

投稿作者:浙江大学 April团队
近年来,基于 Diffusion Transformer 的视频生成模型在短视频质量上进步明显。但当生成任务从几秒钟扩展到更长的叙事片段时,模型需要持续处理历史画面、当前提示和未来动作之间的关系。自回归视频生成按片段逐步生成后续帧,天然适合长视频和流式交互,却也暴露出一个关键问题:局部上下文窗口有限,早期角色和属性会逐渐被弱化。
这一问题在多提示场景中更明显。用户可能在生成过程中加入新指令,例如让某个角色重新入场,或改变角色之间的互动。如果模型无法把提示中的名字和历史画面中的人物绑定起来,就会出现身份漂移、角色重复、服装或发型变化等现象。对叙事视频而言,这类错误会直接破坏连贯性,严重影响观感。
为此,浙江大学 APRIL 团队及其合作者提出了 IAMFlow,无需重新训练视频生成模型,而是在推理阶段引入身份感知记忆机制,显式记忆和检索角色身份。

论文链接:https://arxiv.org/abs/2605.18733
项目链接:https://eddie0521.github.io/projects/iamflow/
针对多提示叙事评测方面的空白,研究团队进一步构建了 NarraStream-Bench。实验表明,IAMFlow 的总体得分达到 75.73,比最强基线高 2.56 分,同时相比最高效基线实现 1.39 倍加速。
这一工作的价值在于把长视频生成中的“记忆”问题具体化为“身份管理”问题。这让模型关注角色是谁、具有什么视觉属性、何时离场和回归,而不只是保存若干历史帧。在用户体验方面,稳定的角色身份能让 AI 视频从短视频展示走向长视频连续叙事,也为交互式创作、短剧生成和虚拟角色应用提供更可靠的基础。
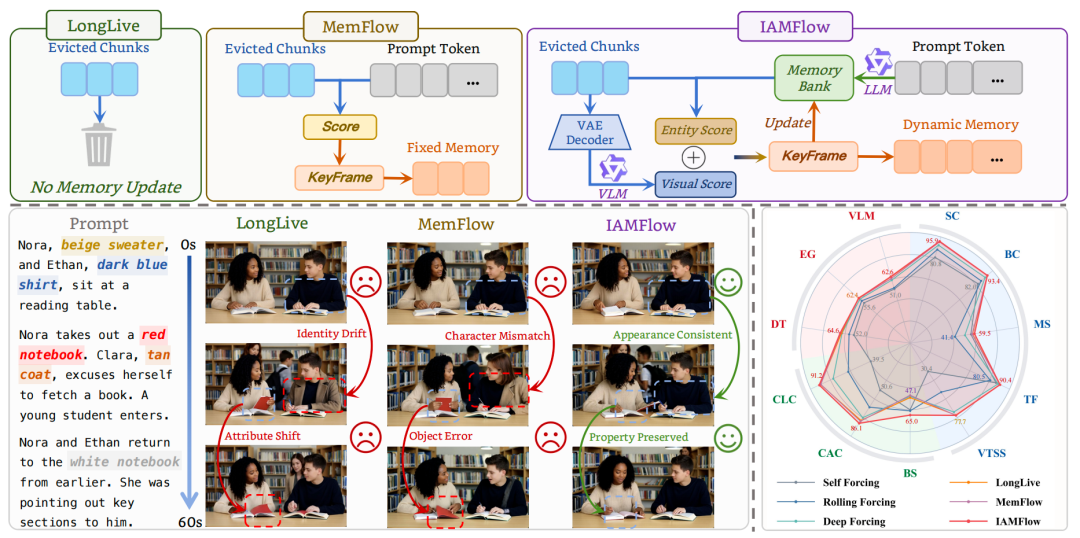
图 1 | 三种记忆范式对比。上:LongLive 用固定锚点,MemFlow 做固定策略检索,都无法应对跨提示角色漂移。下:IAMFlow 在 60 秒内保持角色外貌完全一致。
研究方法
1.IAMFlow:面向角色一致性的身份感知记忆框架
现有长视频方法通常依赖固定历史帧、压缩记忆或基于注意力的关键帧检索。这些策略能保留部分视觉信息,但难以回答当前片段中最需要保留的对象是什么。IAMFlow 改为围绕实体身份组织记忆:每个角色都有全局 ID,系统根据角色 ID 查找相关历史证据,再把这些信息送入后续生成过程。
具体来说,每次接收新提示时,IAMFlow 会先使用 LLM 解析角色名称和视觉属性,例如发型、衣着、随身物品和相对关系,再将新提示中的实体与历史实体匹配,为持续出现的角色维护同一个全局 ID。有了这层身份绑定,即使角色换一种指代表达,或在离场后重新出现,模型仍能找到对应的历史身份。
生成新视频片段前,Memory Bank 会根据当前活跃角色的全局 ID 检索相关关键帧。这一步关注的不是画面整体相似度,而是与目标角色身份有关的历史证据。当旧片段被移出局部窗口时,系统会评估哪些帧更能代表角色身份,并将这些帧归档到长期记忆中,避免早期角色信息随时间被稀释。
在生成过程中,IAMFlow 还使用 VLM 在后台检查角色属性,发现明显偏移后更新记忆。这条校验链路与视频生成并行运行,不会打断主推理流程。同时,方法引入自适应提示过渡,在提示切换时平滑交叉注意力信号,从而降低角色突变和画面闪变的概率。
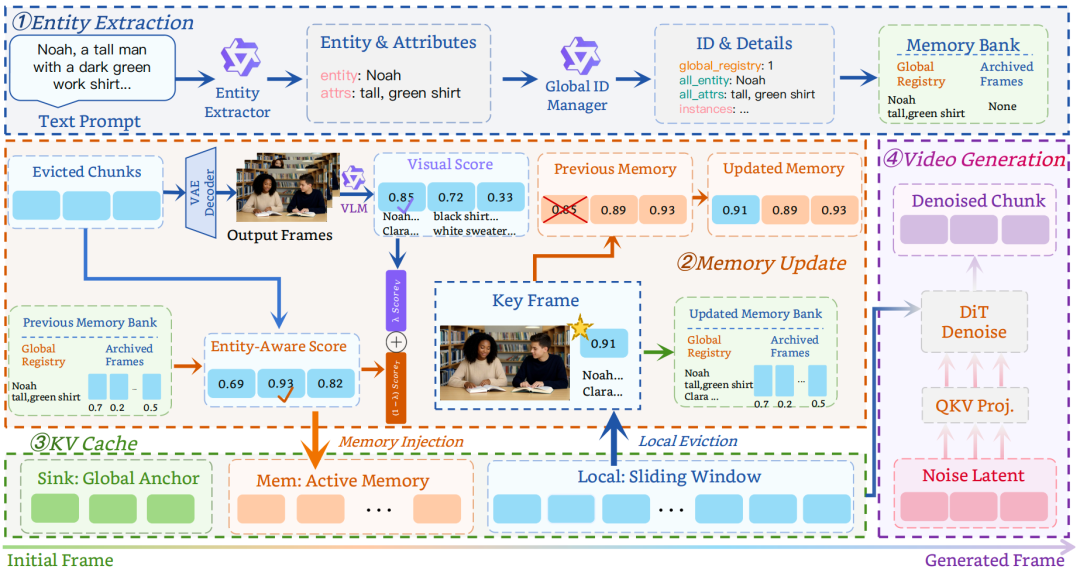
图 2 | IAMFlow 框架总览。LLM 提取实体并分配全局 ID,Memory Bank检索关联帧,异步 VLM 验证更新,DiT 去噪生成。
2.系统加速设计:让身份记忆不拖慢生成
记忆增强方法通常会带来额外开销:历史帧需要存储,关键帧需要检索,角色属性还需要校验。IAMFlow 没有把这些步骤串行叠加到主干推理上,而是把加速设计放进系统流程中,尽量让身份记忆与视频生成并行完成。
第一,异步验证。VLM 负责检查角色身份和视觉属性,但这一过程在后台线程运行,与 DiT 去噪和视频块解码重叠,因此不会阻塞主生成链路。
第二,模型量化。系统遵循 LightX2V 的设置,对 DiT 的 FFN 层进行 FP8 量化,并使用 TinyVAE 解码,降低显存和计算压力。
第三,部署适配。LLM 与 VLM 通过 vLLM 引擎调度,减少离线调用带来的启动延迟。在 NVIDIA H20 上测试时,IAMFlow 端到端生成 60 秒视频的速度达到无记忆模块基线的 1.39 倍,实现了身份一致性和推理效率的同步提升。
3.NarraStream-Bench:填补叙事长视频评测空白
为评估多提示长视频中的角色一致性,团队构建了 NarraStream-Bench。该基准包含 324 个 60 秒叙事脚本,每个脚本由 6 段连续提示组成,覆盖角色数量、交互方式、进出场模式、长程回调、角色区分难度和指代变化等 6 个维度。评测体系包括视觉质量、时间一致性和指令遵循 3 个方面,共 11 项指标。
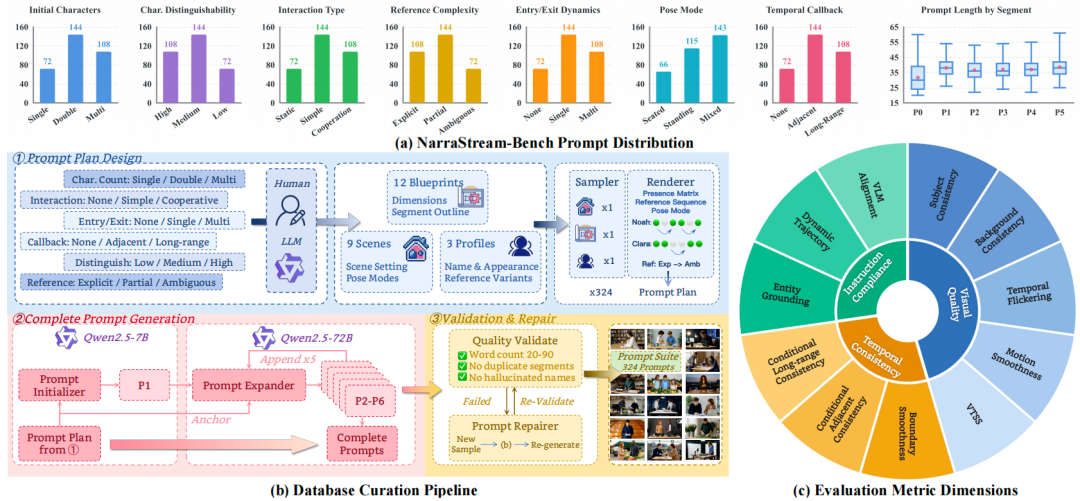
图 3 | NarraStream-Bench 总览。(a) 六维度提示分布 (b) 数据库构建流程 (c) 三维评测维度。
研究成果
研究团队在多方面对 IAMFlow 与 NarraStream-Bench 进行了深入研究。
1.总体表现:角色一致性与指令遵循同步提升
在 NarraStream-Bench 的 60 秒多提示设置下,IAMFlow 获得了 75.73 的总体得分,高于 Deep Forcing、LongLive 和 MemFlow 等基线方法。从细分指标看,时间一致性和指令遵循的提升明显,这与身份感知记忆的设计目标一致。
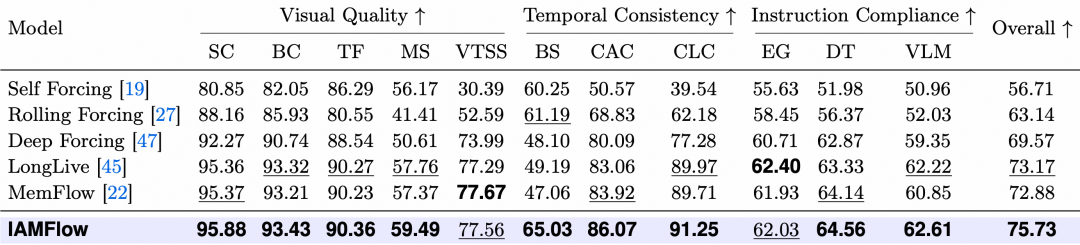
图 4 | NarraStream-Bench上各方法指标对比
2.定性结果:减少身份漂移和属性丢失
在定性对比中,基线方法容易把同一角色生成成不同外观,或在角色再次出现时改变服装和发型。IAMFlow 通过全局 ID 检索对应历史帧,使角色在更长时间跨度内保持稳定。这类改进对普通观众也更直观,因为人物是否一致往往比单帧细节更影响观看体验。

图 5 | 60 秒定性对比。IAMFlow 始终保持角色外貌一致,而基线方法出现不同程度的角色错配、属性漂移和画面质量坍塌。
3.Benchmark鲁棒性与人类偏好研究
针对 Benchmark 本身,团队还做了严格的评测鲁棒性验证:用 GPT-5 和 Gemini-3.1-Pro 替换掉原来的 Qwen3-VL,IAMFlow 依然保持领先。人类偏好研究也确认了自动指标与人类判断的高度一致性。
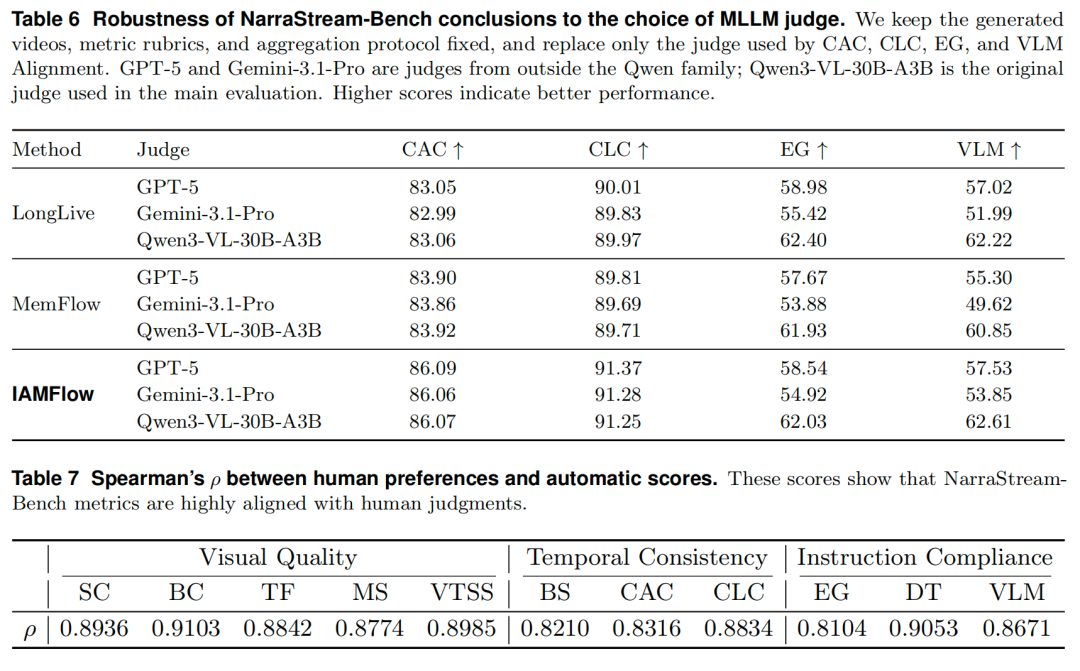
图 6 | NarraStream-Bench的精心设计,使其免受MLLM本身的偏好影响,与人类判断高度一致。
不足和未来方向
当然,这项研究也存在一些局限。
IAMFlow 当前优先保证角色身份稳定,因此在需要大幅改变角色状态的场景中可能偏保守。例如高速运动、复杂肢体交互、服装主动变化和角色关系演化,都要求系统在保持一致和响应新提示之间取得更细的平衡。
研究团队表示,他们将在未来的工作中继续探索更灵活的自适应记忆策略,让记忆强度随剧情和提示变化动态调整;另一条方向则是构建更细粒度的实体表征,把角色的外观、动作、关系和状态变化分开建模。
如果这一问题得到更好的解决,AI 长视频生成将更接近可持续编辑和可复用角色资产的创作流程。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢