
卷友们好,我是rumor。
最近被微软这份109页的MAI-Thinking-1技术报告[1]整感动了。
不同于现在大部分报告就把大家都知道的流水线讲一遍,抛几个亮点但又遮遮掩掩,微软的技术报告中讲了很多他们的设计思考和效果优化技巧,又让我找到了当年那个“微软”的感觉。
要知道在BERT的时代,微软一直是NLP研究的领头羊之一,提出了一系列极具影响力的工作。而到了近三年的LLM纪元,他们却一度把资源倾向OpenAI,弱化了自研路线。
但巨兽不会一直甘于沉寂,上周微软一口气推出了7款模型,而且一下就搞了个大的,其主打的MAI-Thinking-1,35B激活/1T总参,要知道一般刚起步都不会上来就赌这么大的模型,微软选择尺寸,说明他们整套流程已经run到了比较成熟的阶段,且认为这个基座在未来几个月会持续具备竞争力。
他们在技术报告开篇就讲了三条设计原则:
能力要自己学,不能靠蒸馏继承。蒸馏虽快,却缺失了长跑最需要的可控和稳健 简单才可持续。只有简单且scalable的策略、干净的数据、透明的设施,才能撑住模型持续提升 严谨,不抄近路。每个决策都需要被ladder、消融、评测验证
其实这三条原则有经验的厂都知道,但应该如何设计满足这些原则的、可持续稳定产出模型的系统,就是另一个难度了。今天就分享一下微软在预训练和后训练中,我感悟比较深的部分。
预训练Ladder怎么爬
Ladder设置
预训练基座里最折磨人的部分,就是一个策略、结构、数据明明在小模型上效果拔群,结果scale上去之后收益直接蒸发了,白忙活一场。所以爬梯子是很重要的,也就是逐步推到更大的计算量下,看收益增长或下降的情况。
但是梯子怎么爬?更大的尺寸参数都加在哪里?训多少token?
微软直接让层数成为「规模」唯一的变量:
参数规模只由层数L决定,隐藏维按固定比例D=L*256/3,微软设计了L12-L78共8个梯子 锁死TPP(tokens per active parameter,训练Token量/参数量),架构消融在100-200 TPP(Chinchilla最优附近),主训练在500-1000 TPP,主要是希望产出一个相对更紧凑、适合高强度推理需求的模型,所以进行over train换取推理效果
如何衡量效果
确定了梯子怎么设计之后,接下来就是如何定义「好的scale效果」的问题。比较naive的方式就是实验组和对照组分别跑几个梯子,通过scaling law推一下他们在最终尺寸的效果,但这还有俩问题:
Scaling law拟合本身是有误差的,拿两条都带噪声的曲线相减,噪声是叠加的,差距小一点就淹没在拟合误差里了 就算你比出来了,结论是「相等算力下,曲线A比曲线B的loss低0.05」,可0.05到底显著吗?
翻译一下就是,loss这把尺子难衡量。因此微软的解法是换一把尺子——不比loss的绝对差,比「要追上你得多烧多少算力」,这个比值就叫效率增益(Efficiency Gain,EG)。
具体的计算方法是,先对baseline那条ladder拟一个scaling law
这里C是训练成本(FLOPs或时间),A控制loss的整体量级,α控制loss随算力下降的速度,E是降不下去的不可约loss。然后对一个用成本C′跑到loss为L′的候选,去计算:baseline要达到同样这个loss,得花多少算力?记作f⁻¹(L′)。两者一除就是EG:
EG = 1.3,意思是baseline得多烧30%的算力,才能追上候选模型的loss。 这样就清晰多了。
同时,微软只对baseline拟一条曲线当「标尺」,候选模型的每个数据点,是直接投影到这条标尺上去算EG的,并不给候选单独再拟一条曲线。 这么做的好处是全程只有一条曲线在承担拟合噪声。
不过,单个EG只能告诉你某个尺寸上的好坏,真正的答案藏在EG随算力的走势里。,算出EG曲线后,要看:
EG在不在1以上?这说明候选到底有没有用 随着算力变大,EG是稳住、甚至往上走,还是一路往1衰减?这说明这个增益是否能继续scale
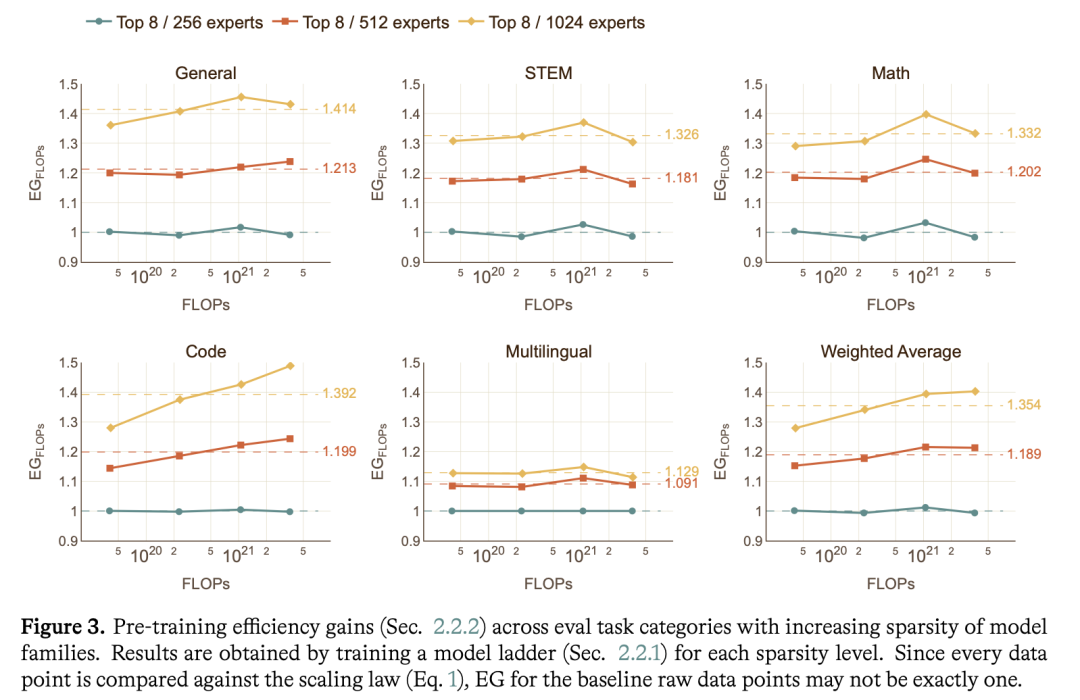
另外的一个设计是,在计算EG时会有两个口径,会分别以FLOPs和时间作为成本C:
EG_FLOPs:不计入实现效率,只看纯架构谁更强 EG_Time:用真实训练时间当成本,因为有些架构已经优化过了,看的是现有的技术栈上谁训得快
报告里有个特别典型的例子,把「每层都用MoE+共享专家」这种常见设计,跟MAI-Base-1的交错布局对比:

每层MoE+共享专家的EG_FLOPs是1.03,算力账上看是略好的,但EG_Time只有0.82,实际训练时间上明显更慢,因为它的架构还没优化。这样在做最终决策时,相当于解耦开来看效果和效率。
评估体系
实际在基座训练中,评估集会非常多,有的波动大有的波动小,经常会看到实验A在X集涨了,在Y集又降了,无法做统一判断。
微软把评估集分成了Code、STEM、Math、General、Multilingual五类,每个候选在5个任务类别上各有一个EG,然后根据目标分配权重,把它们压成一个综合分。
除了评测集的权重分配外,基座的指标选取也一直是一个难题,微软直接采用了NLL衡量模型表现,规避了传统选择题或QA存在的以下挑战:
评测的效率与成本更高:许多基准需要思维链推理、工具使用或其他生成行为。这种自回归生成既昂贵又耗时。当模型结构快速迭代时,往往没有针对这些评测所需的快速自回归推理做优化。同时有开放式或自然语言答案的评测往往还需要一个judge模型来打分,进一步增加成本。 有过多混淆因素:例如经典的MMLU,它的多选格式隐含地假设模型已经获得了「解读并回答多选题」的能力。而在预训练阶段评测时,这种能力通常要一定规模才会涌现。且这类评测本身的格式就会使评测有偏,偏向于训练数据中带有更多同格式数据的setting。 NLL评测更鲁棒:在每一个预测步,模型都以ground truth 前缀为条件。这种teacher-forcing设置限制了一个微小错误能够累积放大的程度。 构建复杂度:构建一个高质量的QA评测需要大量且精心协调的工作,在一个评测达到可接受标准之前,通常需要多轮的数据收集、难度校准、去重和质量控制,而每个阶段都必须与领域专家紧密协作完成,需要付出比较大的时间、算力和人力成本。
后训练RL怎么不崩
MAI-Thinking-1没有使用轻量SFT,而是直接从midtrain下线的checkpoint开始,全靠RL从零长出推理能力。分别训练STEM&竞赛代码、Agentic、helpfulness与safety的三个专家之后,将专家产生的轨迹通过SFT的方式合并进一个模型。再跑一小段RL,修复safety、过度拒答和风格,顺带防止推理能力在合并里被稀释,产出最终的MAI-Thinking-1。
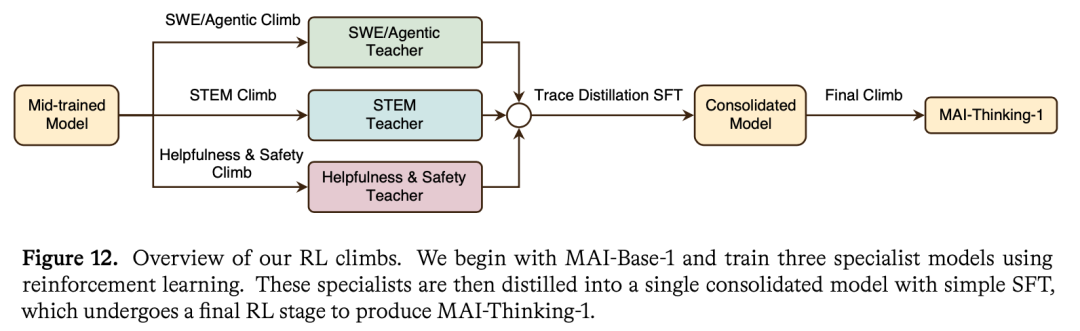
微软把训练比作“爬山”,其后训练策略设计的核心,就是提升长跑稳定性。让效果能持续爬升。
目标函数
对于RL,微软采用了GRPO算法,GRPO在更新策略时,每个token都会算一个比值r(新策略概率/采样时旧策略概率):r>1表示这步在抬高它的概率,r<1表示在压低。裁剪就是把r夹进[1−ε,1+ε],意思是「一步别把某个token的概率动太猛」,给训练留个安全步长(trust region)。微软在这个基础上动了两处提升长跑稳定性:
自适应entropy控制,把固定的裁剪上界改成动态的:正常GRPO中r的上界(1+ε)是写死、对称的。但这个上界还兼着管「策略能多大胆地提升好token的概率」,写太松entropy会爆炸(输出过随机、训练发散),写太紧entropy会坍缩(策略过早变死板、不再探索)。微软用一个积分控制器,每步按实测entropy调上界的松弛量k,把entropy钉在目标值:entropy低了就放宽上界、让策略更敢提升备选token,高了则收紧。 外层ratio裁剪,给所有分支再套一道硬上限:正常GRPO的裁剪是单向的,它只给策略钻advantage空子的方向踩刹车,而把自我纠正方向(压低坏token的概率)故意放开,这是PPO原本的设计意图。但微软发现,这个放开的方向偶尔会撞上某个r异常大的token(训练/推理两套系统对不齐时r会爆到几百几千),瞬间引发灾难性梯度尖刺,一下把训练带飞。因此微软在原裁剪之外再加一道对所有分支都生效的硬上限,r超过rmax=50就砍到50(下界不限)。极端mismatch的样本被摁住,正常范围的token保持原来的trust region行为,思路类似dual-clip PPO。实验证实尖刺明显减少、climb更稳。
奖励设计
奖励拆成三块:
除了任务本身的奖励外,还有:
语言一致性奖励:上下文一长,模型会在CoT里冒外语token,而这种混语CoT和train/inference的log概率发散强相关,于是按非英文词数扣分(top-p采样也能压住零星外语token)。 难度感知的长度惩罚:惩罚正比于 题目通过率×响应长度÷最大长度。难题(通过率低)惩罚轻,允许模型思考更多,简单题惩罚重,引导模型言简意赅。
采样策略
Query筛选:先采一小批算早期通过率,落在合理区间才补满128个rollout,否则直接丢,节省推理成本。补满后再过一道通过率筛子[0.1,0.8],把「几乎全对/全错」的题扔掉。 top-p masking防发散:top-p采样的坑在于,训练时若对这个概率和以外的token也照常反传梯度,等于在更新一些采样时根本不可能被选中的token,造成严重off-policy mismatch(训练用的策略和当初采样的策略对不上),几步就发散。微软的解法是把核外token的logit在softmax前置成−∞,让训练和采样看到的分布一致,发散显著减小。 逐渐加大长度:rollout上限从8k起步,前期模型弱就短着训,按2的幂一路加到128k,省下大量推理。
自蒸馏续训
由于RL训练中难免会崩,微软干脆直接把RL过程中产生的rollout收集起来,在一个mid-trained ckpt上做SFT,得到的新模型当作继续RL的起点,既保留前面RL学到的能力,又重置了数值状态。
为什么不直接回滚到崩之前的ckpt?因为不稳定性往往在真正崩盘的很多步之前就写进参数里了,回滚也带病根,自蒸馏反而更干净。
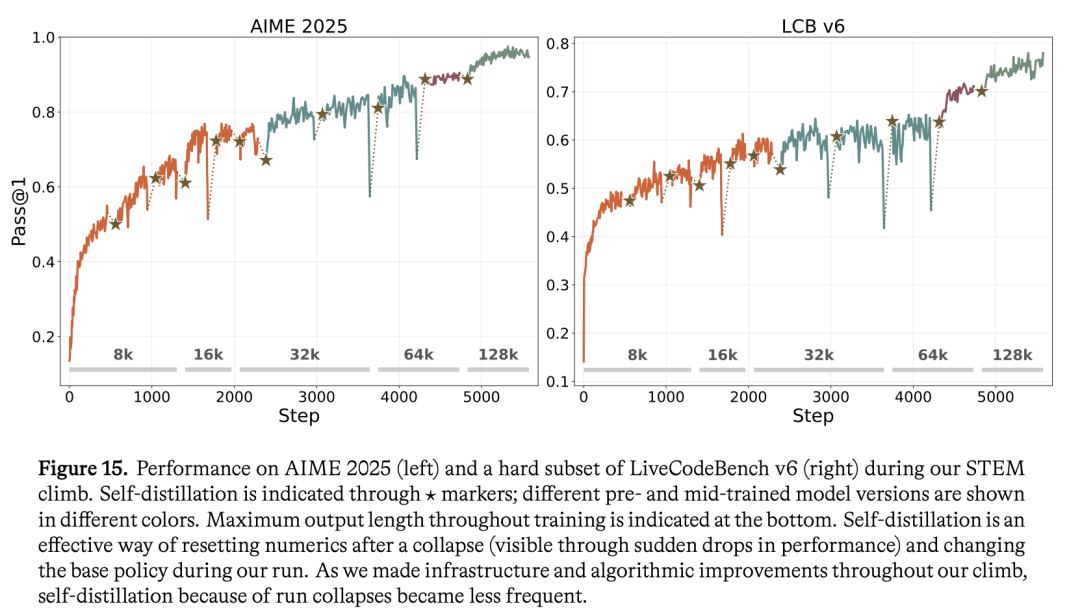
下图中*的点是重新自蒸馏拉起的点,可以看到每次模型训蹦后,这个策略基本可以把模型恢复到之前的水位继续提升:
同时微软分享了在整个RL过程中的best practices:
续训时O(1M)条轨迹SFT就够追平teacher,更多的话会边际递减,还会把策略output分布勒太窄、损害后续RL的探索。 带错误答案的轨迹和只用正确轨迹效果差不多;但他们正确轨迹本就远超1M条,最后只用正确的。 要用climb后期的轨迹:掺早期ckpt的会掉点,只用最终ckpt的又太单一;跨多个强ckpt采,多样性更好,RL恢复后探索更充分。 固定token预算下,prompt多样性比每题多采轨迹更有价值;而且随机采样打败了各种「挑短轨迹/启发式过滤」的花活。 自蒸馏会让模型忘掉长上下文能力,所以在length extension之前要把mid-training数据混回去。
两个超参细节也值得记:长rollout(通常是难题)天然更off-policy,所以长度一上去就调低学习率(1e-6→9e-7)换稳定;整个栈全异步,每5个梯度步更新一次推理模型,超过8次更新(40步)还没用上的rollout直接丢。
Agentic RL
在AgenticRL训练中,微软特地指出了SWE环境要注意的reward hacking现象:
上网搜答案:PR的golden solution在GitHub上搜得到,需要进行沙箱断网/域名白名单。 翻本地git历史:有些答案commit藏在库里,需要把base commit之后的所有commit/分支洗掉,造一个「时间倒流」版仓库。 篡改测试:monkey-patch测试框架让模型代码假装通过,需要评分前重置测试文件、推理时藏起测试改动、再上LLM监控。
另外,微软在实验中发现STEM和Agentic任务具有不对称性,也比较符合直觉:STEM任务掺进agentic RL,发现能稳定训练、且能力可以正向迁移到SWE/工具调用,但反过来agentic对STEM几乎零迁移。
总结
大模型训练至今已经演化成了非常复杂的系统工程,每一次几乎不可重来的预训练,却需要到最终结束才能知道最终效果。
从这次微软的技术报告中可以看到,他们完全由第一性原理出发进行设计:
预训练阶段围绕scaling law,降低爬梯子的复杂度、解耦控制变量,拿到置信的可scalable的结论,确保策略能真正在目标尺寸生效 后训练阶段,重点关注稳定性+奖励设计,只要这两者ok,模型就可以自己roll出各项能力,进行长程迭代,效果逐步提升
虽然微软的模型效果离前几家还有差距,但他们在本次报告中展示的极强的深度研究和系统工程能力,让我毫不怀疑他们今年能跻身第一梯队。
那个巨兽,真的回来了。
MAI-Thinking-1: https://microsoft.ai/news/introducing-mai-thinking-1/

「学到了」
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢