

过去两年,文生视频赛道把"像不像"卷到了近乎恐怖的水平——Sora、Veo、Kling、Wan2.2、HunyuanVideo……单帧截图发朋友圈,没人看得出是 AI 生成的。
但只要你把问题从 "像不像"换成 "对不对",裂缝就冒出来了:一个球没有接触任何物体,却突然加速;啤酒往杯子里倒,液面纹丝不动,泡沫却在凭空生长;刀"划过"木头,切口没有凹槽、木屑从不出现;自由落体可以无视重力加速度。
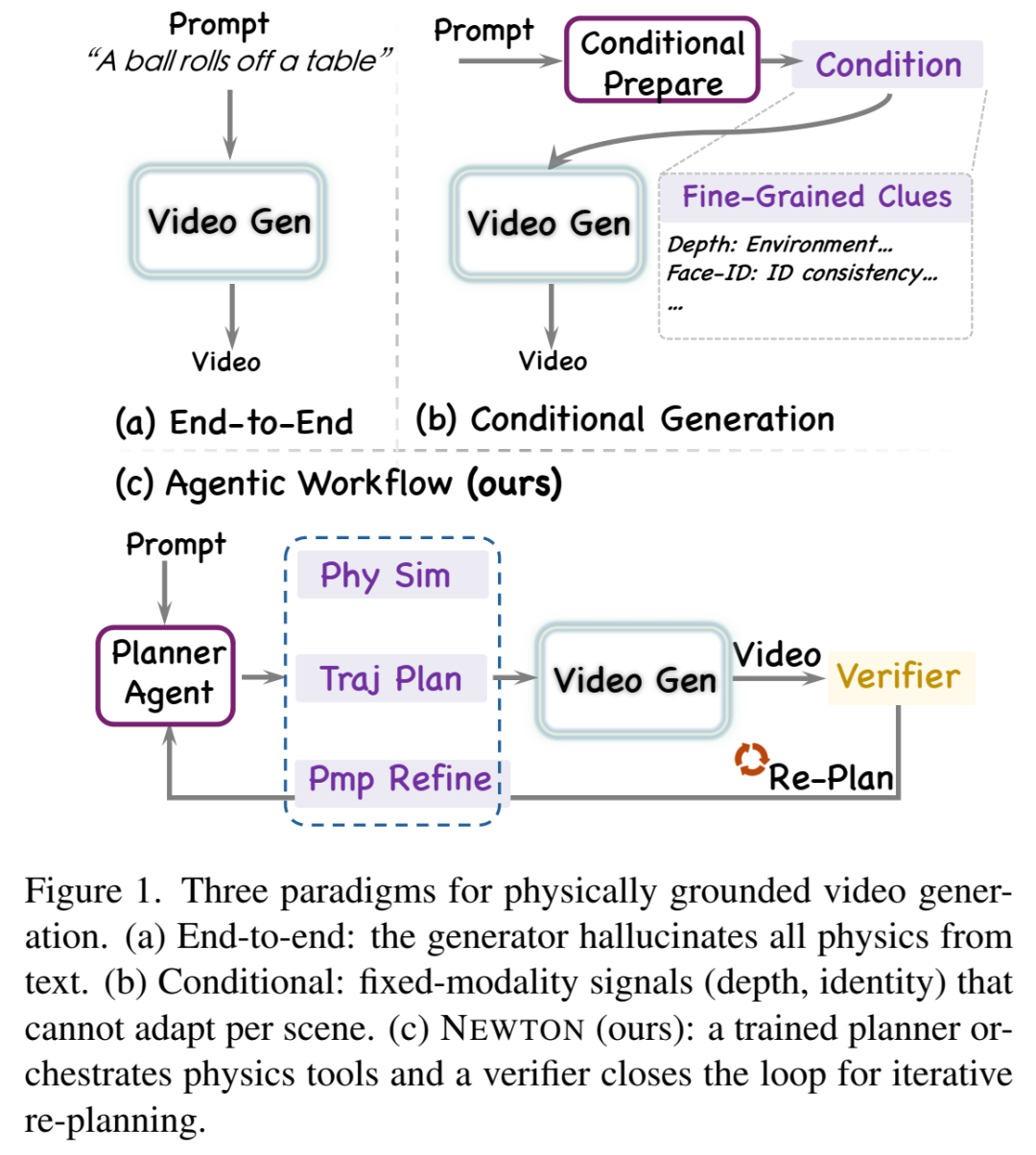
如果把这篇论文只看成“又一个更会生成视频的模型”,就会错过它真正厉害的地方。NEWTON 不是在比谁的生成器更大、训练数据更多,也不是简单把物理知识塞进视频扩散模型里;它做的是一件更具方法论意味的事:把“视频生成为什么会违反物理常识”这个老问题,重新定义成“物理世界该如何被规格化、被调用、被验证”的系统工程问题。
这意味着,论文的重点不在单次生成结果,而在生成前的规划、生成时的工具调用,以及生成后的验证反馈。作者明确指出,当前视频生成模型即便画面越来越像真,依然会系统性地犯物理错误;在 VideoPhy-2 上,最好的模型 joint accuracy 也只有 32.6% 左右。这个数字背后的含义并不是“模型笨”,而是“输入的信息不足以唯一确定动态过程”。换句话说,问题不是模型没学会,而是世界被压缩得太狠了。
这篇工作之所以值得 AI+交叉学科研究者认真看,是因为它给出了一个非常有启发的判断:当任务本身隐含着外部规律、精确参数、过程约束和闭环校验时,单纯依赖 end-to-end 生成往往不是最优路线;把生成问题拆成“规划—执行—验证”的 agentic workflow,反而更符合科学计算、工程控制和实验设计的基本逻辑。NEWTON 的价值就在于,它把这一逻辑第一次比较完整地搬到了视频生成里。

论文:NEWTON: Agentic Planning for Physically Grounded Video Generation
单位:浙大、香港理工、树根科技、三一集团
发布日期:2026.05
Code: https://newton026.github.io/newton/
请索引第103篇论文
 |  |
在 VideoPhy-2(目前最严格的物理常识评测基准)上,即便最强模型,Joint 准确率也只有 32.6%——意思是:同时做到语义贴合(SA≥4)且物理合理(PC≥4)的视频占比不到三分之一。
这不是 bug,这是架构层面的必然。
NEWTON 的价值就在于:它没有继续在"把模型做得更大"这条路上堆赌注,而是停下来问了一句——
"文本 Prompt 到底漏掉了什么,以至于再大的生成器也补不回来?"
答案他们称为 Specification Bottleneck(规格瓶颈)。这也是整篇论文最值得交叉学科研究者细嚼慢咽的核心论点。
01「规格瓶颈」——文本是对物理世界的有损压缩
1.1 一句话 Prompt ≠ 一个物理问题的完整描述
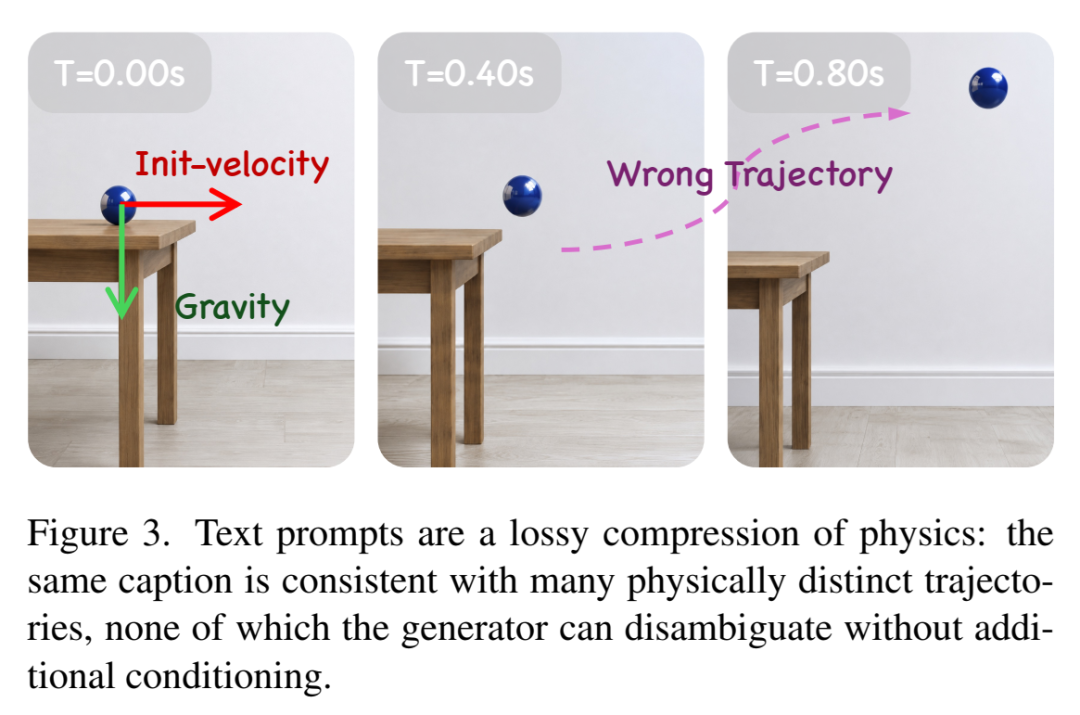
考虑这句看似无懈可击的 prompt:
"A ball rolls off the edge of a table."(一个球从桌沿滚落)
这句话省略了:
球的质量、半径、转动惯量
桌面摩擦系数
桌面高度
球的初始水平速度
地面材质(弹性恢复系数)
空气阻力近似……
以及所有这些量之间的耦合关系
而这些参数联立起来才能唯一确定一个轨迹。生成器拿到手的却只有一句自然语言,然后被要求"交出一段物理自洽的连续视频"。
于是它只能做一件事:在信息严重欠定的条件下,用统计先验做幻觉式补全。单帧好看,时间维度上一塌糊涂——因为这个优化问题本身就是 ill-posed 的。
1.2 关键论断
"No amount of model scaling can recover what was never specified."
——缩放永远补不回输入端从未给过的信息。
这意味着:把物理硬塞进生成器权重(端到端训练)、或者加更多 ControlNet 条件(固定模态信号)、或者做 test-time search(在错误空间里搜)——方向都对,但层级都错了。它们治的是症状,不是病因。
病因在规格层:你没有告诉它这个世界 是什么,就指望它渲染出 这个世界。
02 从规格瓶颈推导出三条铁律
NEWTON 从 "规格瓶颈" 出发,严谨地推导出物理条件化(physics conditioning)必须同时满足的 三个性质——然后证明:现存方法没有一个能三角同圆。
性质 | 含义 | 端到端训练 | ControlNet类 | One-shot增强 |
|---|---|---|---|---|
Sufficiency(充分性) | 覆盖足够物理维度以唯一确定动力学,不留关键参数悬空 | ❌ 隐式嵌入≠显式充分 | ⚠️ 固定模态,维度受限 | ❌ 仍靠一句prompt兜底 |
Dynamism(动态性) | 不同场景需要不同的物理规格——不能一刀切 | ❌ 全局权重,不可自适应 | ❌ 模态固定 | ❌ 单轮无场景分支 |
Verifiability(可验证性) | 能检查输出是否服从目标物理,并能修正 | ❌ 无feedback loop | ❌ 无feedback loop | ❌ 单射无回路 |
读完这个表,你应该能感觉到:论文的 contribution 不在"又搞了一个模块",而在先做了正确的诊断,再开处方。
03 NEWTON 架构:把视频生成器「降级」为 Agent 的工具
核心思想极其干脆——
视频生成不是系统的最终输出,而是一个 Agent 可调用的 Action。
整个系统由 三个角色 + 一个循环 组成:
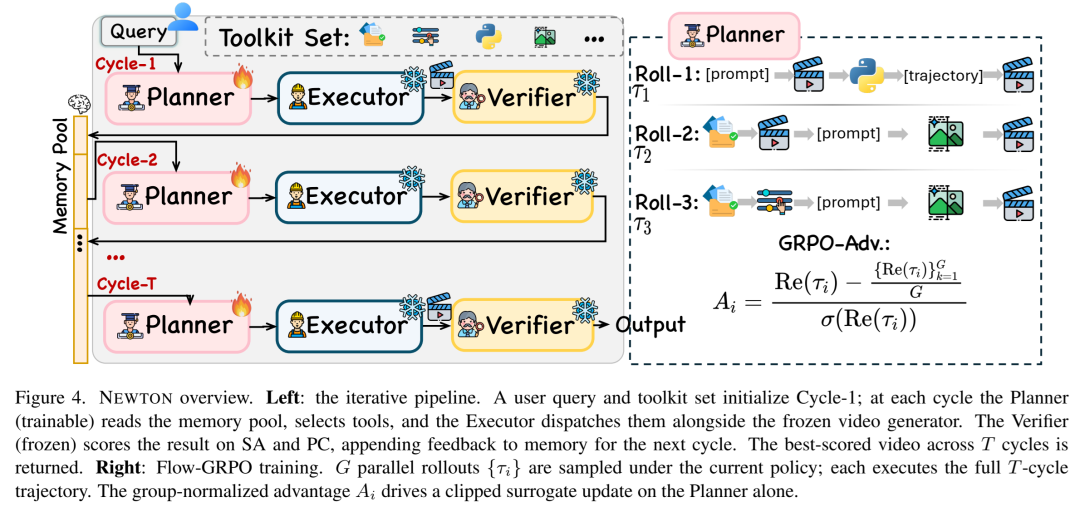
Fig.4:NEWTON 的三角色架构 —— Planner / Executor / Verifier 的迭代循环
3.1 Planner(规划器)
用一个 VLM(Qwen3.5-9B) 作为策略网络 π_θ:
在每一轮 cycle t,Planner 读入 Memory State M^t:
M^t = {原始prompt, 历史工具调用&输出, Verifier反馈得分, 前序推理轨迹}然后输出一个结构化 action:
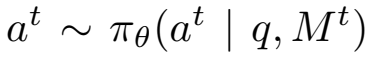
这个 action 可以是:
调 Keyframe Generation(生成物理锚定关键帧)
调 Python Computation(在沙盒里算轨迹/守恒量)
调 Prompt Refiner(把材料属性、因果链写进 prompt)
触发视频生成(用累积的 conditioning 去调冻结的生成器)
或 skip(本轮只推理,不产出)
关键点:生成器全程冻结,不碰权重,不插 adapter。整个系统的可学习部分只有一个 Planner。 这让"物理能力"从生成器内部被抽出来,变成了可组合的 Agent behavior。
3.2 Executor(执行器)
三种 Physics-Aware Tools 各攻一个维度的规格缺口:
工具 | 解决什么 | 怎么做 |
|---|---|---|
Keyframe Generation | 时间边界条件缺失 → 轨迹插值漂移 | 用 T2I 模型生成锚定帧(首/中/尾),如"球在抛物线顶点"的中间帧,强制 generator 插值经过合法状态 |
Python Computation | 定量参数缺失 → 轨迹/动量全靠猜 | 沙盒算 projectile motion、弹性碰撞、旋转动力学,数值结果回写入 memory 供后续 prompt/keyframe 利用 |
Prompt Refiner | 自然语言缺材质/阶段/因果描述 | 显式补写 "rubber ball, coefficient of restitution=0.7" 等,让 generator 的条件分布移到更合理的区域 |
3.3 Verifier(验证器)
VideoPhy-2-AutoEval 给每段生成视频打两个标量:
SA(Semantic Adherence,1-5):有没有做对 prompt 说的那件事
PC(Physical Commonsense,1-5):有没有遵守物理规律
得分追加回 Memory → 下一轮 Planner 据此 re-plan。
系统最多跑 T=5 cycles,最终返回所有 cycle 中 verifier score 最高的视频。
04 训练:Flow-GRPO「在流中」而非「离线抄答案」
这是论文第二个极具方法论味的地方。
4.1 为什么不能 SFT?
如果你用"专家轨迹"(比如 GPT-4o 生成的 high-reward rollout)去做 Supervised Fine-Tuning,Planner 学到的是模仿静态演示,它从未体验到"我调错工具了→视频炸了→我该怎么改"这种活的系统动力学。论文引用 AgentFlow 的发现:SFT on expert trajectories 在 agentic 设定下甚至能比 frozen baseline 还差 19%——因为 mismatch between training distribution 和 live execution 的分布。
4.2 Flow-GRPO:让 Planner 在活循环里吃自己的后果
公式不太长,但思想极干净:
对每个 prompt q,采样 G=8 条并行 rollout,每条 rollout 完整跑完 T=5 轮的
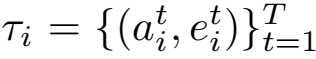
——Planner 必须在真实多轮环境中暴露它的全部决策 horizon。
每条 rollout 拿到一个 trajectory-level reward R(τᵢ)(不是逐帧 reward,而是稀疏的终态质量信号)。
Advantage 做 group normalization:
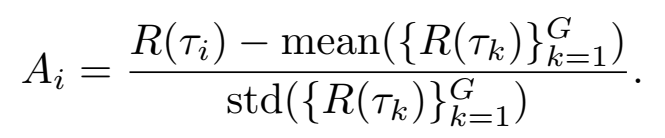
用 clipped surrogate + KL penalty 更新 π_θ——就是 GRPO/PPO 家族的标准做法,但它作用于 multi-turn agent trajectory 上。
Reward 设计 也很讲究(防止 reward hacking):
项 | 含义 |
|---|---|
R_quality(主项) | tiered function of max(SA, PC):不是 pass/fail,而是设中间梯度档,缓解 joint high score 稀疏的问题 |
R_kf(关键帧奖励) | 当 cycle 用了新 keyframe 且 SA 达标 → 固定 bonus,鼓励探索早期 keyframe 策略 |
R_compute(计算奖励) | 当 trajectory 包含有效物理计算(函数正确 + 参数合理)且 R_quality > 0 → 固定 bonus,防"为了奖励而瞎算" |
这套设计的妙处在于:Planner 学到的不是"哪个 token 更像专家",而是"在什么状态下该算、该画、该改 prompt、该生成——以及看到坏分之后怎么翻盘"。
05 实验结果:不改生成器,也能推物理一致性
5.1 主表 —— VideoPhy-2(590 captions,含 180 条 HARD)
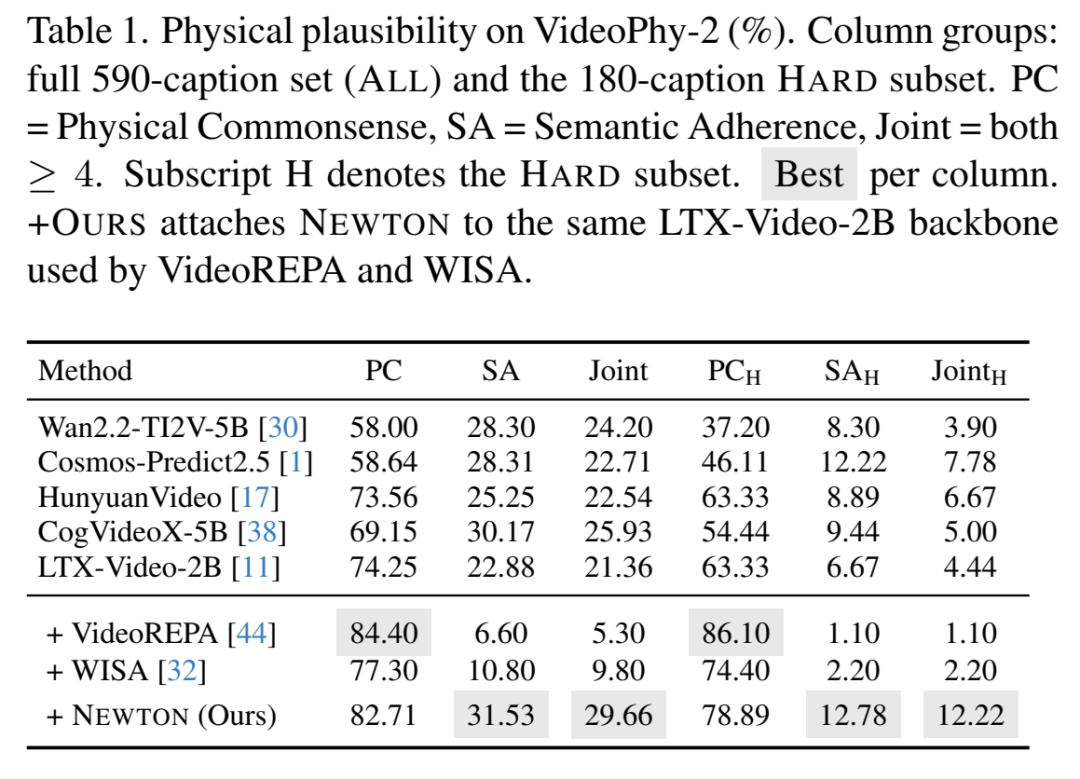
几个必须圈出来的点:
NEWTON 是唯一同时抬 PC 和 SA 的方法。对比之下 VideoREPA 把 PC 刷到 84% 但 SA 崩到 6.6%(Joint 反而掉到 5.3)——典型的"学了一堆物理符号但忘了做什么事"的过拟合现象。
HARD 子集 Joint 4.44% → 12.22%(2.75×)——最难的那批(守恒律、多体碰撞、铰接动力)恰恰是 Agent 工具调用最能发挥的场景。
提升来源不是改生成器权重,而是补齐 conditioning + verify-and-correct 循环。
5.2 跨基准泛化 —— PhyGenBench
同一个训练好的 Planner(只在 VideoPhy-2 train split 上训过),零重新训练迁到 PhyGenBench:
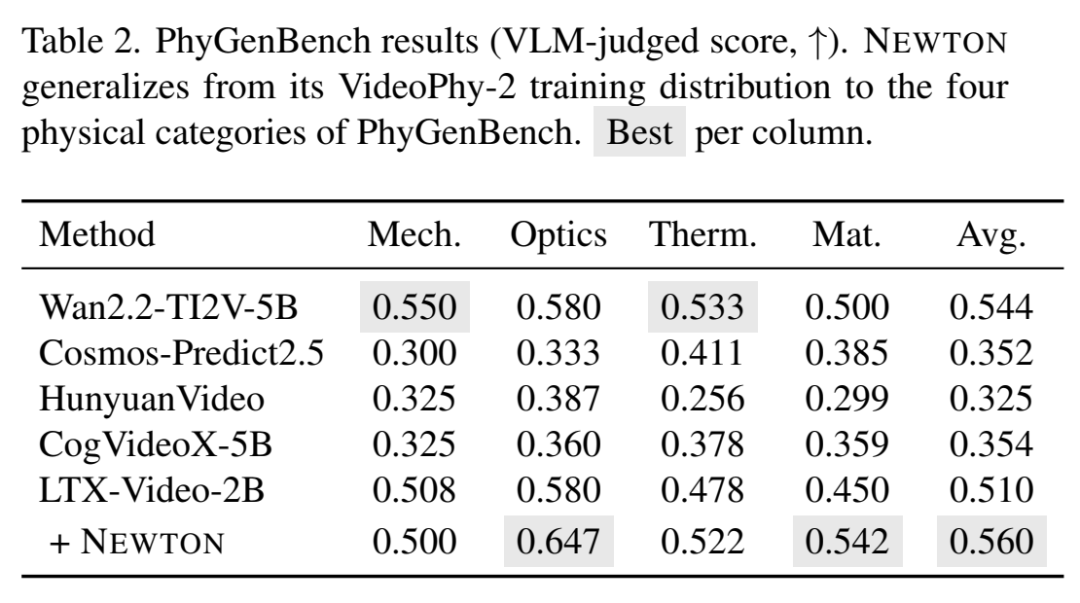
增益集中在 Optics(+0.067)和 Material(+0.092)——恰好是"需要写清楚折射/透明属性"和"需要描述颗粒堆积/形变"的维度,进一步佐证了 Planner 学到的 prompt refinement + keyframe 策略具有跨域迁移性。
5.3 消融:三个轴都站得住
Planner Scale(Qwen3.5 2B / 4B / 9B)——大模型在复杂工具调度上确实值:
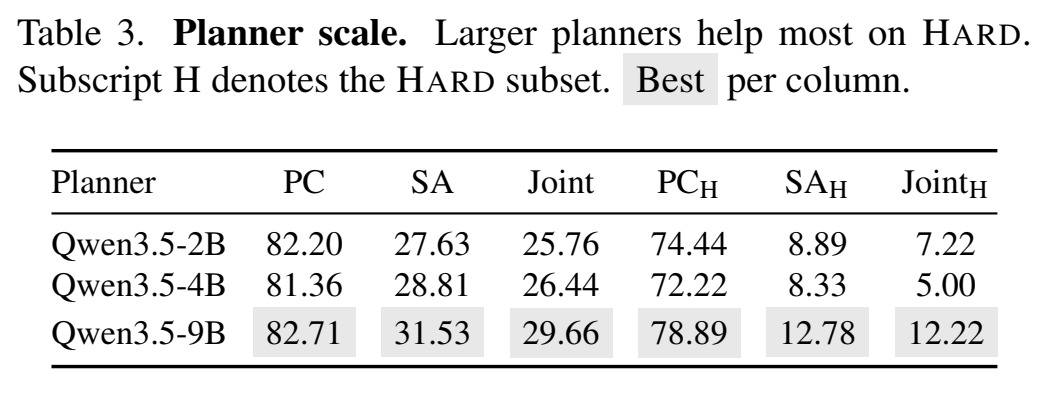
Cycle Budget T={2,3,5}——verify-and-correct 收益是复利型的:
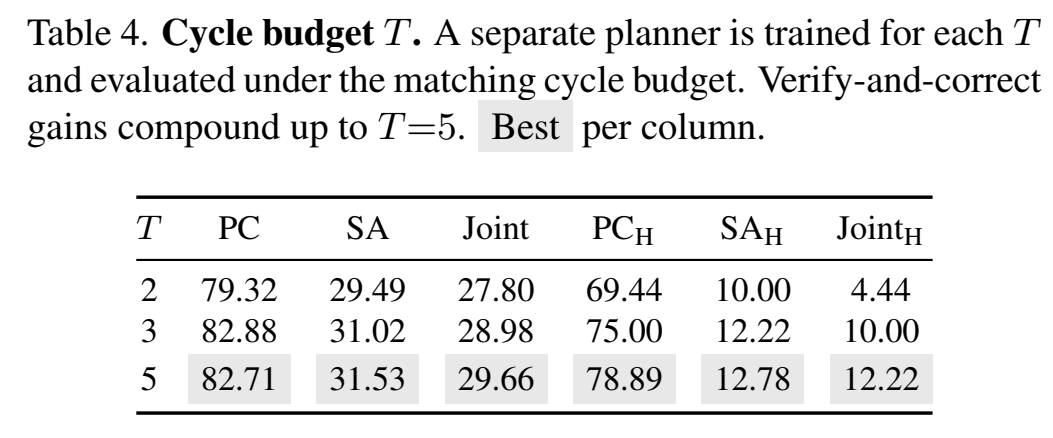
训练策略对比(同 9B):
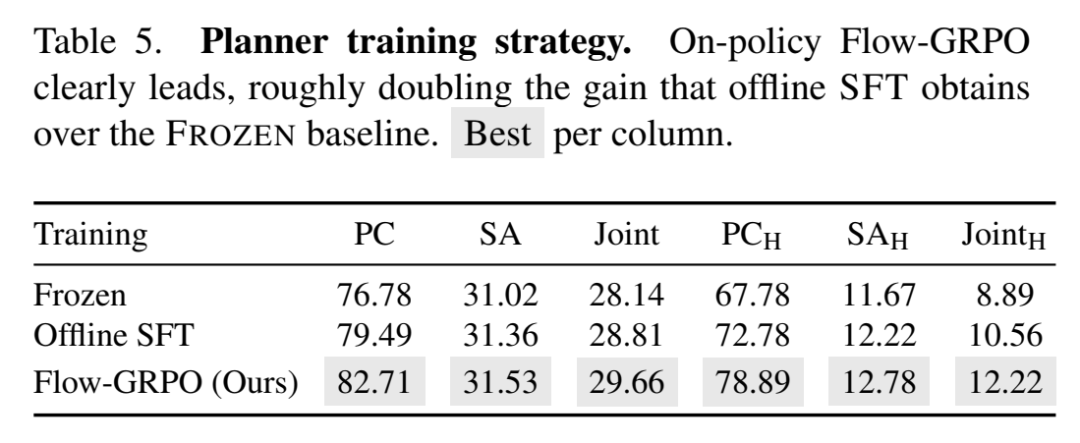
On-policy 训练 大致翻倍了 SFT 相对 frozen baseline 的增益——这其实是一条独立于视频生成的 Agent 方法论结论:在多轮工具调用场景里,"在活流中承担后果"比"抄专家答案"更有效。
5.4 换生成器也堆得上
用 100-caption 子集(受 Veo-3.1 API 成本约束):
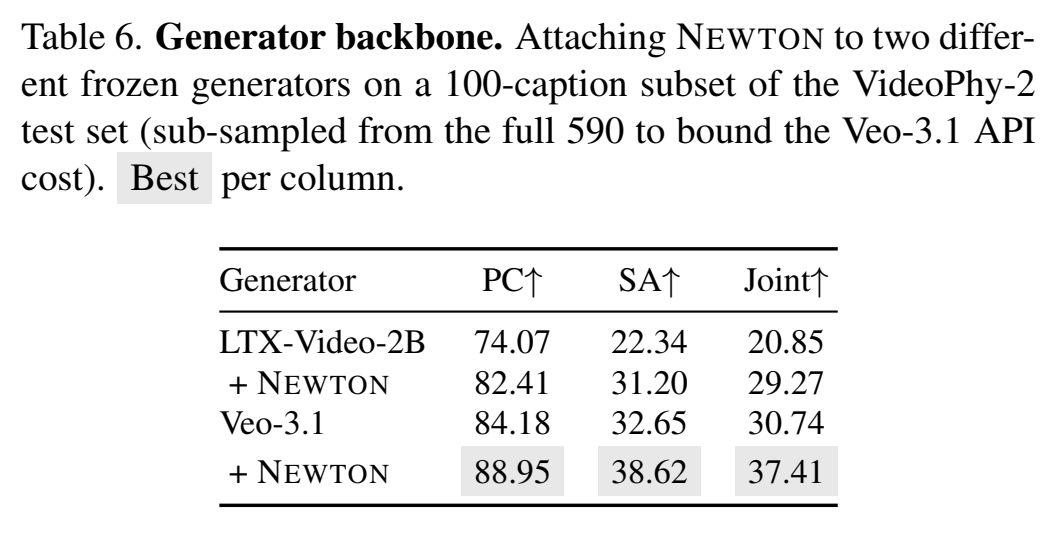
注意 Veo-3.1 本身远比 LTX 强,但 NEWTON 的增益仍然叠加而非被挤压——这说明它修复的不是 generator 的"渲染能力不足",而是"conditioning 规格不足",这个瓶颈在不同强度的底座上都存在。
06 视觉对比

论文中的定性对比非常直白:
倒盐:NEWTON 显示盐堆在盘子上逐渐隆起,LTX 产不出可见堆积,Hunyuan 中途断流,Wan2.2 撒盐但不累积.
削葡萄柚:NEWTON 渲染果皮逐段剥离露出果肉,基线要么起始就 pre-cut,要么只做一个 tiny slice 就停.
这类 failure case 的本质不是"生成器不够高清"——而是世界状态的变化没有被编码进条件信号里。NEWTON 用 keyframe + 物理计算把"状态转移"显式钉住,generator 只需要做它最擅长的:在合法边界之间插值。
07 写给 AI×交叉学科的读者:这篇论文真正的启发在哪?
7.1 「规格瓶颈」是一个通用框架,不限于视频
当你在做任何一个 AI→Real World 的生成/预测/决策任务时,都该问一句:
我的输入信号,是否信息-等价于这个世界问题的完整初值条件?
任务 | 对应的"规格瓶颈" |
|---|---|
分子动力学模拟生成 | SMILES/文本 ≠ 完整构象+溶剂+温度场 |
城市交通流预测→生成 | 路网拓扑文本 ≠ 完整边界流量+信号时序 |
生物序列→折叠轨迹 | 一级序列 ≠ 完整环境pH/伴侣蛋白/Mg²⁺浓度 |
机器人操作规划 | "pick up the cup" ≠ 摩擦/质心/抓取刚度/柔性变形 |
NEWTON 的解法——Agent 拆解缺口 → 调外部工具补齐规格 → verify-and-correct——在这些领域同样值得试。
7.2 Agentic AI 的下一个前沿不是"更聪明的 LLM",而是「可验证的工具编排」
最近半年 Agent 文献里充斥着"LLM + 工具调用 = Agent"的叙事。但 NEWTON 用一个干净的实验事实提醒我们:
一个 frozen 的 prompted LLM 调工具 ≠ 一个 trained Planner 在闭环里学调工具。
差距不在"能不能调",而在"知不知道调了之后怎么根据结果改下一次的调法"。Flow-GRPO 在这篇里扮演的角色,本质上是把强化学习中"environment feedback shapes policy"的逻辑,搬进了 tool-augmented generation 的场景。
对做 GNN/图学习的人尤其值得留意:如果将来你的 graph 代表的是物理场景的约束图(物体节点 + 接触边 + 力传递关系),那么 Planner 的决策空间就是一个 graph-conditioned policy,Verifier 的评分就是一个 graph-constraint violation penalty——这条路直通图科学与物理仿真的交叉地带。
7.3 「冻结 backbone + 外挂 Agent」可能是性价比最高的扩展路线
NEWTON 的实验里最务实的一条信息是:
你不需要重训一个 14B/30B 视频扩散模型来让它"懂物理"。你需要的是一个 9B Planner + 3 个轻量工具 + 一个打分器,围着一个冻结的生成器转。
训练成本、数据依赖、灾难性遗忘——这些痛点全绕开了。对任何已经有大型生成 backbone 的团队来说,这都是一条极其诱人的工程路径。
08 局限性与未来方向
工具库目前只有 3 类(keyframe / python / prompt)。扩展到流体求解器、articulated-body engine(MuJoCo/PhysX bindings)是自然下一步
Verifier 目前只给标量(SA, PC)。如果是 language-form 的诊断("违反了动量守恒在第12帧"),re-plan 可以更靶向
工具调用正确性目前靠 Planner 训练隐含保证,没有形式化验证层——安全攸关场景(机器人/工业仿真)需要额外 guardrail
速览卡片
核心诊断 | 文本 prompt 是物理世界的有损压缩 → specification bottleneck,scale 救不了 |
三根柱子 | Sufficiency · Dynamism · Verifiability(三者缺一,物理 conditioning 就塌) |
架构一句话 | Planner(唯一可训/9B-VLM)→ Executor(3 physics tools + 冻结视频生成器)→ Verifier(SA/PC评分)→ 循环最多5轮 |
训练 | Flow-GRPO,on-policy 在 live multi-turn rollout 里,tiered reward + anti-hacking bonuses |
VideoPhy-2 Joint | LTX: 21.4%→29.7% / HARD: 4.44%→12.22%;Veo-3.1: 30.7%→37.4%(不改生成器权重) |
交叉学科启示 | "规格瓶颈"通用;Agent≠prompt调工具,闭环奖惩才造出真正可调的policy;freeze-backbone外挂路线的高ROI |
Takeaway:与其赌下一代模型自发"涌现"出牛顿力学的理解,不如坦承——自然语言从来不是 ODE 的等价描述。把物理推理从 generator 的权重里请出来,放进一个能看到自己错误、会调计算器、会重画关键帧的 Agent 手里,才是让生成模型走向可信世界模拟器的务实路径。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢