
AutoResearch-MLIP:让每一个假设、每一次失败,都成为下一轮研究的依据
一句话概括:AutoResearch-MLIP 以机器学习力场为研究对象,构建了一套自主科研闭环——智能体持续提出设计假设、修改代码、运行评估、记录失败,并以此指导下一步,整个演化过程有据可查、可以回溯。

自主科研的关键:让每一步都留下可追溯的记录
已有的科研智能体工作大多聚焦在工具调用、代码生成和自动运行实验上。AutoResearch-MLIP关注的是更进一步的问题:智能体能否形成真正意义上的研究过程——持续提出假设、修改代码、运行评估、读取结果、记录失败,并把这些记录带入下一轮?
评价这类系统,不能只看最终模型的分数。一个高分候选可能来自偶然的搜索;一次暂时的失败,往往反而为下一轮尝试提供灵感。真正需要检查的是完整的研究过程:每个想法怎么落到代码,评估结果如何影响了后续决策,哪些失败被记录,又改变了什么。
为什么选 MLIP 作为试验场
机器学习原子间势(machine-learned interatomic potentials,MLIPs)是一个理想的测试对象。一个 MLIP 由多个可以独立实现、组合和继承的设计模块构成——包括局域相互作用、读出层与组成建模、特征表示方式、长程能量项、周期图构造和训练目标。
这些模块不仅可以写成代码,还可以在分子动力学和周期性晶体任务上被定量评估。MLIP开发天然对应一个"提出假设 → 实现代码 → 评估结果 → 继承或放弃"的研究循环,是检验自主科研系统能否产生可追溯设计演化的合适试验场。
系统设计:让每个候选都来自受控的代码修改
AutoResearch-MLIP 的运行依托一套预定义的技能约束框架(skill-programmed harness),明确规定智能体的操作范围和行为边界。其中,MLIP-Evidence负责将论文、代码仓库和代码分析转化为结构化的设计证据;MLIP-Autoresearch 负责试验调度、评估对接、错误修复和继续决策。关键约束是:智能体只能修改候选MLIP的代码,不能更改评估器、数据划分或指标定义。
这套机制的核心作用是把"生成一个候选想法"变成"完成一次受控评估"。每个候选必须先被实现为代码修改,通过固定评估器,得到明确的结果记录,才进入继承、延迟或拒绝的后续流程——这是它进入可追溯研究轨迹的前提。
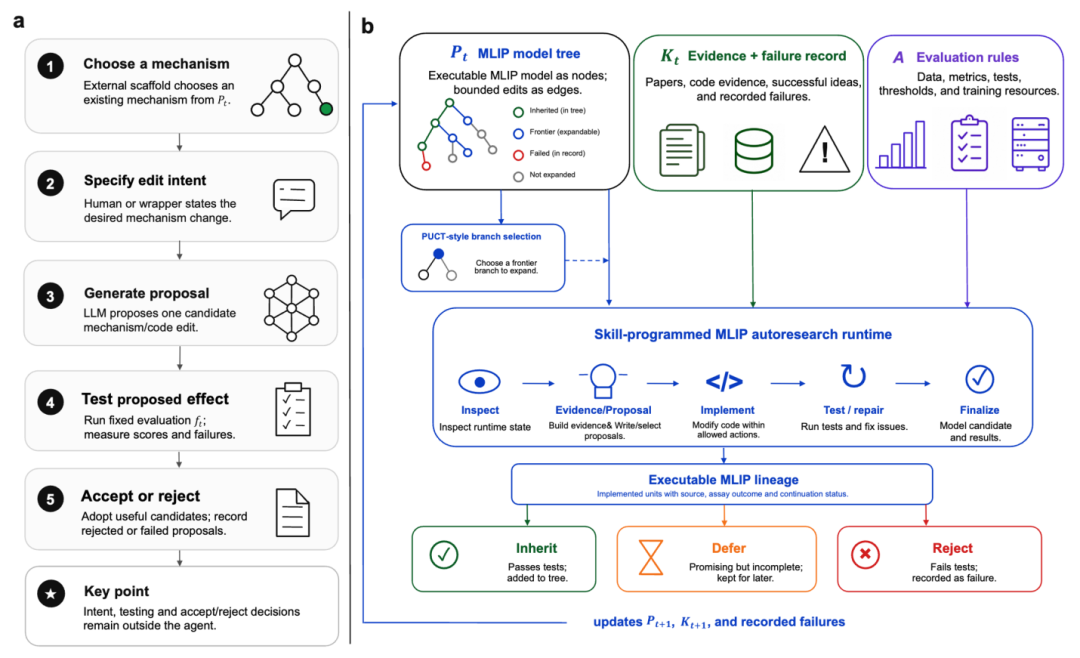
图 1|AutoResearch-MLIP 的基本流程。左侧是传统的一次性候选生成流程;右侧是 AutoResearch-MLIP:设计树、证据与失败记录、评估规则共同约束智能体的全部操作,构成有边界的自主科研运行框架。
从一个近零 MLP 出发:40 代、280 个候选
实验从一个刻意设计得很弱的初始模型出发——基于原子间距的近零MLP,可以运行、可以微分,同时作为整个演化过程的评分基准。
此后进行了40代演化,每代提出10个方向,通常选择8个候选实现并评估,共积累280个已评估候选。图2展示了整体演化轨迹:灰点是每代所有已评估候选,蓝线是每代最高分候选,橙线是实际被选为下一轮起点的候选。
两条线并不总是重合——这正是AutoResearch-MLIP的核心设计之一:最高分候选和研究延续方向是两个独立的决策。前者作为证据保留,后者可以选择分数较低但借鉴意义更强的分支继续展开。
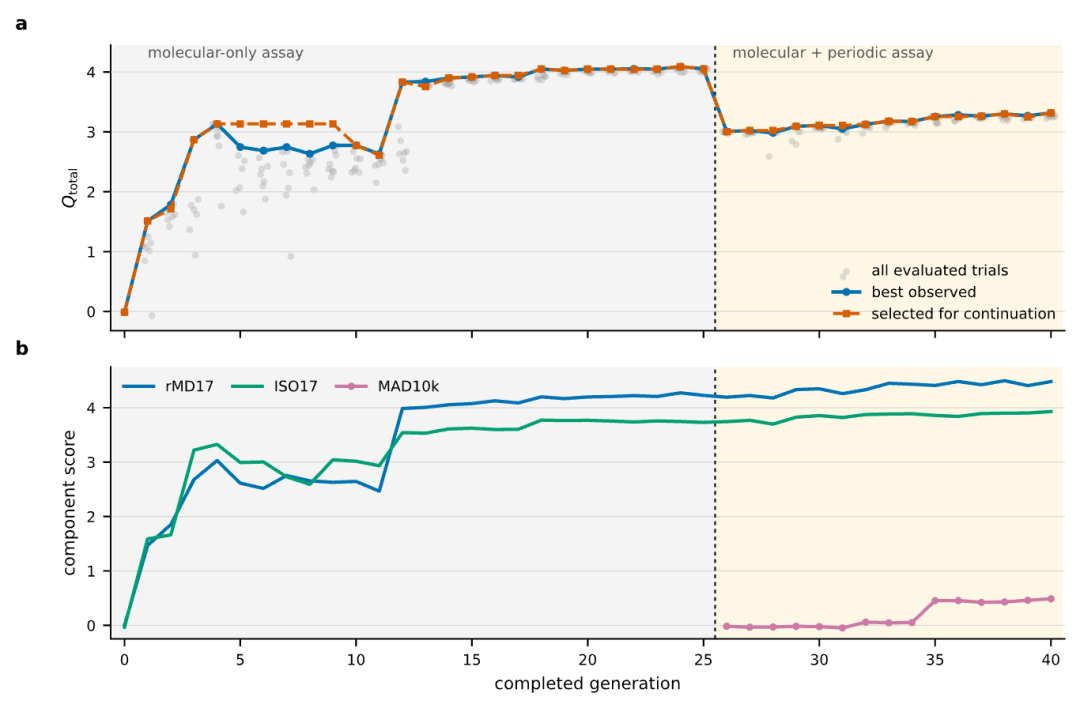
图 2|40 代评估轨迹。蓝线为每代最高分候选,橙线为实际选为下一轮起点的候选;虚线标出周期材料评估模块加入的位置。
设计模块在代际传承中逐步积累
图 3 展示的不是分数,而是被选为延续起点的代码中实际保留了哪些设计模块。
演化路径从初始pair-distance MLP出发,依次加入局域消息传递、读出层与组成建模、角度/高阶/张量特征、长程能量项,最后在周期性晶体训练阶段引入包含镜像偏移信息的周期性结构。蓝色方块标注某个模块首次加入或发生实质变化的位置;浅色单元表示该模块在后续延续起点的代码中被继续保留。
设计元素的积累不是线性的——高分候选可以留存为证据,而延续方向未必是当前最高分的那条分支。
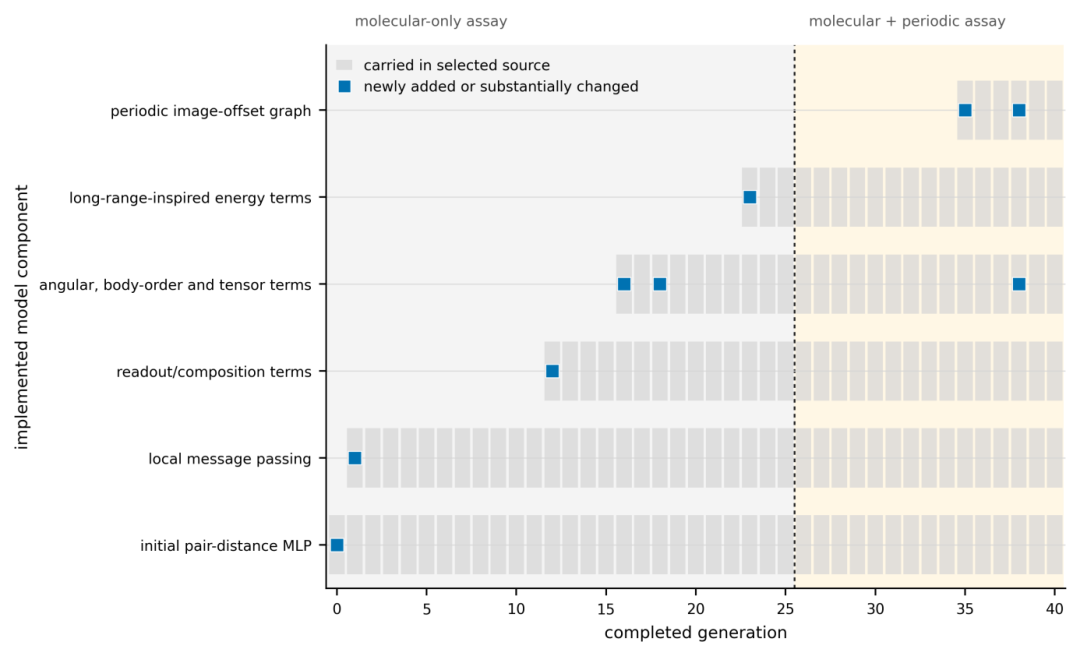
图 3|被选为下一轮起点的代码中实际携带的模型组件。浅色单元为被继承的模块,蓝色方块为新增或有实质改动的模块。
失败不只是低分——它是下一步的边界
AutoResearch-MLIP中,失败不等于低分,而是一类包含约束信息的结果记录。每次失败、对照实验或局部改进,都会被明确标注,并限制下一轮探索可以尝试什么、需要绕开什么。
几个典型例子:早期部分生成分支劣于保留的父代候选;中期某些单一模块的改进没能提升总分;周期材料阶段,单纯调整训练日程、截断半径或残差尾项,均无法让分子模型迁移到周期材料。这些失败记录进入系统记忆,直接改变了后续的搜索方向。
正因如此,系统采用非贪心延续策略:高分候选留存为证据,实际展开的分支可以是分数更低但研究价值更高的方向。
周期材料阶段:验证实现路径,而非重新发现物理规律
周期边界条件本身不是新知识。这一阶段真正要检验的是:从分子任务演化出来的模型,是否把晶胞和周期镜像信息正确传入了图结构。
G026到G034的系列尝试均未产生稳定的周期性信号——调整训练参数、截断平滑和残差项都不奏效。G035 的图修复改变了图的构造方式:将周期镜像作为独立邻边保留,并让镜像偏移信息参与消息传递。修复后,周期性材料相关的指标出现明显跃升。
随后,系统并未把G038的高分直接视为原因明确的进步。G039批次的所有子代均未超过G038,对照重训的得分也有所下降。系统因此保留G038作为当前最优证据,同时选择分数略低但归因更清晰的G039分支继续展开。G040从这一分支出发,最终达到当前评估下的新前沿。
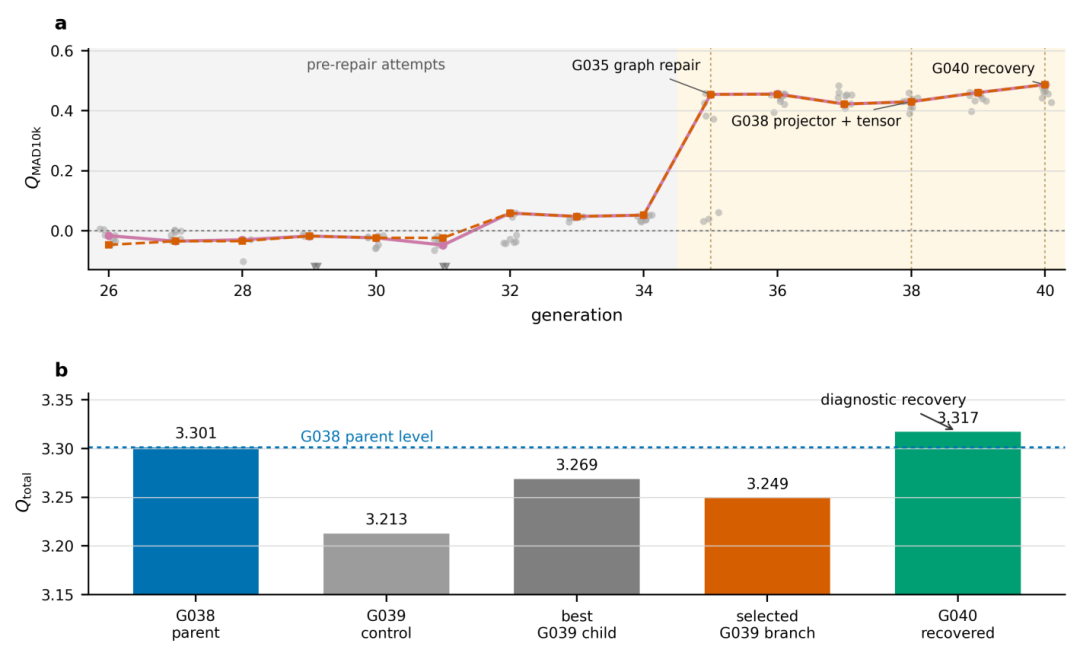
图 4|周期图修复与归因验证后的性能恢复。上图展示 G035 之后周期材料指标的跃升;下图展示 G039 归因验证如何将证据保留与延续方向的选择分开处理。
外部基准:演化结果不只适用于内部评估
内部评估器仅用于指导演化方向,不代表通用性。为此,研究对第40代候选进行了独立的外部验证,与 NequIP、Allegro、CHGNet、MatGL-M3GNet 在相同短训练条件下进行对比,且外部基准的结果未参与任何延续决策。
在MD22(大分子动力学迁移性测试)上,最终候选的能量误差接近NequIP,力误差低于NequIP和Allegro。在 Sub-OMat24(周期结构外部子集)上,力误差优于所有对比基线,但能量校准不如专为材料预训练设计的 MatGL-M3GNet——这在预期之内。
AutoResearch-MLIP不声称演化出了通用势函数。这组结果说明的是:通过连续演化得到的候选,在不针对外部基准做优化的前提下,也能在多项外部指标上表现出竞争力。
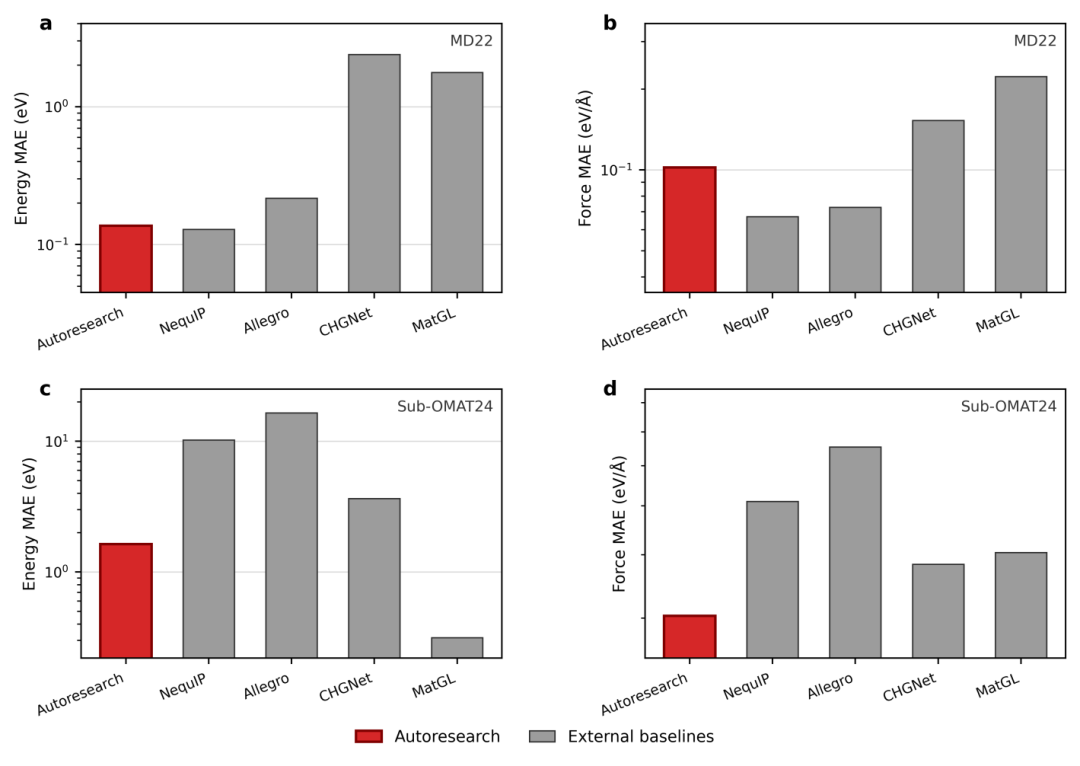
图 5|外部基准对比。红色为 AutoResearch-MLIP 最终候选(第 40 代),灰色为外部基线;结果均基于相同短训练协议。
下一步:从分数优化到表征演化
目前的评估器以能量误差和力误差为核心。一个自然的下一步是把评估目标推进到表征层:不只是让模型在某个基准上得分更高,而是演化出更可复用、更具可解释性的内部表示。
近期关于MLIP表征空间的研究发现,不同架构的模型在经过锚点投影后,原子环境在隐空间呈现出相近的几何结构。这提示未来的评估器可以进一步纳入跨模型的表征对齐、结构不变性的诊断信号。
如果这一方向走通,AutoResearch-MLIP的自主演化循环就不再只是搜索高分模型,而是朝着科学上更可复用、更可迁移的设计原则推进。
总结
AutoResearch-MLIP在机器学习力场这一真实科学建模问题上,构建了一套有迹可循的自主演化研究框架:智能体在固定评估规则下,将假设提出、代码实现、结果评估、失败记录和分支决策,连接成一套完整、可回溯的研究过程。
AutoResearch-MLIP由中国科大机器化学家团队与华为 MindSpore Science团队联合开发,已可通过"灵境造物"科研平台使用。
参考资料
Paper: Agentic, autonomous design evolution of machine-learned interatomic potentials
文章预印:https://chemrxiv.org/doi/full/10.26434/chemrxiv.15003852/v1
代码开源
https://github.com/pic-ai-robotic-chemistry/Agentic-auto-designed-MLIPs
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢