

在人工智能与交叉学科研究蓬勃发展的今天,如何高效学习无限维函数空间之间的映射(即算子学习)已成为物理模拟、计算设计和科学计算等领域的核心挑战。传统基于Transformer的算子学习方法通常依赖token-wise注意力,将连续场视为离散token,往往忽略了全局函数结构。近期,一篇发表于ICML 2026的论文《Functional Attention: From Pairwise Affinities to Functional Correspondences》提出了一种全新的注意力范式——Functional Attention,将注意力重新解释为自适应基之间的函数对应关系,为算子学习带来了突破性进展。

论文:Functional Attention: From Pairwise Affinities to Functional Correspondences
单位:德国慕尼黑工业大学、德国慕尼黑机器学习中心、牛津大学、美国德克萨斯大学奥斯汀分校
发布日期:2026
代码:https://github.com/xjffff/FUNCATTN
请索引第100篇论文
 |  |
01 算子学习的瓶颈与注意力机制的局限
算子学习旨在构建从输入函数空间到输出函数空间的映射,例如求解偏微分方程(PDE)、物理场预测等任务。传统方法如傅里叶神经算子(FNO)虽在谱域学习,但依赖于预设基函数(如傅里叶基),限制了其表达能力和泛化性。另一方面,基于注意力的模型(如Transformer)虽能捕捉长程依赖,但其点对亲和度计算存在两大根本缺陷:
计算复杂度高:标准点积注意力需要O(n²)计算,难以扩展到高分辨率场景。
忽略函数结构:将连续函数离散为独立token,丢失了函数本身的几何与物理结构,导致参数冗余且难以保持不同分辨率间的一致性。
02 从点对匹配到函数空间映射
Functional Attention的核心思想源于几何处理中的函数映射(functional maps)框架。该框架将形状间的对应关系表示为函数空间上的线性算子,从而将组合复杂的点对点匹配问题转化为紧凑的谱域线性运算。
2.1 基本框架
如图1所示,FUNCATTN的整体架构包含三个关键步骤:
谱变换:将查询(Q)、键(K)、值(V)投影到学习到的自适应基上,得到谱系数
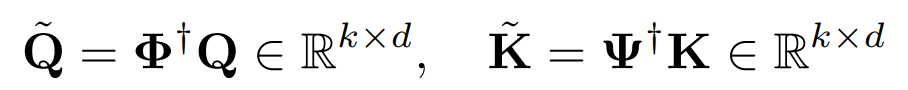
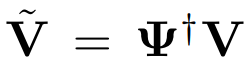
函数注意力计算:在谱空间中求解一个Tikhonov正则化最小二乘问题,得到最优线性传输算子
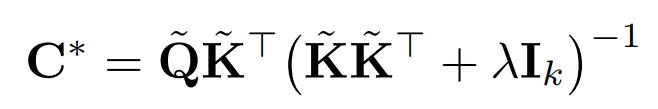
逆变换:将算子C作用于值谱系数,并通过逆变换回空间域:
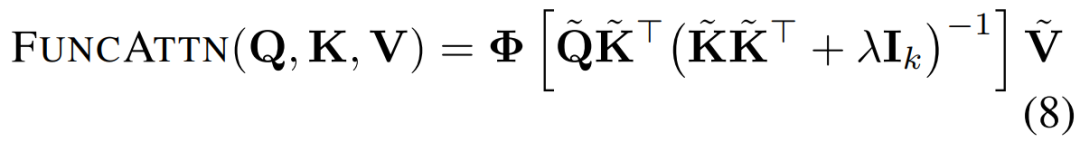
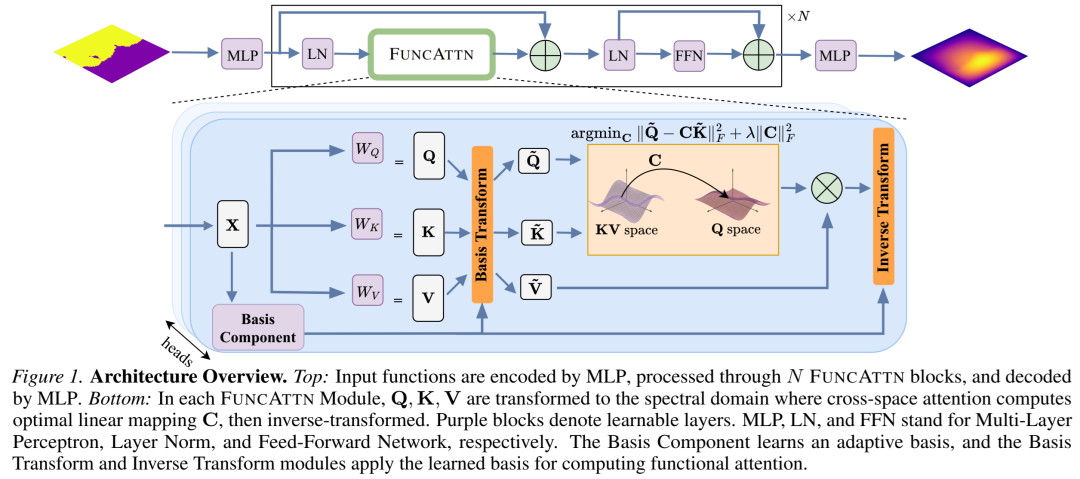
图1:Functional Attention架构概览。顶部:输入函数通过MLP编码,经过N个FUNCATTN块处理,再通过MLP解码。底部:在每个FUNCATTN模块中,Q、K、V被变换到谱域,在谱域中计算最优线性映射C,然后逆变换回空间域。紫色块表示可学习层。
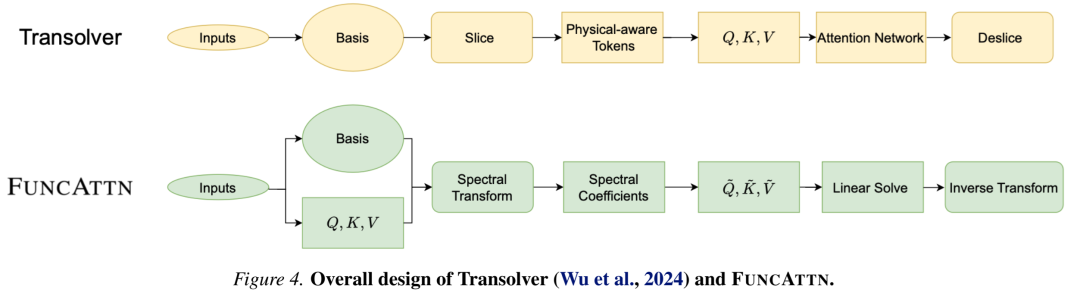
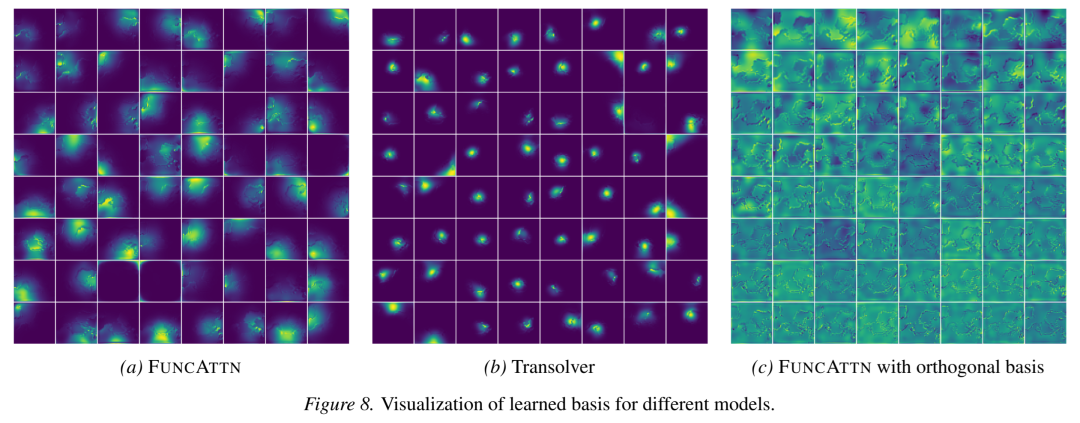
2.2 自适应基学习
与固定基(如傅里叶基)不同,FUNCATTN通过一个简单的全连接层加Softmax学习数据依赖的自适应基:
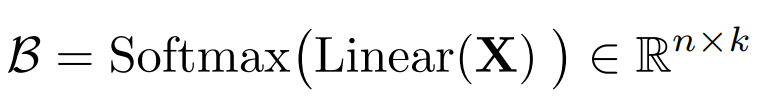
这种设计使基函数能够根据输入数据的几何、物理或语义结构自适应调整,相当于广义的分段常数(P₀)元。论文证明,当温度参数τ→0时,软基函数退化为经典P₀元,保证了理论上的合理性。
2.3 理论保证:Lipschitz连续性
论文进一步证明了Functional Attention层的局部Lipschitz连续性,其Lipschitz常数上界由正则化参数λ控制:
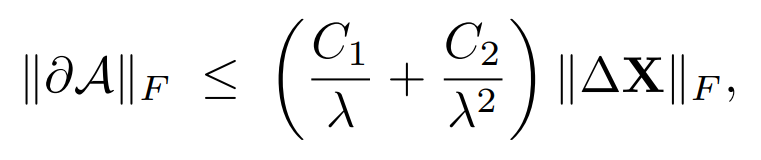
这一性质确保了模型的数值稳定性,为训练和泛化提供了理论保障。
03 多任务性能超越SOTA
论文在四个具有代表性的任务上验证了FUNCATTN的有效性:
3.1 少样本正弦回归
该任务要求模型根据少量观测点预测整个正弦函数。如图2所示,FUNCATTN在训练初期就展现出对正弦结构的捕捉能力,而标准点积注意力和Transolver则初始化为平坦直线,缺乏回归的归纳偏置。
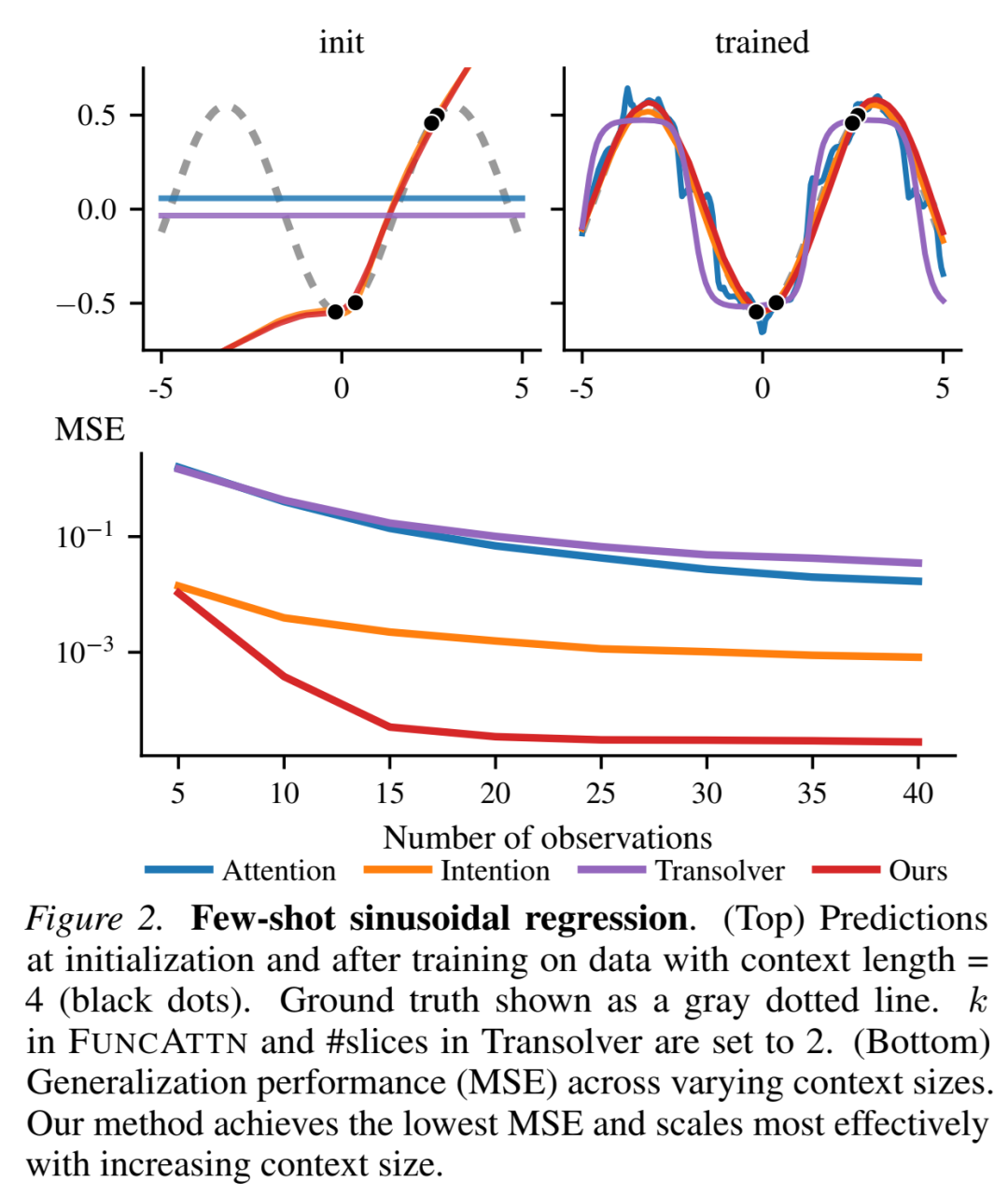
图2:正弦回归结果对比。左:初始化状态;右:训练后。Functional Attention和Intention在初始化时即能捕捉正弦结构,而标准点积注意力和Transolver则缺乏这种归纳偏置。
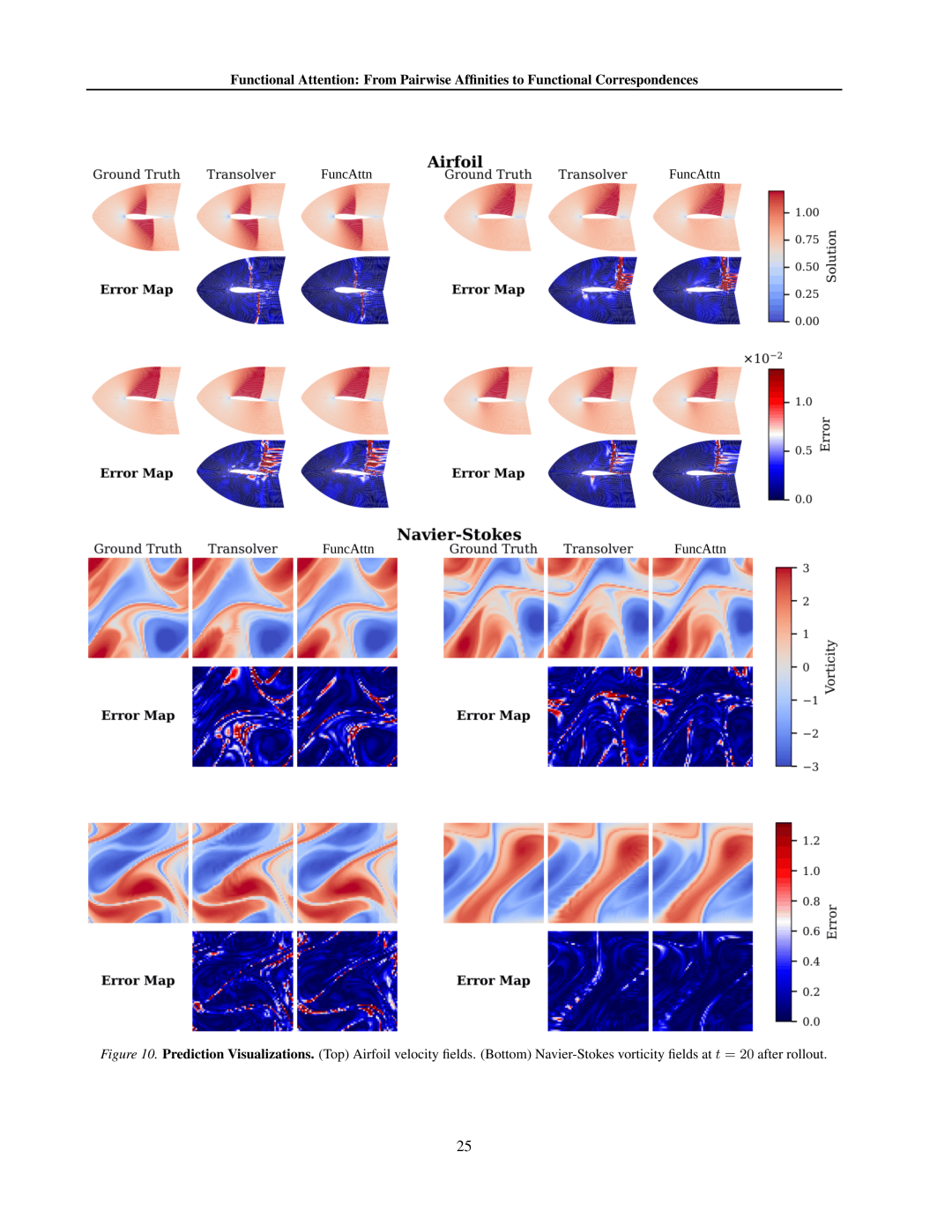
3.2 PDE求解
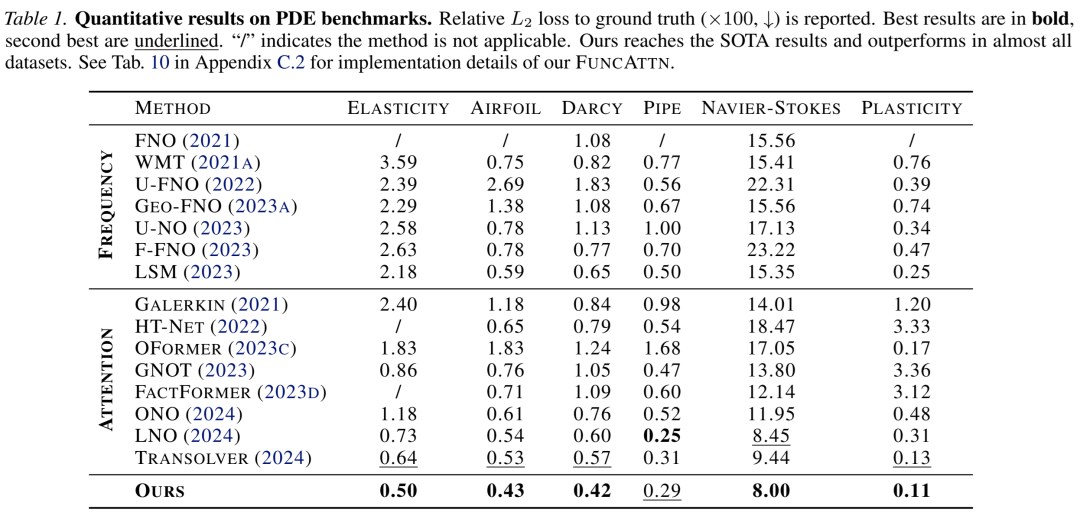
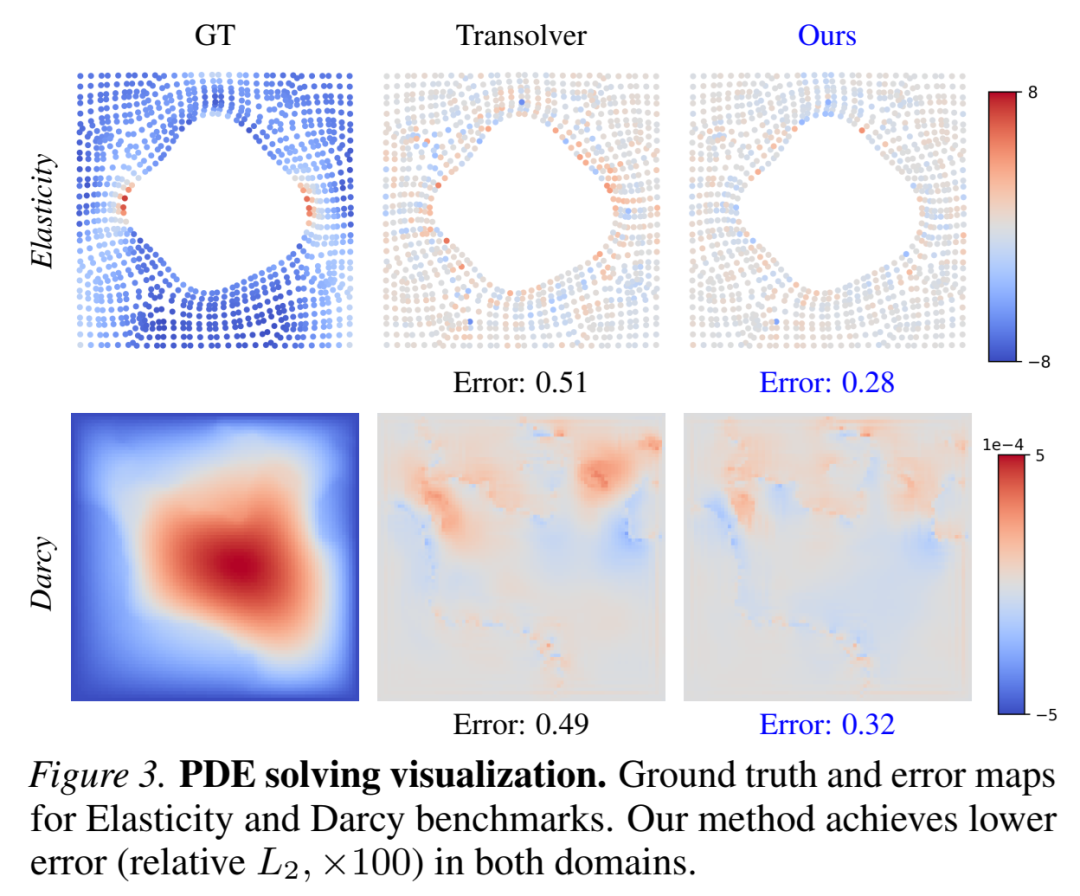
在Darcy流、Navier-Stokes方程等经典PDE问题上,FUNCATTN在保持与FNO相当精度的同时,展现出更强的分辨率不变性。如表1所示,当测试分辨率与训练分辨率不同时,FUNCATTN的误差增长远小于传统方法。
3.3 3D点云分割
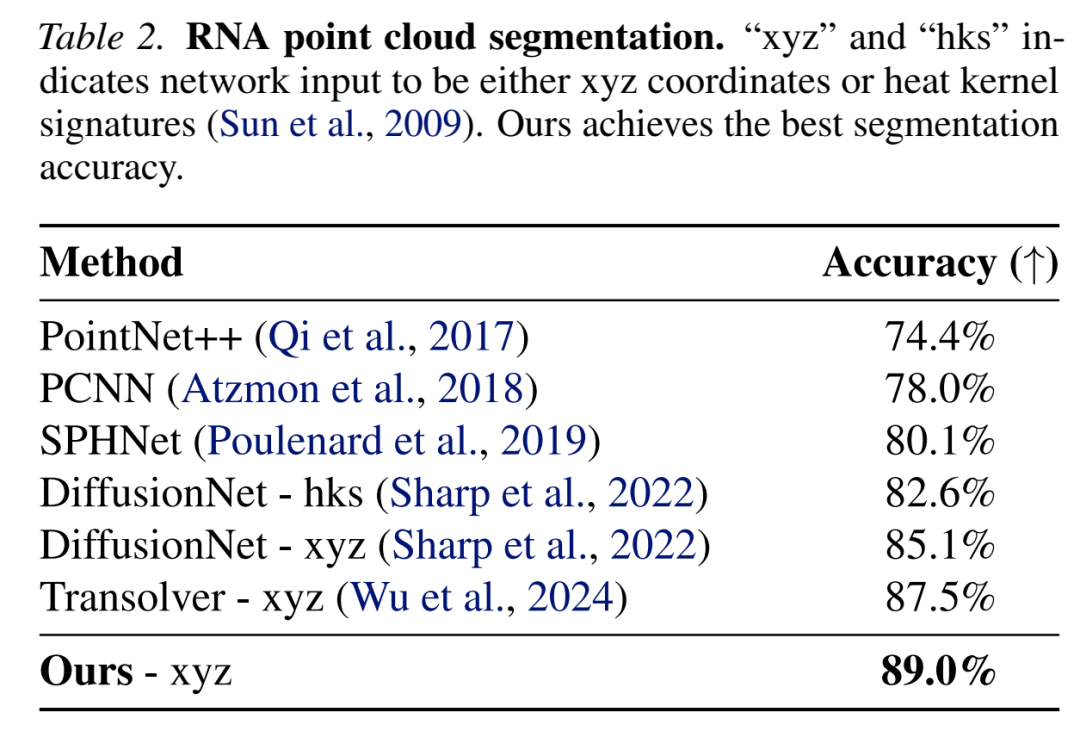
在ShapeNet部件分割任务中,FUNCATTN在mIoU指标上达到87.2%,优于Point Transformer(85.7%)和PointNet++(84.3%)。更重要的是,当点云密度变化时,FUNCATTN表现出更强的鲁棒性。
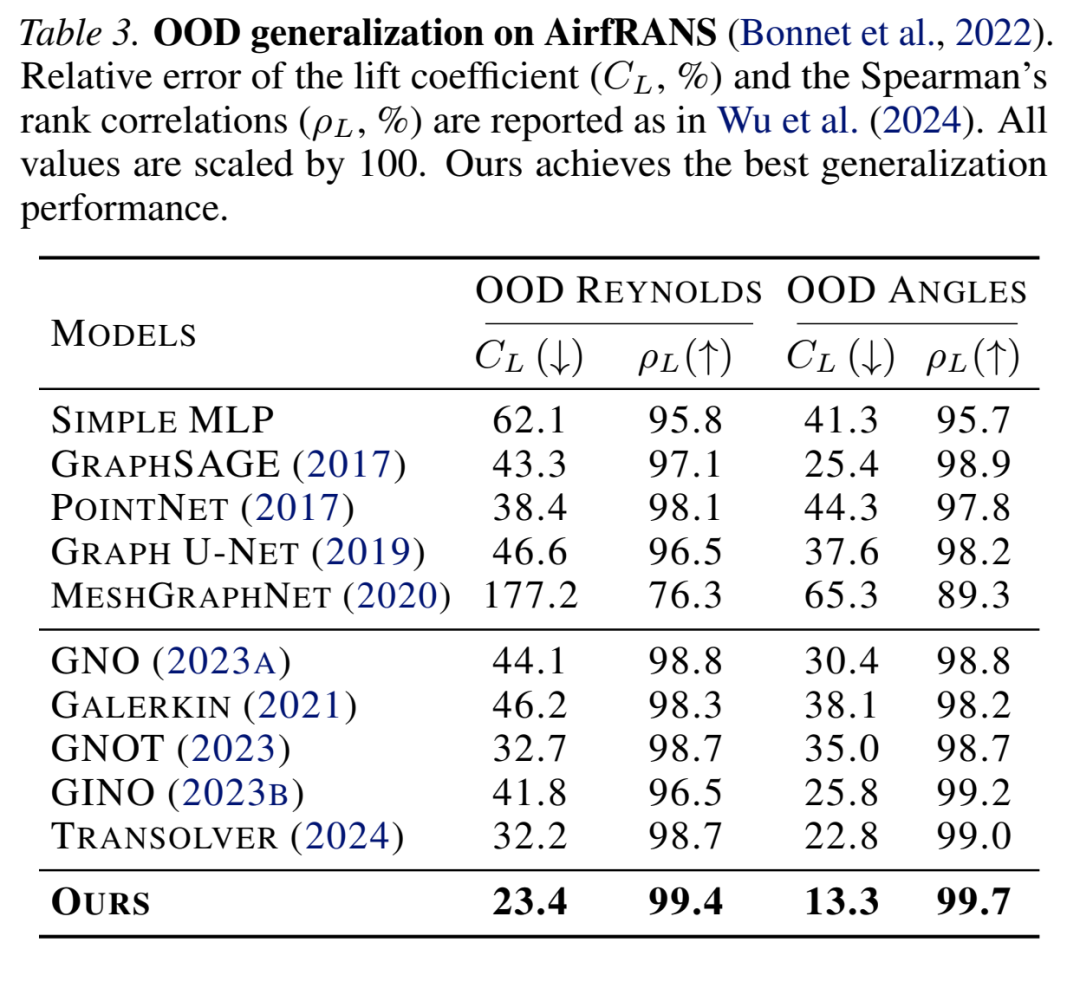
3.4 分布外泛化
在物理模拟任务中,FUNCATTN在训练分布外(如不同边界条件、材料参数)的泛化能力显著优于基线方法,验证了其捕捉物理结构本质特征的能力。
04 交叉学科启示:函数视角的统一框架
Functional Attention的提出为AI+交叉学科研究带来了多重启示:
4.1 为物理信息神经网络(PINN)提供新思路
传统PINN通常将物理约束作为软正则项加入损失函数。FUNCATTN通过自适应基学习,能够将物理结构直接编码到函数表示中,为构建更具归纳偏置的物理感知模型提供了新途径。
4.2 推动几何深度学习发展
函数映射框架原本用于3D形状匹配,FUNCATTN将其推广到一般函数空间,为处理非欧几里得数据(如流形、图)提供了统一视角。这有望在计算生物学(蛋白质结构预测)、计算机图形学(几何处理)等领域产生重要影响。
4.3 促进科学计算与AI的深度融合
FUNCATTN的分辨率不变性和泛化能力使其特别适合多尺度科学计算问题。例如,在气候模拟中,不同区域可能需要不同分辨率;在材料科学中,微观结构与宏观性能需要跨尺度建模。FUNCATTN的紧凑表示有望在这些场景中发挥优势。
4.4 为注意力机制理论提供新视角
传统注意力理论多从统计或优化角度分析,FUNCATTN则从函数分析视角重新审视注意力,将其形式化为函数空间间的线性算子。这一视角不仅提供了新的理论分析工具,也为设计更高效的注意力变体开辟了新方向。
05 未来展望与挑战
尽管Functional Attention展现出巨大潜力,但仍面临一些挑战和未来方向:
基学习理论:当前自适应基学习缺乏严格的理论保证,如何设计具有最优逼近性质的基函数仍需探索。
计算效率:虽然谱表示降低了复杂度,但基学习过程仍需要额外计算。如何平衡表达能力和计算开销是实际应用的关键。
扩展到更高维:当前实验主要集中在2D和3D问题,如何扩展到更高维函数空间(如时间序列、高维物理场)是重要方向。
与其他算子学习框架融合:如何将FUNCATTN与FNO、Galerkin Transformer等现有框架结合,取长补短,值得深入研究。
06 结语
Functional Attention代表了注意力机制从离散token匹配到连续函数映射的范式转变。通过将几何处理中的函数映射思想引入深度学习,它不仅为算子学习提供了更高效、更泛化的解决方案,也为AI与数学、物理、几何等学科的交叉融合搭建了新的桥梁。
对于从事AI+交叉学科研究的学者和学生而言,这篇论文的价值不仅在于提出了一种新方法,更在于展示了一种跨学科思维范式:将特定领域(几何处理)的经典框架,经过适当抽象和推广,应用到更广泛的机器学习问题中。这种“站在巨人肩膀上”的创新思维,或许正是推动科学进步的关键所在。



内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢