在5月28日开幕的2026世界智能产业博览会上,北京智源人工智能研究院发布了 “众智FlagOS·科学智能基座”, 基于FlagOS统一软件栈跨芯能力的智能科学计算基座,正式将FlagOS的多芯能力从大模型拓展到科学计算、量子计算等关键领域。过去三年,FlagOS的技术栈围绕大模型训练和推理构建,跨芯片适配已能做到Day0,新模型发布后即刻在多款芯片上跑起来。这依托于FlagOS面向多种AI芯片的统一、开源系统软件栈。
众智FlagOS全景架构:从芯片适配到模型生态统一开源软件栈
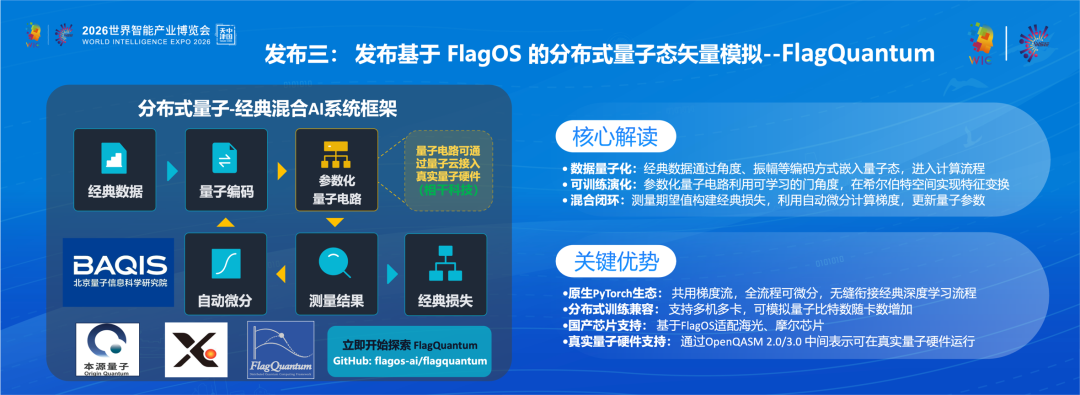
但计算基础设施的演化远未停止:从追求单芯片算力峰值,到解决超节点互联效率,再到通过3D堆叠、HBM变体和存内计算突破数据访问瓶颈。新的负载形态也在出现,Prefill与Decode分离、具身智能的云边协同、量子计算与AI的融合,这些都可以概括为三重多元,即“芯片的多元、框架的多元、计算范式的多元”。前两种,FlagOS已有解法,即“一次开发,多芯运行”—以Triton-TLE统一编程语言编写算子,由FlagTree编译器翻译为各芯片代码,性能中位数达到厂商原生库的83%以上,KernelGen 2.0进一步将算子开发从手工变为AI自动生成,在5款国产芯片上成功率超过95%。这使得FlagOS成为全球支持芯片种类最多的开源AI软件栈,支持了18家厂商的32款AI芯片。计算范式本身也在走向多元—科学计算、量子-经典融合正在成为AI的新战场。多元本身不是问题,它是一种不断的演进,关键在于多元之上有没有统一的软件栈来兜底。这正是FlagOS下一步要做的事:不局限在今天的AI智算,也要为量子计算+AI打好基础。量子计算与AI的融合是FlagOS要面对的新范式。这个判断基于一个事实:量子硬件仍然稀缺,只能依赖于现有的AI加速卡来模拟量子计算,这也是为什么英伟达重度投入量子计算的原因,也是国产卡的机会所在。而当量子计算机真正就绪时,同一套技术栈应让开发者在经典算力和量子算力之间无感切换。为此,我们发布了基于FlagOS的分布式量子态矢量模拟—FlagQuantum。FlagQuantum是一个量子—经典混合AI框架,定位不是万能替代者,而是超级协处理器—经典AI芯片负责大规模并行计算,量子处理单元负责特定子任务的指数级加速,两者在同一个环境下协作。FlagQuantum 分布式量子-经典混合 AI 系统框架
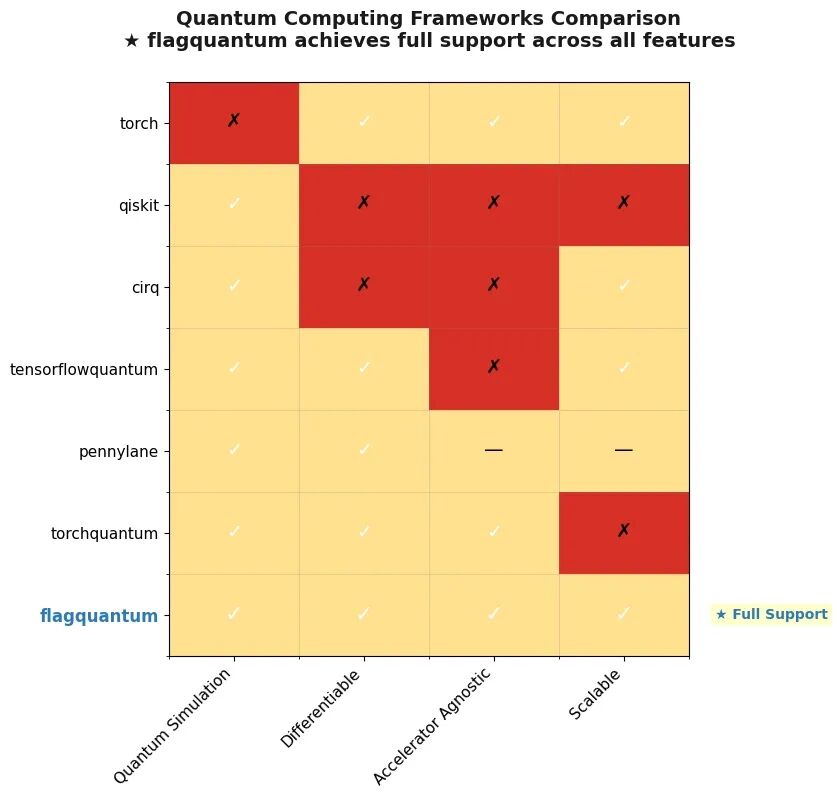
现有的量子计算框架普遍存在软硬割裂的局限。Qiskit 和 Cirq 等通用量子计算框架原生自动微分能力不足,难以适配变分量子算法(VQE/QAOA)的参数优化迭代。PennyLane 和 TorchQuantum 等混合 AI 框架虽在算法层引入了可微性,但底层通信架构仍基于静态 1D-MPI 或编译期硬编码网格,面对大比特状态向量模拟时缺乏多卡可扩展性。FlagQuantum 正是针对这两个短板设计的,也是目前唯一在量子模拟、可微性、加速器无关性、多卡可扩展性四个核心维度上均实现全面支持的框架。
框架对比矩阵图
图注:主流量子计算框架四维能力对比。横轴为四个核心维度:Quantum Simulation(量子模拟能力)、Differentiable(自动微分/变分支持)、Accelerator Agnostic(加速器无关性)、Scalable(多卡分布式扩展能力);纵轴为七个代表性框架。FlagQuantum 是唯一在全部四个维度实现完整支持的框架。
单卡端,传统的反向传播算法需要逐层缓存量子态的中间结果,显存开销随电路深度线性累积,其空间复杂度高达(O(L ·2ᴺ))。在 80GB A100 显存下,面对较深的实际工业级电路,可训练量子比特数被死死卡在 20 比特。为此,我们设计了可逆梯度引擎,利用量子门酉矩阵的可逆性(U†),在反向传播时采用实时重计算机制替代传统的逐层缓存,成功将显存开销与电路深度 (L) 完全解耦。在各类电路规模测试中,可逆梯度稳定提升 2 到 4 个可训练量子比特,GPU 与显存利用率均维持在 99% 以上。
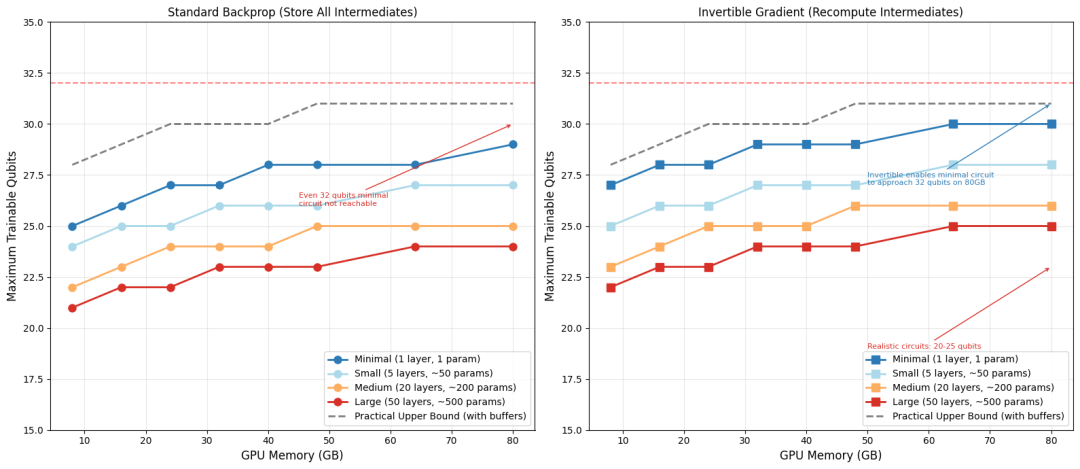
单卡框架对比矩阵图
图注:单卡可逆梯度引擎效果对比。(a) 标准反向传播需逐层缓存中间态,显存随电路深度线性增长,80GB A100 下 20 比特大型电路已触及极限;(b) 可逆梯度重计算机制在各规模电路上稳定释放 +2 至 +4 个可训练量子比特空间。
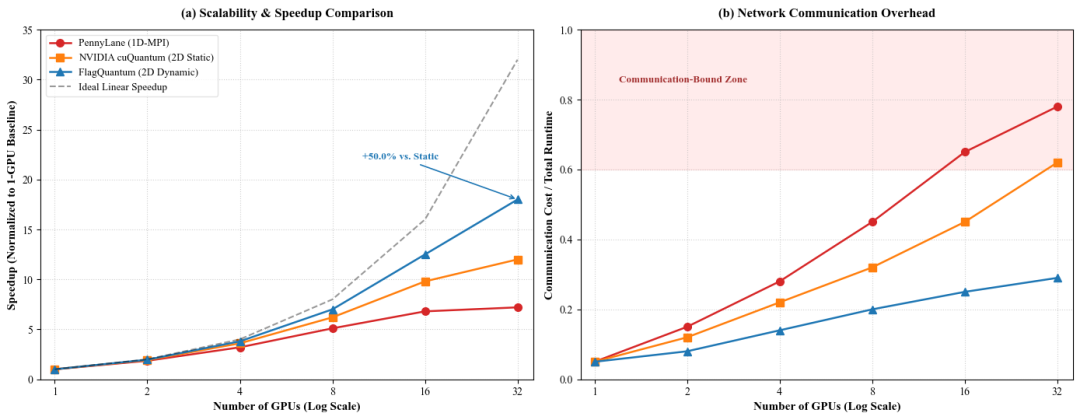
然而,即便可逆梯度极大释放了单卡潜能,但受限于状态向量随比特数呈指数增长(O(2ᴺ))的固有属性,在大 Batch 并行训练与优化器状态表缓存的叠加下,面对 20 层以上、25 比特以上的工业级参数化量子电路,单卡 80GB 的物理边界依然无法逾越—这直接论证了多卡分布式架构的必要性。多卡端,当量子门作用于高位控制量子比特时,传统1D-MPI 静态切分架构会触发全局的 All-to-All 阻塞通信,在跨节点扩展时引发严重的网络瘫痪。为此,智源提出了拓扑感知的2D动态切分架构。该架构将量子比特空间解耦为“节点间切分轴”与“节点内切分轴”,能够实时感知底层网络拓扑。通过内置的门序列动态重排管线,框架将跨节点 InfiniBand 的大算力数据对调,自适应转译为节点内 NVLink 的高并发流水线传输,有效规避了通信瓶颈。在 4 节点共 32 张 A100 的集群上,智源进行了弱扩展性(Weak Scaling)性能测试。实验中,可模拟的量子比特数随卡数同步成倍扩展(单卡负载维持恒定),直至满载的 32 卡集群挑战 32 比特、深度 20 层的工业级 QAOA 电路。测试结果显示:扩展至 32 卡时,PennyLane 和 NVIDIA cuQuantum (cuStateVec) 的通信开销分别飙升至 78% 和 62%,GPU 大量时间用于等待网络传输而非实际计算;FlagQuantum 将通信开销压制在 29% 以内,加速比较 cuQuantum 高出 50%,真正实现了分布式计算吞吐量随集群规模的近线性增长。多卡扩展性实验图
图注:QAOA 电路多卡扩展性对比(4 节点 × 8 卡 A100 集群)。(a) 加速比随 GPU 数量变化:传统方法在跨节点(16→32 卡)时遭遇规模墙,FlagQuantum 保持近线性扩展,较 cuQuantum 加速比高出 50%;(b) 通信开销占比:32 卡时 PennyLane 和 cuQuantum 通信占比分别达 78% 和 62%,FlagQuantum 压制在 29% 以内,GPU 始终保持在高效计算状态。注:本测试采用随着卡数同步按比例放大模拟规模的弱扩展性(Weak Scaling)规范。
整个训练链路原生集成 PyTorch—经典数据通过角度编码、振幅编码等方式嵌入量子态,进入参数化量子电路完成计算,测量结果构建经典损失函数,梯度自动回传更新门参数,全程无需手动干预。开发者调用量子电路与调用普通 PyTorch 层体验一致。电路通过 OpenQASM 2.0/3.0 中间表示导出,可部署至夸父量子云等真实量子硬件运行。FlagQuantum 已在二分类任务上跑通了从国产 GPU 训练到国产量子云推理的完整流程,推理精度与模拟器结果高度吻合。这是业界率先实现统一调度国产 AI 芯片与国产量子芯片的 AI 框架,在可微模拟、多卡扩展、加速器无关和真实量子硬件部署四个核心维度上处于全面领先地位。FlagQuantum作为态矢量模拟器,为量子算法开发与量子硬件评估提供了“理论标准答案”,是校准真实量子计算机性能、对比不同方案优劣的关键参照系。FlagQuantum已在海光、摩尔线程等国产芯片上完成适配。
FlagQuantum Github:
https://github.com/flagos-ai/FlagQuantum
科学计算的硬件适配是比大模型推理更碎片化的问题—分子动力学、量子化学、气象模拟等场景对底层数值计算的精度和性能要求极高,而研究者往往需要为每一种芯片单独维护一套底层实现,改造成本长期制约着科学软件的跨平台流通。
FlagOS 此前已在大模型推理中完成多芯算子能力的系统性验证,此次将这一能力正式延伸至科学计算领域。在 FlagGems 510+ 通用算子库基础上,新增六大领域算子库—FlagFFT(快速傅里叶变换)、FlagSparse(稀疏矩阵)、FlagBLAS(基础线性代数)、FlagTensor(张量运算)、FlagDNN、FlagAudio,共计 90 个算子,覆盖分子动力学、量子化学、气象模拟、偏微分方程、有限元、图神经网络等核心科学计算场景,适配18家厂商32款芯片,国产芯片全覆盖。FlagGems 同时是全球最大 Triton 单一算子库,并已纳入 PyTorch 基金会生态项目。
FlagGems Github:
https://github.com/flagos-ai/FlagGems
FlagOS AI for Science 算子库
所有算子均基于 Triton/Triton-TLE 实现,通过 FlagTree 统一编译器可编译至英伟达、华为昇腾、平头哥玄铁、海光、摩尔线程等十余种芯片后端。这意味着AI for Science 领域的研究者不再需要为每种芯片单独维护底层实现—同一套算子代码,即可在多类硬件上高效运行。六大领域库与 510+ 通用算子库的组合,为AI for Science模型在异构芯片上的部署提供了从底层计算到上层推理的完整技术栈。FlagOS 正在将多芯片适配的工程基础,系统性地铺向整个科学计算领域。四款AI for Science 模型首次适配发布
当下,AI for Science正在从"少数顶级实验室的前沿探索"走向"广泛科研工作者的日常工具"。然而,科学计算场景的硬件碎片化问题比大模型推理更为严峻—高校实验室、科研机构的计算资源千差万别,从集群到单卡、从GPU到国产加速卡,硬件异构性使得AI for Science模型的推广应用面临隐形门槛:一篇Nature上的分子模型,到了使用不同芯片的实验室就可能无法直接运行,跨芯片迁移的改造成本正在把先进模型锁在少数算力条件充裕的实验室里。让科研成果跨芯片自由流动,需要一个能够抹平底层差异的统一软件栈,众智FlagOS基于统一多芯片系统软件栈,完成了四款AI for Science领域代表性模型的多芯片适配与发布,覆盖化学分子、单细胞生物学、心脏医学影像三个学科方向,支持英伟达、海光两类AI芯片。这是FlagOS首次将多芯片适配能力从大语言模型拓展至AI for Science科学计算领域。BAAI Cardiac Agent—业内首个心脏磁共振(CMR)多模态智能体。北京智源人工智能研究院成功自研一套能动态协调多个子模型的Agent系统:输入一组心脏磁共振影像,依次完成序列识别、多腔室分割、心功能定量测量、疾病筛查和结构化报告生成。技术上采用Agent-Expert架构—微调的LLaVA多模态模型担任Agent,负责任务理解与调度;多个CNN专科模型作为Expert Worker,分别执行分割和分类。在性能验证上,2413例患者、7类心血管疾病多中心测试中,诊断AUC达到0.93以上。跨芯片验证的结果更为直接:LVEF、LVEDV、LVESV、SV、LVM、LVEDD六项心脏功能量化指标,在英伟达原生环境与海光-FlagOS环境之间实现零偏差。近期已在安贞医院手术中首次将数字孪生心脏带入外科手术室,为被称为"外科上的明珠"的瓣膜成形手术提供术中决策支持。BAAI Cardiac Agent 工作流程图
SMI-TED—大规模化学语言模型。来自 IBM Research,采用 Transformer Encoder-Decoder 架构,在 9100 万 PubChem 分子上预训练。输入 SMILES 分子式字符串,输出分子嵌入向量、性质预测值或重构分子结构,主攻材料科学中的分子性质预测与生成。在药物发现和新材料筛选场景中,可大幅缩短分子性质实验验证周期。FARM—功能基团感知的分子表征。UIUC 等机构出品,基于 BERT 架构(约 1.1 亿参数)。核心创新在于分子分词算法—在表征阶段即融入功能基团信息,而非依赖后处理提取,使模型对局部化学结构的感知更为精确。与 SMI-TED 形成互补:一个擅长全局理解与生成,一个聚焦功能基团做精确预测,两者可在分子科学研究中协同使用。C2S-Scale-Gemma-2-27B—单细胞生物学大模型。耶鲁大学 van Dijk 实验室与 Google 联合开发。通过 Cell2Sentence 框架将 scRNA-seq 数据按基因表达量降序排列为"细胞语句",让大语言模型直接处理单细胞数据。基于 Gemma-2 27B,在 5700 万细胞上训练,在细胞类型注释、基因扰动预测等任务上展现出跨物种泛化能力。四款模型覆盖化学、生物、医学影像三个学科,均已完成英伟达与海光双芯片适配验证。FlagOS 的多芯片统一软件栈正在将这一能力从大语言模型系统性延伸至科学计算领域,让更多实验室无论使用何种硬件,都能直接运行和部署前沿AI for Science 模型。附下载链接:模型 | 芯片 | 下载链接 |
|---|
BAAI-Cardiac-Agent | 海光 | https://modelscope.cn/models/FlagRelease/BAAI-Cardiac-Agent-hygon-FlagOS |
SMI-TED | 英伟达 | https://modelscope.cn/models/FlagRelease/materials.smi-ted-nvidia-FlagOS |
SMI-TED | 海光 | https://modelscope.cn/models/FlagRelease/materials.smi-ted-hygon-FlagOS |
C2S-Scale-Gemma-27B | 英伟达 | https://modelscope.cn/models/FlagRelease/C2S-Scale-Gemma-2-27B-nvidia-FlagOS |
C2S-Scale-Gemma-27B | 海光 | https://modelscope.cn/models/FlagRelease/C2S-Scale-Gemma-2-27B-hygon-FlagOS |
FARM | 英伟达 | https://modelscope.cn/models/FlagRelease/farm_molecular_representation-nvidia-FlagOS |
FARM | 海光 | https://modelscope.cn/models/FlagRelease/farm_molecular_representation-hygon-FlagOS |
模型 | 芯片 | 下载链接 |
|---|
BAAI-Cardiac-Agent | 海光 | https://huggingface.co/FlagRelease/BAAI-Cardiac-Agent-hygon-FlagOS |
SMI-TED | 英伟达 | https://huggingface.co/FlagRelease/materials.smi-ted-nvidia-FlagOS |
SMI-TED | 海光 | https://huggingface.co/FlagRelease/materials.smi-ted-hygon-FlagOS |
C2S-Scale-Gemma-27B | 英伟达 | https://huggingface.co/FlagRelease/C2S-Scale-Gemma-2-27B-nvidia-FlagOS |
C2S-Scale-Gemma-27B | 海光 | https://huggingface.co/FlagRelease/C2S-Scale-Gemma-2-27B-hygon-FlagOS |
FARM | 英伟达 | https://huggingface.co/FlagRelease/farm_molecular_representation-nvidia-FlagOS |
FARM | 海光 | https://huggingface.co/FlagRelease/farm_molecular_representation-hygon-FlagOS |
在算力平台端,FlagOS模型镜像已部署超算互联网平台,DeepSeek V4、Qwen3.5、MiniMax M2.7等大模型开箱即用,推理精度与原生版本对齐。中科曙光作为平台运营方,已将FlagOS整体集成至智算平台,面向科研用户提供从算力到模型的一站式服务。在教育端,FlagOS 与北京大学联合打造的开源课程已正式投入教学,将多芯片系统软件栈的工程实践引入高校培养体系。在开发者社区,我们持续举办"KernelGen 24 小时极限算子优化挑战赛",以真实工程问题邀请开发者参与算子的优化。各赛道冠军分别来自北京大学、中国人民大学、天津大学等高校,冠军方案已被直接纳入 FlagOS 官方算子库,形成社区贡献反哺系统能力的正向循环。https://github.com/flagos-ai/KernelGen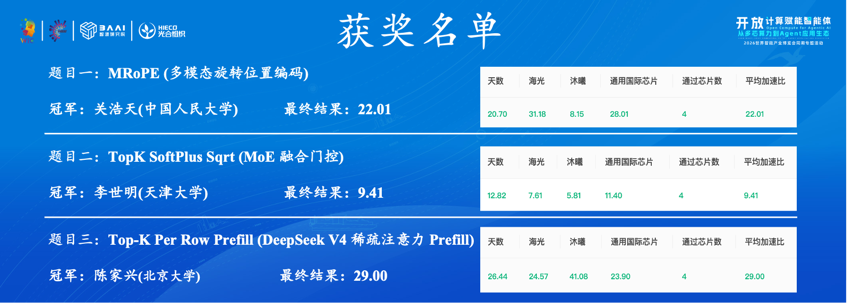 5.29 KernelGen 24小时极限算子优化挑战赛成绩公布
5.29 KernelGen 24小时极限算子优化挑战赛成绩公布
为解决不同AI芯片大规模落地应用,北京智源研究院联合众多科研机构、芯片企业、系统厂商、算法和软件相关单位等国内外机构共同发起并创立了众智FlagOS社区,目前已经有78家成员单位。FlagOS是一款专为异构AI芯片打造的开源、统一系统软件栈,支持 AI 模型一次开发即可无缝移植至各类硬件平台,大幅降低迁移与适配成本。它包括大型算子库、统一AI编译器、并行训推框架、统一通信库等核心开源项目,致力于构建「模型-系统-芯片」三层贯通的开放技术生态,通过"一次开发跨芯迁移"释放硬件计算潜力,打破不同芯片软件栈之间生态隔离。社区官网:https://flagos.io
GitHub:https://github.com/flagos-ai
GitCode:https://gitcode.com/flagos-ai
模型镜像下载:https://huggingface.co/FlagRelease
https://modelscope.cn/organization/FlagRelease
FlagOS社区欢迎更多开发者、研究者和硬件厂商加入共建。
内容中包含的图片若涉及版权问题,请及时与我们联系删除





评论
沙发等你来抢