
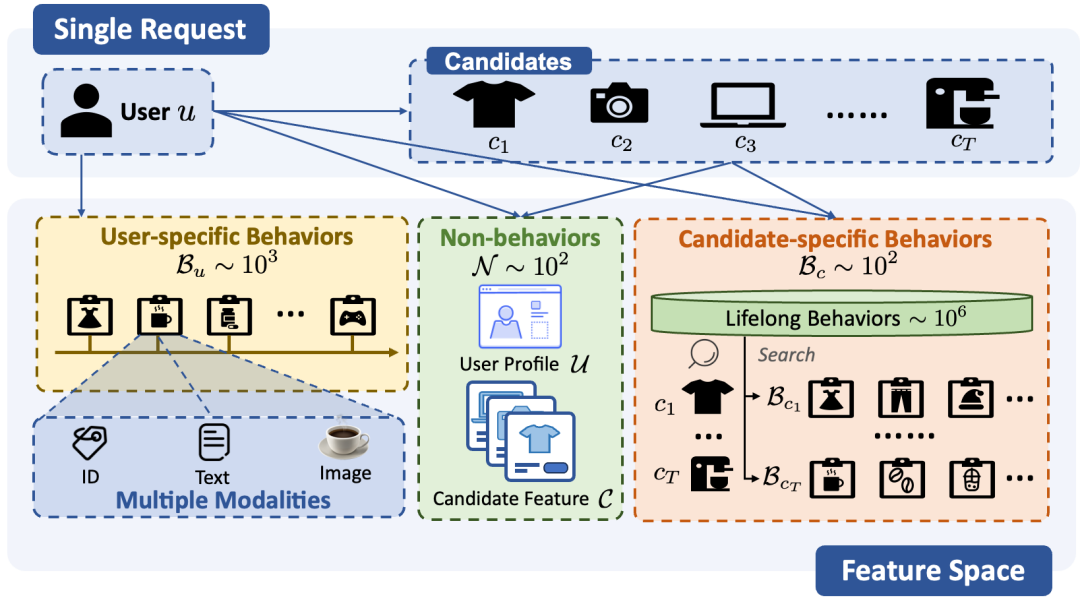
引言:大语言模型 (LLM) 的快速演进验证了“规模即智能”:随着参数、数据与算力持续扩展,模型性能往往呈现稳定且可预测的提升,这也促使我们重新思考工业 CTR 预估任务是否存在通向“大模型化”的可行路径。但与语言建模不同,CTR 场景输入高度异构:既包含长而稀疏的行为序列,也包含数量有限但决策价值极高的非行为特征,同时还需满足高吞吐、低时延的工程约束,因此现有方法多采用先压缩行为序列、再联合建模的层级范式,虽然高效,却形成了难以逆转的信息瓶颈,限制了模型继续扩展的收益。
那么什么样的架构才真正适合推荐系统的大模型化?通过重新审视 CTR 与 LLM 的结构差异,本文提出两个关键判断:一是行为特征与非行为特征存在显著的信息密度不对称,不同类型交互的建模价值并不相同;二是内容模态具有强烈的模态特异性先验,更适合作为关系建模的指导信号,而非被简单视作普通 token 混入统一序列。
基于这两点,阿里妈妈展示Rank团队提出EST(Efficiently Scalable Transformer),在不依赖早期有损聚合的前提下,实现全部原始输入的全序列统一建模,并通过 LCA 与 CSA 两个模块分别解决算力分配与内容信号利用这两个核心问题。EST在淘宝展示大规模商业化场景中验证了“全序列化统一建模”的工程可行性,也为工业级CTR预估模型迈向大参数时代提供了一条清晰而高效的演进路径。
论文标题:EST: Towards Efficient Scaling Laws in Click-Through Rate Prediction via Unified Modeling
论文作者:Mingyang Liu, Yong Bai, Zhangming Chan, Sishuo Chen, Xiang-Rong Sheng, Han Zhu, Jian Xu, Xinyang Chen
论文链接: https://arxiv.org/pdf/2602.10811
一、背景
语言模型所展现出的泛化能力,以及Scaling Laws所揭示的持续扩展收益,正在推动推荐系统进入“大模型化”的新阶段。但与语言任务不同,工业推荐首先面对的是极为严格的线上约束:系统需要在毫秒级时延内,为单次请求完成数千个候选物品的打分。这意味着,模型不仅要追求更强的表达能力,还必须同时满足高并发、低延迟的部署要求。也正因如此,标准Transformer虽然具备强大的建模潜力,却很难直接迁移到工业推荐场景中,其计算成本会随着参数规模和序列长度同步上升,在线推理代价难以接受。因此,推荐大模型真正需要回答的,不只是“能否Scale",而是“如何高效Scale"。
这一问题的复杂性,还来自工业推荐系统自身的演化方式。多数线上模型并非自上而下统一设计,而是在长期业务迭代中逐步叠加形成。这样的路径保证了实用性,却也带来了大量碎片化结构与细粒度算子,使得GPU难以充分发挥并行优势,算力开销大量消耗在非关键计算和硬件利用不足的环节中。要让推荐系统真正走向大模型,仅仅增加参数并不足够,更需要在建模范式上完成一次面向硬件效率的重构,将分散的结构统一到更适合GPU执行的框架中,从而为后续的规模扩展建立可持续的基础。
 图注:传统层级建模与统一序列建模的结构对比
图注:传统层级建模与统一序列建模的结构对比
现有的技术路线主要分为两大范式:
层级建模范式
传统的层级建模方案通过 DIN[1]、LONGER[2] 等模块先将海量行为序列聚合成固定长度向量,再与非行为特征联合建模。这种序列的早期聚合虽换来了高效的实时推理,却以牺牲序列细粒度 token 信号为代价,制约了 Scaling Law 的性能收益。
统一建模范式
为保留细粒度信号,最近业界一些工作尝试将用户行为与上下文特征放入同一序列联合建模[3],并通过用户侧“计算复用”大幅分摊线上开销。然而,现有架构仍然属于“部分统一”:候选侧序列(如 SIM 子序列[4])无法跨候选共享,只能被迫压缩成定长向量,信息损失问题并未根除。
为实现真正意义上的“统一建模”,最大化释放 Scaling 红利,本文从分析 CTR 预估任务与 LLMs 的底层差异出发,提炼出两大 insights,指导设计高效扩展的 CTR 预估模型。下一节将对具体 Insights 进行详细阐述。
二、发现
为突破现有架构的瓶颈,实现真正的全序列统一建模并充分释放模型的 Scaling 潜力,我们摒弃了对 Transformer 的生搬硬套,并基于对 CTR 预估任务与 LLMs 的底层逻辑的对比设计了验证性实验,明确了架构设计上的两大关键 insights,作为构建高效可扩展推荐架构的设计指导:
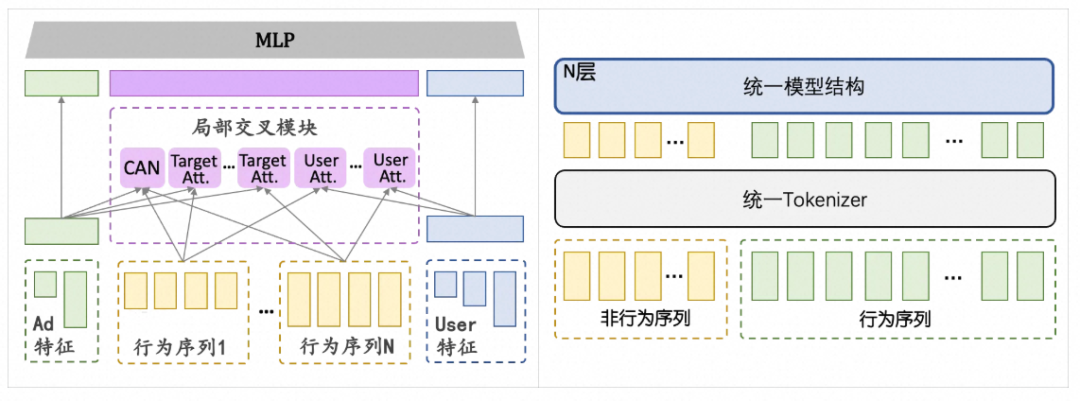
信息密度指导交互先验 异质特征的信息密度不对称性:不同于 LLM 中相对同质的 token 序列,CTR 预估模型的输入呈现高度异构与信息密度不对称:高信息密度的非行为特征 N 需与海量、低信噪比的用户行为序列 B 进行交互; 交互贡献的非均衡性:基于有效秩分析和 Mask 消融实验,本文发现不同密度特征的交互对性能的贡献并不相等。其中以非行为特征 N 作为 queries,行为序列 B 作为 keys/values 的 Cross-attention 是性能的主要贡献来源; 架构设计启示:算力应向高收益项倾斜,简化标准 self-attention 中的冗余计算,以在严格算力预算下实现效率与效果的最优解。
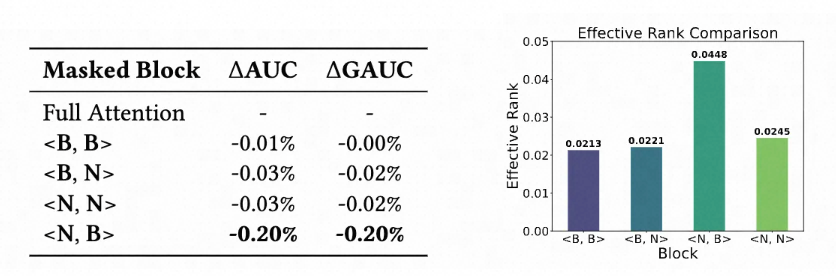 图注:分块 Mask 消融实验与有效秩分析实验
图注:分块 Mask 消融实验与有效秩分析实验内容信号更适合作为语义先验 模态特异性先验:内容表征集成方法的对比实验表明,将图像、文本等稠密内容表征直接转化为 token 嵌入并非最优解。相反,将其作为相似性先验引导 ID 特征交互,能更高效地弥合语义鸿沟。 架构设计启示:内容特征需要专门的利用机制,而不再局限于简单的 token 级交互。
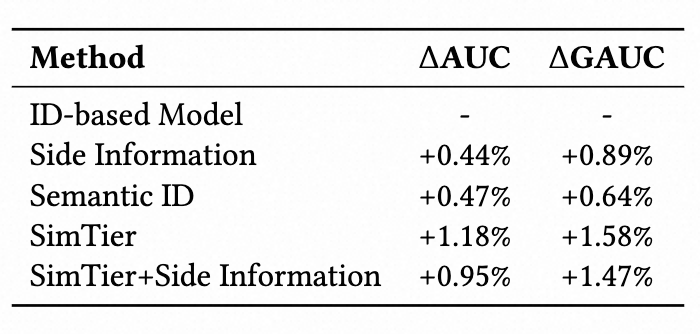
三、方案
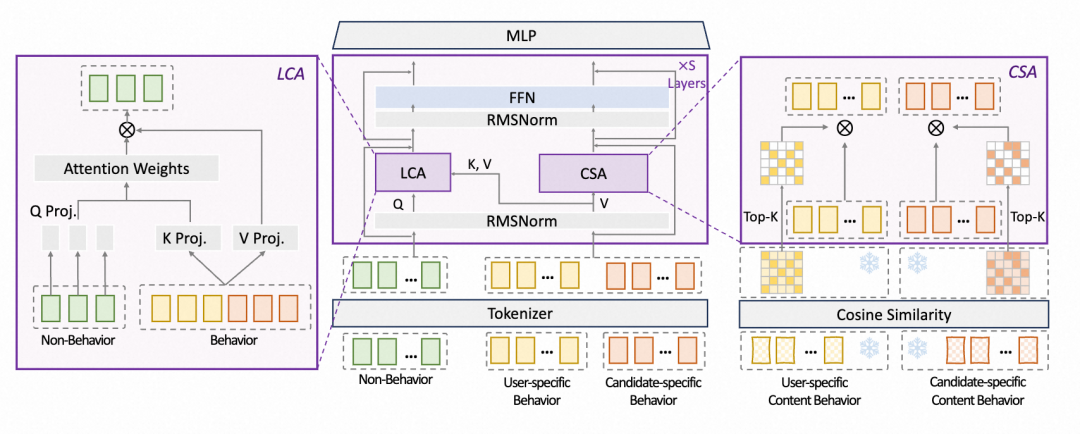 图注:EST 模型结构图
图注:EST 模型结构图3.1 整体框架
基于以上分析,本文提出EST模型,包含两个核心模块:(1)轻量级交叉注意力(LCA) 聚焦高收益的跨特征交互,舍弃冗余行为自交互,支持包括候选侧序列在内的用户行为序列,避免早期聚合带来的信息损失,为Scaling释放空间;(2)内容稀疏注意力(CSA) 将内容信号转化为相似性先验,动态筛选高相关行为子集进行稀疏计算,以极低开销换取显著性能增益,有效实现了内容模态的高效集成。
3.2 LCA
基于“信息密度指导交互先验”这一insight,本文提出Lightweight Cross-Attention(LCA)。LCA模块以非行为特征N为queries,行为序列B作为 keys/values,聚焦高收益交互项,摒弃冗余计算。LCA具备两大工业部署优势:(1)计算解耦与复用:支持用户侧序列的计算被所有候选商品共用,显著降低推理延迟;(2)复杂度简化:通过摒弃冗余计算,将标准自注意力的二次方复杂度降为双线性复杂度,支持处理长行为序列,满足毫秒级延迟预算。
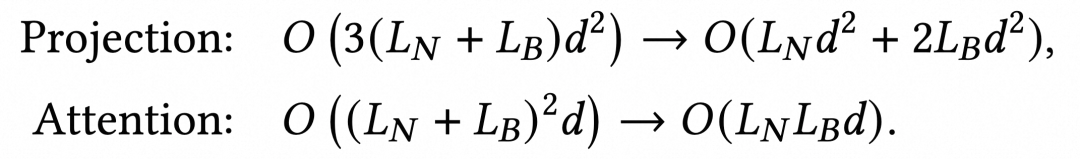
图注:计算复杂度对比:标准 Self-Attention vs. LCA
3.3 CSA
基于“内容信号更适合作为语义先验”这一insight,本文提出Content Sparse Attention(CSA)。与依赖可学习参数的传统自注意力不同,CSA利用冻结的内容表征之间的语义结构引导序列内交互,实现免训练且高效的计算。为保持用户候选计算解耦,CSA独立处理用户侧行为序列和候选侧行为序列。
具体来说,CSA模块利用计算归一化的内容表征计算相似度矩阵,该矩阵源于冻结特征、无需参与反向传播且可跨层复用,直接作为免训练的注意力权重作用于行为序列的ID特征。此设计有效融合了ID的共现关系与内容的语义关系。为避免二次复杂度的计算瓶颈,CSA引入Top-K稀疏化操作(在所有实验中,K设置为5),使每个item仅与最相似的K个item交互,计算复杂度被降至

图注:CSA 伪代码实现
该设计带来三大工程优势:(1)并行预计算:相似度矩阵的构建与稀疏化可与特征处理并行,支持跨层复用,计算延迟可忽略;(2)计算解耦与复用:独立处理用户侧行为序列和候选侧行为序列,支持用户侧计算跨候选共享;(3)线性复杂度:Top-K 稀疏化将计算复杂度降至与序列长度呈线形关系。
四、离在线实验效果
4.1 离线实验对比
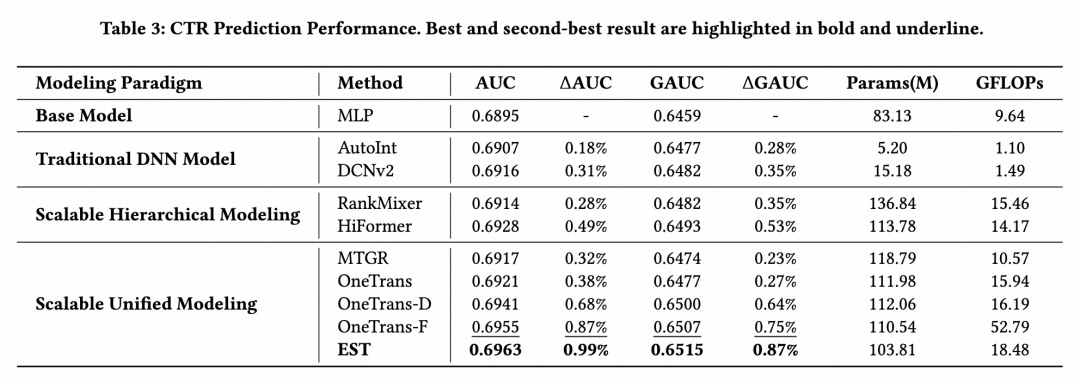
为全面评估EST的离线性能,本文将其与 RankMixer[5]、MTGR[6]、OneTrans[3] 等前沿模型进行严格对比。为确保实验公平性,所有模型的参数量均统一控制在0.1B量级。在工业推荐场景中,离线GAUC提升0.1%通常就能带来显著的线上收益。离线结果充分验证了EST架构的有效性。
4.2 Scaling 实验
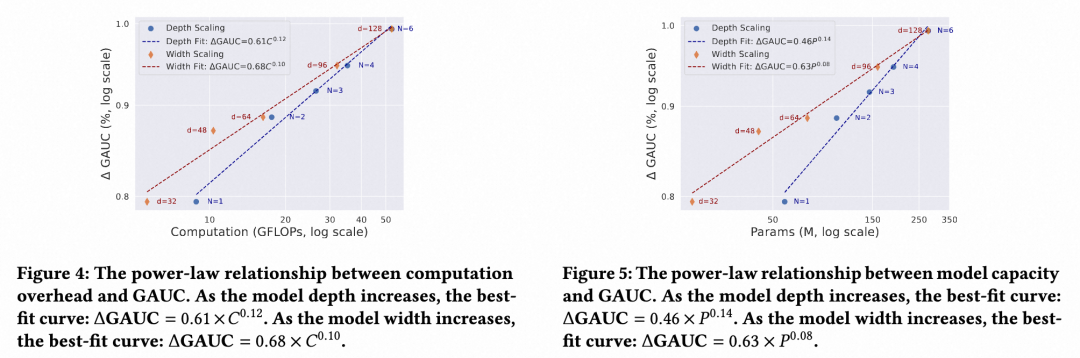
为验证EST的可扩展性,沿计算开销 C 和模型参数量 P 两个维度进行Scaling Law分析。实验通过调节网络深度与宽度,覆盖5~50 GFLOPs的计算预算与0.03B~0.3B的参数规模。对数变换后的拟合曲线表明:无论是增加算力还是参数量,
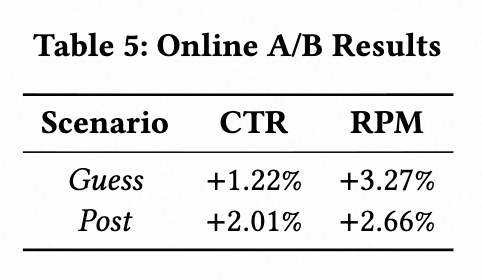
4.3 在线 A/B 实验
淘宝工业系统上的在线 A/B 实验结果表明,与生产基线相比,EST取得显著收益:在全站推广[7] 计划中,EST在“猜你喜欢”场景中,CTR 提升 1.22%,RPM 提升 3.27%;在“购后”场景中,CTR 提升 2.01%,RPM 提升 2.66%。该结果充分证明了EST模型在复杂工业环境下卓越的推荐性能,带来显著业务收益。
References
[1] Zhou, Guorui, et al. "Deep Interest Evolution Network for Click-Through Rate Prediction." Proceedings of the 33rd AAAI Conference on Artificial Intelligence. 2019.
[2] Chai, Zheng, et al. "LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders." Proceedings of the 19th ACM Conference on Recommender Systems. 2025.
[3] Zhang, Zhaoqi, et al. "OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender." arXiv preprint arXiv:2510.26104. 2025.
[4] Pi, Qi, et al. "Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction." Proceedings of the 29th ACM International Conference on Information and Knowledge Management. 2020.
[5] Zhu, Jie, et al. "RankMixer: Scaling Up Ranking Models in Industrial Recommenders." Proceedings of the 34th ACM International Conference on Information and Knowledge Management. 2025.
[6] Han, Ruidong, et al. "MTGR: Industrial-Scale Generative Recommendation Framework in Meituan." Proceedings of the 34th ACM International Conference on Information and Knowledge Management. 2025.
[7] Li, Ningyuan, et al. "Beyond Advertising: Mechanism Design for Platform-Wide Marketing Service"QuanZhanTui"."Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 2025.
关于我们
阿里妈妈展示Rank团队负责核心商业化预估算法的迭代和创新研发,致力于利用人工智能前沿技术打造超大规模体量下的创新预估解决方案。团队在模型参数Scaling (EST)、用户兴趣建模及终身序列建模 (DIN,DIEN,SIM,MUSE)、多场景建模 (STAR)、CVR 预估 (ESMM, DEFER, HDR, MAL)、多模态建模 (TaobaoMM) 等技术方向上持续深耕,用持续的技术突破和创新带动业务增长。近年在KDD、SIGIR、CIKM、WSDM等学术会议上发表多篇论文。欢迎感兴趣同学加入我们~
📮 投递简历邮箱:zhangming.czm@taobao.com

也许你还想看
关注「阿里妈妈技术」,了解更多~
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢