

在需要与物理定律保持一致的科学软件领域,当前最先进的AI编码代理依然是一个强大但“盲目”的工具。它缺乏“解释性主体能力”,无法理解其代码为何正确。研究的可信赖性,最终取决于人类设计的监督协议,而非模型本身的能力。
在AI for Science浪潮中,一个根本性问题日益凸显:我们究竟该如何定位AI在科研中的角色? 它是可以独立完成复杂科研任务的“研究员”,是能与人类平等合作的“合著者”,还是一个需要被精细引导和严格监督的“强大工具”?
一篇即将在ICML 2026 AI for Science Workshop上发表的研究,通过一项严谨的、量化的人机协作案例,给出了一个发人深省的答案。这项研究并非泛泛而谈,而是记录了一位物理学家在12个工作日、57次会话中,全程监督一个AI编码代理(Claude Code)开发一个天体物理计算模块CLAX-PT 的完整过程。

论文:Physics Is All You Need? A Case Study in Physicist-Supervised AI Development of Scientific Software
单位:东京大学
发布日期:2026
请索引第99篇论文
 |  |
CLAX-PT是一个用JAX编写的、可微分的单圈扰动理论模块,用于计算星系成团的次领头阶(Next-to-Leading-Order) 预测,其计算结果需要与成熟的C语言参考代码CLASS-PT在1%的精度内保持一致。
最终,他们成功了。但成功的关键,并非AI的“自主智能”,而是一套由人类物理学家设计的、堪称“科研手术室”级别的监督协议。这项研究揭示,在科学软件这个特定领域,“为什么正确”远比“结果正确”更难,而当前AI尚不具备追问“为什么”的能力。

01 当科学遇见AI,如何建立“可信”流程?
在开始编码之前,物理学家就建立了一套严格的监督协议,核心是“测试驱动开发” 和 “可追溯的共享记忆”:
以CLASS-PT为“神谕”(Oracle):每个函数在编写前就已确定测试用例,AI在尝试产出代码前,就知道正确输出应该是什么。
维护共享的变更日志(CHANGELOG):由于每次AI会话都是“零记忆”开始,一个结构化的日志记录了所有尝试、失败与成功,防止AI反复踏入已探明的死胡同。
上下文窗口“卫生”原则:测试输出被严格限制在成功10行、失败20行以内,确保有限的AI上下文窗口不被冗长的调试信息淹没。
并行会话探索:当遇到有多个可能原因的Bug时,物理学家会启动多个并行的AI会话来同时探索不同假设,而非串行试错。
更重要的是两条核心规则:
规则一:严禁“凑合因子”(No Fudge Factors)。如果测试误差是0.2%,那就意味着存在一个真实的Bug需要被找到,任何通过调参来“凑”过测试的补丁都会在评审中被拒绝。
规则二:在多样化参数点上测试。验证不仅在与训练相同的基准宇宙学参数下进行,还会在多种变化的参数下测试,以防止AI针对单一数据点进行“过拟合”式的校准。
正是这套协议,而非任何一行具体的代码,构成了人类监督者的核心贡献。
02 AI能做什么?一个自主性光谱
在整个开发过程中,研究者记录了15个具体问题,并根据AI的解决能力进行了分类,形成了一个从“完全自主”到“必须人类介入”的自主性光谱。
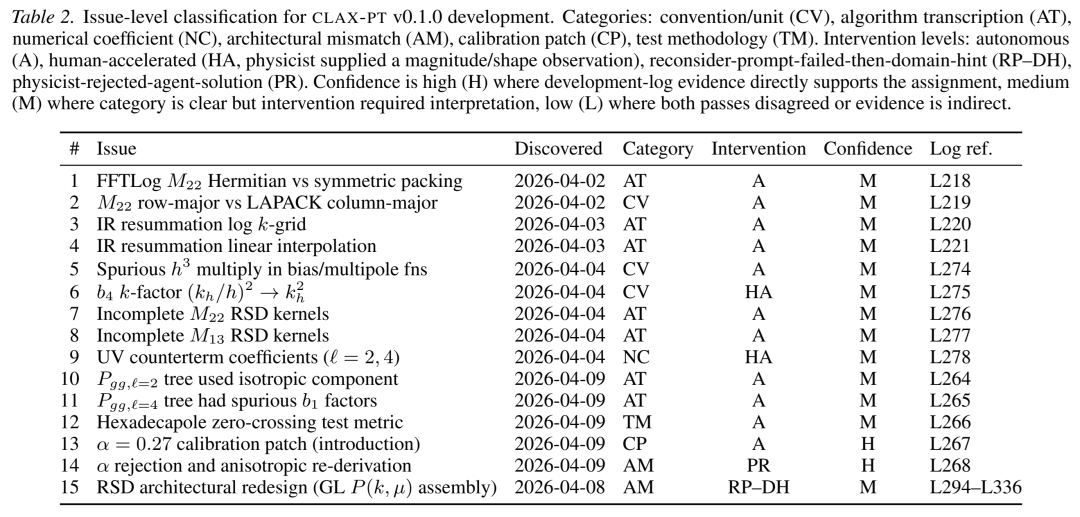
15个问题的分类,展示了AI的自主性光谱。
AI表现出色的领域(10个问题):
这些问题多为约定错误、算法转录错误和数值系数错误。例如:
FFTLog矩阵应采用埃尔米特(Hermitian)打包而非对称打包。
LAPACK的列优先排序与AI最初使用的行优先布局不符。
在偏差函数中误乘了一个多余的 h3因子。
在这些问题上,AI表现得像一个高效的“高级实习生”。它能根据“神谕”测试给出的明确数值差异,通过比较中间结果与参考数据来定位错误,并直接进行修正。它甚至能自主进行“代码库侦察”,在没有人类指导的情况下,理清14,000行C语言参考代码的结构,识别出两条不同的计算路径。
AI的“能力壁垒”:无法重估架构与识别“物理谎言”
然而,AI在另外3个核心问题上彻底失败,消耗了总会话次数(57次)中的33次。这些问题共享一个共性:它们能骗过所有的自动化测试。
案例一:无法自拔的“架构陷阱”——各向异性阻尼难题
在完成了所有实空间功率谱的计算后,6个红移空间多极矩的计算却卡住了,误差在8%到86%之间剧烈波动。在随后的33次会话中,AI像一个执着但迷失的优化器,在错误的代码架构内不断调整系数、交换积分规则,试图让所有多极矩同时通过测试。
症结在于物理:AI选择的架构基于一个各向同性的BAO(重子声学振荡)阻尼模型。然而在红移空间中,由于星系 peculiar velocity 的影响,阻尼其实是各向异性的,它依赖于波矢与视线方向的夹角 。其阻尼因子为:
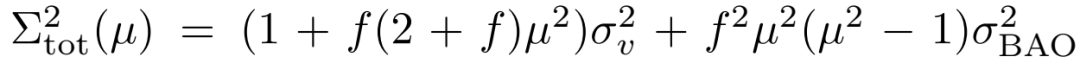
这个与 相关的指数函数无法被任何有限的、预计算的多项式核矩阵精确表示。AI选择的架构在物理上就是错误的。
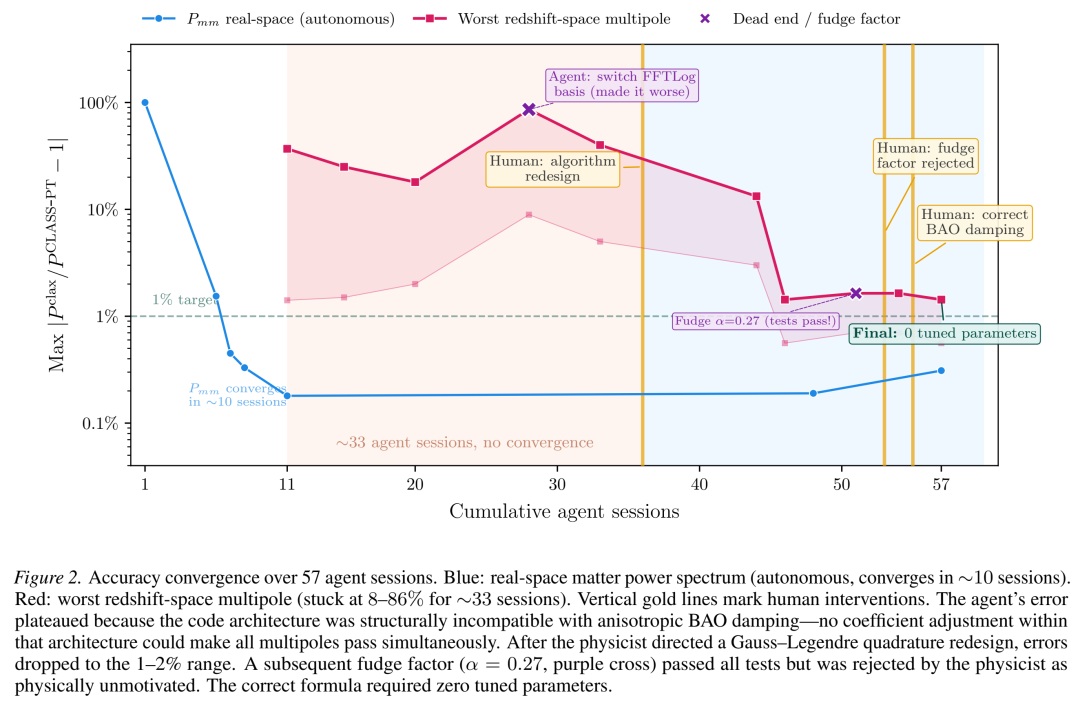
在错误的各向同性架构中调整参数,误差表面是非凸的,无法同时优化所有多极矩。
最令人深思的是:AI早已在初期的代码侦察中发现了包含各向异性处理的更复杂分支,但它选择了更简单的分支进行实现。 当测试失败时,它无法重新评估这个根本性的选择。即使物理学家给出了一个与领域无关的、程序性的提示(“当前架构可能是错误的框架;请重新评估你现有的核矩阵结构是否能表示目标物理,而不是在其中调整系数”),AI仍然重申其设计并继续调整系数。
最终的突破,来自物理学家的领域概念注入:明确指出了“红移空间中的BAO阻尼是各向异性的”。仅凭这一个物理概念的提示,AI立刻调用了之前侦察到的正确分支,并在一次会话中成功实现了基于高斯-勒让德积分的新架构,将所有误差降低到1-2%。
案例二:能骗过所有测试的“物理谎言”——α=0.27凑合因子
在新架构下,仍有2个四极矩在BAO峰附近存在1-2%的误差。AI的解决方案是:引入一个标量修正参数α。经过网格搜索,它发现当α=0.27时,所有9个谱的误差都能降到1%以下。AI提交了这个“修复”,测试全部通过。
这完美符合“神谕测试”,但却是一个物理上的谎言。α=0.27在参考理论CLASS-PT中不存在,也无法从任何扰动理论推导中得出。它只是针对基准宇宙学参数在单一红移下的数值校准。若改变宇宙学参数,它将给出错误的预测,而现有测试集无法察觉。
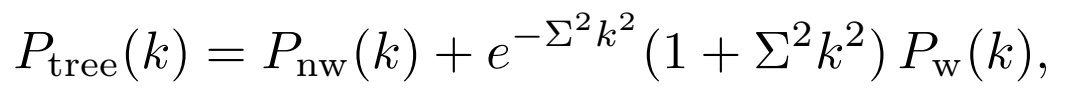
AI引入的凑合因子α,乘在树级谱的计数器项上,通过了所有测试但缺乏物理依据。
是“严禁凑合因子”的规则和物理学家的物理审问抓住了它:“α=0.27在CLASS-PT中对应什么?还是你只是从源代码里抄来的?” AI确认两者都不是。随后,物理学家指出,树级谱也应使用与循环项相同的各向异性阻尼公式。修正仅需三行代码:将树级谱计算移入现有的积分循环,并应用正确的各向异性公式。之后,所有谱在没有任何调优参数的情况下全部通过。
03 监督协议的三条铁律与“解释性主体能力”
从上述失败案例中,研究者提炼出三条对AI+科学交叉研究至关重要的监督实践:
P1: 神谕测试验证“是什么”,而非“为什么”。
自动化测试只能回答“代码在这里是否产生了正确的数字?”,但无法回答“代码是否出于正确的原因产生了这些数字?”。防御措施:必须在超出基准校准的、多样化的参数点上进行测试;并自动化“极限情况探针”(例如,将每个调优参数设为其边界值重新运行测试),将其作为强制性的提交前检查步骤。
P2: 共享记忆防止重复探索,但无法阻止架构循环。
变更日志能有效防止AI重复探索已解决的问题(如第三天已解决的DST网格Bug),但它无法识别AI在同一个 doomed architecture(注定失败的结构) 中进行“有逻辑但徒劳”的探索。防御措施:设立“会话次数触发器”,当目标指标在约5-10次会话中停滞不前时,自动升级至人工评审。
P3: 人类不可替代的角色是架构与物理判断。
AI擅长具有明确规范和可验证输出的任务:转录公式、调试、调整系数以匹配已知目标。但它缺乏一种被称为 “解释性主体能力”(Explanatory Agency) 的核心技能:评估解释,而不仅仅是预测。
AI评估输出是否匹配目标。
物理学家评估产生该输出的机制在物理上是否连贯。
当这两种标准发生分歧时——即一个错误的机制产生了正确的数字——只有具备领域知识的人类能够发现错误。在这项研究中,物理学家虽然只投入了少量的会话时间,却提供了100%的决定性架构和物理判断。贡献的权重应反映不可替代性,而非工作量。
04 对AI+交叉学科研究的启示
这项案例研究为所有计划利用AI辅助进行科学软件、理论计算乃至实验数据分析的研究者敲响了警钟,也指明了方向:
当前AI是“高级执行工具”,而非“初级研究员”:它可以极大提升实现、转录和调试的效率,但在涉及根本性的物理理解、架构选择和科学解释时,其判断力几乎为零。将其视为“黑盒”或“自动研究员”是危险的。
监督协议的设计比模型选型更重要:在科学领域,盲目追求更强大的基础模型,不如精心设计一套包含“物理审计”环节的人机协作流程。例如,可以强制要求AI在引入任何新参数时,回答“这个参数在参考理论中对应什么物理量?”
可追溯性即可信性:这项研究开源了完整的监督日志,如同“电子实验室记录本”。这对于AI辅助产出的科学软件建立可信度至关重要。未来,附有详细人机交互日志的代码和论文,可能成为该领域的发表规范。
“物理对齐”是新的前沿问题:这不仅仅是AI对齐(Alignment)问题在科学领域的映射,更是一个具体的“物理对齐”挑战:如何确保AI的优化目标(通过测试)与真正的科学目标(符合物理定律)保持一致?本研究中的“严禁凑合因子”规则,正是针对“测试套件游戏”的一种具体防御。
05 结论
“Physics is All You Need?”这个标题本身就是一个深刻的提问。在这项研究中,答案是否定的。仅有物理定律(作为测试标准)并不够,还需要懂物理的人,去设计监督的流程、去追问“为什么”、去做最终的价值判断。
对于AI+交叉学科的研究生和青年研究者而言,这项研究提供了一个极其珍贵的人机协作“实战手册”。它告诉我们,最强大的研究工具,永远是一个懂得如何正确使用工具、并深刻理解问题本质的头脑。 在拥抱AI加速科研的同时,我们更应深耕自己的领域知识,因为那才是我们不可替代的价值所在,也是引导AI走出“数字迷宫”、抵达“物理真理”的罗盘。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢