
作为机器学习与人工智能领域公认的顶级盛会,ICML 2026(第 43 届国际机器学习大会,International Conference on Machine Learning)将于 2026 年 7 月 6 日至 7 月 11 日在韩国首尔 COEX Convention & Exhibition Center 举行。
本届大会竞争尤为激烈,在全球收到的 23918 篇投稿中,仅有 6352 篇论文成功入选,录取率约为26.6%。这一严苛的筛选标准,使得最终入选的论文不仅代表了当前学术界的最前沿理论突破,更深刻反映了工业界落地应用的迫切需求与技术风向。
今年 ICML 淘天集团有多项前沿工作脱颖而出。这些工作不再仅仅满足于提升基准测试的分数,而是直击真实场景中的核心痛点——无论是真实视频虚拟试衣的交互缺失;还是高分辨率图像下被噪音淹没的“关键细节”,亦或是强化学习中难以捉摸的“奖励稀疏”困境。
本期精选的五篇论文,不仅展示了算法层面的精妙创新,更标志着多模态 AI 正向着更懂物理交互、更具商业价值、更加可靠可控的方向坚实迈进。
iTryOn打破了视频虚拟试衣的交互局限,引入 3D 手部先验与时序语义,让 AI 模特真正学会“动手”展示服装细节。 HiDe以反直觉的洞察颠覆了传统“放大(Zoom-in)”策略,通过层次化解耦分析找出 MLLM 高分图像性能退化的真正原因。 E-VAds填补了多模态大模型在电商短视频商业逻辑理解领域的学术空白,更为复杂高噪场景下大模型强化学习的对齐演进提供了一套极具工业参考价值的新范式。 TP-GRPO则针对流匹配文生图强化学习优化问题,通过“步级增量奖励”和引入“转折点”建模机制,破解了训练中奖励稀疏困局。 RuCL 针对多模态大语言模型推理中的奖励作弊与幻觉,提出基于分层规约的课程学习框架,将关注点从传统的“数据筛选”转向“奖励权重设计”。
1、iTryOn:交互型视频虚拟试衣框架,让 AI 模特真正“动手展示”服装
《iTryOn: Mastering Interactive Video Virtual Try-On with Spatial-Semantic Guidance》
论文链接:https://arxiv.org/abs/2605.21431
痛点:现有视频虚拟试衣方法大多只能生成非交互式展示视频,例如模特走秀、转身、摆姿势等。但在真实电商直播中,主播往往会主动与服装互动,例如拉伸衣角、拉开拉链、挽起袖口等。这类动作能够展示服装弹性、版型、内搭和细节,对提升用户购买意愿非常重要。
解决方案:提出交互型视频虚拟试衣框架 iTryOn,将视频试衣建模为由服装图像和动作语义共同引导的条件生成任务,使模型不仅能完成换装,还能生成自然的人衣交互动作。
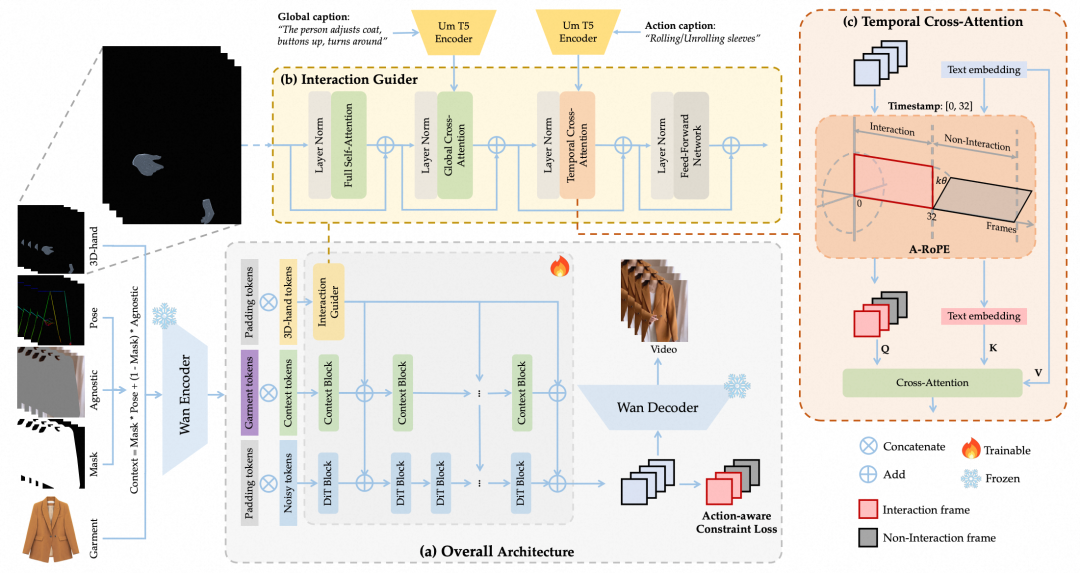
iTryOn 包含三个关键技术贡献点:(1) 引入 3D 手部先验,为模型提供更精细的手部姿态和空间位置信息,避免了传统 2D 人体关键点缺少深度信息导致的歧义性;(2) 使用带时间戳的交互动作类别标签,明确告诉模型交互动作的类型、开始时间和持续时间,并通过动作感知旋转位置编码 A-RoPE 实现动作语义与视频帧之间的精准时序对齐;(3) 提出动作感知约束损失 AC Loss,在训练过程中强化对交互动作帧的监督,避免稀疏的交互信号被大量非交互帧淹没,从而提升模型对复杂交互动作的生成能力。
实验结果:iTryOn 不仅在交互型视频试衣任务上展现出明显优势,在传统视频虚拟试衣任务中也优于其他方法。模型能够更准确地理解手部与服装之间的空间关系,并生成更加自然、连贯的人衣交互视频。
2、HiDe:重构高分辨率多模态认知机制,基于"Zoom-in"深度拆解的免训练新范式
《HiDe: Rethinking The Zoom-IN method in High Resolution MLLMs via Hierarchical Decoupling》
论文链接:https://arxiv.org/abs/2510.00054
痛点:现有多模态大模型(MLLM)在处理高分辨率图像时往往表现不佳。业界传统观点将其归结为“感知限制(目标物体过小)”,因而广泛依赖“放大(Zoom-in)”策略来恢复细节。然而,模型真的是因为看不清才表现不好吗?当前学术界缺乏对该机制底层失效根源的深度归因。此外,现有的视觉搜索与裁剪方案多存在推理极度低效、多目标易漏检、且极易引发显存溢出等落地瓶颈。
解决方案:本文突破性地对"Zoom-in"操作进行了严密的层次化解耦分析(层层拆解为:放大与裁剪、前景与背景、语义与非语义 Token、外观与空间布局)。实验论证了一个反直觉的结论:单纯的“像素放大”对模型认知几乎毫无帮助,MLLM 高分图像性能退化的真正原因在于“复杂的背景语义干扰与海量的 Token 冗余”。
基于这一深刻洞察,本文提出了一种名为 HiDe 的免训练优化框架,将隐式的注意力过滤转化为显式的区域提取:首先,通过 Token 级注意力解耦(TAD),精准分离问题语义,剥离背景中的噪音,实现对多个微小物体的精准定界;其次,引入保持布局的解耦重构(LPD),将目标区域从杂乱背景中彻底抽离,并重组为高信息密度的紧凑表征,在过滤冗余 Token 的同时严格保留了关键的空间关系。此外,结合独创的单次张量卸载工程优化,打破了高分图像推理的显存壁垒。
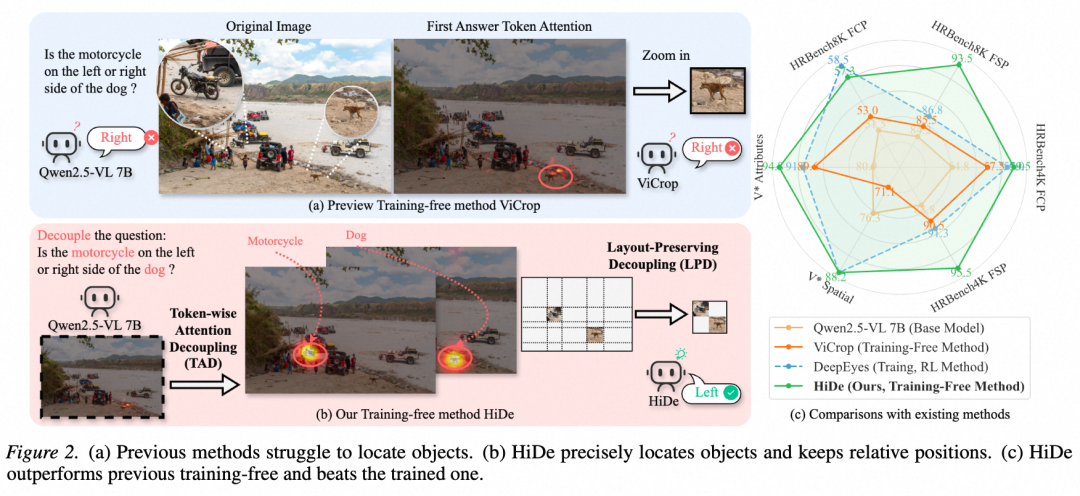
实验结果:凭借对失效根源的精准把控,HiDe 在 V*Bench、HRBench 等极具挑战性的高分辨率评估集中全面实现 SOTA,不仅优于现有免训练方案,甚至超越了基于强化学习(RL)精调的基线模型。在部署指标上,相比原有方案,HiDe 将峰值显存占用大幅压降 75%(自 96GB 降至 20GB),同时将推理延迟减半,为高分辨率 MLLM 的低成本、规模化工业部署提供了极具理论深度的新范式。
3、E-VAds:电商短视频理解新基准,突破高密度多模态商业推理瓶颈
《E-VAds: An E-commerce Short Videos Understanding Benchmark for MLLMs》
论文链接:https://arxiv.org/abs/2602.08355
痛点:现有多模态视频基准多聚焦于通用场景,严重忽视了电商短视频中高密度多模态信号(视/听/文本的极速交织)与商业转化意图的复杂性。面对开放式的商业认知推理任务,现有大语言模型(MLLM)由于缺乏专业的高质量评测数据以及有效的强化学习奖励信号,在此类真实业务场景中表现疲软。
解决方案:本文提出了首个针对电商短视频理解的综合评估与优化框架。为克服高信息密度与开放式推理的挑战,采用了“量化评估 - 基准构建 - 强化对齐”三阶演进范式:
多模态密度度量(Metric):提出视觉动态、音频语速、文本覆盖三大密度评估指标,首次定量揭示了电商视频极端高信息密度的任务复杂度。 E-VAds 数据基准(Benchmark):依托“多智能体协作生成 + 人工审查”机制,构建了首个电商视频推理基准,包含 3,961 个短视频与 19,785 个高质量问答对。 E-VAds-R1 推理模型(Model):针对商业推理奖励稀疏的痛点,研发了基于强化学习的 R1 模型,并引入多粒度相对策略优化(MG-GRPO)。该机制通过混合宽严评分,兼顾了模型早期探索的平滑引导与精准推理的非线性激励。

实验结果:E-VAds-R1 仅需几百条训练数据,即可在复杂的商业意图推理任务上实现高达 109.2% 的性能提升,显著超越现有的强通用基线模型。我们的工作不仅填补了多模态大模型在电商短视频商业逻辑理解领域的学术空白,更为复杂高噪场景下大模型强化学习的对齐演进提供了一套极具工业参考价值的新范式。
4、TP-GRPO: 全面建模流匹配强化学习中关键步骤的长短程交互作用
《Alleviating Sparse Rewards by Modeling Step-Wise and Long-Term Sampling Effects in Flow-Based GRPO》
论文链接:https://arxiv.org/abs/2602.06422
痛点:对于基于 Flow Matching 的文生图强化学习优化问题,现有 Flow-GRPO 一类方法通常将最终生成结果的奖励统一分配给所有去噪步骤,其会带来两个问题:其一,奖励信号过于稀疏,无法准确刻画不同去噪步骤的真实贡献;其二,方法主要关注同一时刻不同轨迹之间的排序,却忽略了单条轨迹内部跨步骤的依赖关系,尤其是早期关键去噪动作选择对后续生成质量的延迟影响。
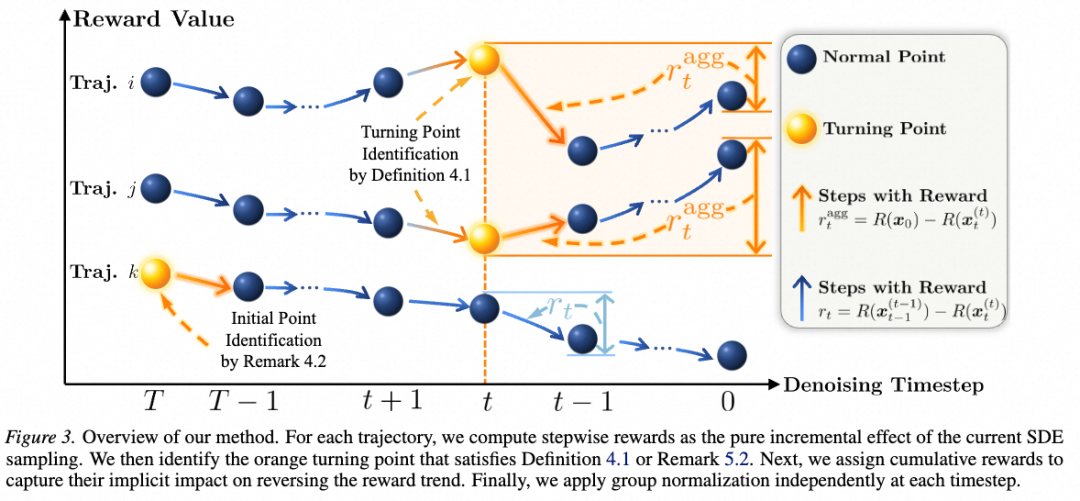
解决方案:针对这些问题,本文提出 TurningPoint-GRPO(TP-GRPO)。该方法一方面以“步级增量奖励”替代终局奖励传播,通过比较单步去噪前后的奖励变化,为每一步提供更细粒度、更准确的学习信号;另一方面首次提出在扩散模型去噪过程中引入“转折点”建模机制,识别那些能够扭转局部奖励趋势、并对后续轨迹产生隐式引导的步骤,并为其分配聚合式长期奖励,从而在去噪路径内部挖掘可靠的监督信息,显式建模关键去噪动作的长程影响。
实验结果:TP-GRPO 在组合生成、文本渲染和人类偏好对齐等任务上均稳定优于 baseline;同时,在 Flow-GRPO 的验证设置上部署到 SD3.5 与 FLUX.1-dev 时,也均能持续超过既有方法,展现出良好的有效性与鲁棒性。
5、RuCL:基于分层规约的多模态大语言模型推理课程学习
《RuCL: Stratified Rubric-Based Curriculum Learning for Multimodal Large Language Model Reasoning》
论文链接:https://arxiv.org/abs/2602.21628
痛点:多模态大语言模型(MLLM)在强化学习(如 RLVR)中过度依赖终局结果(Outcome-only)进行监督,极易诱发“奖励作弊(Reward Hacking)”——模型通过混乱或幻觉的中间推理步骤凑出正确答案。尽管引入规约(Rubrics)的过程监督能缓解此问题,但现有多模态方法通常针对单个样本在线生成规约,计算开销极高;且在训练时对所有规约一视同仁,导致模型在未掌握基础感知时便被强加高阶逻辑惩罚,造成严重的梯度噪声与训练不收敛。
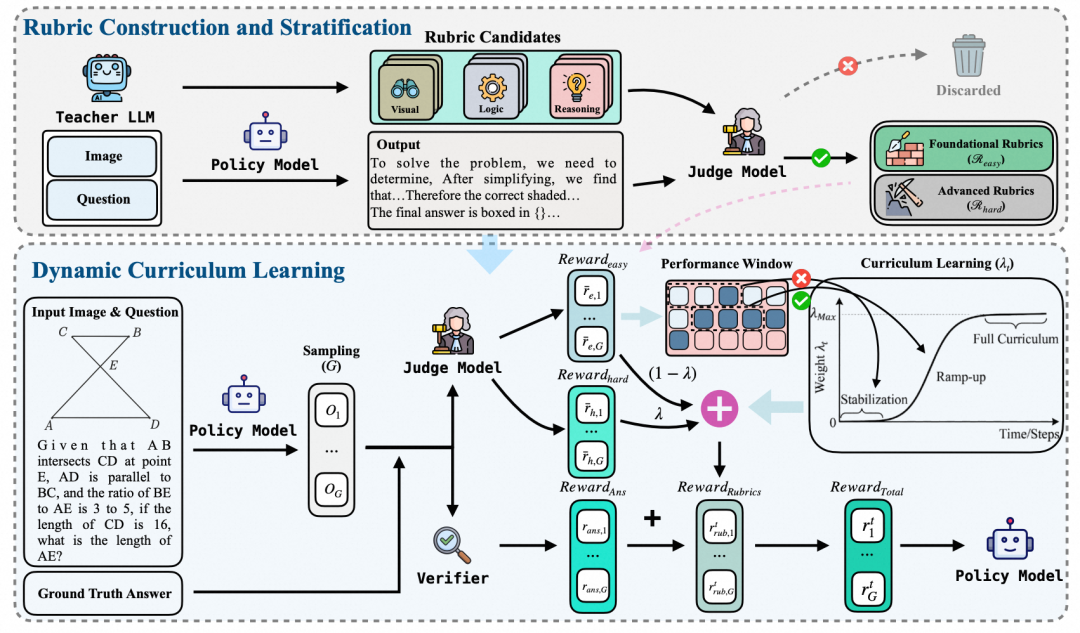
解决方案:团队提出了一种基于分层规约的课程学习框架(RuCL),将课程学习的关注点从传统的“数据筛选”转向“奖励权重设计”。一方面,框架采用数据驱动的方式离线构建一组通用的多模态推理规约,避免了样本级生成的昂贵开销;另一方面,依据模型初始通过率将规约划分为“基础感知”与“进阶推理”两层,并在训练过程中利用性能触发调度器动态调整两者的奖励权重(λ_t),引导模型稳步实现从基础视觉定位到高阶逻辑演绎的平滑过渡。
核心技术架构:
实验结果:该方法在数学推理和通用视觉推理等七大主流基准上均显著优于多种强基线。RuCL 在 Qwen2.5-VL-7B 基础模型上取得了 +7.83% 的平均性能提升,达到了 60.06% 的 SoTA 准确率(在 WeMATH 与 LogicVista 上分别提升 12.97% 和 **10.40%**)。消融实验表明,其渐进式奖励机制有效降低了早期的梯度方差,并在不牺牲感知能力的前提下显著抑制了逻辑作弊与幻觉。
以上精选收录论文里有哪些内容是你感兴趣滴,在评论区说出你的想法~没准儿就有机会提前看到背后的论文解读细节哦!

也许你还想看
关注「阿里妈妈技术」,了解更多~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢