
2026年5月7日,来自Biohub公司、斯坦福大学以及Chan Zuckerberg Initiative机构的研究人员在《Science》上发表了一篇文章,题为“TranscriptFormer: A generative cell atlas across 1.5 billion years of evolution”。
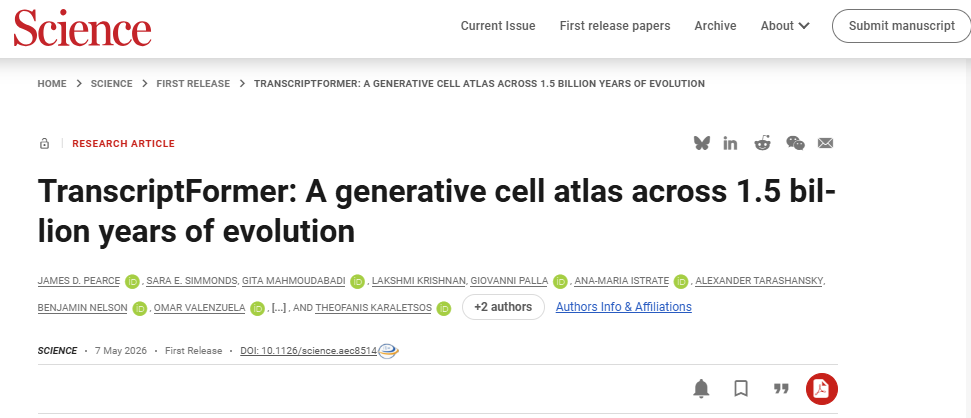
单细胞转录组数据已经覆盖大量物种和细胞类型,但不同物种之间基因同源性有限,传统跨物种比较常常受限。文章提出TranscriptFormer,一组生成式单细胞基础模型,试图在统一的嵌入空间中学习跨物种、跨细胞状态的表达规律。其最大版本TF-Metazoa使用来自12个物种的1.12亿个细胞进行训练,覆盖约15.3亿年的进化跨度,包括脊椎动物、无脊椎动物、真菌和原生生物。
背景
细胞基因表达的多样性驱动着从单细胞生物环境响应,到复杂有机体组织和器官中专门化细胞形成,再到物种进化创新的各级生物复杂性。理解基因表达程序如何产生细胞多样性,以及这些程序如何在进化中改变或保留,是生物学中的基础问题。
单细胞转录组数据的迅速增长已经覆盖生命树中数以亿计的细胞,这既带来机遇,也带来挑战。CZ CELLxGENE和人类细胞图谱等资源降低了访问标准化数据集的门槛,但跨物种比较和解释仍然困难。现有大型单细胞数据整合方法通常依赖同源基因集,而远缘物种共享的同源基因较少,因此限制了比较分析范围。
已有单细胞基础模型证明,无监督学习能够从转录组数据中提取有意义的生物表征,并支持细胞类型注释和基因调控网络推断等任务。然而,这些模型大多不是生成式模型,通常不适合零样本预测,往往需要针对每个任务微调,并且多局限于人类数据。这限制了其在比较细胞生物学中的应用。
为此,作者提出TranscriptFormer,一组大规模生成式单细胞基础模型,最多使用来自12个物种、跨越15.3亿年进化历史的1.12亿个细胞进行训练。模型学习基因及其表达水平的联合概率分布,从而能够表示细胞状态,并作为生物学探究的“虚拟仪器”。通过把ESM-2蛋白语言模型衍生的蛋白嵌入纳入训练,TranscriptFormer把不同物种的基因映射到共享的、物种无关的嵌入空间中。该设计允许模型跨物种学习细胞和基因表征,同时保留物种特异的生物学信息。作者评估了三个版本:覆盖12物种的TF-Metazoa、覆盖人类和4个模式生物的TF-Exemplar,以及只训练于人类数据的TF-Sapiens。
TranscriptFormer模型家族
TranscriptFormer是生成式自回归模型,它按序预测每个基因及其表达水平,把细胞转录组视为“细胞句子”。每一步预测都以此前已选择的基因为条件。模型通过最大化对数似然进行训练,除测序技术标识外,不依赖元数据即可从细胞测量中学习有生物学意义的特征。与UCE类似,模型用ESM-2蛋白嵌入表示基因标记。输出包括两类信息:一类是基因表达概率分布,另一类是编码细胞转录信息的嵌入向量。表达水平通过表达感知注意力机制编码,使高表达基因获得更强注意力,对预测产生更大影响。
作为基础模型,TranscriptFormer支持细胞类型分类、疾病状态预测和跨物种学习等多种下游任务。与纯嵌入方法不同,生成式训练还允许通过提示模型来预测转录因子靶标或模拟细胞响应,这些能力来自模型对转录关系的学习。
作者建立了三个变体。TF-Metazoa训练于来自6个脊椎动物、4个无脊椎动物以及真菌和原生生物外群的1.12亿个细胞;TF-Exemplar训练于人类、鼠、斑马鱼、果蝇和线虫;TF-Sapiens仅训练于5700万人类细胞。三个模型共享相同架构和评估时相同数量的活跃参数。
为了明确生成式架构的贡献,作者还构建了ESM2-CE基线:它使用相同输入表征,但通过平均ESM-2衍生的蛋白嵌入得到固定长度细胞嵌入,省略生成式建模部分。评估覆盖进化泛化、跨物种迁移和人类特异任务。
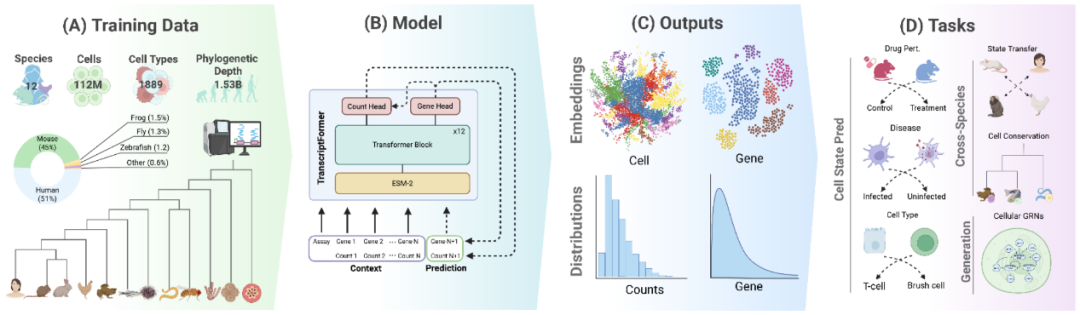
图1 TF-Metazoa的12物种训练范围、细胞句子输入、基因/细胞层输出,以及细胞类型分类、疾病状态预测和基因-基因相互作用模拟等应用。
细胞图谱预训练支持跨物种细胞类型与状态表征
作者首先评估模型对训练中从未见过的物种的泛化能力,包括鼠狐猴、热带爪蟾、海七鳃鳗和石珊瑚等。使用这些系统发育上差异明显的物种细胞图谱,作者以宏平均F1分数评估细胞类型分类表现,并与UCE和ESM2-CE基线比较。
TF-Metazoa和TF-Exemplar在远缘物种上保持稳健分类能力,即使在与人类分化约6.85亿年的石珊瑚上也保持较高F1表现;相比之下,UCE在远缘物种上的表现下降明显。多物种训练在匹配细胞数量的消融实验中也显示出优势,说明系统发育多样性本身能促进跨物种泛化。
随后,作者使用覆盖九个脊椎动物的精子发生数据集测试细胞类型注释的跨物种迁移。总体上,亲缘关系越近,迁移F1越高。例如狨猴到恒河猴的迁移表现接近各自自迁移水平。TranscriptFormer显著优于基线,尤其在鸡到哺乳动物等较远距离迁移中优势更大。
在灵长类背外侧前额叶皮层数据中,作者也观察到类似提升,说明这种迁移能力可推广到不同组织类型。最后,作者分析小鼠、大鼠、兔和猪骨髓来源单核吞噬细胞对LPS处理的炎症免疫应答迁移。TF-Exemplar和TF-Metazoa可以较好区分对照与6小时LPS处理状态,明显优于UCE和ESM2-CE。这些结果说明,TranscriptFormer既能捕捉稳定的细胞身份,也能捕捉跨物种保守的扰动应答表达程序。
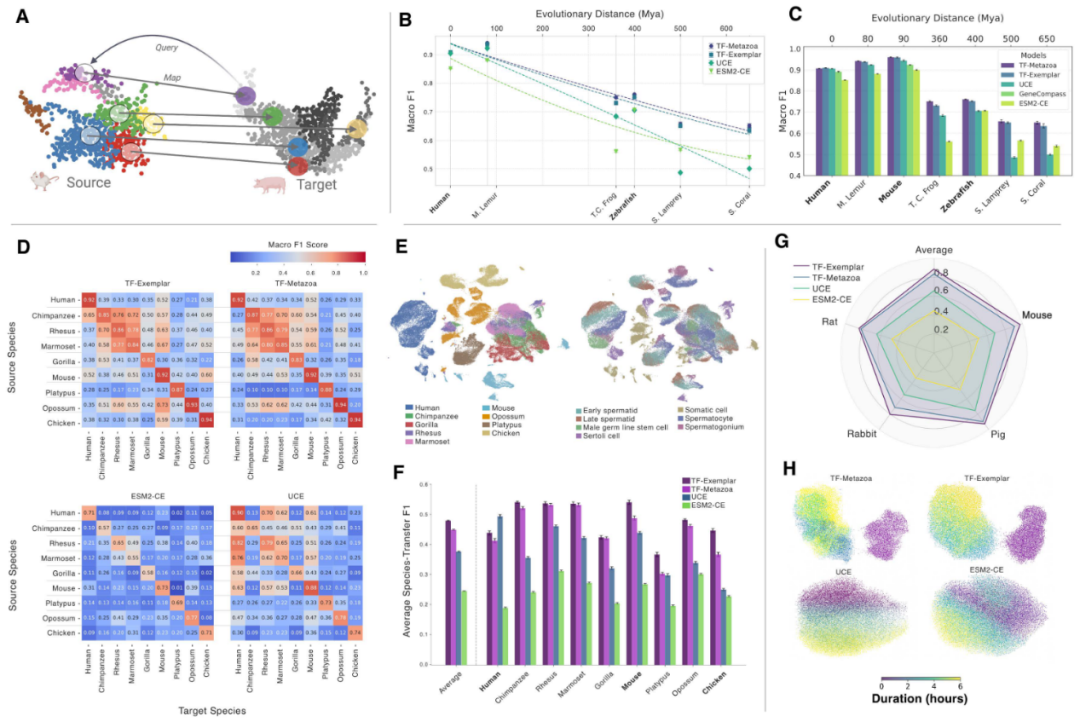
图2 参考映射策略、随进化距离变化的细胞类型分类F1、精子发生跨物种迁移矩阵、UMAP嵌入,以及LPS炎症应答迁移结果。
TranscriptFormer跨生物情境推断人类细胞状态
作者接着评估TranscriptFormer在多种人类生物情境中的泛化能力,包括细胞类型分类、疾病状态预测和药物扰动响应。细胞类型分类使用Tabula Sapiens 2.0中新近、未发表的部分数据作为测试集,这些数据未进入TranscriptFormer训练,也晚于所有基准模型的训练数据。
在Tabula Sapiens 2.0任务中,TF-Exemplar取得最高宏平均F1,TF-Metazoa和TF-Sapiens紧随其后,并与UCE相当或略优。虽然多数细胞类型接近饱和表现,但在髓系白细胞、T细胞和先天淋巴样细胞等困难类别上,TranscriptFormer和UCE较其他模型保持更高分数。多物种预训练没有削弱人类分类表现,反而略有提升。
在疾病状态预测方面,作者使用未纳入训练的SARS-CoV-2感染数据集和胶质母细胞瘤肿瘤/正常数据集。SARS-CoV-2任务中,TF-Sapiens得分最高,TF-Exemplar和TF-Metazoa紧随其后,均明显优于UCE、scGPT和Geneformer。嵌入空间中感染与未感染细胞的分离支持模型捕获了感染特异的转录变化。
药物扰动评估使用Tahoe-100M数据集样本,把任务设为DMSO对照与药物处理的二分类。TF-Sapiens在95种扰动中取得最高平均AUC,优于UCE、scGPT和scVI。部分药物如TAK-901、Bortezomib和PH-797804几乎可被完美区分,说明模型能在不同细胞系中识别强而一致的药物诱导转录签名。
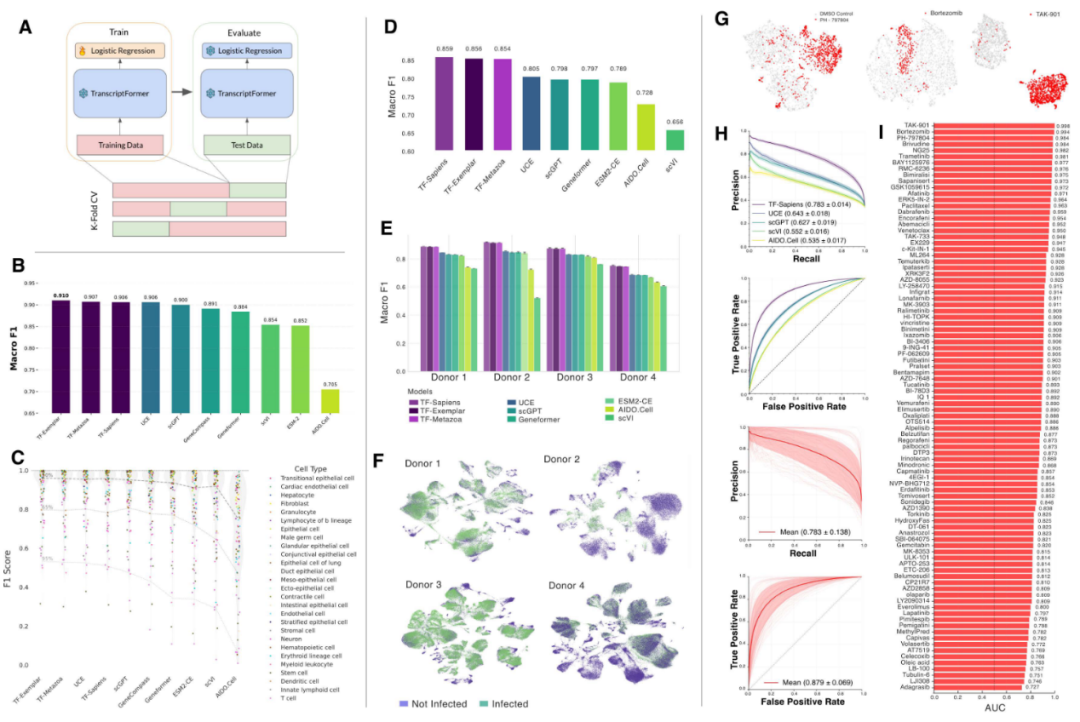
图3 线性探针流程、Tabula Sapiens 2.0分类结果、SARS-CoV-2感染状态预测,以及Tahoe-100M药物扰动的UMAP、PR/ROC曲线和AUC比较
细胞与基因嵌入中涌现的层级生物结构
作者进一步考察TranscriptFormer是否在内部表征中学习到有意义的生物结构。模型能够计算上下文化基因嵌入(CGEs),即在特定细胞句子上下文中对单个基因的表示。尽管同一基因的输入ESM-2嵌入相同,CGEs仍主要按细胞类型聚类,说明模型能够捕获细胞类型特异的上下文。
共享细胞类型在不同组织之间的CGE分析显示,模型可以在零样本条件下捕捉同一细胞类型在不同组织中的细微转录差异。模型还对供体特异的转录变异敏感,能在同一细胞类型和组织中按供体分离。方差分解分析显示,细胞类型信息在CGE空间中占主导,组织和供体作为次级因素贡献较小但可检测。
在细胞层面,精子发生数据中的嵌入能重现雄性生殖系分化的经典阶段顺序;TF-Metazoa嵌入的物种间余弦相似度随进化距离增加而下降,而ESM2-CE不呈现这种相关性。这说明单纯蛋白序列相似不足以形成同样的系统发育结构,大规模转录组训练是关键。
作者还构建了160万细胞的多物种发育细胞图谱,用TranscriptFormer寻找跨物种最相似细胞。模型能够在猪和兔、爪蟾和斑马鱼、斑马鱼和兔等不同进化距离上恢复保守细胞类型类别,例如神经、内皮、肌肉、免疫和造血相关细胞。更具探索性的是,作者将淡水海绵的领细胞和神经样细胞映射到线虫与爪蟾。海绵领细胞对应到两种动物中的初级感觉神经元,而神经样细胞对应到分泌腺细胞。这一结果与“早期神经细胞可能类似纤毛感觉细胞”的假说相一致,但作者也强调跨界比较的生物解释需要谨慎。
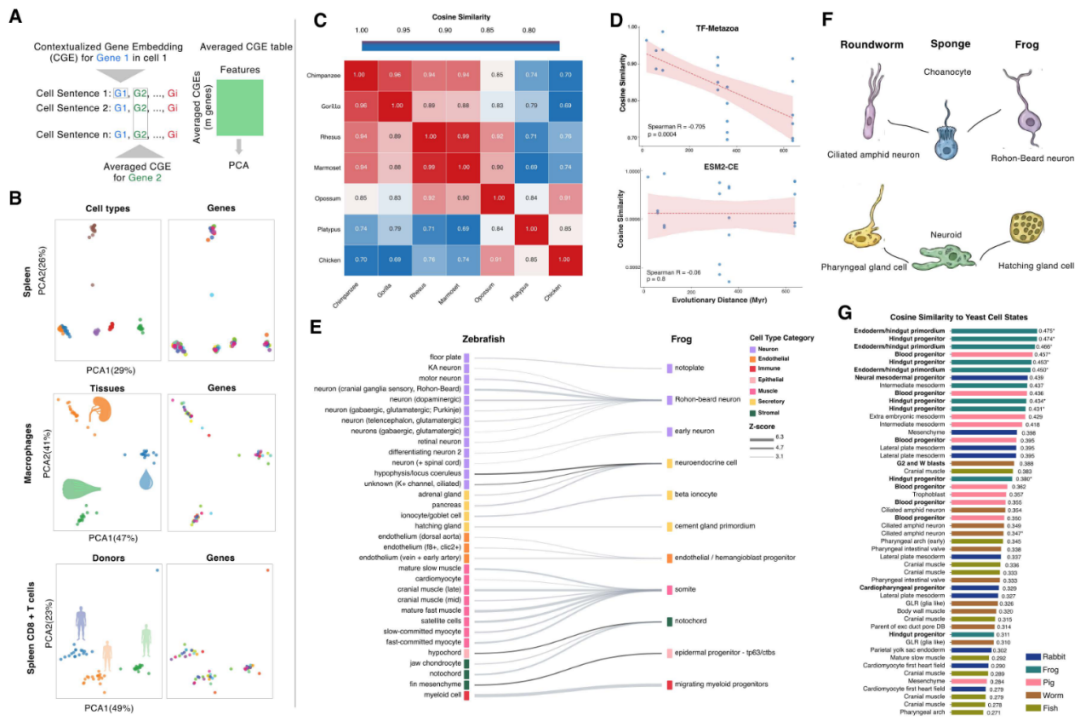
图4 CGE的PCA、物种嵌入相似度矩阵、相似度与进化距离相关性、斑马鱼-爪蟾发育细胞图谱Sankey映射、海绵细胞到两侧对称动物细胞的映射,以及酵母与动物胚胎祖细胞状态的跨界分析。
通过提示把TranscriptFormer作为虚拟仪器
TranscriptFormer对细胞中基因和表达水平的联合分布建模,类似生成式语言模型。作者利用这一生成能力,把模型作为“虚拟仪器”,通过提示提出复杂的细胞生物学查询,而不必重新汇编大量实验数据。
第一个提示任务是预测转录因子与其他蛋白编码基因之间的功能关联。作者计算转录因子-基因对之间的点式条件互信息(PMI),并用校正后的显著性阈值识别高置信关联。PMI可以捕捉在相同细胞上下文中共同表达的统计依赖,同时校正高基线表达基因。为了验证预测,作者将结果与STRING v12.0数据库中的功能关联进行交叉比对,并通过置换检验建立随机期望。TF-Sapiens对多个功能不同的转录因子给出了高度富集的已验证关联。例如,模型把细胞周期调控因子E2F8、FOXM1和MYBL2连接到复制、纺锤体和有丝分裂调控相关基因;也把SPIB与B细胞标记相关联,把UHRF1与复制压力和检查点因子联系起来。
第二个提示更复杂:作者以Tabula Sapiens 2.0中人类特定细胞类型的标记基因为条件,生成112个已知人类转录因子在细胞类型中的条件表达概率。模型生成的热图重现了经验数据中常见的全局结构:一类是跨多种细胞类型广泛表达的垂直条带,另一类是沿对角线排列的细胞类型特异转录因子。
这些结果说明,TranscriptFormer在预训练中内化了复杂基因调控网络,可在未见数据分布上给出有生物学意义的预测。作者据此提出,未来的细胞图谱不应只是数据查询表,而可以成为可交互、可模拟的知识模型。
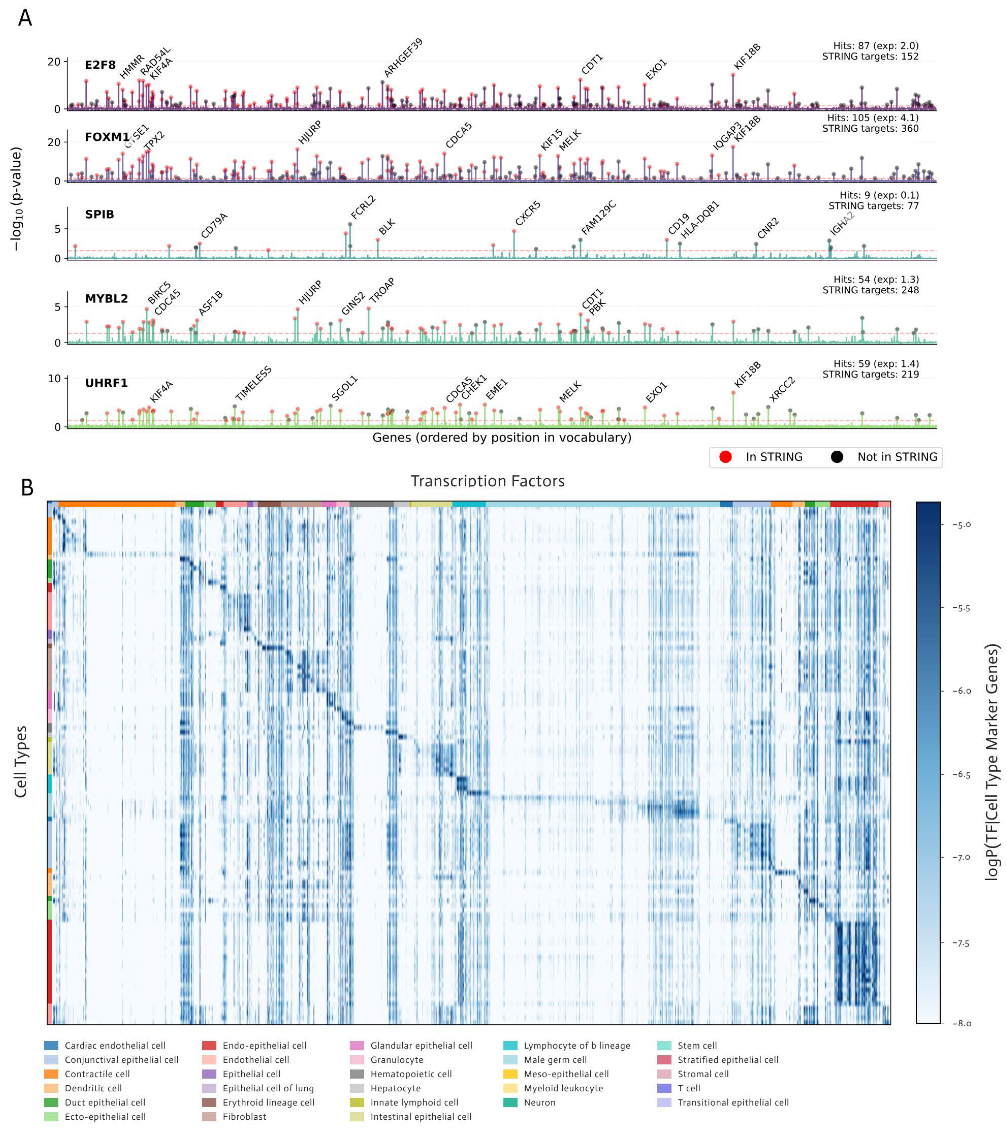
图5 A为选定转录因子的PMI谱,STRING注释基因以红色标出;B为TF-Sapiens预测的112种人类细胞类型中转录因子表达对数概率热图。
总结
TranscriptFormer通过在15.3亿年进化跨度上整合转录组数据,推进了生物学基础模型的发展。研究显示,结构设计创新与同时建模基因和表达计数的生成式预训练可以超过此前方法;对于跨物种任务,多物种预训练带来额外收益。
TF-Metazoa和TF-Exemplar在人类Tabula Sapiens 2.0分类任务上优于或接近TF-Sapiens,说明更广的进化预训练可能增强一般化的生物学泛化能力;但TF-Sapiens在疾病相关任务上表现更好,提示当目标任务处于特定物种训练域内时,物种特异训练仍具优势。不同多物种模型也存在任务依赖差异:TF-Exemplar在跨物种迁移学习中倾向于更强,而TF-Metazoa在对进化上更远物种的泛化中略占优势。这一权衡提示模型选择应由应用目标决定:进化分析和迁移学习适合跨物种模型,精细人类细胞状态和疾病建模适合物种特异模型。除基准测试外,TranscriptFormer的生成式接口使其能够作为生物学探究的虚拟仪器。模型可通过提示生成细胞类型特异转录因子预测和基因-基因相互作用,从而用于假设生成。上下文化基因嵌入和细胞嵌入则展示了模型无需显式监督即可编码从细胞类型到组织再到供体差异的多层次结构。未来工作需要扩大物种多样性,更统一地处理批次效应,并整合转录组以外的更多模态。TranscriptFormer为这一愿景建立了框架,展示机器学习如何帮助统一理解跨进化时间的细胞多样性。
参考链接:
James D. Pearce et al. ,TranscriptFormer: A generative cell atlas across 1.5 billion years of evolution.Science0,eaec8514
DOI:10.1126/science.aec8514
--------- End ---------
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢