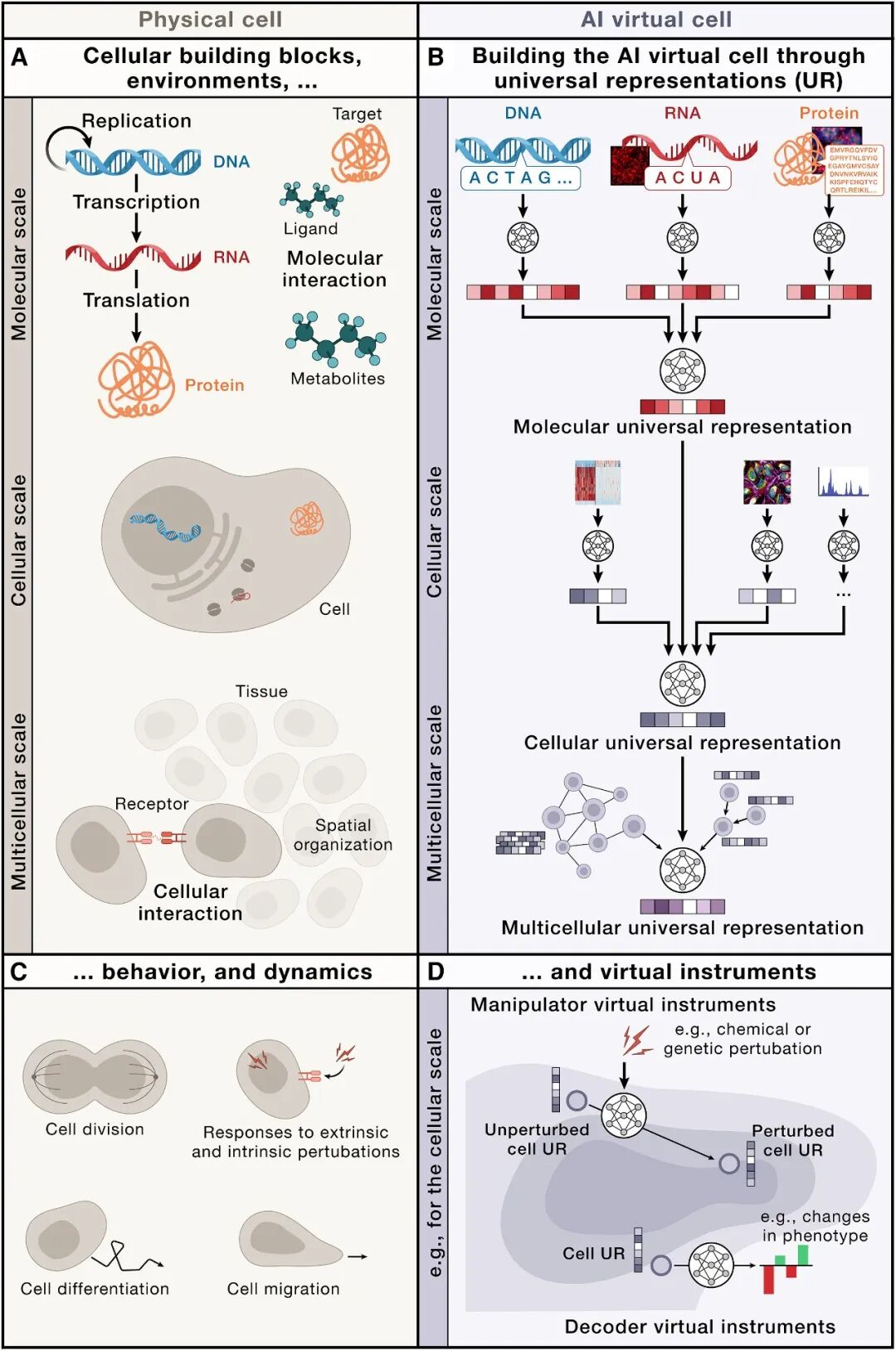
03 架构全景:三层物理尺度 × 两种虚拟仪器
这是全文最核心的骨架。论文用一张对比表把物理细胞的层级与AI虚拟细胞的镜像设计对齐:
表1:物理细胞 vs. AI虚拟细胞——层级映射关系
物理细胞的层级 | 物理世界中发生了什么 | AIVC 中对应的设计 |
|---|---|---|
分子层 (Molecular) | DNA→转录→RNA→翻译→蛋白→代谢物;分子间相互作用、PTM、凝集 | Molecular UR:将序列(nt/aa)或原子结构编码为embedding;可用生物LLM / 原子级GNN / equivariant networks |
细胞层 (Cellular) | 分子在亚细胞位置聚集形成功能;形态、信号网络、转录状态 | Cellular UR:聚合分子UR + 定量(scRNA-seq/scATAC/蛋白组)+ 空间定位 + 影像特征 → 统一细胞状态embedding |
多细胞层 (Multicellular) | 细胞通过空间邻近通信组成niche → 组织 → 器官;TME微环境 | Multicellular UR:将空间转录组/成像数据组织为graph或point cloud,用GNN/ ViT提取组织级embedding |
然后,Virtual Instruments (VI) 分两类操作这个UR空间:
VI类型 | 输入 → 输出 | 类比 | 典型例子 |
|---|---|---|---|
Manipulator VI(操纵器) | UR → UR'(扰动后的新状态) | "virtual pipette / CRISPR / drug" | 化学/遗传扰动→预测细胞状态转移;可用conditional diffusion / flow matching / neural optimal transport |
Decoder VI(解码器) | UR → 人类可读输出 | "virtual microscope / FACS readout" | 预测细胞类型标签、合成显微图像、表型、药物响应曲线 |
关键洞察:因为所有VI共享同一套UR,它们可以组合、复用、社区共享——就像你写一个PyTorch module然后pip install一样。这暗示了一个open-source ecology:任何人都能挂自己的VI到公共AIVC backbone上。
04 深入到每一层:对你做AI的启示
4.1 分子层 —— 生物序列 = 另一种"语言",但别太迷信纯LLM
论文直言不讳:DNA/RNA/蛋白作为字符序列,天然适合Transformer-based LLM(DNABERT, ESM, Evo等等)。但它也警告:
序列 ≠ 全部分子实体。糖基、脂质、小分子代谢物、金属离子……不一定能塞进token串
原子级建模(AlphaFold/RoseTTAFold All-Atom路线)更普适但算力吃紧、动态构象仍难
所以务实路线:sequence-based UR做主干,原子-level做精修/特定模块
对你做AI的启发:如果你在想"我的GNN/Transformer还能pretrain在什么新domain上"——生物序列+结构联合预训练仍然严重under-explored,尤其是跨分子类型的统一tokenizer。
4.2 细胞层 —— 这里是多模态融合的主战场
单个细胞的状态 = 一串基因表达 × 染色质可及性 × 蛋白丰度 × 亚细胞定位 × 形态。
论文给出的技术拼图:
模态 | AI工具 | 痛点 |
|---|---|---|
scRNA-seq / scATAC | Transformer / autoencoder (scVI系谱) | dropout、稀疏、批次效应 |
成像(形态、荧光) | CNN / Vision Transformer / MAE-style self-supervised | 光学差异、光照、染色协议异构 |
空间组学 | GNN over spatial graph + 跨模态对齐 | 分辨率-通量权衡、配准 |
本质上就是一个 multi-view representation learning + cross-modal alignment 问题——这正是近几年ML顶会(NeurIPS/ICLR)里最活跃的方向之一,只不过这里的"view"不是RGB和Depth,而是 reads count matrix 和 显微镜像素。
论文特别提到一个优雅想法:用 cell morphology(可低成本获取) 预测/补全 transcriptome(昂贵)——这本质上是 cross-modal imputation / retrieval,也是你可以用对比学习(InfoNCE)直接上手的任务。
4.3 多细胞层 —— GNN人的主场
到了组织尺度,细胞之间的空间关系自然形成图:
节点 = 一个细胞的UR embedding(基因表达/蛋白marker)
边 = 空间邻近 / 已知ligand-receptor通信
论文明确点名:GNN和equivariant networks是这一层的workhorse。
任务 | GNN怎么用 |
|---|---|
识别TME niche | 消息传递捕获邻域上下文 → 发现"免疫排除型"vs" inflamed"空间模体 |
细胞-细胞通信推理 | 边特征 = 距离/接触面积/L-R pair score;node更新=接收邻居信号 |
组织级状态预测 | 全局readout(sum/attention pooling)→ 肿瘤进展/纤维化评分 |
如果你lab在做 GNN for spatial data,这篇论文等于给你一份从Cell级背书的应用场景清单:空间转录组 + GNN = 最接近"可规模化落地"的交叉切口。
05 Figure 1 解读:AIVC的三大能力环(论文的核心主张图)
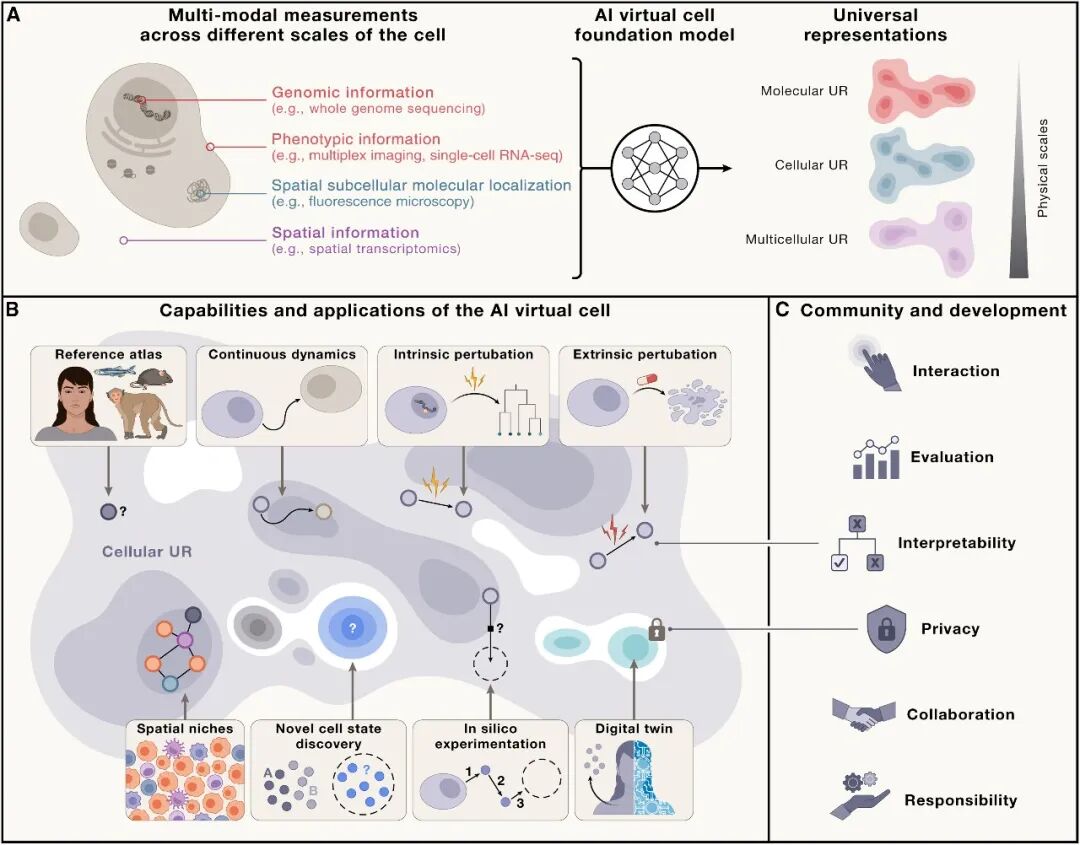
论文用Figure 1勾勒了AIVC能力的逻辑闭环,我们把它转述为三段:
(A) 通用表示 UR —— "把一切变成同一个latent"
UR 可以从不同物种、不同条件、不同模态得到。今天你给它scRNA-seq,明天给它空间蛋白+ H&E,后天给它活细胞延时摄影——全投影到同一空间。
这意味着UR不只是embedding,它是跨数据集的统一坐标系统(很像HuBMAP/ CZ CELLxGENE想做但没有用foundation model做的事)。
(B) 预测 + 动力学 —— "从快照推轨迹,从UR推干预"
UR空间里你可以:
插值与外推:已知巨噬细胞炎症态A和B → 预测从未见过的微胶质炎症态
动力学建模:diffusion / flow matching 在UR空间里学 vector field(细胞状态转移的连续流)
反问题:给定目标状态(如"健康β细胞表型"),反推需要的perturbation组合
这就是论文所说的:AIVC把假设生成从"做一次实验再想"变成"在潜空间里穷举 → 只做实险率最高的几个"。
(C) 可用性三层面 —— 开放科学的现实检验
层面 | 要求 |
|---|---|
个体 scientist | open license + 算力民主化;用LLM agent做自然语言查询接口 |
科学共同体 | 超越narrow benchmark的评估;community-driven迭代 |
社会 | 敏感数据隐私(医院数据/个人基因组) |
这一段其实是在提前回应批评:"又一个硅谷大厂把生物数据吸走" 的担忧。
06 Box 2 的四个"未来故事"——帮你向老板/审稿人讲清楚Why Care
论文用四个应用 vignette 来具象化AIVC的价值:
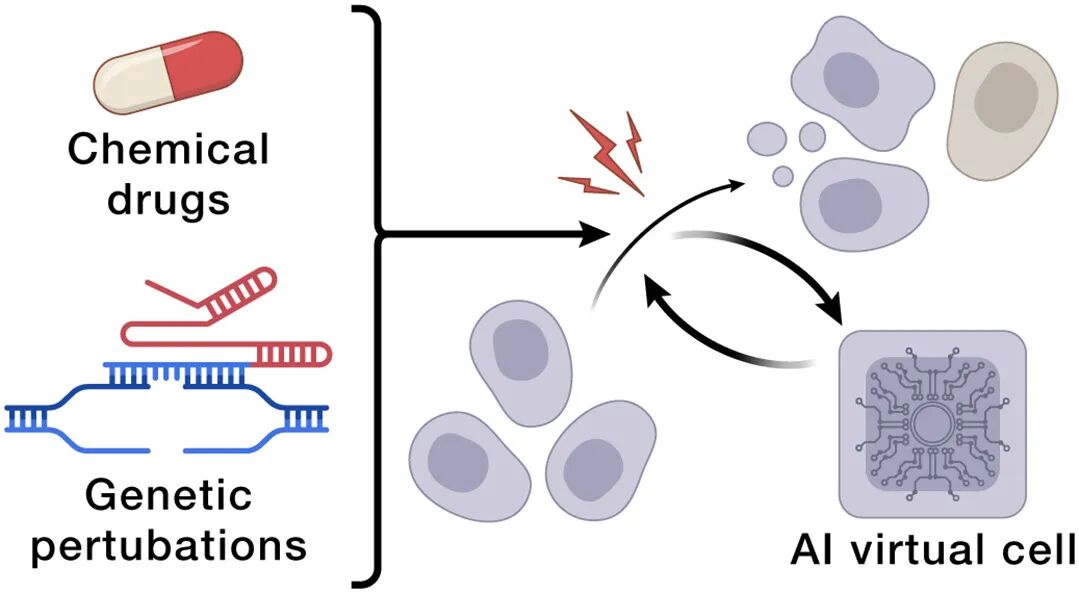
场景1:表型药物发现 & 细胞治疗工程
传统靶点-centric筛选忽略疾病背景下的全细胞状态
AIVC可以做 virtual phenotypic screen:在silico试不同干预组合×不同病人profile
胰岛β细胞例子:simulate驱动分化→cloak from immune→维持功能,指导工程或in situ编辑
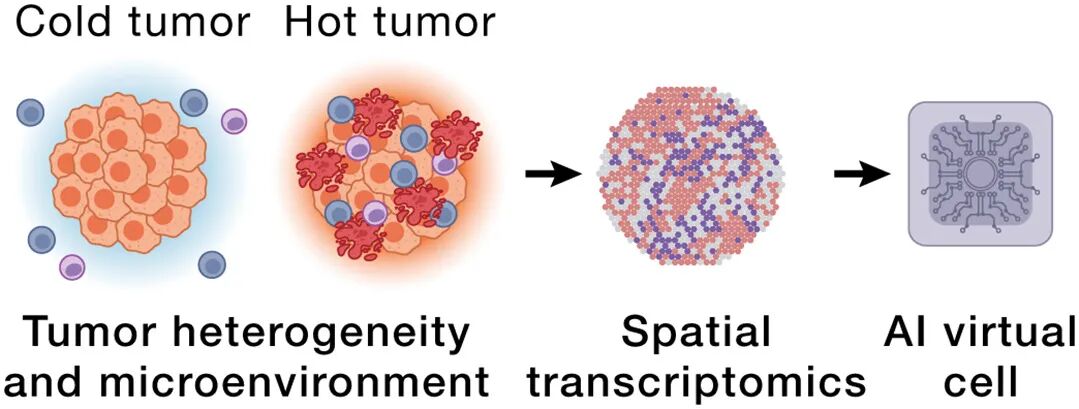
场景2:空间生物学×癌症——泛癌TME框架
肿瘤微环境的空间niche决定免疫逃逸
AIVC跨多个癌种学shared niches → 旧药新用(找相似态→迁移已有治疗方案)
加上肿瘤测序→不只看表达变化,还model 功能变化(LoF / PTM / PPI rewiring)
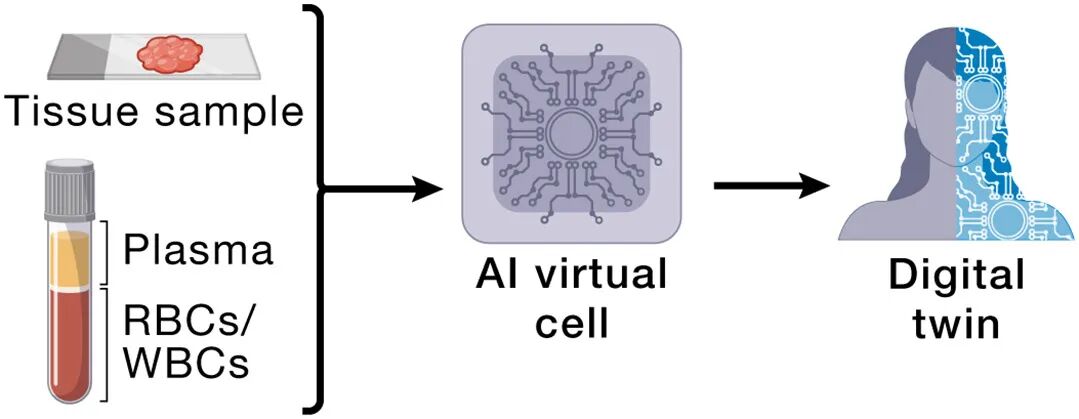
场景3:个体化诊断的数字孪生
每个人有personalized AIVC实例:基因序列 + 外周血sc-profile + 病理影像 + EHR
周期性更新(liquid biopsy transcriptomics作cheap update signal)
甚至用可采样细胞(血/皮)推断不可采样细胞(胰岛β/神经元)——这是UR跨模态对齐的直接红利
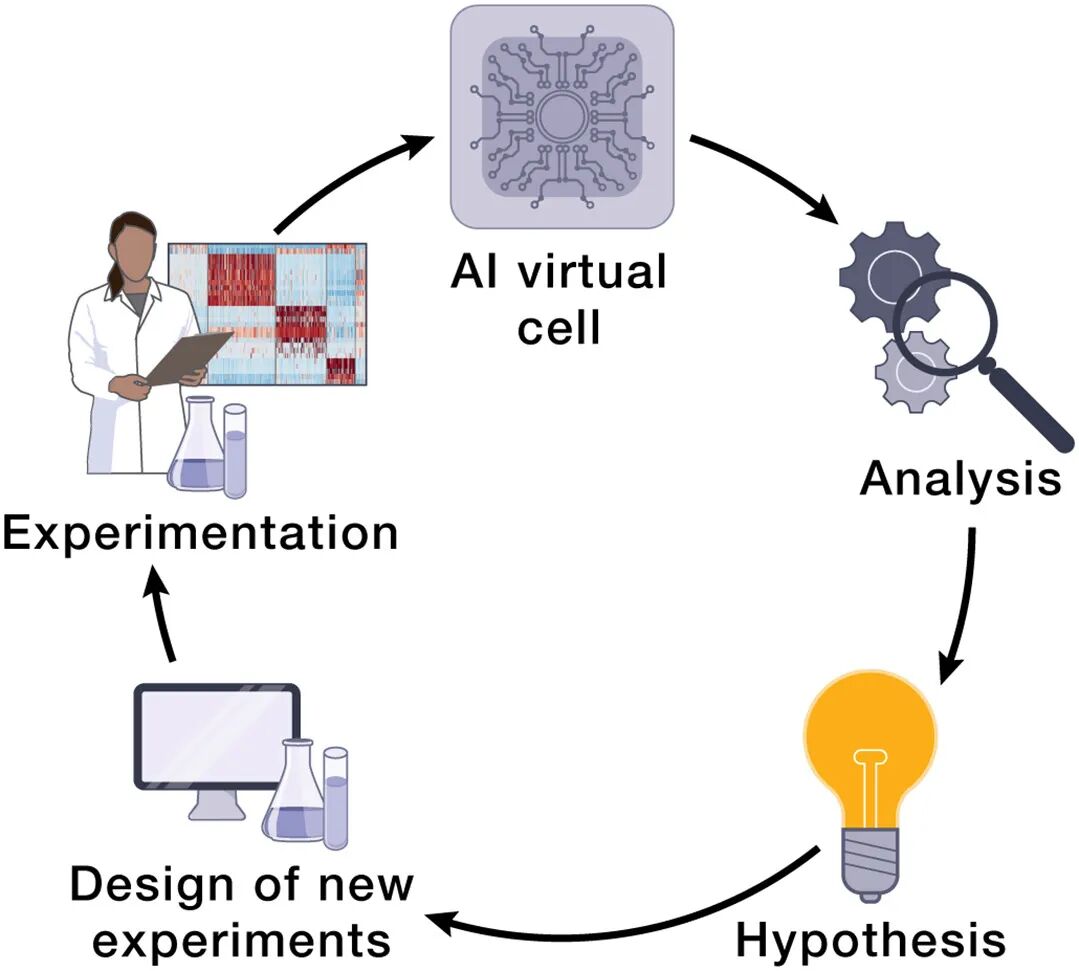
场景4:假设生成的主动学习闭环
传统:experiment → analyze → hypothesize
AIVC模式:explore vast hypothesis space in silico → 挑information gain最大的实验 → lab-in-the-loop迭代
终极愿景:self-driving lab for cell biology
07 他们没回避的硬骨头:数据、评估、可信度
7.1 数据需要多少?
论文给了冷冰冰的数字:SRA(Short Read Archive)已经 >14 PB,是ImageNet的千倍以上——但大量冗余。核心瓶颈不是"更多数据"而是:
瓶颈 | 具体表现 |
|---|---|
多样性 > 体量 | 人/小鼠/E.coli极不均衡;性别/祖先/疾病亚型偏置 |
跨平台标准化 | scRNA-seq protocol A ≠ protocol B,更别说跨模态对齐 |
时间分辨率 | 大多数据是静态snapshot;动力学需要timelapse / lineage tracing |
组合扰动 | 双敲/三敲的组合空间炸掉,必须靠active learning而非穷举 |
7.2 怎么评估一个"虚拟细胞"?
这是最深的问题——不是accuracy of one prediction,而是generalizability + 是否真的帮人发现新生物学。
论文建议的benchmark方向:
Cross-modal reconstruction:给形态 → 预测未见细胞的基因表达(反之亦然)
Out-of-distribution extrapolation:新细胞类型/新物种/新分子(定义"分布边界"本身就是开放问题)
最终判据:产生可验证的实验假设(phenotype那类能在bench上测的)
7.3 可解释性——不做黑盒怎么做科学?
论文的态度很诚实:
我们可能放弃fully mechanistic的精确重建(那需要第一性原理+参数你永远测不到),但可以通过modular结构 + multi-scale wiring分析来锚定可检验的因果因子集——把搜索空间缩小,让wet lab去验证。
这条路线上,attention weight / gradient attribution / concept activation vectors / causal discovery on the graph——都是可以嫁接的技术。
08 Box 3 速览:AIVC技术栈一览(给AI人快速索引)
架构 | 最适合的生物学对应 | 论文中的角色 |
|---|---|---|
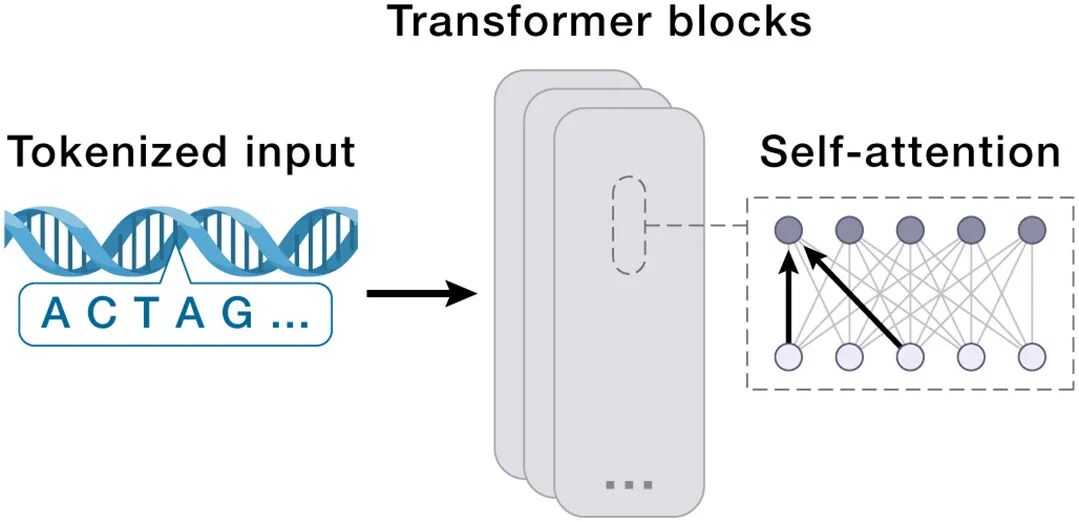 | ||
Transformer | 生物序列(DNA/RNA/aa);也用于cell-as-bag-of-genes(per-token = RNA molecule / gene) | molecular UR的主力;加position encoding处理序列依赖 |
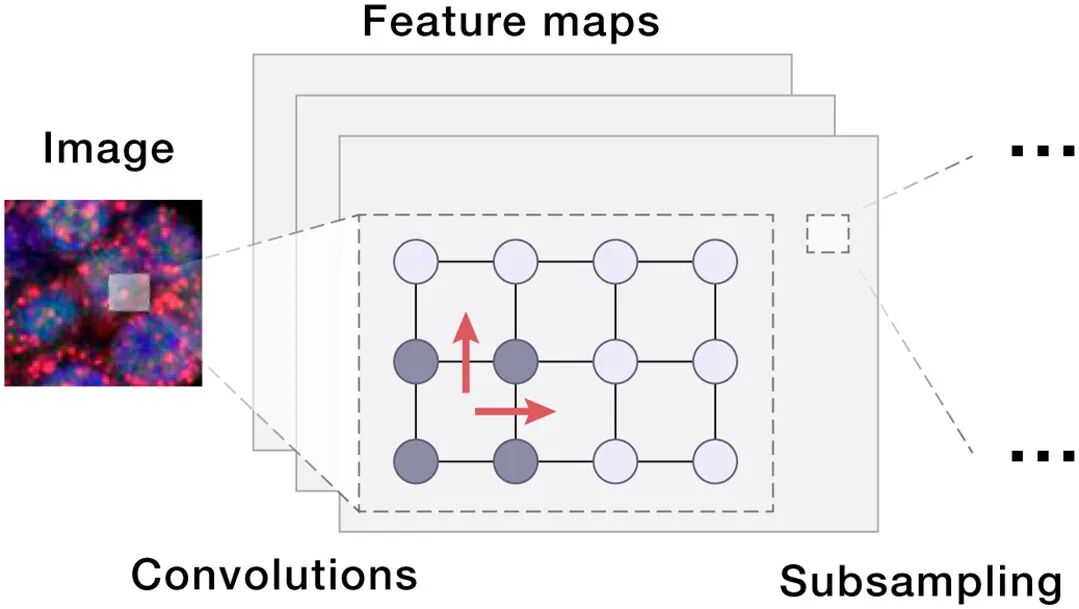 | ||
CNN / ViT | 显微图像(荧光/H&E/活细胞成像);多通道复用成像 | 细胞形态→embedding;也可当decoder VI合成虚拟图像 |
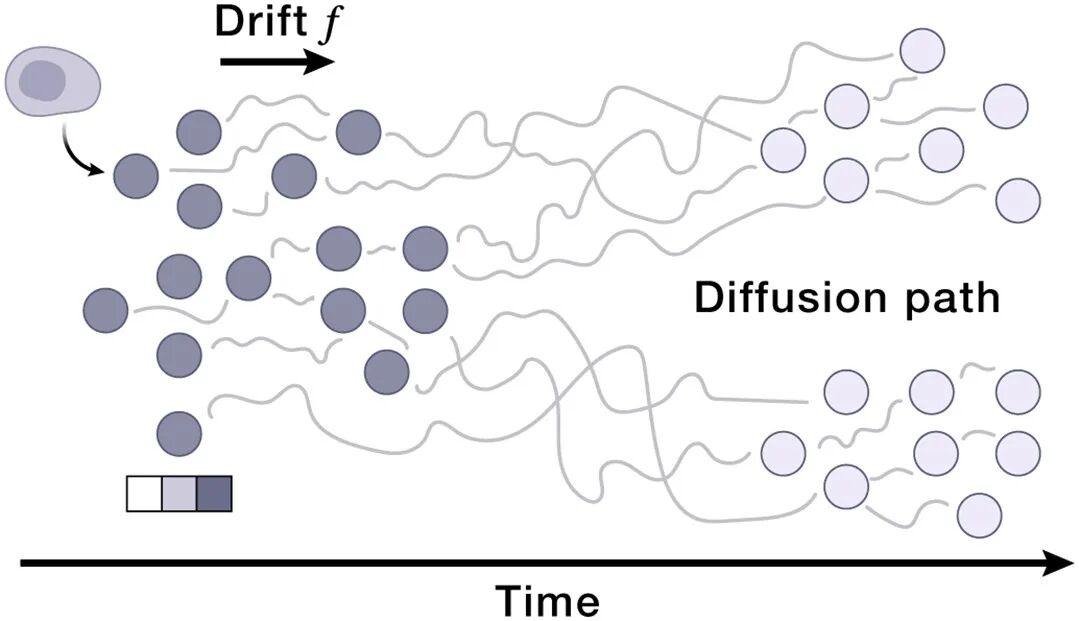 | ||
Diffusion Flow Matching | 细胞状态分布的连续演化(分化轨迹、扰动响应分布) | manipulator VI的核心:条件生成 UR'|perturbation |
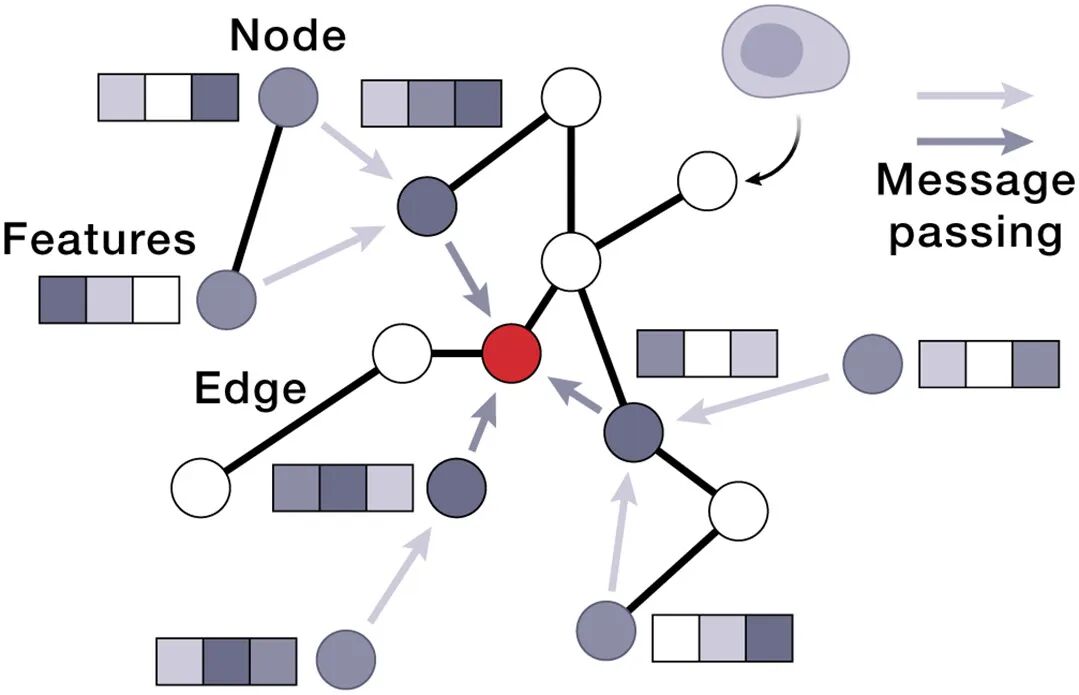 | ||
GNN | 空间邻接图(细胞-细胞);分子结构图(残idue-level) | multicellular UR + 空间niche发现 |
09 批判性视角:乐观在哪里,风险在哪里?
为什么现在可行(而10年前不行)
以前缺什么 | 现在有什么 |
|---|---|
数据量 | scRNA-seq爆炸(百万级细胞公开)、CZ CELLxGENE、Human Cell Atlas、空间组学起飞 |
模型 | Transformer扩展律验证、扩散模型成熟、GNN/equivariant nets标准化 |
算力+生态 | GPU/A100/H100; PyTorch; 开源单细胞工具链 |
但仍需警惕
Correlation ≠ Mechanism:高保真预测≠理解。论文知道这点,但社区压力会倾向于"把它当oracle"
数据偏差制度化风险:如果训练语料以欧美、富裕机构样本为主,AIVC的"通用"可能是伪通用
过度参数化的诱惑:用100B参数memorize 14PB组学数据 ≠ 学到可泛化生物规律
评估鸿沟:benchmarks比Kaggle难一万倍,因为ground truth常常是另一个同样有noise的实验
10 给你的Actionable Takeaways
如果你是这个公众号的核心读者——AI方向本硕博 / 交叉学科老师——这篇论文至少给出三条可执行的research angle:
Angle 1:把你的GNN/Transformer/Diffusion经验"移植"到组学数据
空间转录组的 graph construction + message passing 设计空间还很大(adaptive edges? physics-informed priors?)
跨模态对齐(表达↔图像)用 contrastive / optimal transport(论文本身就cites neural OT和Gromov-Wasserstein方向)
Angle 2:Uncertainty Quantification = 决定AIVC能否上bench的关键
Deep ensemble / conformal prediction / Bayesian NN
论文专门提了:没有uncertainty就没有active learning,没有active learning就只是"炫技生成"
这是ML方法论贡献可以直接改变生物学实践的少有机会
Angle 3:Open infrastructure > 单篇SOTA
论文最后一节几乎是呼吁:"我们需要的是CERN式协作,不是各自刷private榜。"
如果你在考虑长远影响力——参与/共建 open AIVC backbone + benchmark suite,可能比发一篇method-only paper更有复利。
交叉之火最有意思的地方,不在AI吃掉生物,而在两者互相逼迫对方变严格。
AIVC的赌注是:细胞可以被"潜空间化"——而一旦成功,bench biologist和算法工程师说的就是同一种语言。
如果你对文中某个模块(比如"用GNN做空间转录组的具体pipeline""flow matching在UR空间的推导细节""conformal prediction给perturbation prediction做uncertainty")想继续深挖,欢迎留言,我们可以拆出续篇做code-level的技术拆解。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢