

投稿作者:浙江大学 April团队
近年来,大语言模型与多模态模型正推动智能体进入更复杂的开放世界游戏。不同于传统问答,游戏智能体需要在持续变化的环境中完成长时程决策,包括观察画面、规划任务、使用工具以及失败恢复,而这也带来了 planning、latency 与 memory 之间的核心矛盾:深度推理更稳健,但成本高;轻量反应更高效,却容易陷入错误循环。
针对这一问题,来自浙江大学的研究团队及其合作者提出了 SPIKE——一种面向长程游戏智能体的自适应双控制框架。SPIKE 通过战略控制与快速反应协同,仅在必要时触发高成本推理,实现了效率与鲁棒性的平衡。在星露谷物语这款游戏的StarDojo Lite-100 基准上,SPIKE 在成功率、token 消耗与延迟等指标上均显著优于现有方法,验证了“选择性推理”相比“每步推理”更高效、更稳定。

论文:https://arxiv.org/pdf/2605.18636
GitHub:https://github.com/wencanjiang/SPIKE
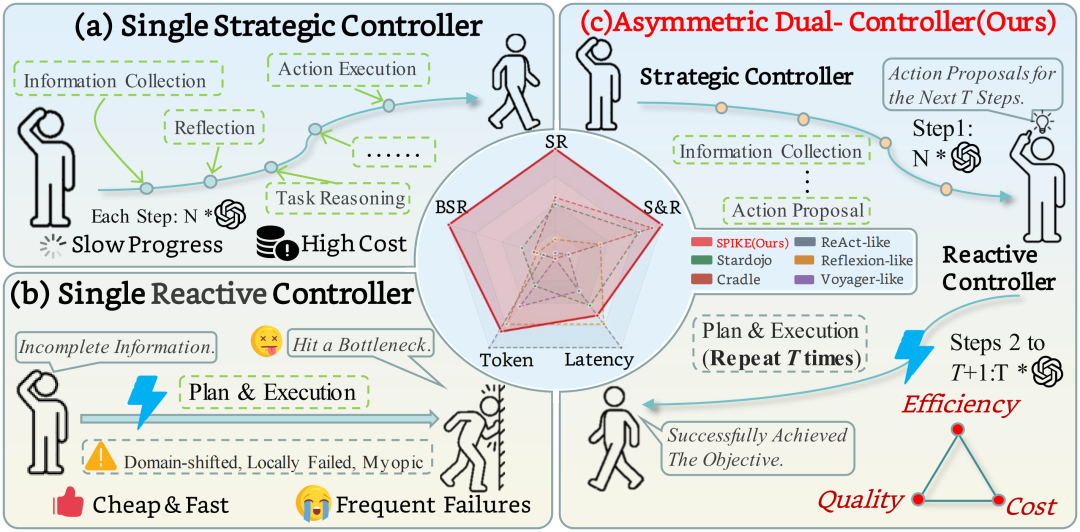
图 1 | 长程游戏智能体的三难困境。单一战略控制器推理强但成本高,单一反应控制器成本低但容易卡住,SPIKE 通过事件触发的双控制器机制在两者之间动态切换。
SPIKE 把推理本身看作一种需要调度的预算资源,而不是将长程游戏智能体的提升简单归结为“调用更强模型”或“增加更多记忆”。对于开放世界游戏、复杂软件操作和多步骤具身任务来说,学会在关键转折点重新思考、在稳定阶段低成本执行,可能是提升智能体实用性的关键路径。
SPIKE 如何把推理花在刀刃上
SPIKE 将智能体拆成两个控制器:Strategic Controller 负责低频的全局规划、失败分析和恢复;Reactive Controller 负责高频、低成本的局部执行。两者之间由 Event Trigger 协调。当系统检测到视觉突变、进展停滞、动作重复或执行失败时,才升级到 Strategic Controller 重新规划;否则就让 Reactive Controller 继续快速执行。
同时,SPIKE 使用 Hierarchical Memory 区分不同类型的记忆:State-Action Memory Bank 用于局部动作复用,State-Action Knowledge Graph 用于结构化规划证据,避免把所有历史经验混成一个嘈杂的检索池。
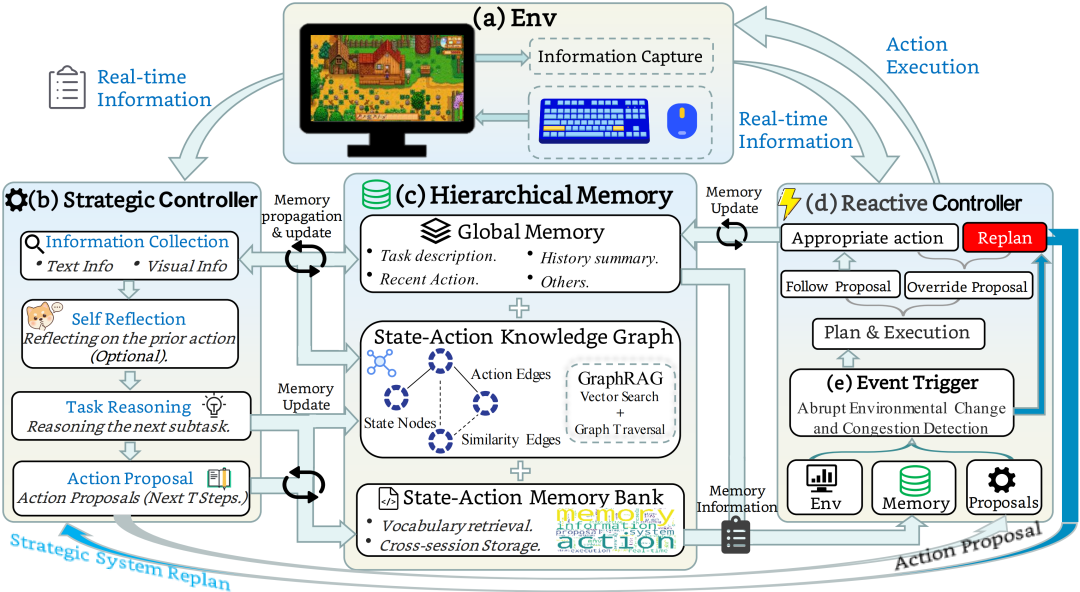
图 2 | 系统由环境信息捕获、Event Trigger、Strategic Controller、Reactive Controller 和 Hierarchical Memory 组成,在执行、触发、规划和记忆更新之间形成闭环。
1.SPIKE:让智能体学会“该想时想,该做时做”
在执行过程中,SPIKE 会先从游戏画面、UI 信息、任务进度和执行反馈中获取当前状态,再由 Event Trigger 判断是否出现关键事件。如果环境仍然稳定,系统不会反复调用昂贵的战略推理,而是让 Reactive Controller 基于短程计划和局部记忆继续执行。
一旦智能体出现卡住、失败、动作重复或明显场景变化,SPIKE 才会切换到 Strategic Controller。此时系统会重新收集状态信息,分析失败原因,并生成新的短程计划。动作执行结束后,成功经验、恢复行为和有效规划证据会被写回层次化记忆,为后续任务提供可复用的依据。
这种设计的关键在于:SPIKE 把推理当成一种预算资源,只在最值得花的时候花。
2.Event Trigger:什么时候该重新思考?
在长程任务中,并不是每一步都值得调用昂贵的战略推理。SPIKE 的 Event Trigger 会持续监控几类信号:执行反馈是否显示失败;距离上次战略规划是否已经过久。当这些信号表明当前计划可能失效时,系统才会升级到 Strategic Controller。否则,Reactive Controller 会继续利用已有计划完成局部动作。
这让 SPIKE 避免了两种极端:既不会像 always-strategic agent 那样每一步都重新规划,也不会像纯 reactive agent 那样在错误路径上反复尝试。
3.Hierarchical Memory:不是记更多,而是记得更合适
长程游戏任务需要记忆,但不同控制器需要的记忆并不一样。
Reactive Controller 需要的是“当前这种局部状态下,以前什么动作有效”。因此 SPIKE 使用 State-Action Memory Bank(SA-MB) 存储低延迟的局部动作经验,帮助智能体快速复用成功行为。
Strategic Controller 需要的是“当前任务为什么失败、哪些状态和动作之间存在可靠关系”。因此 SPIKE 使用 State-Action Knowledge Graph(SA-KG) 存储结构化证据,用于检查计划、分析失败和重新规划。
这种分工让记忆不再只是一个越来越长的历史窗口,而是变成面向控制器角色的证据系统。

图 3 | SPIKE Workflow
研究成果
1.StarDojo实验:更高成功率,更低成本
团队在 StarDojo Lite-100 上评估 SPIKE。Lite-100 包含 100 个开放世界游戏任务,覆盖 farming、crafting、exploration、combat 和 social interaction 五类任务。
SPIKE 的 Budgeted SR 达到 21.6%,高于最强 budgeted baseline StarDojo 的 12.3%,提升 9.3 个百分点。
同时,SPIKE 并不是靠花更多计算换来提升。相比 CRADLE,SPIKE 将 token 消耗从 372.5k / task 降到 168.1k / task,降低 54.9%;延迟从 73.5s / step 降到 43.5s / step,降低 40.8%。
恢复能力上,SPIKE 的 Recovery/Stuck Ratio 达到 2.75,也优于所有主要 baseline。
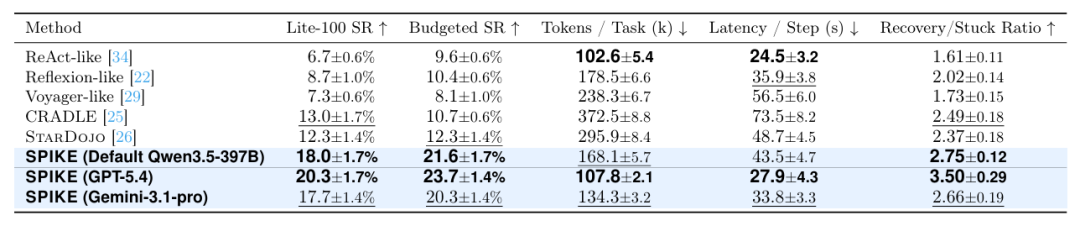
图 4 | StarDojo Lite-100 主结果。SPIKE 在成功率、预算内成功率、token 消耗、延迟和恢复能力之间取得更好的 trade-off。
这说明 SPIKE 的收益并不是来自某一类任务的偶然优势,而是来自更通用的控制机制:在稳定阶段低成本执行,在关键阶段重新规划,在失败后利用结构化记忆恢复。
当然,combat 和 social 仍然是最困难的任务类别。前者涉及动态敌人和复杂空间导航,后者往往需要更长距离的路线规划和交互顺序管理。这也说明,当前长程游戏智能体还远没有“解决”开放世界任务。
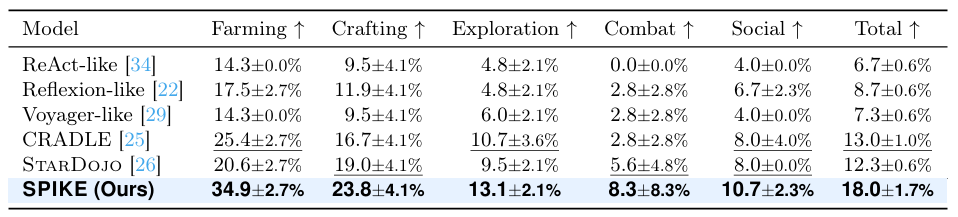
图 5 | Lite-100 任务类别结果。SPIKE 在五类任务上均取得最高平均成功率,但 combat 和 social 仍然是主要挑战。
2.消融实验:收益来自哪里?
消融实验进一步说明,SPIKE 的提升不是简单来自“多加了一个控制器”。
如果只使用 Strategic Controller,智能体虽然具备较强规划能力,但成本明显偏高;如果只使用 Reactive Controller,成本更低,但成功率和恢复能力不足。
完整 SPIKE 的优势来自三部分协同:
Event Trigger 决定什么时候值得升级到战略推理;Reactive Override 允许局部执行时进行有限纠错;
Hierarchical Memory 为不同控制器提供不同证据。
移除 Event Trigger 或 Reactive Override 后,Lite-100 SR 都会从 18.0% 降到 15.7%。将 Hierarchical Memory 替换为普通 Global Memory 后,SR 会降到 12.3%。移除 SA-MB 或 SA-KG 也会削弱成功率和恢复能力。
这说明 SPIKE 的关键不是“多记一点”或“多想一点”,而是把推理、执行和记忆分配到合适的位置。
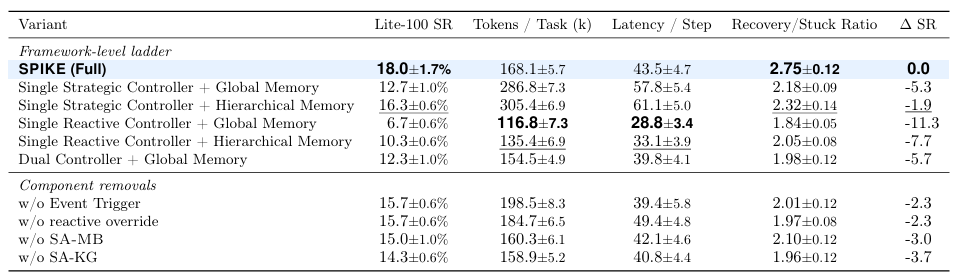
图 6 | SPIKE 消融实验。Event Trigger、Reactive Override、SA-MB 和 SA-KG 分别贡献了触发时机、局部纠错、动作复用和结构化规划证据。
3.定性案例:从卡住到恢复
在定性案例中,ReAct-like 控制器容易持续输出低成本但无效的动作,因为它缺少足够强的机制来判断“当前计划已经失效”。
Always-strategic 控制器能够重新理解场景并恢复,但它会在恢复之后仍然不断调用昂贵推理,导致成本过高。 SPIKE 的行为更接近一种“快慢结合”的执行模式:当计划稳定时,它让 Reactive Controller 执行低成本动作;当画面变化或进度停滞时,它通过 Event Trigger 重新调用 Strategic Controller;当恢复完成后,再回到低成本局部执行。
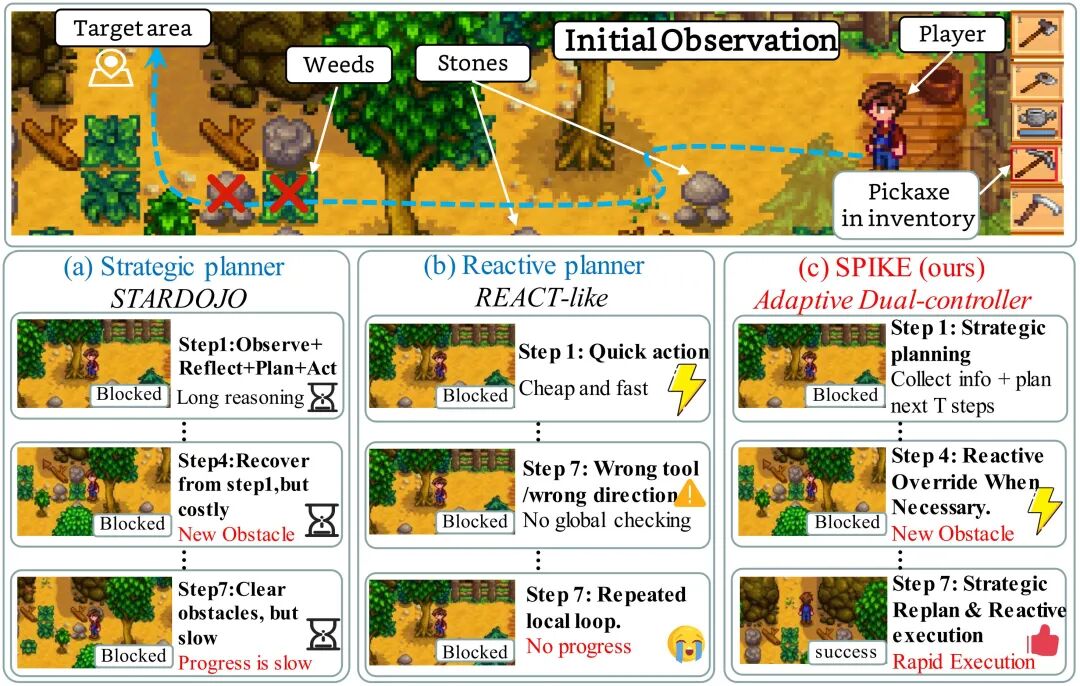
图 7 | 定性对比。SPIKE 在关键失败点触发重新规划,并在计划稳定后回到低成本局部执行。
展望
SPIKE 展示了长程游戏智能体中的一个重要方向:智能体不应该只追求更强的单步推理,而应该学会分配推理预算。
当前 SPIKE 仍然有局限。Lite-100 的绝对成功率仍然不高,说明开放世界长程控制依然困难;Event Trigger 的阈值也需要根据不同游戏环境的视觉动态、动作节奏和反馈密度进行校准;在 combat 和 social 等复杂任务中,智能体仍然容易受到移动目标、长距离路线和多阶段交互的影响。
未来,更灵活的事件检测、更强的局部控制器、更可靠的跨任务记忆结构,可能进一步提升长程智能体在开放世界中的稳定性和泛化能力。
一句话总结:SPIKE 让长程游戏智能体学会“该行动时行动,该思考时思考”。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢