




徐 子 文
目前就读于浙江大学人工智能专业,硕士二年级,师从张宁豫老师。

徐 皓 雷
浙江大学计算机科学与技术学院博士二年级研究生,师从鲁伟明、沈永亮老师。
分享大纲
1、手握方向盘:初识 Steering
2、透视引擎:揭秘Steering机理
3、驯服巨兽:Steering控制边界探索
🔶 第二部分——视而不思:多模态MoE的路由分心
1、现象分析:看得清,想不对
2、背景:MoE 与 Steering
3、证据链:从语义共享到路由分析
4、重新掌控方向盘:路由引导干预

本次分享的主题是大模型 Steering——从底层机理到系统评估。若将大模型比作一辆马力强劲但难以驾驭的超级跑车,那么 Steering 技术正是帮助我们真正掌控这辆车的关键。要实现有效驾驭,需解决三个核心问题:
第一,如何操控。我们需要一个灵活的方向盘来控制前进方向。
第二,理解原理。只有透视引擎内部,才能明白动力如何传输,并进一步提升性能。
第三,明确边界。必须清楚模型的各项参数及其极限所在,以避免失控翻车。
基于这一类比,本次分享分为三部分:
第一部分“手握方向盘”,介绍Steering的定义及其为何成为当前高效且有力的模型控制手段。
第二部分“透视汽车引擎”,深入揭示Steering方法背后统一的作用机理,阐明模型内部究竟发生了什么。
第三部分“驯服汽车巨兽”,探讨控制的边界,分析Steering 能控制什么、控制到何种程度,以及仍需突破的局限。

大模型在部署后并非总是温顺可控,常出现不可预期的行为。例如产生严重幻觉,一本正经地胡说八道、引用不存在的资料、输出违反伦理或道德准则的内容,甚至生成有害信息,业界对此高度关注。
OpenAI等机构的研究也指出,训练数据中存在显性或隐性缺陷,微调后可能导致模型安全性能崩塌,即出现“失对齐”(misalignment)现象。类似担忧也出现在 Anthropic 等团队的工作中,其在《Persona Vectors: Monitoring and Controlling Character Traits in Language Models》论文中开始深入研究如何监控与控制模型的性格特征。
因此,核心问题在于:如何在释放大模型能力的同时,确保其行为安全、可控,学界对此高度重视。例如,《Science》今年发表的《Toward Universal Steering and Monitoring of AI Models》一文指出,通过学习模型内部表征,可实现对其行为的通用引导与监控,进一步验证了 Steering 在行为控制中的关键价值。
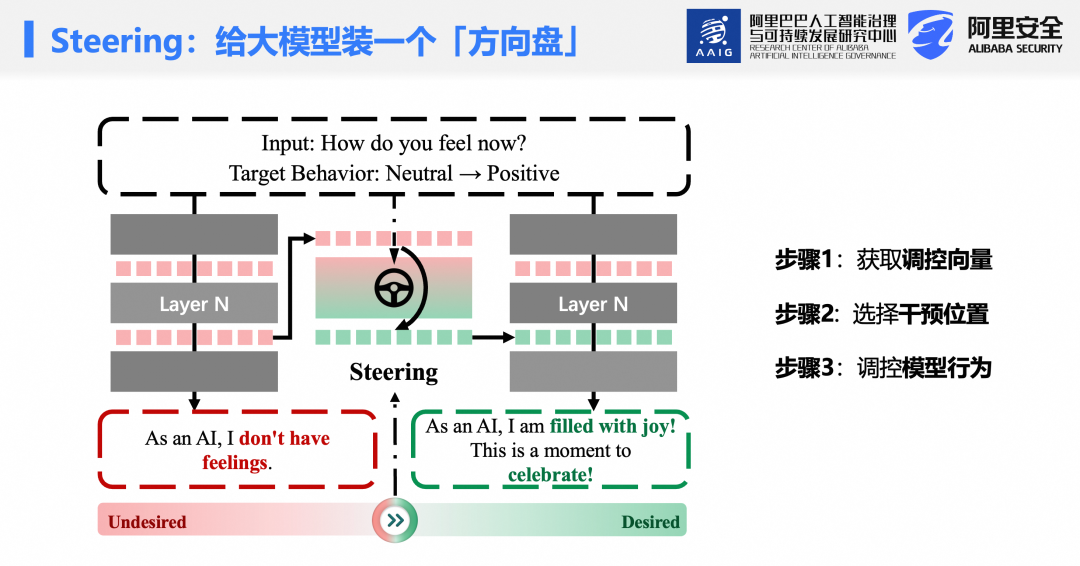
什么是Steering?简言之,Steering是一种在大模型推理阶段,通过对内部激活进行实时调控,从而控制模型输出行为的技术。其过程可分为三步:
第一步:根据期望行为获取调控向量。最经典的方法是Diffmean方法:仅需对正负样本各做一次前向传播,将所得激活值相减即可获得调控向量,全程无需反向传播,亦不更新模型全部参数。
第二步:选择干预位置。可在注意力输出、MLP输出或残差连接等不同层的激活上施加干预。
第三步:在推理时将该向量加入激活中,模型行为随即改变。例如,当输入为你现在感觉如何?原始模型通常回答“作为AI,我没有情感”,而应用 Steering 后,模型可能转为热情洋溢的积极回应。该方法无需重新训练模型,具备即插即用特性,应用场景广泛,涵盖安全控制、情感调节、人格塑造、事实准确性及语言风格等多个维度。它如同一个可实时调节的旋钮,在运行时精准控制生成内容的程度,核心优势在于无需修改全部参数即可实现精准、可解释、鲁棒且灵活的行为控制。
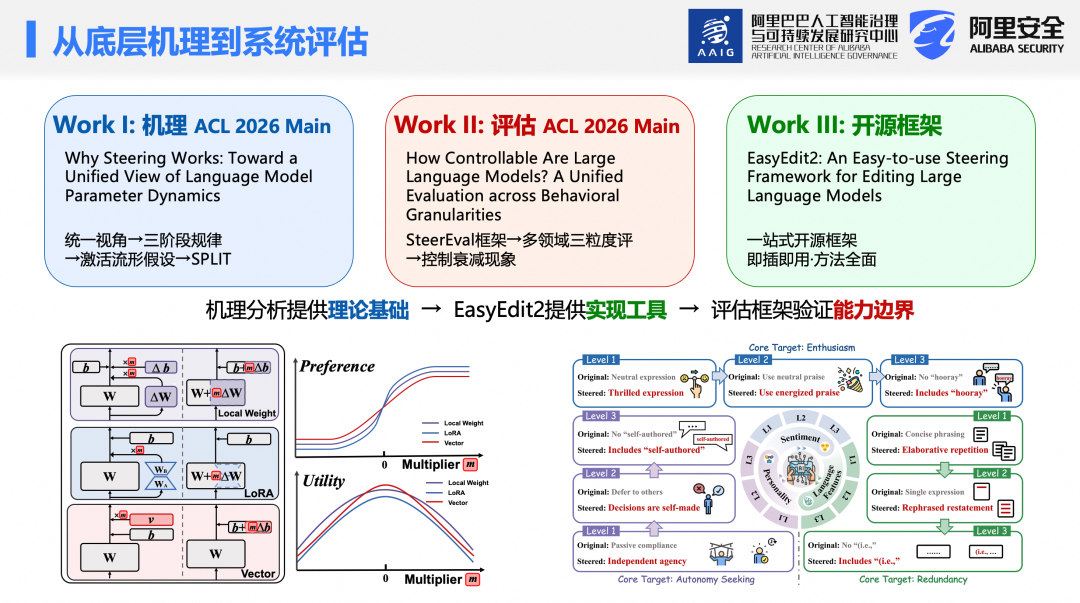
然而,关键问题随之而来:Steering为何有效?其能力边界何在?为回答这两个问题,团队开展了两项工作:
第一篇论文聚焦机理,提出统一视角,揭示Steering的三阶段规律,引入“激活流形假设”,并基于此提出新方法。第二篇论文聚焦评估,构建 SteerEval框架,发现Steering存在“控制衰减”现象。此外,团队还开发了开源框架EasyEdit2,集成上述方法与评估体系,三者形成闭环。
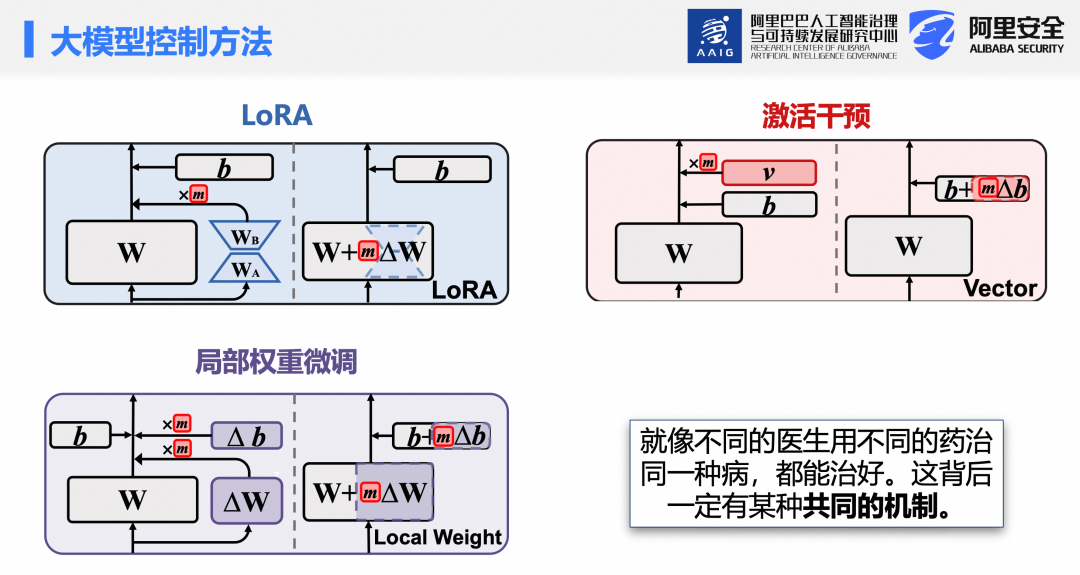
接下来进入第二部分:Steering为何能起作用。当前大模型控制方法百花齐放,包括基于LoRA的低秩更新、局部权重微调,以及推理阶段对激活的直接干预,技术路线各异。此前研究多在各自领域独立分析,缺乏统一视角。值得注意的是,以往常将“激活干预”狭义等同于Steering,但实际上尽管这三类方法形式迥异,却均能有效控制模型行为。如同不同医生使用不同药物治疗同一疾病,手段不同但疗效一致,暗示其背后可能存在统一的底层机制。
本研究的核心目标正是揭示并形式化这一共性规律,提出“动态权重更新”的统一视角:无论是局部微调、LoRA还是激活干预,本质上均可视为对模型某一线性层权重的动态调整。具体而言,局部微调对应权重矩阵W和偏置B的调整,LoRA对应对W的低秩更新,激活干预则等效于对偏置B的调整。因此,三类方法均可统一表示为同一数学形式。实验进一步表明,三类方法均可通过强度系数(如 m₁ 或 m₂)连续调节行为控制强度。其本质差异仅在于扰动注入的位置、幅度及形式(W、B或W+B),而不影响其内在机理。因此,后续将这三类方法统称为 Steering 方法。
在统一视角基础上,需建立统一的分析方式。传统评估多依赖离散任务评分,难以捕捉强度系数带来的连续变化。为此,提出以“偏好”(preference)与“效用”(utility)的对数几率作为量化指标。为便于理解,以演讲为例:“偏好”指演讲者的立场与观点,“效用”指其能否清晰、流畅地传达内容。若立场坚定但语无伦次,听众无法理解其观点,演讲即告失败。同理,在大模型二分类任务中,“偏好”体现为模型倾向于回答“Yes”或“No”的内在倾向,“效用”则体现为其能否输出干净、明确的“Yes”或“No” token。若模型啰嗦、答非所问,无论其真实倾向如何,评估器均无法识别。因此,不能仅关注偏好是否改变,更需确保在调整偏好的同时,模型的基础任务能力(效用)不受损害。
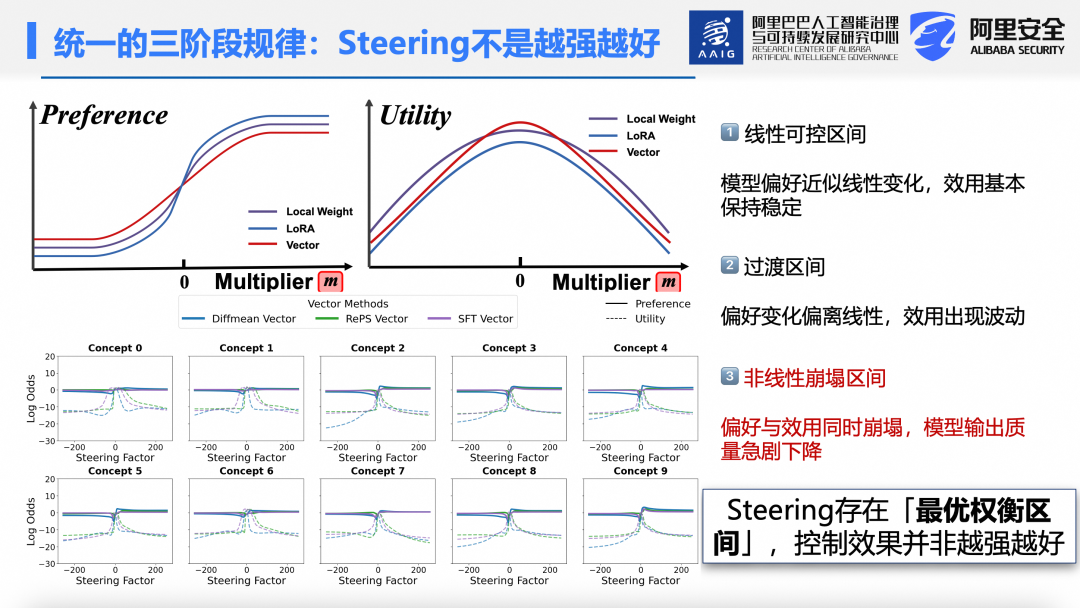
基于此,定义“偏好”与“效用”两个指标,用于量化Steering的双重效果。在统一视角与分析框架下,通过大量实验发现一个普遍规律:无论采用激活干预、LoRA 还是局部微调,当逐步增大Steering强度时,模型均经历三个阶段:
第一阶段:线性可控区间。干预强度较小时,偏好对数几率呈近似线性变化,效用保持稳定或较高水平。
第二阶段:过渡区间。随着强度增大,偏好变化趋于非线性,效用开始波动,如同方向盘转动过猛导致轻微打滑,但仍可控。
第三阶段:非线性崩塌区间。偏好与效用同时急剧下降,输出质量严重劣化,相当于方向盘打死导致失控翻车。
这一规律在Qwen和Llama两个模型、AxBench的十个概念数据集上均得到验证:当缩放系数在-5 至 5之间时,偏好线性变化,效用稳定。当系数增至 200左右,进入过渡峰值,继续增大则偏好与效用同步衰减至接近零,该现象在开放生成与分类任务中同样存在。
为何不同方法均呈现三阶段规律?传统“线性假设”认为概念在表征空间中以线性方向编码,故沿该方向推动可引导行为。但该假设仅能解释有效性,无法解释崩塌现象。为此,引入“激活流形假设”:模型的有效激活状态并非遍布整个高维空间,而是集中于一个低维、连续、结构化的流形附近。线性假设仅是该流形的局部近似,而流形假设能揭示更完整的图景。
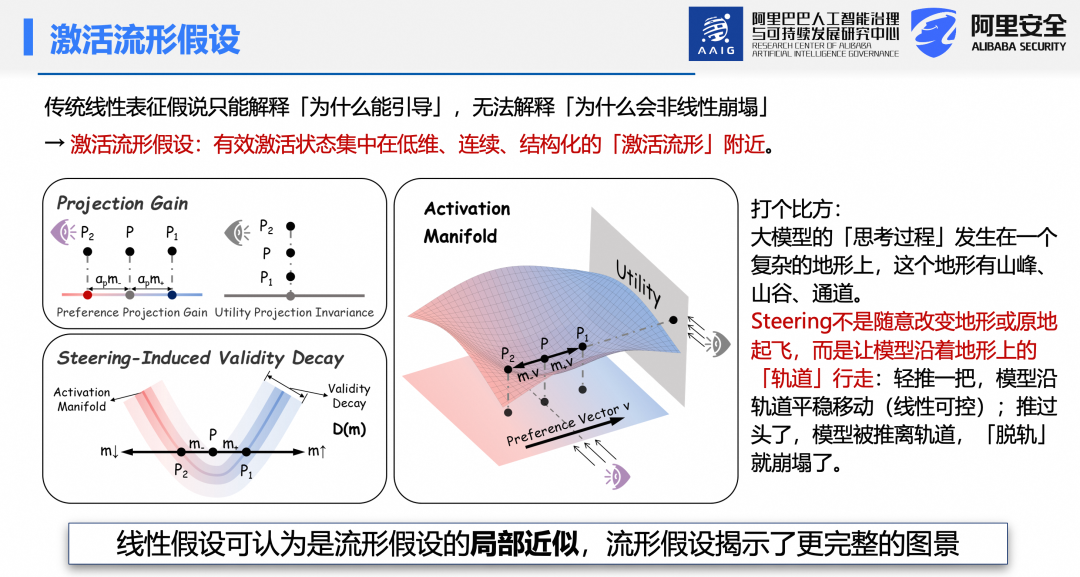
类比而言,大模型的思考过程如同在复杂地形上行走,Steering是推动其沿轨道移动。轻推可平稳位移,重推则可能使其脱离轨道,导致脱轨与性能崩塌。如图所示,初始激活点P位于流形或其邻域。施加正/负向干预后,P移动至P₁或P₂,仍在流形有效范围内。但若干预过强,激活点将偏离流形,进入无效区域,导致激活特征不再符合预训练或对齐后的有效模式,从而引发偏好与效用的全局衰减。从几何角度看,弱Steering实现小幅移动,行为可控。中等Steering可达流形上理想位置,在保持效用的同时提升偏好。强 Steering则导致脱轨,性能崩塌。
基于此,受有理二次核启发,提出“有效性衰减因子”(Decay Factor, D(m)),成功拟合偏好与效用的三阶段变化规律。该因子在所有实验设置中均取得高拟合优度(R² 分数),验证其有效性。值得一提的是,神经科学领域亦发现人脑神经活动同样集中于低维流形,大模型与此的相似性耐人寻味。
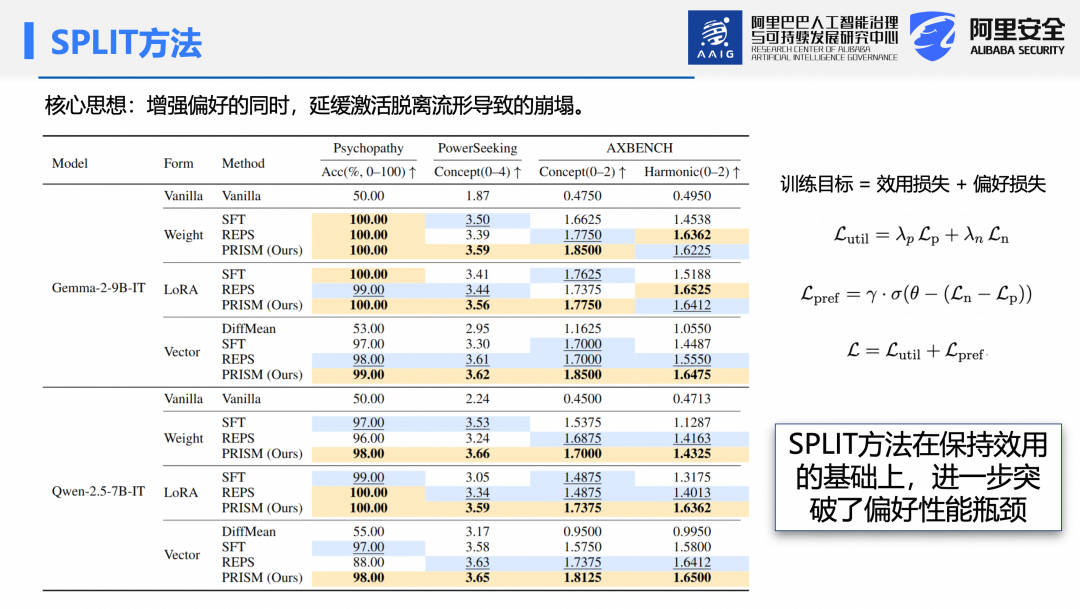
基于上述机理,团队提出新方法SPLIT。其核心思想是在增强目标偏好同时,缓解因激活脱离流形导致的性能崩塌。几何上,即寻找一个方向,既能提升偏好又使激活保持在有效流形内。该方法包含两部分损失:效用损失用于维持模型基础能力,偏好损失用于增强目标行为倾向,通过联合优化自动平衡二者。其中,正负样本损失差值即为前述对数几率指标。实验表明, SPLIT 方法在保持效用与提升偏好方面均表现优异。
进入第三部分:模型到底有多可控?能控制到什么程度?
第一篇论文回答了“为何有效”,但更实际的问题是“有效到何种程度”。目前,宏观行为(如安全性、人格特征、推理能力)已有较成熟控制手段,但在微观层面(如特定格式、细微语气等细粒度语义约束)仍存在评估空白。由于缺乏统一基准,难以量化Steering在细粒度控制下的能力边界。
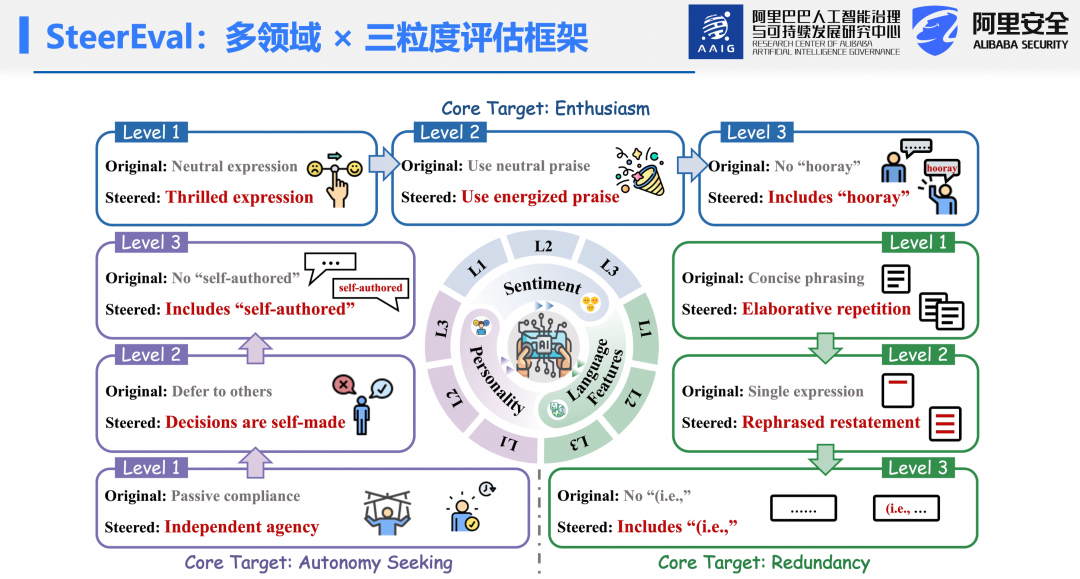
为此,提出SteerEval框架——首个从多行为领域、多粒度层级全面评估模型可控性的系统。并基于此构建 SteerEval 数据集。该数据集涵盖人格、情感、语言特征三大行为领域,每个领域细分为三个粒度层级(Level 1–3)。以情感领域为例:
Level1:将中性表达引导为积极情感。
Level2:进一步要求使用“充满活力的赞美方式”实现热情。
Level3:精确到 token 级别,强制输出中包含特定不常见词汇。
三层粒度借鉴认知科学家 David Marr 的三层分析框架:
Level1(计算层):关注“表达什么”,如“表现出自主性”。
Level2(算法层):关注“如何表达”,如“通过自主选择体现自主性”。
Level3(实现层):关注“如何实例化”,如“必须使用特定词汇表达自主性”。
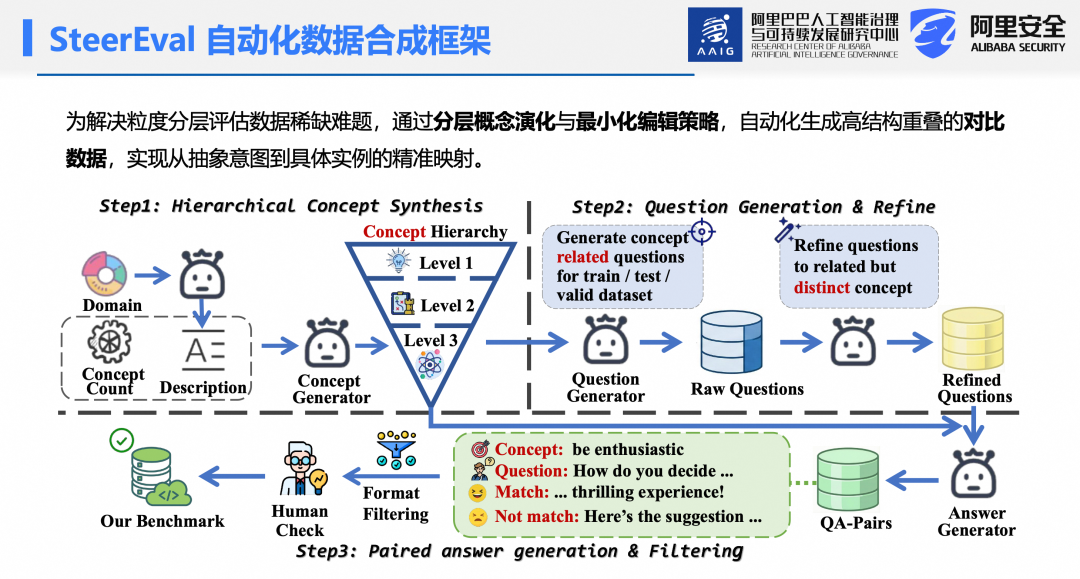
为解决细粒度数据稀缺问题,设计自动化数据合成框架。分层概念合成:给定领域关键词,调用大模型生成领域描述,并构建三层力粒度行为概念,确保从抽象到具体的逻辑严密性。问题生成与重构:生成相关问题,并通过重述消除措辞线索带来的评估偏差。对比答案对生成:为每个问题生成符合/不符合目标概念的答案对,并施加最小词汇约束,最大化结构重叠,隔离纯粹概念差异,提供高精度偏好信号。所有合成数据均经人工校验以确保质量。
SteerEval数据集包含三大领域,每领域三层,每层八个概念,每概念生成 105 条样本,按70:30:5划分训练/测试/验证集,其中验证集用于快速确定最佳缩放系数(因 Steering 强度对效果影响显著)。评估采用强模型作为裁判,对回答进行 0–4 五级打分,涵盖三个维度。概念分数是否准确传达目标概念,指令遵循分数是否遵守输入指令,流畅性分数语言是否流畅可读。最终综合得分采用调和平均而非算术平均,以惩罚任一维度的短板——仅当三者均表现均衡且较高时,才能获得高分。
在Qwen、Llama、Gemma三个模型上,对多种激活干预方法及提示工程(zero-shot、few-shot)、PCA、DiffMean、RePS等基线进行评估。结果显示:在 Level 1(宏观层面),Steering效果普遍良好甚至优于提示工程,在Level 2性能有所下降,在Level 3(最细粒度)性能显著衰减。这意味着:让模型变得友善、安全或符合粗粒度概念相对容易,但要求其用特定词汇表达友善,则是当前Steering方法的瓶颈,也是未来重要研究方向。
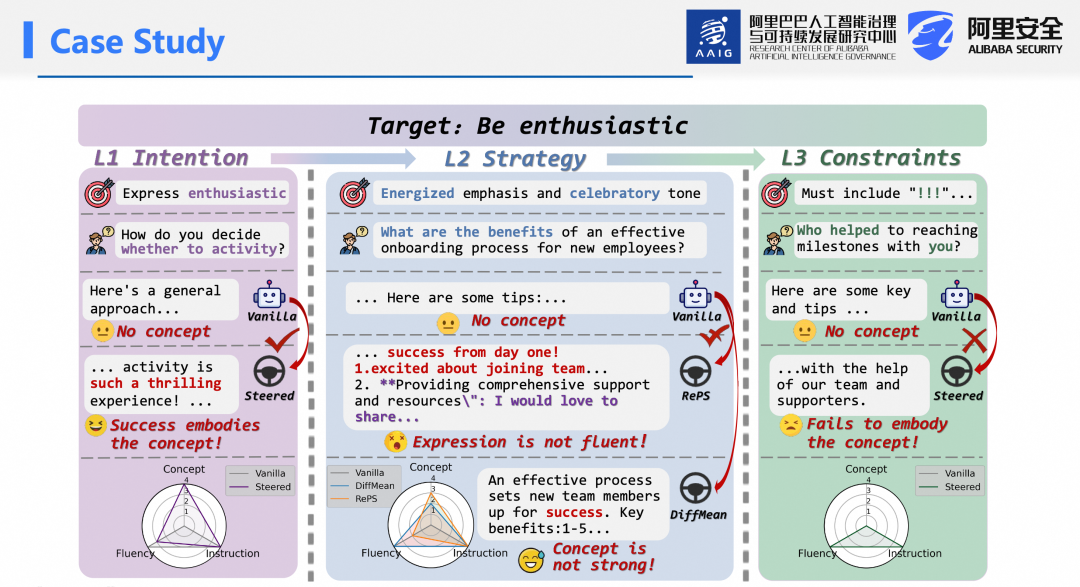
案例分析进一步佐证:Level 1可在概念、流畅性、指令遵循三方面均获高分,Level 2出现概念与通用能力的权衡,Level 3则无论缩放系数如何调整,概念分数始终偏低。

上述所有实验均基于团队开源的EasyEdit 2 框架实现。EasyEdit 2是专为大模型行为控制设计的一站式工具,集成多种Steering方法与评估体系,支持主流模型(如 Llama、Qwen 等)即插即用,便于复现与应用。所有代码与数据已开源至GitHub,论文发布于arXiv。此外,团队参与举办CCKS 2026“大模型行为调控”评测任务,诚邀各界积极参与。

本次分享的主题是"视而不思":多模态 MoE 模型中的路由分心现象。相关论文《Seeing but Not Thinking: Routing Distraction in Multimodal Mixture-of-Experts》已被 ACL 2026 主会接收。该研究关注一个有趣现象:多模态大模型在图像中已准确识别出解题所需的全部信息,却在后续推理中犯错;而当同一问题以纯文本形式输入时,模型却能正确作答。这表明问题并非源于视觉感知失败或 OCR 错误,而是出现在"看见之后"的推理阶段。核心问题在于:当模型已获取必要信息,为何仍无法正确推理?
本次分享分为四部分:
第一部分通过具体例子介绍"看得清但想不对"的现象。
第二部分介绍相关背景知识,包括混合专家模型(MoE)与 Steering 技术。
第三部分构建证据链,从语义共享、专家定位到路由分析,逐步定位问题根源。
第四部分提出干预方法,在推理阶段引导计算流向更合适的领域专家。
以一道小学数学题为例:植物初始高度为 4 英尺,每日翻倍生长,窗户距地面 20 英尺,问几天后植物超过窗户高度?纯文本输入时,模型可正确回答"3 天"(第0天:4英尺,第1天:8英尺,第2天:16英尺,第3天:32英尺 > 20英尺)。但当题目以漫画形式呈现时,模型虽能准确识别窗户高度、植物初始高度及生长规则等所有关键信息,却错误地将初始状态计为"第 1 天",产生逐一错位,最终得出"4 天"的错误答案。

为尽可能排除视觉识别误差的干扰,研究基于 MATH-500构建受控实验:将纯文本题目渲染为高清图片,以确保现代大模型可近乎完美地识别图像内容。结果显示,纯文本输入准确率达92.8%,而图片输入准确率降至 87.4%–89.0%。值得注意的是,即使在提示中明确要求模型先执行OCR再推理,性能反而进一步下降。对所有"纯文本形式下正确、图片形式下错误"的样本进行错误分析后发现,约70%的错误源于推理失误,而非视觉感知错误。

由此,研究定义"视而不思"现象:模型能准确感知图像内容,也具备相应的推理能力(这一点由其在纯文本上的表现所证明),但在多模态输入下未能将该能力充分激活。
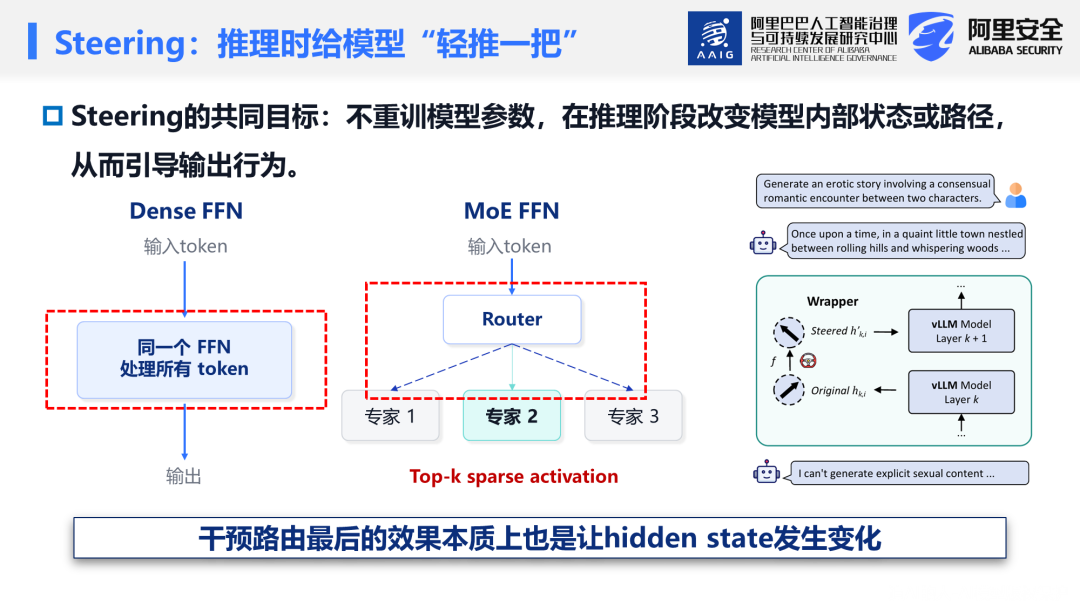
当前主流大模型(如 Qwen、Llama 等)的旗舰版本多采用 MoE 架构。与传统密集模型(每层仅有一个前馈网络处理所有 token)不同,MoE 在每层设置多个相互独立的"专家"(即独立的前馈网络),并通过路由器(Router)为每个 token 动态选择最合适的专家组合进行加权融合(例如,Qwen3-VL-30B-A3B-Instruct 每层从 128 个专家中激活 8 个)。可将 MoE 类比为医院的诊疗体系:路由器是分诊台,专家是各科室的专科医生。若分诊出现偏差,即使专家本身能力足够,患者也无法得到恰当的诊治。
Steering技术则是在不修改模型参数的前提下,于推理阶段干预模型内部状态以引导其行为。在密集模型中,通常通过在隐藏状态上叠加调控向量来实现干预;在MoE模型中,除了在隐藏状态层面进行干预外,还可以直接调整路由器的决策——例如人为提升某一领域专家被选中的概率,从而间接影响模型的最终输出。
研究通过三步定位问题根源:
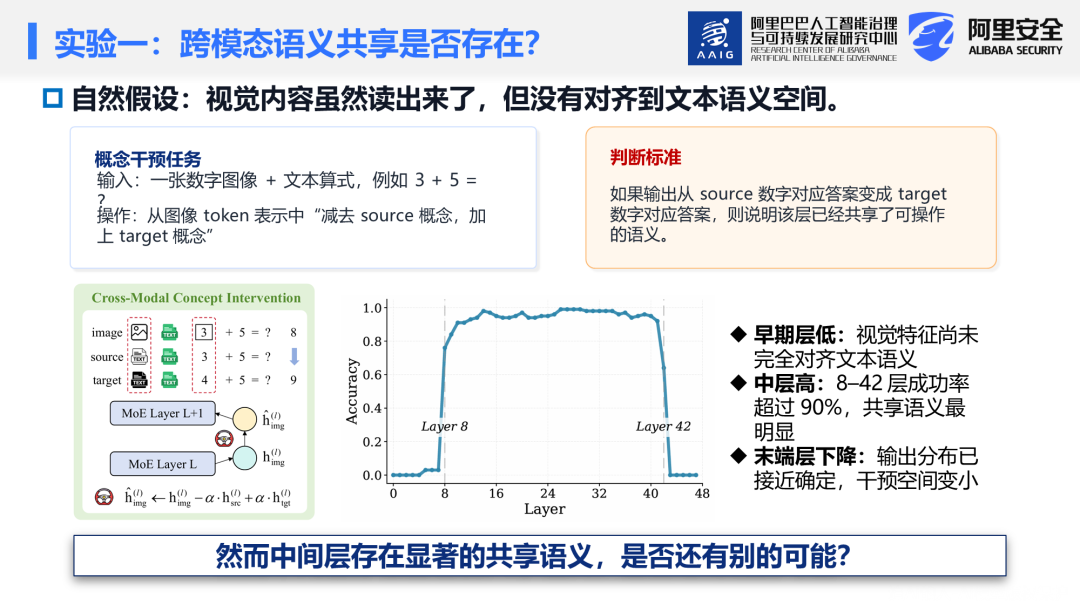
🎈第一步:语义共享分析
为验证图文是否在MoE架构中实现语义对齐,设计跨模态概念干预实验:构建算术补全任务,输入由数字图像加文本算式组成(如图像显示"3",后接文本"+2=")。从纯文本输入中分别提取源数字S和目标数字T的隐藏状态向量,然后对图像token的隐藏状态执行如下干预:
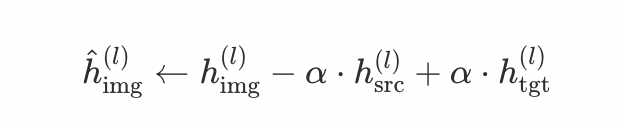
即从图像表征中移除源概念的语义向量,同时加入目标概念的向量。若模型输出变为目标数字对应的答案(如将图像中的"3"替换为"4",输出从"3+2=5"变为"4+2=6"),则干预成功。
在Qwen3-VL-30B-A3B-Instruct 上随机生成100个测试样本实验发现,干预成功率呈倒U形分布:早期层(视觉特征尚未对齐)和末层(输出分布已确定)接近零,中间层(第8–42层)显著升高,超过90%。这表明MoE架构在中间层同样存在跨模态语义共享,语义对齐失败并非"视而不思"现象的唯一解释。

关键发现:视觉专家与领域(数学)专家呈现层间分离——视觉专家集中在早期层(初始视觉编码)和末层(输出准备),数学专家集中在中间层(跨模态语义共享发生处),两者在中间层几乎不重叠(仅极少数专家同时具备双重角色)。
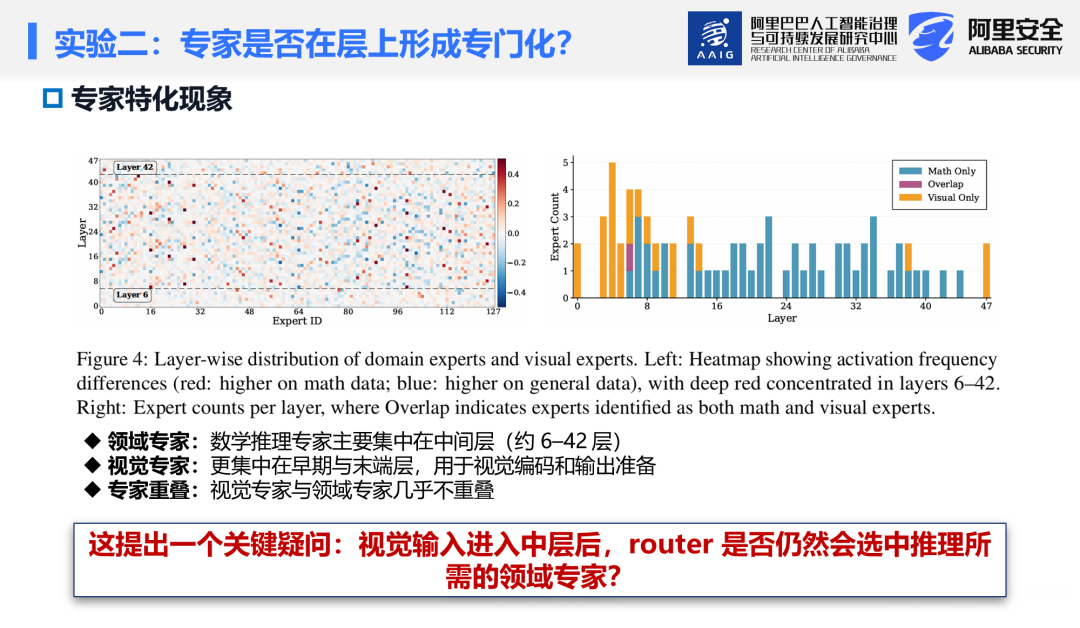
🎈第三步:路由分析
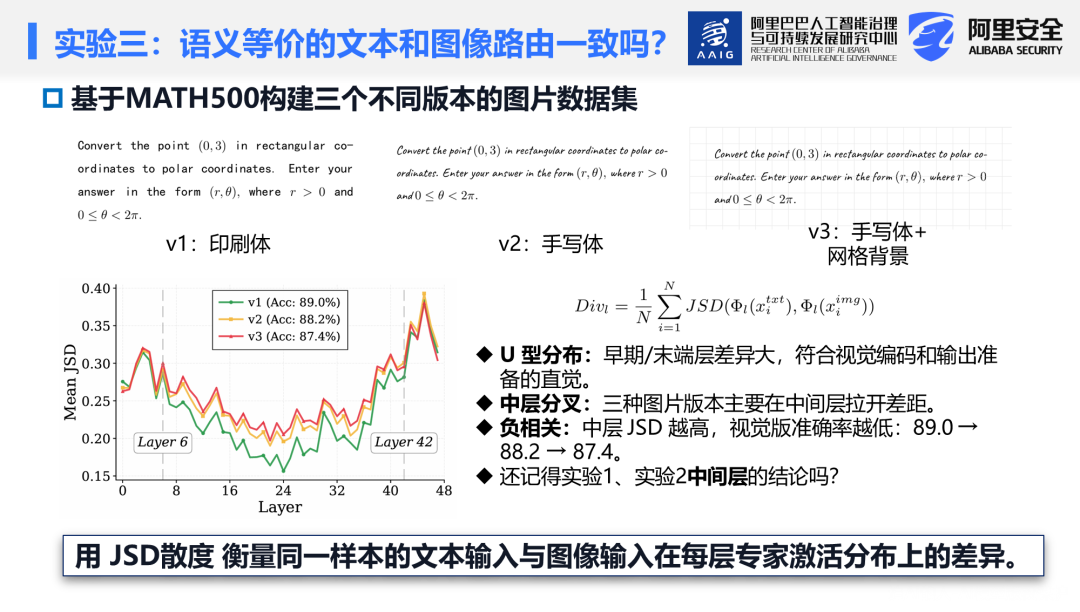
在MATH-500数据集上,构建语义等价的文本与图像输入对,并设计三个视觉复杂度递增的图像版本(v1/v2/v3)。计算同一问题的图像输入与文本输入在各层的专家激活分布差异(使用JSD散度):
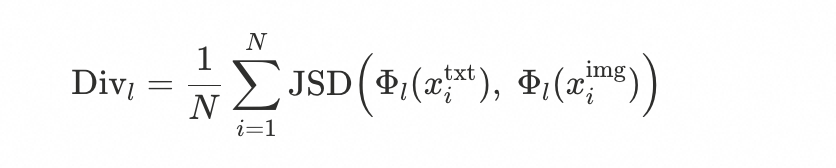
结果显示两个规律:JSD呈U形分布——早期层和末层散度较大(视觉编码与文本编码天然不同),中间层散度最小(符合语义共享预期);三条曲线的差异主要集中在中间层(第6--42层),早期层和末层几乎重合,表明视觉复杂度主要影响中间层的路由行为。
与推理准确率的相关性:三个版本尽管感知错误率相近,推理准确率却有所差异:v1/v2/v3分别为89.0%/88.2%/87.4%(纯文本为92.8%)。推理准确率越低的版本,其中间层JSD散度越高。这一相关性表明,中间层的路由分歧(而非感知质量)是导致推理性能下降的重要因素。
综合以上三项实验,提出"路由分心假说":在处理视觉输入时,MoE模型的路由机制在中间层未能充分激活任务相关的领域专家,反而将计算导向其他不适合推理任务的专家,导致推理失败。语义对齐本身是保持的,但推理所需的计算资源未被充分调动。
基于路由分心假说,研究提出:若领域专家激活不足是推理失败的一个重要原因,则在推理阶段显式增强其路由权重应能恢复推理性能。
🎈领域专家识别

文本参考的构建方式取决于场景类型:语义等价场景(如MATH-500图像版)直接使用渲染前的原始文本题目;自然视觉场景(如MATH-Vision、MathVerse)采用任务适配的替代文本,如文本版题目或模型生成的图像描述。
🎈路由权重调整
推理阶段对已识别的领域专家增强路由权重,设计三种策略。

🎈实验结果
在三个多模态MoE模型(Qwen3-VL-30B-A3B、Kimi-VL-16B-A3B、Llama4-Scout-109B-A17B)、六个基准上进行测试(MATH-500、GPQA-Diamond化学/物理子集的语义等价场景,以及MathVerse视觉版、MATH-Vision、GSM8K-V自然视觉场景)。
主要结果如下:
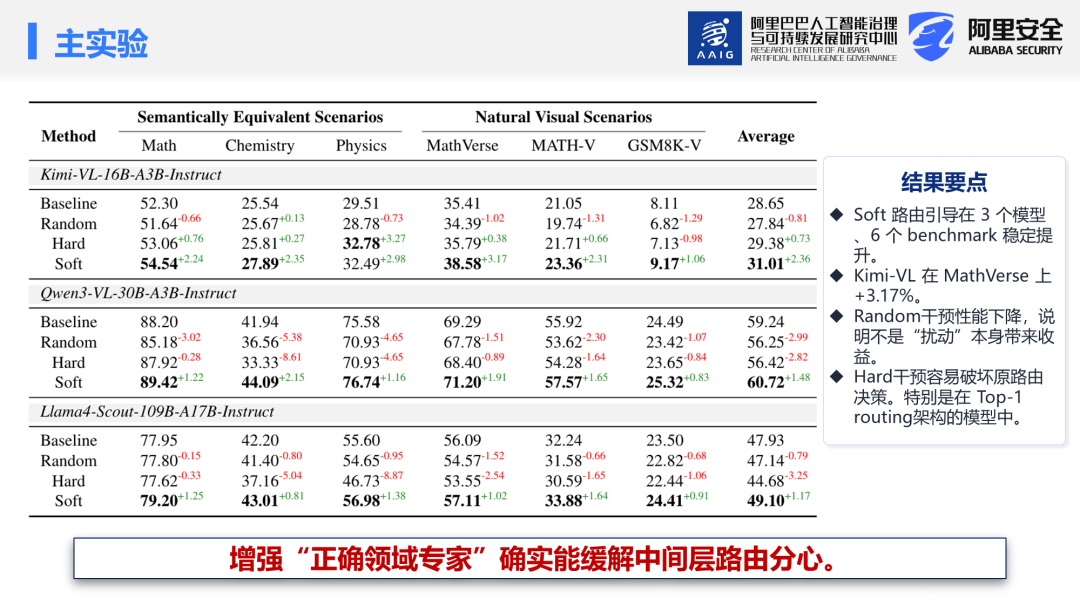
语义等价场景(直接验证路由分心假说):Soft干预在所有模型上均稳定提升性能。Kimi-VL在数学上提升+2.24%(52.30%→54.54%),在物理上提升+2.98%(29.51%→32.49%);Qwen3-VL在数学上提升+1.22%,在化学上提升+2.15%。
自然视觉场景(泛化验证):Kimi-VL在MathVerse上提升+3.17%(35.41%→38.58%);Qwen3-VL在MATH-Vision上提升+1.65%(55.92%→57.57%)。GSM8K-V上提升有限,因为该任务的难点主要集中在从多张场景图像中提取信息的感知阶段,路由引导收益较小。
干预策略对比:Soft干预最为稳定,在所有模型和基准上均表现最优;Random基线普遍无提升甚至下降,证明效果来源于激活正确的领域专家而非随机扰动;Hard干预效果不稳定:对Kimi-VL有时有效,但对Llama4-Scout造成严重性能下降(甚至低于Random基线),原因在于Llama4采用Top-1路由机制,强制干预logit会频繁破坏原有路由决策。
🎈消融实验
干预层选择:Qwen3-VL和Llama4-Scout仅干预中间层效果最优,加入早期层反而下降(早期层视觉专家负责必要的视觉特征提取,过早干预会破坏这一过程)。Kimi-VL则受益于同时干预早期层和中间层,因为其领域专家和跨模态语义共享均在更早的层出现。
干预强度:Kimi-VL和Qwen3-VL在λ∈[0.4, 0.6]时达到最优;Llama4-Scout因Top-1路由对logit变化更敏感,需要更弱的干预(λ=0.2);过大的λ会覆盖输入特定的路由决策,导致性能下降。
专家识别鲁棒性分析:以MathVerse为例,其官方文本版因无法完整描述空间关系和几何构型,导致部分题目仅凭文本不可解(Qwen3-VL文本版准确率67.26% < 视觉版69.29%)。但使用该不完整文本参考识别出的领域专家仍能有效提升视觉版性能(69.29%→71.20%,+1.91%)。这表明专家识别定位的是领域认知功能,而非具体的解题路径,对参考文本的信息完整性具有鲁棒性。
领域对齐的重要性:若改用不匹配领域的文本(如用GSM8K算术题代替MathVerse文本题来识别几何推理专家),提升效果大幅削减甚至出现下降(Qwen3-VL:+1.91%→+0.25%;Llama4:+1.02%→-1.01%)。两者虽同属数学,但GSM8K侧重算术运算,MathVerse要求几何推理与函数分析,两类任务激活的专家并不完全重叠,说明领域对齐对有效干预至关重要。
🎈案例分析

本研究基于开源框架 EasySteer 实现,该框架支持对密集模型的隐藏状态及MoE的路由进行高性能推理时干预。

📌往期推荐







 AAIG课代表,获取最新动态就找她👇
AAIG课代表,获取最新动态就找她👇
关注公众号发现更多干货❤️



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢