

ACM SIGKDD Conference on Knowledge Discovery and Data Mining(KDD) 是数据挖掘与数据科学领域历史最悠久、影响力最高的国际学术会议之一,由美国计算机学会(ACM)旗下 SIGKDD 专业委员会主办,被中国计算机学会(CCF)列为 A 类推荐会议,长期受到学术界与工业界的广泛关注。它不仅是学术界理论突破的展示台,更是工业界技术落地的试金石。
KDD 2026 将于 2026 年 8 月 9 日至 13 日 在韩国济州国际会议中心(ICC Jeju)举行,本届会议延续了其一贯的高水准,设置 Research Track、Applied Data Science(ADS)Track、Dataset and Benchmark Track以及AI for Science Track四大核心赛道,全方位探讨数据智能的新边界。

在这一全球瞩目的舞台上,淘天集团再次展现了其在工业场景的深厚积淀与创新活力,此轮累计有十数篇论文在ADS Track、Research Track以及Dataset and Benchmark Track赛道被接收。
此次精选了来自电商核心业务场景实践的13篇论文,见证在大模型、强化学习、世界模型等技术驱动下,业务链路的重塑与范式革新,探讨新时代下工业界智能化升级的新解法、新趋势以及新形态。
接下来,我们也会邀请核心作者来详细解析背后的论文思路和技术成果,欢迎关注~
一、架构创新实现大模型时代下电商核心链路的智效合一
大模型时代下,工业场景也渴望引入大模型(LLM/Transformer)的Scaling Law(规模效应)或深度推理能力(CoT/生成式)。然而真实在线环境对算力成本和毫秒级延迟有着严苛约束。一个共同的问题横亘于此:如何在不牺牲线上推理速度的前提下,最大化地释放大模型或复杂推理架构的性能红利?而以下四篇工作共同揭示了一个关键趋势:大模型在电商领域的落地,正走向更深层次的架构创新。通过架构创新来实现性能与效率的平衡,解决工业界“算力受限”与“追求 Scaling Law"之间的矛盾。
1、TaoSR1:电商搜索LLM落地新范式,兼顾深度推理与低延迟部署
《TaoSR1: The thinking model for e-commerce relevance search》
Track:ADS Track
论文链接:https://arxiv.org/abs/2508.12365
痛点:传统BERT模型在电商搜索中缺乏复杂推理能力,以及现有大语言模型(LLM)方案多局限于知识蒸馏而难以直接线上部署。
解决方案:本文提出了一种名为TaoSR1的优化框架。为克服在线部署延迟、思维链(CoT)错误累积及判别幻觉等实际挑战,该框架创新性地采用了三阶段优化范式:首先通过结合CoT的监督微调(SFT)激发模型对复杂搜索意图的深度推理能力;其次,利用基于Pass@N策略的离线多次采样结合直接偏好优化(DPO),显著提升模型的偏好生成质量;最后,引入基于难度的动态采样与群体相对策略优化(GRPO)相融合,进一步有效缓解了模型的判别幻觉问题。此外,为了突破线上推理的计算耗时瓶颈,研究团队独创了“后置CoT处理”与“基于累积概率的相关性分档”策略,成功实现了LLM的高效在线部署。
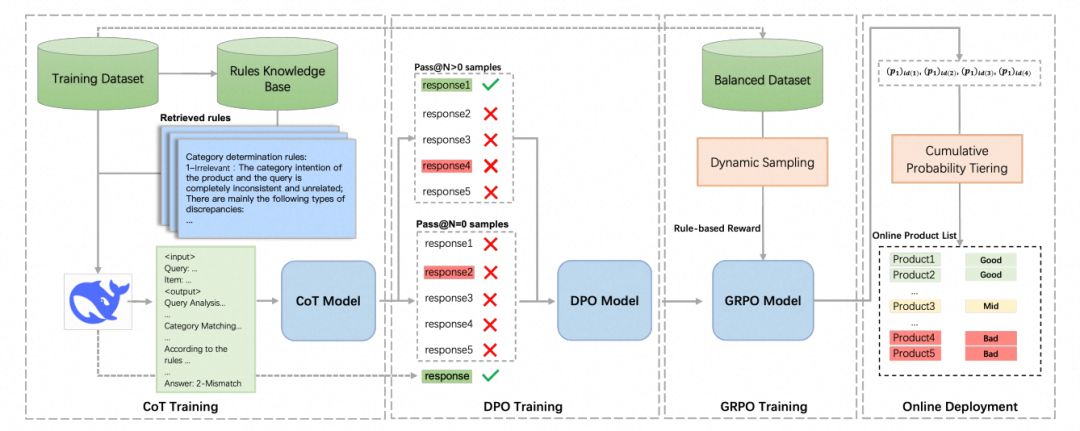
实验结果:TaoSR1不仅在极具挑战性的离线评估数据集上显著超越了现有的基线模型,而且在线上实际业务的Side-by-Side人工盲测评估中也取得了大幅的体验提升,该工作为将大模型CoT推理直接应用于传统分类判别任务提供了一套极具工业参考价值的强化学习对齐新范式。
2、用于电商Query推荐的端到端混合生成架构 AIGQ
《AIGQ: An End-to-End Hybrid Generative Architecture for E-commerce Query Recommendation》
Track:ADS Track
论文链接:https://arxiv.org/abs/2603.19710
痛点:我们的工作面向淘宝首页 HintQ底纹场景,提出了首个端到端生成式框架AIGQ,系统性破解传统方法中浅层语义、冷启动与新颖性不足等核心瓶颈。
解决方案:技术上,AIGQ 在训练范式、策略优化和部署架构三个层面提出创新:(1)IL-SFT(兴趣感知列表级监督微调),通过 Session 级行为聚合与兴趣引导的重排策略,建模细粒度用户意图;(2)IL-GRPO(兴趣感知列表级GRPO),首创双层奖励机制,联合优化单 Query 相关性与列表整体属性,并引入线上 CTR 模型作为奖励信号,实现 Query 粒度的细粒度信用分配;(3)离线-在线混合架构,由近线个性化生成的 AIGQ-Direct 与具备推理能力的AIGQ-Think 协同覆盖召回,满足毫秒级延迟约束。
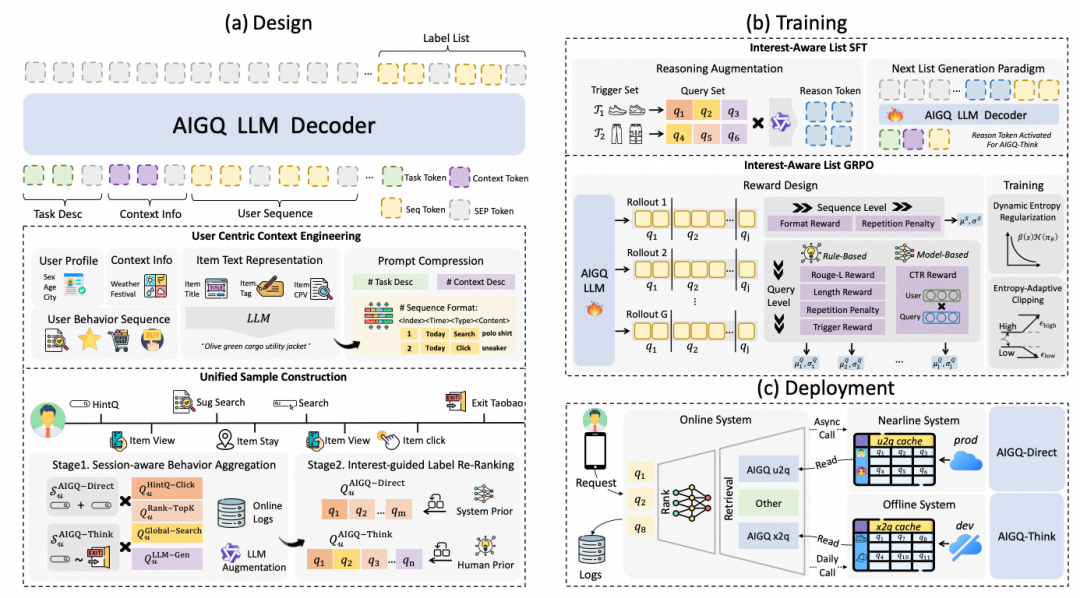
实验结果:离线评测中 AIGQ 在 Cate HR@30、Query HR@30 等指标全面超越 向量召回、Qwen3-30B、Gemini 3 Pro、GPT-5.1 等强基线;线上 30 天 A/B 实验显示,成交笔数 +10.31%、成交GMV +10.68%、UCTR +7.42%、7 日留存 +3.73%,且约 40%的叶子类目为 AIGQ 独有覆盖,充分验证了方案在效率、转化与新颖性上的工业价值。
3、FAT:将 Scaling Law 转化为生产力,工业级预估模型的全量落地实践
《From Scaling to Structured Expressivity: Rethinking Transformers for CTR Prediction》
Track:ADS Track
论文链接:https://arxiv.org/abs/2511.12081
痛点:搜推广预估模型长期困在一个矛盾中:GPU算力持续翻倍增长,但模型加大后效果却增长乏力,根源在于传统模型由碎片化的结构拼接而成,GPU有效利用率长期停滞在个位数。标准Transformer也难以直接套用——它依赖语言的有序序列语法,而预估模型输入本质是数百个异构字段的组合语义,不加区分地自由交互会引入大量噪声,算力投入无法兑现为确定性的效果提升。
解决方案:FAT的核心思路是让Transformer从底层理解“字段语义”——每个特征属于哪个字段、字段之间该如何交互。它重新设计了两个核心组件:一是字段感知的注意力机制,为每个字段分配独立的投影矩阵,并通过轻量门控精准调控跨字段信息流,强化关键通路、抑制噪声;二是基组合超网络,通过共享基底动态合成字段专属参数,参数量降低超99%且无额外推理成本,新字段接入只需学习轻量路由,无需重新训练全量参数。整个计算流高度规整,天然适配现代GPU的张量计算特性。
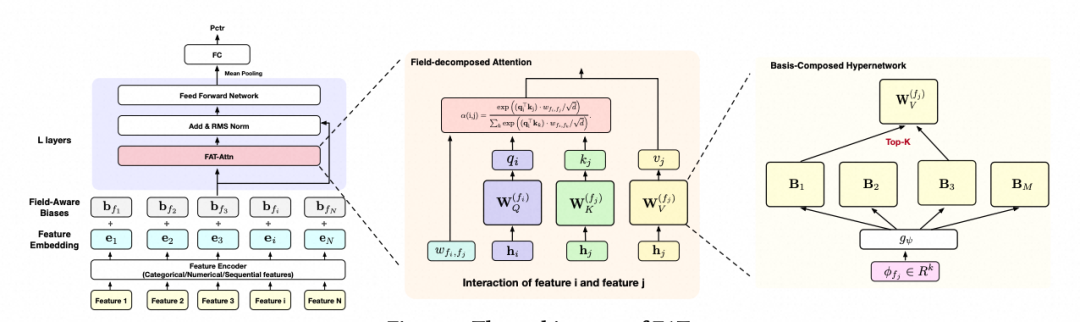
实验结果:离线AUC显著提升,Scale up至2B规模仍然有持续性收益。目前在阿里妈妈主场景全量落地两期,累计贡献CTR +8%,MFU从个位数飙升至30%+,真正打通了“投入算力即产出效果”的高效转化路径,实现确定性规模化增长
4、面向高效扩展的统一建模点击率预估模型
《EST:Towards Efficient Scaling Laws in Click-Through Rate Prediction via Unified Modeling》
Track:ADS Track
论文链接:https://arxiv.org/pdf/2602.10811
痛点:工业场景中的点击率(CTR)预估模型希望像大语言模型一样,能够随着模型规模扩大持续获得性能收益,但在真实落地中却受到严格的时延与算力约束。现有方法通常通过对用户行为进行提前聚合来控制计算成本,往往只实现了“局部统一建模”,难以充分释放规模化建模的潜力。
解决方案:论文提出了EST(Efficiently Scalable Transformer)框架,重新审视CTR预估任务与LLM在建模对象上的关键差异:一方面,行为特征与非行为特征之间存在明显的信息密度不对称;另一方面,多模态内容信号具有不同于ID特征的结构化先验。基于这两点观察,作者设计出一种面向工业CTR预估任务的高效可扩展统一建模架构。EST将用户行为以及非行为特征统一组织到同一序列中进行建模,同时有针对性地规避高成本、低收益的冗余交互。
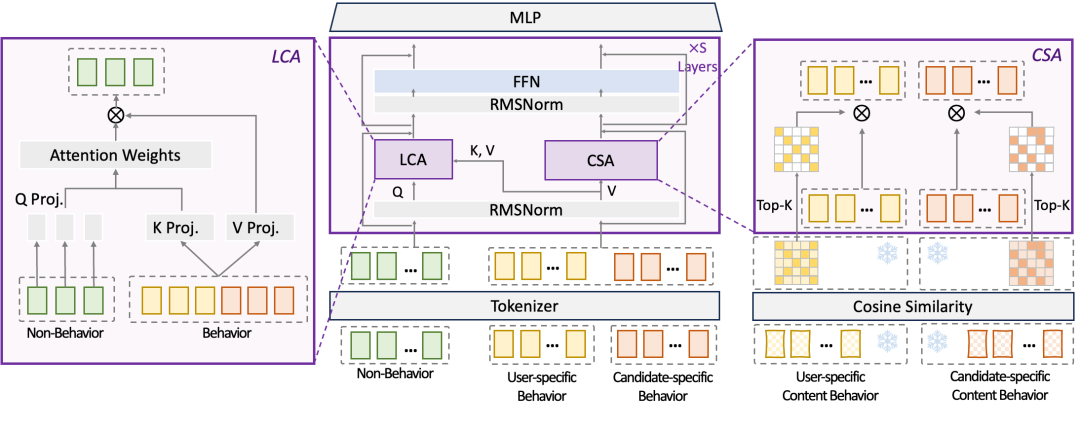
该方法包含两个核心模块:一是Lightweight Cross-Attention(LCA),以非行为特征作为Query,重点建模其与行为序列之间最关键的跨特征交互,从而显著削减冗余的自注意力计算;二是Content Sparse Attention(CSA),利用图文等内容特征的相似性作为关系先验,动态筛选高价值行为,并进行稀疏注意力建模,以较低的计算开销提升多模态信息利用效率。
结果表明:EST在淘宝真实推广数据上展现出稳定的幂律Scaling规律,即随着模型参数规模和计算量增加,模型性能能够持续、可预测地提升。在线A/B测试中,EST已成功部署于淘宝相关平台,在全站推核心场景中带来了1.22%的CTR提升和3.27%的RPM提升,验证了其在大规模工业CTR预估中的实际业务价值。
二、从被动响应到主动推理:AI驱动下一代商业决策系统
传统商业决策系统长期受困于‘黑盒优化’与‘被动响应’的范式瓶颈:推荐系统依赖隐式反馈难以洞察用户真实意图,定价与出价策略因缺乏长周期视野而陷入短视博弈,且底层拍卖机制往往滞后于动态估值更新,制约了系统整体效率。本次选取的几篇突破性工作( RecBot、AIGP、LOGIC、两阶段拍卖机制、生成式世界模型),揭示了工业界决策智能正从基于历史数据的统计拟合,迈向具备‘主动交互、可解释规划、长期价值对齐’的新一代智能架构。
1、交互式推荐流:双智能体框架RecBot捕捉用户真实意图
《Interactive Recommendation Agent with Active User Commands》
Track:Research Track
论文链接:https://arxiv.org/abs/2509.21317
痛点:传统推荐流系统依赖点赞、点击、不喜欢等被动反馈信号,难以精准刻画用户的真实意图,系统也难以对用户反馈进行细粒度属性归因,导致偏好建模失真、信息茧房加剧,用户意图与系统理解间长期存在交互鸿沟。
解决方案:提出全新的交互式推荐流(IRF),支持用户在推荐流场景中通过自然语言指令实时调控推荐策略,将单向推荐升级为双向交互。为支撑该范式,团队设计了双智能体框架 RecBot:
解析智能体(Parser)将用户文本指令解析为「正/负反馈」和「软/硬约束」四象限的结构化偏好,并以「保留—融合—消解」原则维护长程动态记忆;
规划智能体(Planner)负责模块化工具的自适应链式编排,将抽象指令转化为具体可执行函数。此外,借助模拟增强的蒸馏机制,将强教师模型能力迁移至轻量学生模型,实现低成本工业部署。
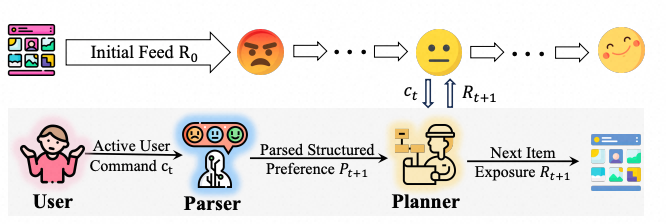
实验结果:在公开和内部私有数据集上,设计单轮、多轮、含兴趣漂移的多轮交互场景,RecBot均达到最优表现。三个月线上 A/B 实验验证了RecBot能够有效降低用户负反馈频率0.71%,点击品类多样性提升1.44%,GMV提升 1.40%。
2、LLM 结合离线 RL 偏好对齐实现可解释的长周期电商定价
《AIGP: An LLM-Based Framework for Long-Term Value Alignment in E-Commerce Pricing》
Track:ADS Track
痛点:围绕电商自营业务的大规模长期定价场景,基于价量预估模型的传统方法与基于强化学习的方法均为黑盒决策,且难以利用商品描述、用户评论等非结构化信息;通用 LLM 虽具备文本理解与可解释推理能力,却缺乏领域知识与长周期奖励监督,易输出短视决策。如何让定价既"讲得清"又"看得远",是工业级 LLM 定价的核心瓶颈。
解决方案:AIGP 基于 LLM Agent 构建定价策略,以思维链推理承担"讲得清"、以离线强化学习驱动的长期价值对齐承担"看得远",两条路径同框协同。
讲得清:采用 LLM-as-Policy 范式,结合 RAG 引入运营经验知识库,在 CoT 推理中融合结构化与非结构化信号,输出可审计的折扣决策;配合 LLM-as-Judge 筛选专家样本,通过 SFT 将教师模型能力蒸馏至可部署的小模型。
看得远:基于离线强化学习训练决策长期价值预估器(LTVE),刻画定价行为在搜推链路中的延迟收益; 以LTVE辅助构造正负样本对驱动 DPO 偏好对齐,为 LLM 策略注入显式的长期价值监督,破解复杂电商市场缺乏可靠仿真器、长期奖励难标注的困境。
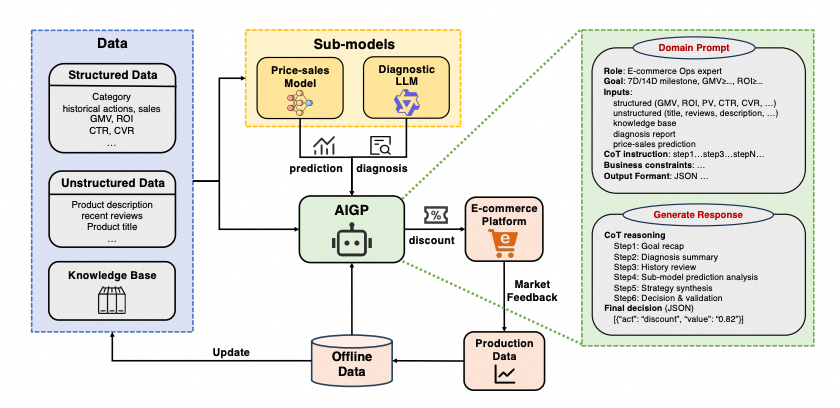
实验结果:大量离线评测与在线实验均表明 AIGP 带来了显著效果提升,在冷启等分布外场景中优势尤为明显。在线上 A/B 测试中,AIGP 相比线上应用策略实现 14 天 GMV +13%、ROI +8%,且定价稳定性显著增强,验证了其在真实电商环境中兼顾长期收益、稳定性与可解释性的综合优势。
3、LOGIC:目标引导+一致性校验,重塑生成式自动出价新范式
《LOGIC: Learning Optimal Goals with an Integrated Critic for Generative Auto-Bidding》
Track:Research Track
痛点:自动出价需在动态博弈中实时决策。传统方法受限于离线分布偏差,探索能力不足;现有生成式方法(如 DT)本质为被动模仿,缺乏主动发现高价值策略的能力,且在动作空间探索时易陷入分布外(OOD)陷阱,导致策略崩溃、性能不稳定,阻碍了算法在工业界多场景下的迁移与应用。
解决方案:提出鲁棒目标引导框架 LOGIC。核心思想是将探索重心从脆弱的“动作空间”转移至鲁棒的“RTG(目标回报) 空间”。借助集成 Critic 主动引导高价值战略目标生成,突破 DT 的模仿局限;利用 DT 固有的行为克隆特性,将 RTG 隐式映射为分布内合理动作,规避 OOD 风险;引入反向一致性校正(BCR)模块,校验生成RTG序列的数学一致性。这种“目标引导+一致性校验”机制,以极简训练动态实现了策略的主动探索与稳健执行。
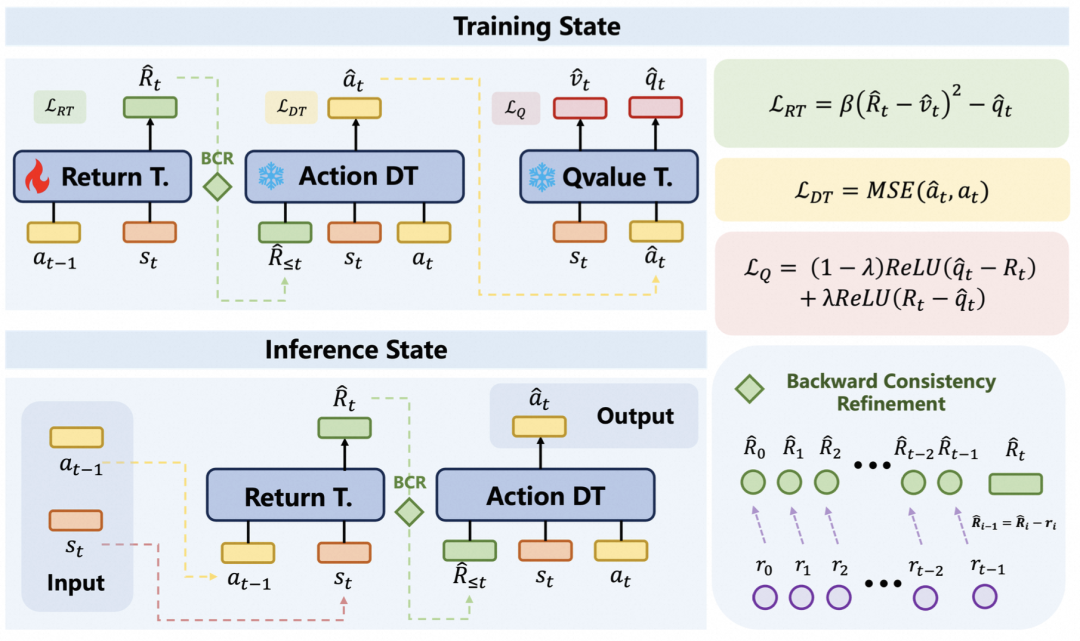
实验结果:在 AuctionNet 基准及在线 A/B 测试中,LOGIC 展现了卓越性能与鲁棒性。即使在零正则化约束下,其得分仍达 38.3,优于动作探索方法 GAVE(37.2),且对超参数不敏感。在线实测显著提升了客户 ROI 与消耗效率,验证了其在真实复杂环境中的有效性与落地潜力。
4、支持出价更新的在线推广两阶段拍卖机制
《Two-Stage Auctions with Bid Refinement for Online Advertising》
Track:Research Track
痛点:在大规模在线推广系统中,为兼顾预测精度与系统延迟,平台通常采用两阶段拍卖架构:第一阶段从海量推广中筛选候选集合,第二阶段再进行精细预测和最终拍卖。然而,现有机制往往只在单一阶段收集实时出价,难以反映客户估值随实时质量预测结果(如 CTR、CVR)更新而变化。若直接允许客户在两个阶段分别提交出价,在缺乏激励约束的情况下,客户可能在筛选阶段虚高报价,从而扭曲候选集筛选并损害整体拍卖效率。
解决方案:提出一类支持出价更新的两阶段拍卖机制。研究发现,为避免客户操纵初始出价,机制需要引入“入场费”来反映进入第二阶段机会的价值。为解决入场费可能破坏事后个体理性的问题,进一步设计了带折扣的动态两阶段拍卖机制,提出基于实现结果的入场费和历史行为约束的激励方案,能够适配工业界常见的排序分数分配规则。
结果表明,该机制能够在近似激励兼容和个体理性间取得平衡,帮助提高拍卖效率,为两阶段出价更新机制的系统部署提供机制设计基础。
5、针对自动出价问题的生成式世界模型,突破传统统计建模范式
《Physics-Informed Generative World Models for Real-Time Bidding: Deriving Statistical Laws from First Principles》
Track:Research Track
痛点: 现有RTB模拟器依赖确定性点预测目标,无法捕捉拍卖数据中方差随均值爆炸式增长的极端异方差性,也忽略了反馈变量之间的结构耦合关系。此外,由于分布的重尾性质,传统统计建模无法利用有限数据分辨出正确的统计分布。
解决方案:论文从拍卖市场的基本公理出发,针对自动出价问题提出了一种生成式世界模型,突破了传统统计建模范式,从拍卖反馈的离散事件生成机制出发,证明竞价反馈的边际分布服从Poisson-lognormal和Tweedie-lognormal规律,并提出零膨胀广义Beta第二类分布作为高效可计算代理。此外,论文发现成本与价值在极端情况下会同时飙升,据此引入归一化流Copula来捕捉这种非高斯的联动关系。
实验结果:在大规模生产数据上,ZI-GB2显著降低了预测损失(SMAPE,CRPS),并且归一化流Copula的NLL显著优于高斯、Student-t和Gumbel Copula;同时模型展现出清晰的Scaling law现象,表明物理先验是释放大模型在该领域潜力的关键前提之一。
三、业务透视镜:电商决策中的多维因果推断与全局增量优化新范式
面对工业界长期存在的“局部有效、全局失真”困局,以下四篇研究构建了全方位的业务透视镜,MAC通过开源多归因基准与算法库,打破了单一视角的认知局限,在数据资源、算法实现上为多归因学习提供社区生态;CanniUplift与M-DLRI分别从“全局挤占去噪”和“多杠杆联合交互”两个维度,引入经济学约束与结构化建模,还原了激励措施的真实边际贡献;而STEAL则巧妙打通了短期实验与长期价值的时空壁垒,利用历史数据校正分布偏移,解决了长期指标难以实时观测的痛点。
1、首个多归因CVR预估基准数据集MAC与配套算法代码库PyMAL开源
《MAC: A Conversion Rate Prediction Benchmark Featuring Labels Under Multiple Attribution Mechanisms》
Track:Dataset and Benchmark Track
开源地址:https://github.com/alimama-tech/PyMAL
痛点: 现有公开CVR预估数据集只提供单一归因机制下的转化标签,难以刻画用户从多次点击到最终购买的复杂转化心智。
解决方案: 开源首个多归因CVR预估基准数据集MAC与配套算法代码库PyMAL,在数据资源、算法实现上为多归因学习提供社区生态。
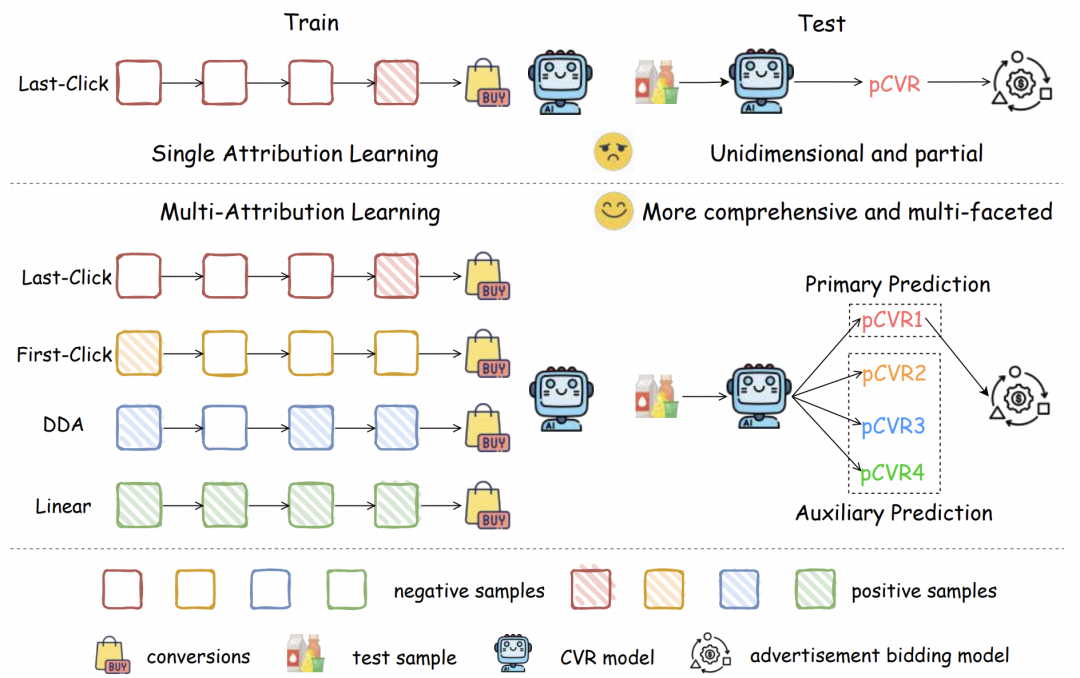
第一,在数据资源方面,本工作开源的MAC数据集为每条点击同时提供 Last-click、First-click、Linear 和 DDA 四类归因机制下的转化标签,使模型能够从不同视角学习用户转化心智,突破现有数据集仅支持单一归因视角的限制。
第二,在软件生态方面,本工作开源 PyMAL 多归因学习算法库,统一实现各类基线方法,支持公平、可复现的实验比较,并为后续研究提供核心洞察:多归因学习在多种目标归因机制下均能稳定提升 CVR 预测性能,尤其对转化路径较长、触点更复杂的用户增益明显;此外,辅助归因目标并非越多越好,不同目标归因机制需要选择合适的辅助视角。
第三,在算法创新方面,本工作提出 MoAE模型,通过 MoE 结构学习多归因知识,并以主任务优先的非对称知识迁移机制服务核心CVR 预测目标。实验结果表明,MoAE 在四种目标归因机制下均优于现有最佳基线,GAUC最高提升0.39pt。
2、电商激励增量预测新框架:全局对齐+核销去噪,破解“局部有效、全局失真”困局
《CanniUplift: A Holistic Framework for Mitigating Seller and Incentive Cannibalization in E-commerce Uplift Modeling》
Track:ADS Track
痛点:电商平台中的优惠券、补贴等激励发放,是提升交易转化和平台收益的重要手段。但传统增量预测方法通常默认“单个激励的效果可以独立归因”,难以应对真实场景中的多 seller 竞争和多激励并存问题:一次转化可能只是从其他 seller 被挤占而来,或由自然需求、并发激励共同驱动,从而导致局部 uplift 被系统性高估,难以真实反映平台净增量收益。这也使得激励策略优化长期面临“局部有效、全局失真”的核心挑战。
解决方案:用户算法团队提出了一种基于平台全局对齐和核销分解去噪的电商激励增量预测框架。该方法从平台级净增量视角重新定义激励归因问题:一方面,通过平台全局对齐约束,将 seller 粒度的局部 uplift 预测与平台整体 GMV 变化联系起来,缓解跨 seller 挤占导致的过度归因;另一方面,利用核销行为对处理后的转化机制进行分解,将更可能由真实激励驱动的转化与自然需求或其他激励引发的转化区分开来,从而提升增量估计的鲁棒性。该方法为复杂场景下的平台级激励优化提供了新的建模思路。
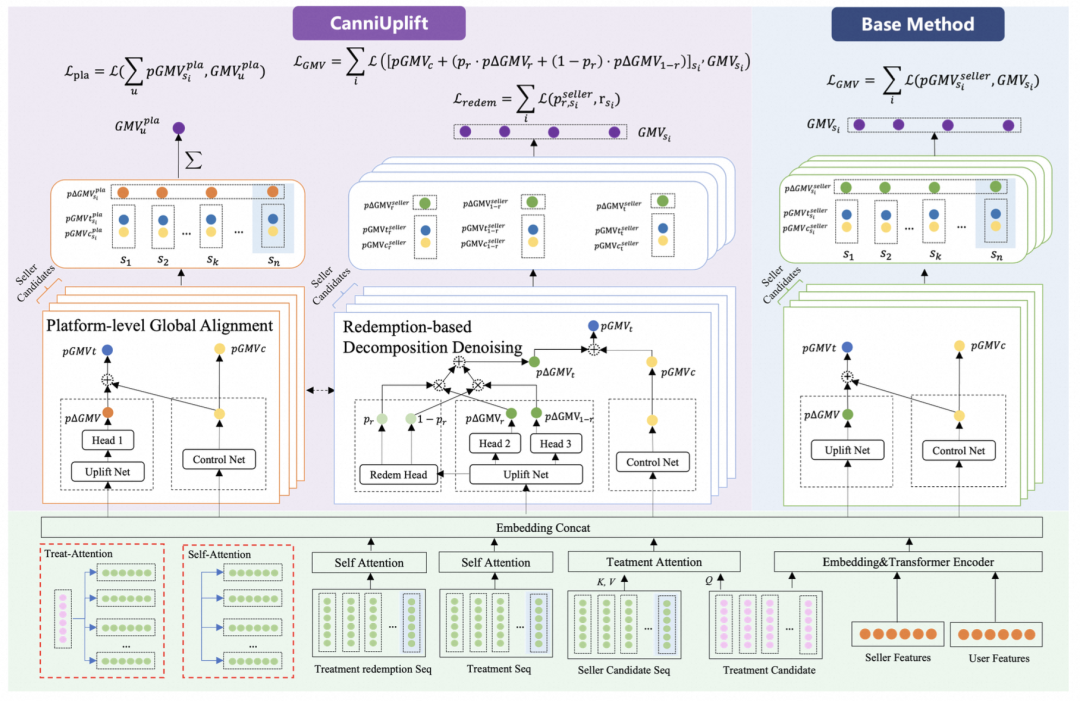
实验结果:该方法在公开数据和真实业务场景中均显著优于多种主流 uplift 基线,在平台级收益对齐、seller/user 粒度排序质量以及在线 A/B 效果上均取得稳定提升。其中,模型在 seller-level 和 user-level AUUC/QINI 等更细粒度指标上持续优于强基线,说明其收益不仅体现在平台总量拟合上,也能够更稳健地支持细粒度激励分配决策。
3、多杠杆联合 Uplift 建模框架 M-DLRI
《Scalable and Traceable Joint Uplift Modeling for Multi-Lever Online Marketing》
Track:ADS Track
痛点: 联盟营销中常需要同时调整商品折扣、C 端补贴、佣金率等多类激励,但不同营销杠杆之间存在复杂联合效应,简单相加难以刻画;若为每种补贴组合单独建模,又会带来参数爆炸和数据稀疏问题。
解决方案: 论文提出多杠杆联合 Uplift 建模框架 M-DLRI。文章设计了一个多激励联合编码层,该模块将单个激励强度的细粒度变化、多激励之间的联合交互,以及“激励增强不应降低响应”的经济学单调约束统一建模;文章同时引入 CP 低秩分解和对数加性门控机制,高效建模多类营销杠杆的联合影响,并支持对各杠杆贡献进行因果归因和可视化追踪。
结果表明: 在合成数据和阿里妈妈真实工业数据上,M-DLRI 均优于 XTNet 等 SOTA 方法;在 15 类处理场景下 Root-PEHE 从 XTNet 的 1.145 降至 0.854。线上 A/B 实验中,该方法带来 ROI +0.86%的显著提升。
4、长短期预估模型 STEAL,利用历史数据为在线短期实验提供长期指标估计
《Offline Long-Term Causal Effect Estimation with Short-Term Experimental Data for Recommendation Systems》
Track:Research Track
痛点:在推荐系统中,长期指标难以在短期 A/B Test 中直接观测,因此通常需要利用短期行为预估长期效果。然而,现有方法仍面临两大挑战:一是策略对短期行为影响较弱,却可能显著影响长期指标,导致评估误差较大;二是长期标签依赖历史数据,而历史与在线实验间存在策略不一致和时间带来的分布偏移问题。
解决方案:长短期预估模型 STEAL,利用历史数据为在线短期实验提供长期指标估计。
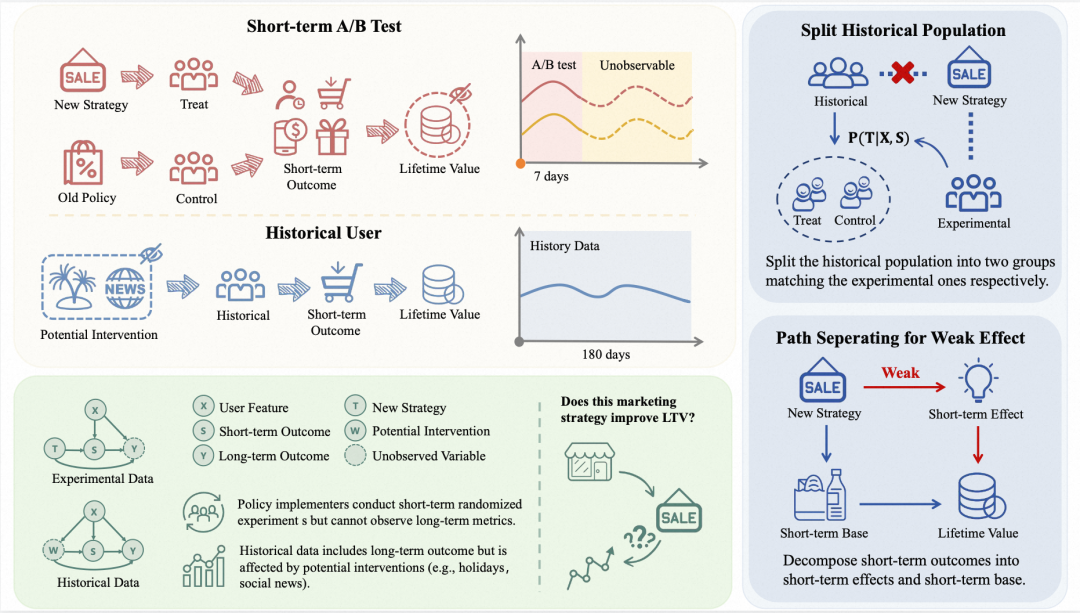
STEAL包含三个关键技术路径:(1) STEAL基于短期行为S的异质性,在历史数据中生成伪策略标签T,以模拟在线实验中的不同策略人群,实现历史与在线数据的对齐;(2) 随后,通过对短期行为路径进行拆分,将策略T对短期结果S的因果效应显式分离,从而提高长期指标Y因果效应的估计准确性;(3) 最后,引入交互注意力机制,进一步增强模型对异质性因果关系的建模能力。
结果表明,在仿真实验中,STEAL 显著降低了 PEHE 指标,说明其能够更准确地估计长期指标的异质性因果效应;在真实 A/B Test 中,STEAL 在整体效果上均优于基线模型,为平台策略评估与决策提供了更可靠的依据。
以上收录论文里有哪些内容是你感兴趣滴,在评论区说出你的想法~没准儿就有机会提前看到背后的论文解读细节哦!

关注「阿里妈妈技术」,了解更多~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢