
大语言模型在 False Belief 测试题上刷出高分的同时,Ullman 等人做了一个简单到令人尴尬的实验——只要对经典 ToM 任务做微不足道的改写,所有大模型立刻崩盘。Strachan et al. 在 Nature Human Behaviour上的系统性电池测试也得出类似的怀疑论结论。
这引出一个更深层的问题:过去十几年里,大家造了一堆可以"过 ToM 测试"的系统,却从未严格定义过"机器心智理论(Machine Theory of Mind, MToM)"到底是什么。
本文的核心价值就在于此:它是世界上第一篇对 MToM 给出严格形式化定义、提炼证据支持的 Principles、并用一个 holistic meta-model 把整个领域"拔高一层"的工作。
对于做 AI+认知科学交叉、图神经网络、不确定性量化、多智能体 RL 的读者来说,这篇文章提供的不是某个新模块,而是一张概念坐标系——让你看清自己那块拼图在整个版图上的位置。

论文:A formal definition and meta-model for a machine theory of mind
单位:牛津
发布日期:2026
请索引第101篇论文
 |  |
为什么「机器心智理论」至今没有正式定义?牛津这篇工作首次把它写成了数学,并提出了一个统领性元模型
01 心智理论的三个经典流派(及为什么机器版不能只挑一边站)
1.1 认知心理学给我们的三条线索
流派 | 核心主张 | 对 MToM 的启示 |
|---|---|---|
Theory-Theory (TT) | 人对他人的理解靠的是一套"理论"(命题式知识结构),儿童像小科学家一样提假设、验证据 | 机器需要知识库 + 假设生成/检验 + 符号/神经符号推理;但存储无穷多理论认知代价爆炸 |
Simulation-Theory (ST) | 人通过把自己的推理系统"代入"他人来推其心理状态("我要是他,会怎样想?") | 机器可用自身决策/规划引擎模拟他人;依赖"他人与我足够相似"的先验 |
Modular Theories | ToM 由脑中专门模块负责(进化产物),mPFC / TPJ / STS 等构成功能网络 | 暗示 MToM 架构应是有功能子模块组装而非单一端到端黑箱 |
作者给出的立场非常明确:你需要一个 hybrid,两者缺一不可(Principle 4)。纯 ST 在没有足够锚定信息时不知道该"设成谁";纯 TT 在没有交互证据时理论空间爆炸。人类自己就是又模拟又建理论的。
1.2 神经科学的现状:有用,但尚未 ready-to-implement
论文坦率指出:神经科学目前还不足以直接指导 MToM 架构设计(mirror neuron 假说热度退潮后,现在更多认为是 mPFC+TPJ+STS 等组成的分布式网络)。但它提供的两点非常关键:
组装式(assemblage)证据:人脑似乎不是用一个"ToM模块"硬开关,而是用基础构建块动态组装来处理不同社会情境——这对我们设计可重组的仿真架构(Neural Module Search 思路)是直接启发。
自我模拟是起点:mPFC 活动在 self vs. other 区分中扮演关键角色——形式上意味着你的先验可以用 sim(self) 做初始化。
02 八大 Principles:从证据到约束条件
这是全文最"值钱"的部分——作者从认知心理+神经科学+AI 三条线索,推导出 MToM 必须满足的 8 条原则(不是拍脑袋 axioms,而是 literature-backed):
Principle | 认知/实证来源 | 对 AI 模型的打击点 | |
|---|---|---|---|
P1 | ToM 是终身持续学习过程,随经验迭代更新 | 儿童 ToM 3–4 岁才出现,需多年多情境交互 | 一次性训练/静态 benchmark 是根本性错配 |
P2 | 无证据时,用自身思维过程模拟他人(自我模拟 kick-start) | "child applies their own reasoning to others";COMMON-TOM 基准也围绕 common ground | 纯从零数据学他人 ≠ 人类的 bootstrap 机制 |
P3 | 应从观察 + 交互两条通道学习(非仅其一) | 人看电影/读故事也能学;RL 反馈循环也能学 | 把 MToM 缩减成纯 SL 或纯 RL 都是削足适履 |
P4 | Hybrid:ST(模拟)+ TT(假设生成/检验)共存 | 模糊情境下人既代入又提问验证 | 纯端到端黑箱或纯符号都偏科 |
P5 | 须含主动学习:为消解歧义去获取新证据 | 你会问朋友"你是不是烦了?"来验假设 | 当前所有静态 ToM benchmark 完全忽略这条 |
P6 | 须处理高阶递归 ToM("我认为你认为我认为…") | 谈判/博弈/有限信息竞价中高阶 ToM 有可测优势 | 大多数方法止步一阶 belief tracking |
P7 | ToM 是多任务:意图、信念、情绪、解释、预测……输出是 manifold insights,非单一 label | 同一场景不同目标要不同输出 | 把 ToM 降维成"猜下一个动作"丢掉了半壁江山 |
P8 | 过程是本质不确定的——他人心智不可直接观测,不确定性是 epistemic 型的 | 行为→心智是 ill-posed inverse problem | 点预测不够;需要 credal sets / random sets / second-order uncertainty |
交叉学科读者的一个关键takeaway:P1+P8 合在一起告诉你——MToM 的本质不是一个分类器或一个 predictor,而是一个在持续演化、永远 under-determined 的推理过程。这意味着它的数学形态更像 online Bayesian updating / conformal prediction / credal-set reasoning 而非 standard supervised learning。
03 把"理解他人心智"写成映射
这是本文最硬核的贡献。作者定义了:
Definition 1(MToM 核心映射):一个 Observer ω 观察 agent a 处于环境 e 中。
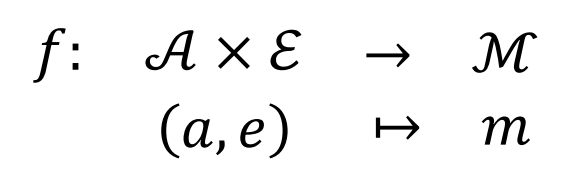
其中每个 model本身又是一个映射:
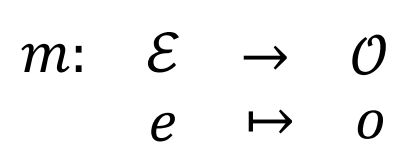
即:环境描述 → 关于 agent a 的一组 insights (意图、最可能决策、情绪状态、信念……)。
加上时间维度(P1 持续更新)
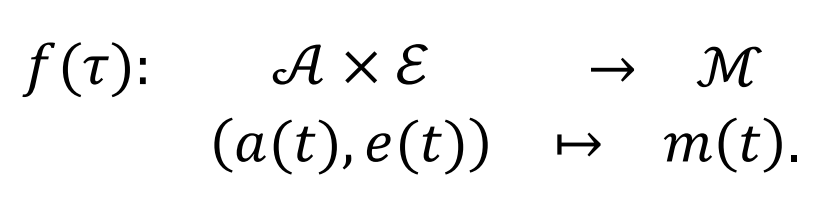
更新发生在离散时刻 (异步),被观测序列 和交互奖励驱动。
Definition 2(更优雅的分离写法)把"agent 类"和"环境"解耦:
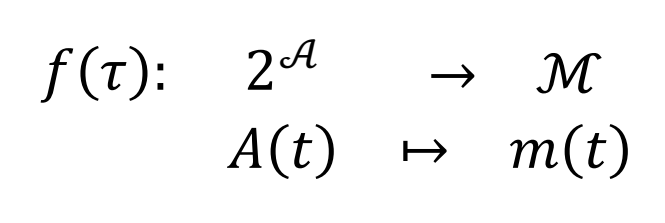
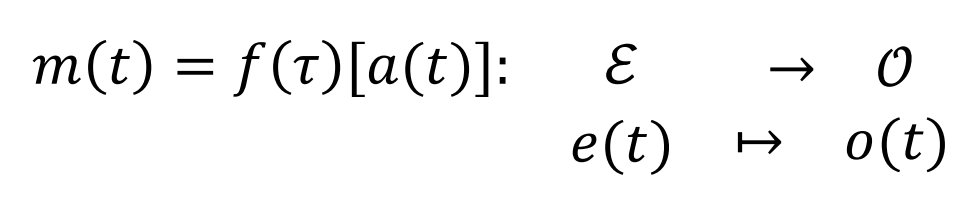
你可以把 理解为 Observer 脑子里的 "心智模型构建器",输入看到的人(类)和情境流,输出一个 针对该 agent/agent-class 的 executable model,这个 model 吃进当前场景 ,吐出你想要的任意 insight(belief / intention / emotion / explanation / next action distribution …)。
这个形式的美妙之处在于它的包容性——IRL 框架、Bayesian ToM、BDI 逻辑模型、GNN 消息传递图、甚至(scaffolded)LLM agent 都可以被视作这个 的特例实现。它提供的是接口层定义,不是某个具体算法。
04 Holistic Meta-Model
4.1 整体架构(核心图)
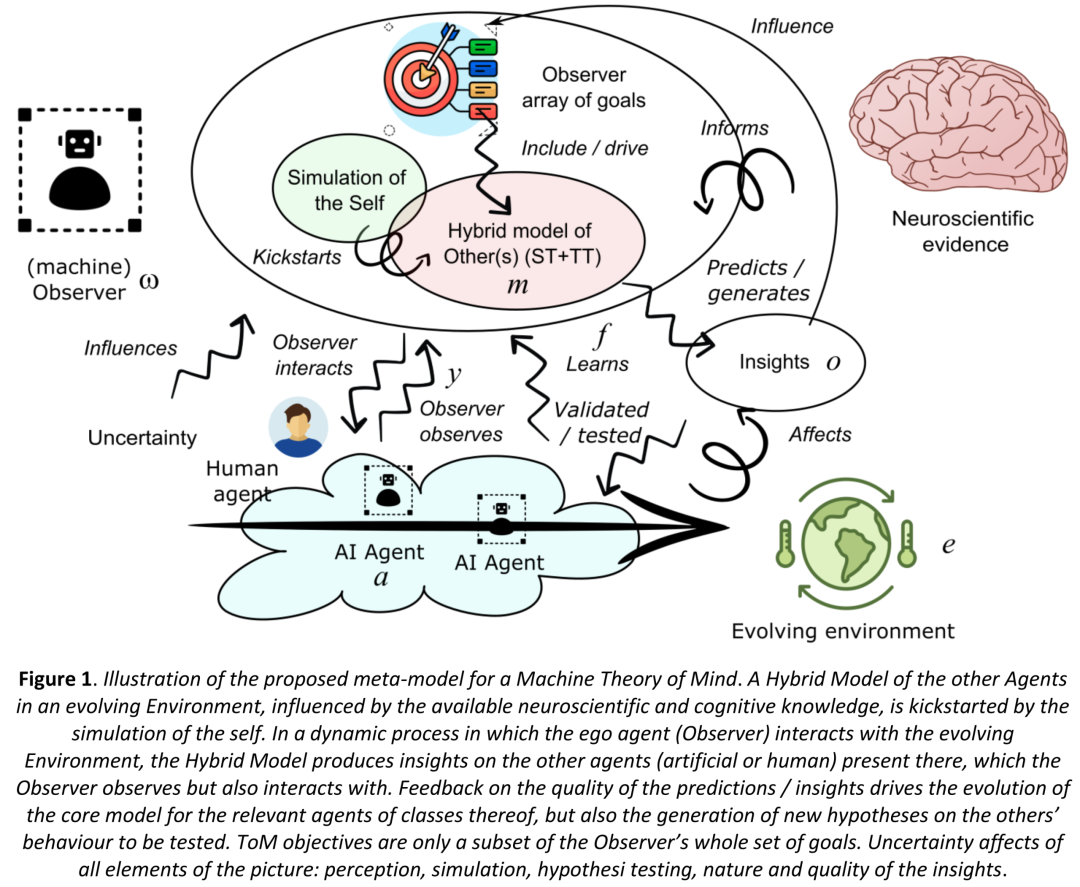
Figure 1:MToM 元模型全图。Observer(≠纯 ToM模块)在动态环境中同时观察+行动,Hybrid Model 产出对他人的 insights,不确定性贯穿感知→模拟→假设检验→insight 每一环,预测质量反馈驱动模型演化。
ToM 不是独立子系统,而是 Observer agent 整体目标集合的一部分。Observer 有自己的 goals(大多 ToM-irrelevant),其中一部分是 ToM-related goals——这两者共同决定交互行为,而交互产生的数据反过来更新你的 ToM 模型。
4.2 四大组件拆解
① 仿真侧(Simulation / ST 侧)
用 self-simulation 初始化(P2):你对陌生 agent 的第一近似 = "若我是他…"
随证据积累,从 agent class-level(刻板印象/原型 sim)细化到 individual-level
仿真架构本身不是给定死的,而是通过 Continual NAS / Neural Module Search 让结构随任务演化
作者的推荐非常具体:
Continual Neural Architecture Search — made cheaper by module-based constraints (NMS: freeze base modules, re-wire) — is the best-suited mechanism.
这对 图科学/图学习 读者是个暗线提示:如果把 mental state 建模成 graph of states(),那么"模块重组"天然对应 子图提取 + message passing 结构调整,就是一个 dynamic graph NN 的架构搜索问题。
② 理论侧(Theory / TT 侧):假设生成 + 主动探询
TT 在这里不做拟人玄学,而是工程化为两种等价形态:
假设检验型:formulate hypotheses → design action to disambiguate → update(经典 active learning loop)
目标函数型:把"减少 insight 的不确定性"或"提升 sim 保真度"写成 reward/objective,塞进 Observer 的多目标优化里
论文还抛出一个非常前沿的方向:用 epistemic generative models(epistemic GAN / VAE / diffusion)来生成消解歧义所需的 counterfactual 观测——这在当前的 MToM 文献里几乎没人碰。
③ 多目标 Agent Goal Optimisation 学习框架
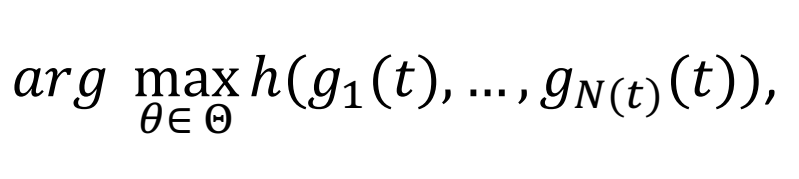
其中 ToM-related objectives 至少可分四类:
Objective | 形式 | 作用 |
|---|---|---|
ToM-SL | — 预测误差 | 用可观测行为监督 insight 质量 |
ToM-RL | — 累积奖励 | 通过与 agent 交互的效果反推心智模型好不好 |
ToM-TT | 假设真伪统计检验置信度 | 驱动 TT 侧的假设筛选 |
ToM-U | — uncertainty reduction | 主动压低 epistemic uncertainty |
而且 goal set 本身随时间演化(Figure 2 的 Evolving AI 理念)——你意识到需要搞清某个 agent 的某个维度,本质上就是新 goal 的涌现。
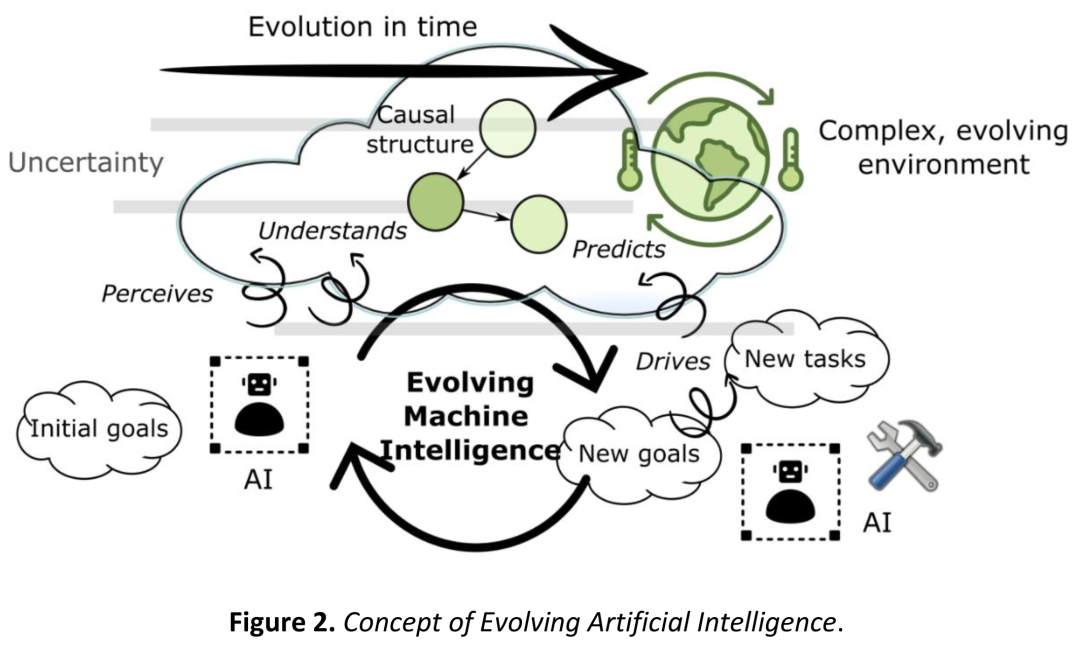
Figure 2:Observer goals 的动态演化——新目标可以从探索目标空间的过程中涌现,而不仅是手写的。
④ 不确定性建模(贯穿所有组件)
这是论文花最大篇幅强调的"欠账":
观测噪声(视觉检测失败、语言歧义)
环境非平稳(场景动态本身不确定)
人类行为的内在丰富性(同一 mental state → 多种 exteriorization)
simulation 内部结构的不确定(图结构的边权、节点含义、层级关系)
insight 自身附 uncertainty(你输出的"他认为…"应带置信/第二阶不确定)
作者特别点名 credal sets / random-set representations 作为比普通 Bayesian / ensemble 更有前途的路线(更紧的泛化界、更好的 OOD detection、天然二阶 epistemic 表达),并指出它们在 ToM 中尚未被用过——这是一个 open gold mine。
05 现有方向差在哪?
5.1 逐条审判
Principle | IRL / MARL 系 | Bayesian ToM | BDI / 认知架构 | LLM (scaffolded) | 生物启发 |
|---|---|---|---|---|---|
P1 持续 | ✅ 天然时序 | ⚠️ 多数静态 | ⚠️ 学习≠持续 | ⚠️ 上下文窗口≠终身 | ⚠️ 有learn但未连续 |
P2 自我模拟 | ❌ 纯外部 | ⚠️ 潜力在但未见paper | ✅ self-model → other | ⚠️ self-cognition刚起步 | ✅ STS等通路 |
P3 观察交互 | ✅ RL交互侧强,观察偏弱 | ✅ obs更新,action缺 | ❌ 不关心env交互 | ⚠️ agentic时有交互 | ❌ 只管仿脑不管交互 |
P4 ST+TT | ❌ 纯TT味 | ❌ 纯probabilistic TT | 部分 BDI+规则 | ❌ 纯隐式 | 提法有但很少真融合 |
P5 主动学习 | ⚠️ 有IRL但不成体系 | ⚠️ 信息增益未主流 | ❌ | ❌ | ❌ |
P6 高阶 | ⚠️ IPOMDP可扩但贵 | ⚠️ 可嵌套但脆 | ❌ | ⚠️ prompt递归但黑箱 | ❌ |
P7 多任务 | 常限reward inference | belief/desire可扩 | ✅ 多attitude | ✅ 表面多task | 单视角 |
P8 不确定 | ⚠️ 部分 | ✅ 核心优势 | ⚠️ 逻辑≠uncertainty calib. | ❌ 点估计为主 | ⚠️ |
一句话总结:没有任何现有 strand 全满足;最接近的是 Bayesian ToM × continual RL,但它在 P2(自我模拟初始化)和 P5(结构化主动探询)上是明显短板。
5.2 Benchmark 生态的系统性缺陷
论文对现有 benchmark 做了大规模普查(Table 1 汇总了 30+ 数据集/框架),然后掷出一个尖锐判断:
"Overall, as all of these are static benchmarks, none satisfies Principle 5 (active learning), nor Principle 1 (continual update). Uncertainty quantification (P8) is widely ignored. Higher-order (P6) only in Hi-ToM. P2 and P4 are invisible to data format."
下面把论文的 Table 1 整理成更易读的版本供参考:
Benchmark / Dataset | 模态 | 数据形态 | 核心任务 | 年份 |
|---|---|---|---|---|
FANToM | 文本 | 10K queries / 256对话 | 6类交互ToM压力测试 | '23 |
OpenToM | 文本 | 696叙事 (GPT生成) | location/attitude/belief 多跳 | '24 |
ToMBench | 文本 | 2,860样本 / 双语 | 8task×31ability | '24 |
Hi-ToM | 文本 | – | 高阶递归ToM (deception) | '23 |
MMToM-QA | 视频+文 | 134视频/600query | true/false belief, belief tracking, goal inference | '24 |
EgoToM | 视频 | 7k 5-min clips (Ego4D派生) | 第一人称ToM QA | '25 |
MovieGraph-ToM | 视频+文 | 30电影/65.6k query | 长程社会因果图推理 | '26 |
MOMENTS | 视频 | 2.3k MCQ (SF20K) | 7类ToM类别 | '25 |
SoMiToM | 视频+文 | 35第三视角视频+363第一视角图 | 具身社交多视角 | '25 |
MuMa-ToM | 视频+文 | 18参与者/90问 | 多智能体具身mental reasoning | '25 |
MindCraft | 虚拟世界+文 | 100局Minecraft协作 | 共建任务/互belief追踪 | '21 |
ToM-SSI | 网格世界 | 6,000问/5task | 群体交互/空间+社交 | '25 |
COKE | KG | 45k+认知链 | situation→thought→action→emotion | '24 |
DynToM | 文本 | 1,100context/78.1k问 | 时态演化的心智状态追踪 | '25 |
CogToM | 文本(双语) | 8,000实例/46范式 | 36tasks跨7心智范畴 | '26 |
如果你在做视觉/具身方向,看 MuMa-ToM / EgoToM / ToM-SSI;如果你在做时态动态,DynToM 是目前唯一认真建模 mental state 时间演化的;如果你在做语言agent,FANToM 和 ToMBench 的覆盖面更严。但请记住:没有一个现有benchmark测P1(持续学)和P5(主动交互探询)——这两个维度只能自己设计闭环环境(PsychSim / Mujoco social / 自定义grid world)。
06 给你的研究启示
作者对未来的推演翻译成更"可执行"的研究建议,按受众分组:
如果你做图学习 / 网络科学 + AI
把 mental state 表示成 dynamic heterogeneous graph(entity states → nodes;causal/temporal/belief edges → edge types),用 GNN message passing 做 belief propagation,但关键是把 graph topology本身做成 learnable(architecture search over graph structures)
考虑 credal-set / random-set 版本的 GNN(论文 references: Tolloso & Bacciu "Credal GNN", Woodley et al. "Random-Set GNN")——把 epistemic uncertainty 织入消息传递而非事后calibration
如果你做多智能体 / MARL
把 opponent modeling 从 "learn a policy net" 升级为 P1+P3+P5 框架:你的 opponent model 要持续更新(continual),且要主动设计交互动作来降低对其 intent 的 entropy
高阶 ToM(P6)别只当game-theory练习题——IPOMDP框架 + 可扩展近似推断(particle filters / amortized inference)是现实路径
如果你做 LLM + ToM
承认一个残酷事实:论文的结论是LLM的ToM能力skeptically viewed——LLM在ToM任务上的高分很多是 pattern matching over textual schema, not genuine simulation of minds
最有价值的LLM×ToM路线不是"刷榜",而是 scaffold LLM 为 hybrid meta-model 的组件:用LLM做 natural language ↔ structured belief 的接口层(LaBToM方向),但把核心 belief update / uncertainty 交给符号+概率引擎
自我认知(self-cognition)→ 自我模拟(P2)这条路值得认真做,而不是只加prompt
如果你做不确定性/可信AI
MToM 是 epistemic uncertainty 的天然高强度试验场(因为 ground truth mental state 原则上不可直接观测)
把 conformal prediction / credal sets / second-order uncertainty 引入 belief tracking,把它做成 certifiable 的输出(不只是"他要去左边",而是"我对这个判断的 epistemic confidence = X,需要再探询吗?")——这直接连到 safety-critical 应用(自动驾驶预测行人意图、人机协作信任校准)
07 结语
有人可能会说:"不就是写了个映射 吗?" 但这个看似简单的动作解决的是领域内真正的结构性缺失。
没有形式化定义 → 没有共识度量 → 每个方法选自己的tech然后宣称做ToM → 领域碎片化 → 无法累积进步
Cuzzolin 做的事相当于给一个长期靠直觉推进的交叉领域立了地基:八大原则是从三条学科的实证文献里归纳出来的(不是a priori哲学偏好),形式化定义给出了接口,元模型给出了装配蓝图,benchmark census 标出了荒地。
对读者而言,最有嚼头的部分在于:ToM 的 search space 天然是结构性的(层级 mental-state DAG / factor graph / causal graph / BDI 逻辑图),这意味着图神经网络、结构学习、神经符号图推理不仅"能用",而是在MToM的形式定义中就站在舞台中央。



内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢