
【论文标题】Bi-tuning of Pre-trained Representations
【作者团队】Jincheng Zhong, Ximei Wang, Zhi Kou, Jianmin Wang, Mingsheng Long
【发表时间】2020/12/25
【论文链接】https://arxiv.org/pdf/2011.06182.pdf
【推荐理由】提出作为一个通用的微调框架,双调优可以应用于各种主干,而无需任何附加假设,对有监督和无监督的预训练模型进行了大幅度的改进。此论文被 ICLR2021接收。
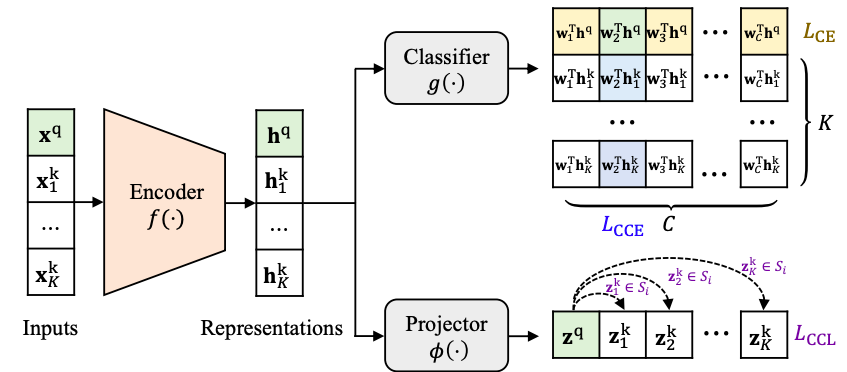
在深度学习社区中,首先从大规模数据集预训练深度神经网络,然后对预训练的模型进行微调,以适应特定的下游任务,这是很常见的。近年来,有监督和无监督的学习表示的预训练方法都取得了显著的进展,它们分别利用了标签的辨别性知识和数据的内在结构。根据自然的直觉,下游任务的甄别性知识和内在结构对于微调都是有用的,然而,现有的微调方法主要利用前者而放弃后者。问题来了:如何充分挖掘数据的内在结构来促进微调?在这篇论文中,我们提出了双调优,一个通用的学习框架,对下游任务的有监督和无监督的预先训练表示进行微调。Bi-tuning通过整合两头的支柱预训练表示:一种改进的对比交叉熵损失分类器头以实例对比的方法更好的利用标签信息,和一个带有新设计的对比学习损失的投影头,这是一种为了以类别一致的方式充分利用数据的内在结构。综合实验证实,双调优在有监督和无监督的预训练模型的微调任务中都获得了最先进的结果(例如,在低数据情况下,CUB准确率绝对提高了10.7%)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢