
北京时间 2026 年 6 月 12 日,中国科学院上海药物研究所郑明月研究员、张素林研究员和王明亮研究员团队与合作者在 Nature Chemical Biology 在线发表题为“Atomic-level protein-ligand recognition with PBCNet2.0 for probe discovery”的研究论文。该研究报道了用于蛋白质-配体相对结合亲和力预测的深度学习模型 PBCNet2.0。该模型以蛋白质-配体复合物三维结构为输入,可用于系列化合物相对活性排序、分子探针发现、先导化合物优化以及结合口袋突变影响分析,为基于结构的药物设计提供了新的智能计算工具。

1.背景
新靶标创新药物研发高度依赖高质量分子探针和可持续优化的先导化合物。在药物化学研究中,研究人员通常需要在有限时间内比较大量结构相近的候选分子,判断哪些取代基、构象或相互作用更可能提升活性、选择性和后续成药性质。由于化学空间具有组合爆炸特征,即使只围绕单一先导骨架的少数位点开展取代基变换,也可能产生成百上千个候选分子;若逐一合成并完成体外活性测试,将消耗大量时间、人力和实验资源。因此,引入可靠的计算辅助设计工具,为“设计-合成-测试-分析”(Design-Make-Test-Analyze, DMTA)循环提供排序和决策依据,是加速先导化合物优化和分子探针发现的重要方向。
以自由能微扰(free energy perturbation, FEP)为代表的物理模拟方法在相对结合亲和力预测方面具有较高精度,其中商业化软件 Schrödinger FEP+ 常被视为高精度相对亲和力预测的重要参考方法,在理想同系物体系中可接近实验精度。然而,其规模化应用仍受到以下因素限制:
计算成本高、通量有限。即使在高性能计算资源支持下,FEP 通常也只能处理有限数量的配体扰动,难以满足大规模候选分子快速排序的需求。 技术门槛较高。该类方法对力场参数、体系准备(如质子化状态、水分子分布)和采样策略较为敏感,需要较多专家经验参与。 结构适用范围受限。FEP 更适用于结合模式相近的同系物比较,对涉及较大骨架变化或结合模式改变的优化场景适用性有限。
与此同时,传统打分函数(如 Glide Score)、MM-GB/SA 以及部分深度学习方法在泛化能力、排序稳定性和可解释性方面仍有改进空间。总体而言,现有方法在面对药物化学中广阔的结构探索空间时,仍需要在预测精度、计算效率和结构适用范围之间取得更好的平衡。围绕这一问题,研究团队在前期 PBCNet(Nat. Comput. Sci. 2023, 3, 860-872)工作的基础上开发了 PBCNet2.0。
2.结果与讨论
PBCNet2.0 框架简介
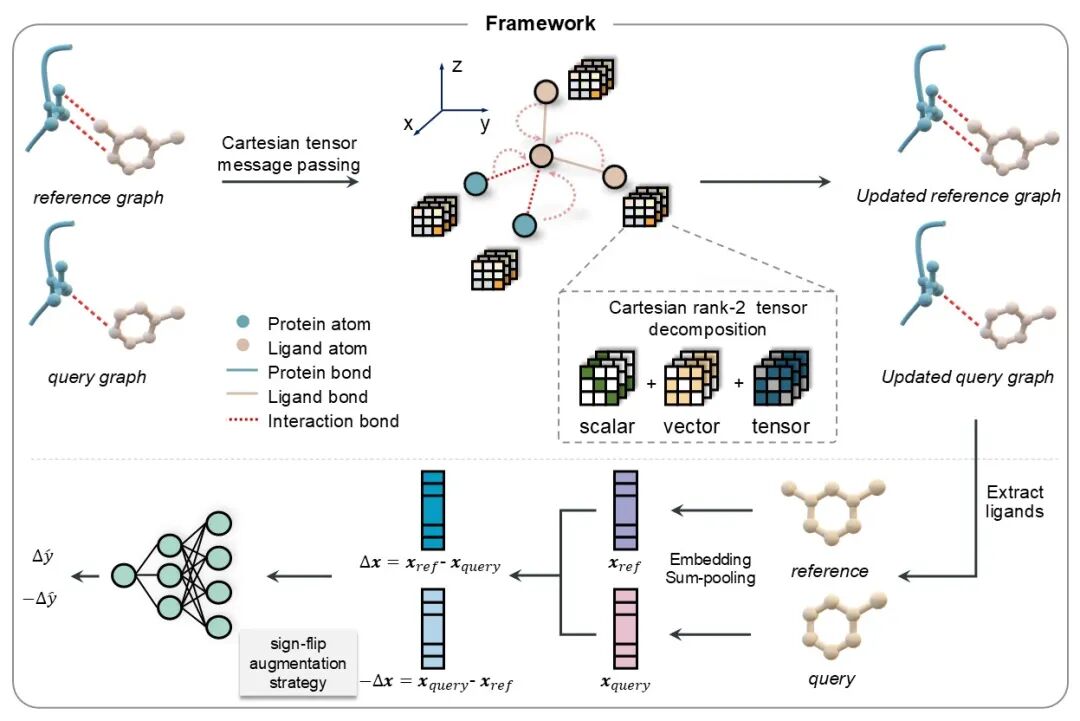
PBCNet2.0 的模型结构如图1所示。其主体框架延续了 PBCNet 的成对输入设计与三阶段范式,包括消息传递阶段(Message Passing Phase)、读出阶段(Readout Phase)和预测阶段(Prediction Phase)。PBCNet2.0 的输入为一对蛋白质-配体复合物;在训练集中,同一复合物对中的两个配体通常为结构类似物,并结合于同一蛋白质口袋。为降低计算开销,模型未采用全蛋白结构,而是提取距离配体分子 8 Å 范围内的氨基酸残基作为蛋白质口袋的局部结构表示。
消息传递阶段用于实现配体分子与蛋白质口袋之间的信息交互,并获得配体原子的节点级(node-level)表征。PBCNet2.0 在这一阶段的核心改进,是引入基于笛卡尔张量的等变神经网络,从而更系统地捕捉蛋白质-配体相互作用及分子构象中的距离、方向和角度等几何信息。具体而言,每个节点的隐空间表征被编码为笛卡尔二阶张量,以 3 × 3 矩阵形式表示;该矩阵可分解为标量(scalar)、矢量(vector)和张量(tensor)三类特征,分别对应 1、3 和 5 个自由度。在信息传递过程中,这些特征通过张量运算实现等变更新。消息传递完成后,模型移除口袋原子的表示,仅保留配体原子的表示用于后续读出和预测。
读出阶段的目标是生成图级(graph-level)和成对(pair-level)表征。图级表征通过对参照配体和待测配体的原子节点不变表征取平均值得到,分别记为z(ref) 和 z(query)。成对表征定义为二者之差 z(ref,query) = z(ref) - z(query),这一设计不同于前代 PBCNet 中拼接 z(ref)、z(query) 和 z(ref,query) 的策略。
预测阶段中,成对表征 z(ref,query) 经过三层前馈神经网络处理,用于估计两种配体之间的相对结合亲和力 y(ref,query)。同时,为使模型输出满足反对称性约束,即 𝑓 (𝑧(ref,query)) = −𝑓(−𝑧(ref,query)),研究团队在训练过程中同时引入 -z(ref,query) = z(query) - z(ref),并据此计算组合损失。
PBCNet2.0 在相对结合亲和力预测任务中的性能评估
为系统评估 PBCNet2.0 在相对结合亲和力预测中的表现,研究团队设计了零样本、少样本与主动学习三个层层递进的实验,分别对应先导化合物优化的早期阶段、中期积累少量 SAR 数据后的阶段,以及更接近真实项目决策的候选分子优先级排序场景。研究采用皮尔逊相关系数(R)和斯皮尔曼秩相关系数(ρ)评价模型的预测和排序能力。
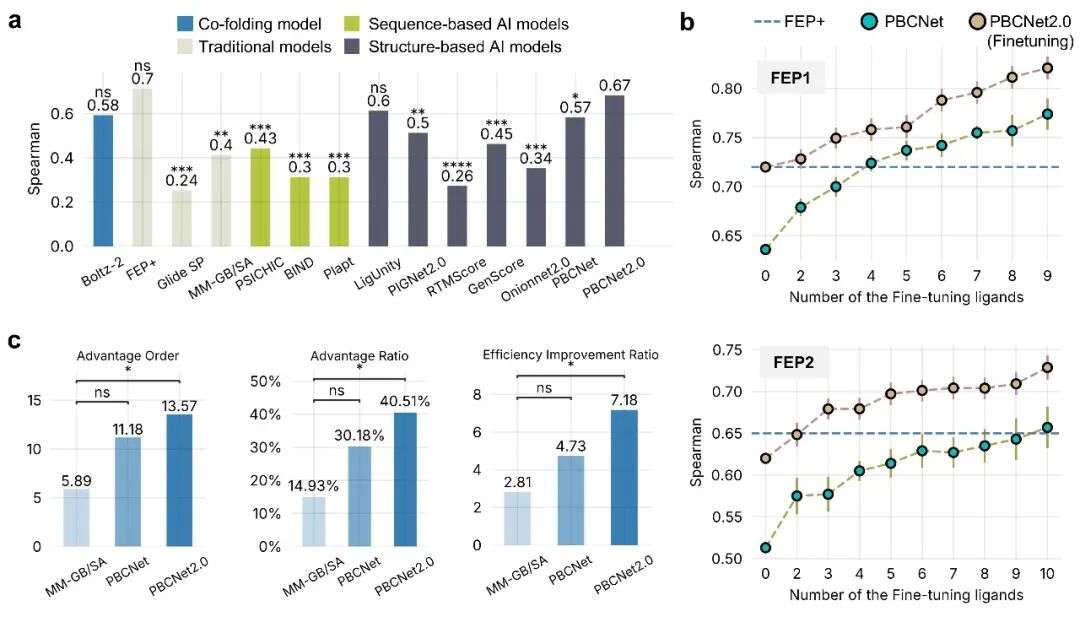
零样本预测直接将模型应用于未参与训练的 FEP 基准数据集。PBCNet2.0 取得 ρ = 0.67、R = 0.66 的排序性能,较前代 PBCNet 提升约 18%,并与 Schrödinger FEP+(ρ = 0.70)在该基准上的表现接近,统计检验显示二者无显著差异(图2a)。这说明,在仅需单一结合构象输入、无需长时间采样的条件下,PBCNet2.0 已能在关键排序指标上接近高计算成本的自由能微扰模拟结果。
少样本学习模拟项目中已积累少量活性数据后的应用场景。利用 2-10 个已知分子对 PBCNet2.0 进行靶点特异性微调后,模型排序能力随数据增加而提升,并在该评估设置下超过 Schrödinger FEP+ 的参考表现,显示出较好的数据利用效率和项目定制化潜力(图2b)。
主动学习挑选实验进一步贴近真实优化流程:模型从候选池中迭代挑选预测活性较高的分子。在 8 个重要靶点的回顾性测试中,PBCNet2.0 平均比实际合成顺序提前 13.57 个位次找到最优分子;按论文定义的资源节约指标,其优势比为 40.51%,对应的优化效率提升为 7.18 倍,优于 MM-GB/SA 和前代 PBCNet(图2c)。这些结果提示,PBCNet2.0 有望在候选分子优先级排序中减少不必要的合成与测试工作。
三项实验覆盖了先导化合物优化中不同阶段的典型需求,表明 PBCNet2.0 在预测精度、数据效率和候选分子优先级排序方面均较前代模型有所提升,可为药物研发中的结构优化决策提供计算支持。
蛋白质-配体相互作用是 PBCNet2.0 的重要预测依据
为分析 PBCNet2.0 的预测是否主要来源于蛋白质-配体相互作用信息,而不是简单记忆配体结构特征(即“配体记忆偏差”),研究团队设计了两组互补实验,对模型决策依据进行评估。
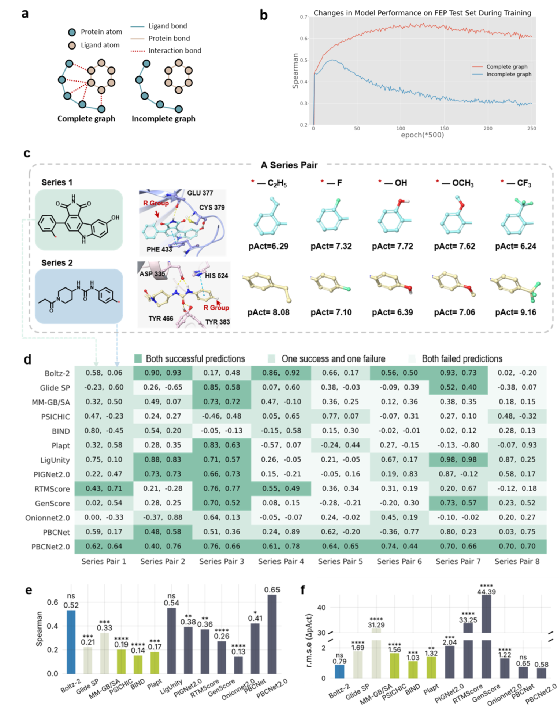
首先,研究团队通过训练动态分析,对比模型在“完整图”与“移除蛋白-配体相互作用边的不完整图”上的表现(图3a)。训练初期,两条性能曲线较为接近,提示模型可能主要依赖较易学习的配体自身结构特征;约 12,500 步后,两条曲线开始分化:完整图模型性能持续提升,而不完整图模型性能下降(图3b)。这一现象表明,随着训练推进,蛋白质-配体相互作用信息逐渐成为 PBCNet2.0 预测的重要驱动因素。
为进一步验证这一点,研究团队构建了具有挑战性的 SAR-Diff 测试集。该测试集成对呈现“相同修饰基团、不同结合环境”的化合物系列,使相同化学改造在不同口袋环境中产生不同构效关系(图3c)。若模型仅凭配体结构记忆,将难以区分这类差异。结果显示,PBCNet2.0 是唯一在全部 8 对化学系列中均表现出排序能力的模型(斯皮尔曼相关系数均超过 0.4,图3d-e)。相比之下,多数基线模型,特别是部分基于序列的 AI 模型,在该测试集中性能下降,提示配体记忆偏差在相关任务中可能较为普遍(比较图2a与3d)。
上述两组实验从不同角度支持了同一结论:PBCNet2.0 的预测并非单纯依赖配体结构记忆,而是在较大程度上利用了蛋白质-配体原子级相互作用模式。这一特点有助于提高模型在真实药物化学场景中的可信度和可解释性。
PBCNet2.0 能够识别受严格几何约束的微弱分子间相互作用
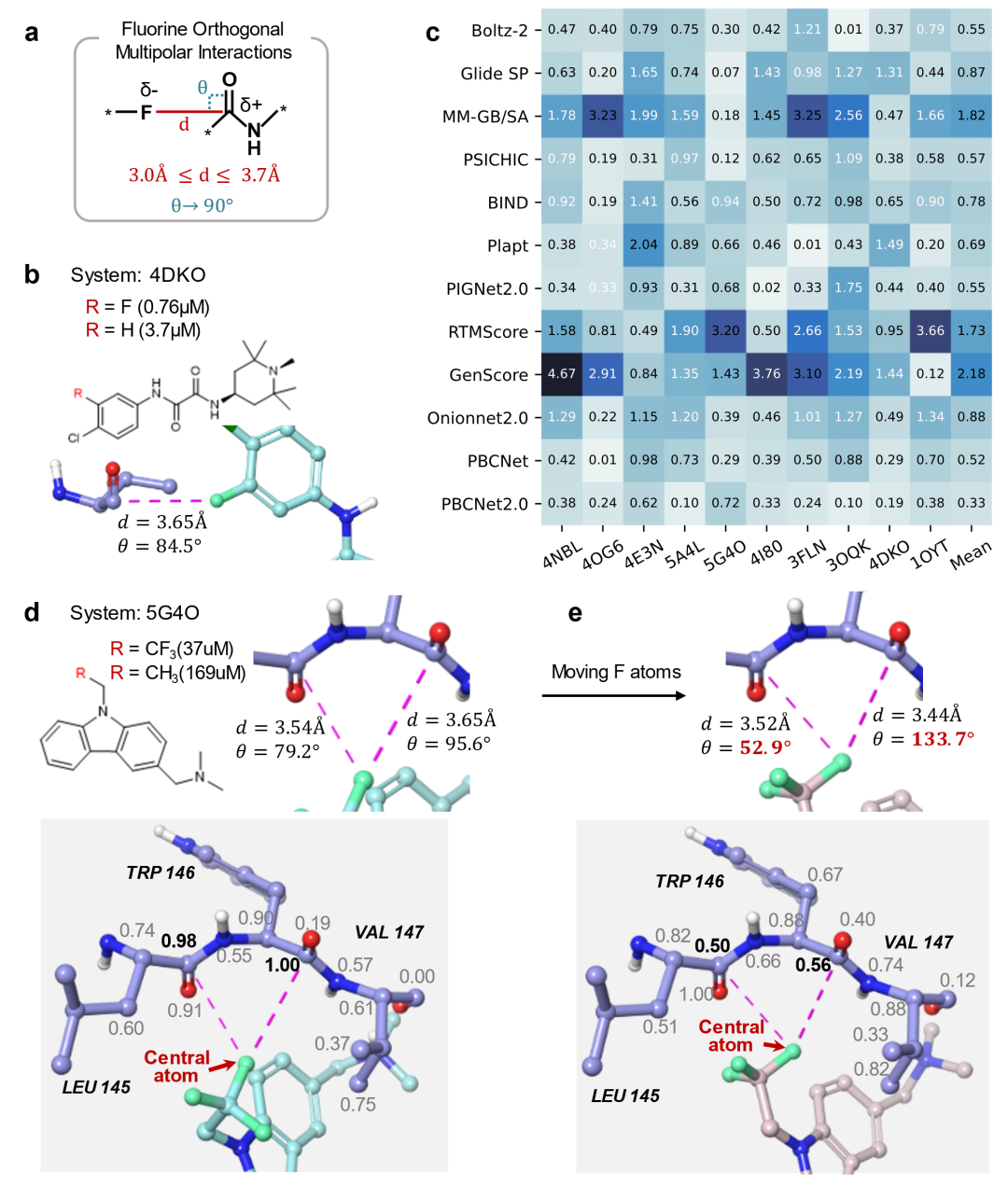
为进一步解释 PBCNet2.0 的预测能力,研究团队开展了可解释性分析,并聚焦于一类常被忽视但在蛋白质-配体识别中具有意义的相互作用:氟正交多极相互作用(图4a)。氟原子的高电负性使其形成亲核中心,而羰基碳因受羰基氧吸电子效应而呈亲电性,二者之间可形成具有方向性的正交多极相互作用。这类相互作用对几何条件较为敏感,通常要求氟-碳距离小于 3.8 Å,且 F···C=O 夹角接近 90°,因此可作为检验模型空间几何建模能力的案例。
研究团队据此构建了 F-Opt 基准测试集,包含 10 对因氟取代而增强结合活性的化合物对(图4b)。结果显示(图4c),PBCNet2.0 的平均绝对误差为 0.33,在所比较方法中最低;前代 PBCNet 次之(0.52)。更重要的是,只有 PBCNet2.0 和 PBCNet 实现了 100% 的预测方向(正负号)一致性,而其他方法的方向错误率为 20%-50%。
为理解模型如何识别这种相互作用,研究团队对代表性体系 PDB ID: 5G4O 进行了可解释性分析(图4d):参与相互作用的碳原子在模型中被赋予 0.98-1.00 的高权重。研究团队进一步通过人为移动氟原子破坏关键角度(一个角度从 79.2° 变为 52.9°,另一个从 95.6° 变为 133.7°,均偏离合理作用范围)来扰动该相互作用。结果显示,相关碳原子的权重分别下降至 0.50 和 0.56,说明 PBCNet2.0 的判断依赖于该相互作用所需的角度约束,而不仅是简单识别元素或距离特征(图4e)。
PBCNet2.0 对蛋白突变效应表现出“涌现能力”
蛋白结合口袋中的氨基酸突变可显著影响药物结合活性(图5a),也是临床耐药的重要原因之一,例如非小细胞肺癌中 EGFR 的 T790M 突变。尽管 PBCNet2.0 的训练数据并不包含突变相关样本(仅包含同一蛋白位点上不同配体的结合数据),研究团队仍进一步评估模型能否泛化到突变效应预测这一相关任务。
为此,研究团队构建了包含 8 个药物相关靶点、涵盖临床观察到的结合口袋突变的“突变基准测试集”。结果显示(图5b),PBCNet2.0 取得平均 ρ = 0.53 的排序性能,表现相对稳健;而 Boltz-2、Glide SP、BIND、PLAPT、RTMScore 和 GenScore 等方法在该测试中表现较弱,部分方法甚至出现负相关。其中,Boltz-2 的失败可能与共折叠方法难以准确刻画突变引起的局部结构变化有关,进而影响其活性预测模块。
研究团队选取乳酸杆菌胸苷酸合成酶(LTS)作为案例进行可解释性分析(图5c-d):N229C 突变破坏了 ASN229 酰胺氧与配体吡啶氮之间的关键氢键,导致结合活性下降(实验值 ΔpKd = -0.62);PBCNet2.0 对该变化的预测值为 -0.79,与实验趋势一致。可解释性分析显示,野生型中该氧原子被赋予高权重(0.99),而突变后该信号消失,直观支持了模型预测的分子机制解释。
研究团队还回顾性分析了三个已上市或处于临床试验阶段的突变选择性抑制剂案例:靶向 IDH1 突变体的 Olutasidenib(2022 年获 FDA 批准用于急性髓系白血病)、靶向 KRAS G12D 突变的 MRTX1133,以及非共价 BTK 抑制剂 Pirtobrutinib。在这三个结构不同的体系中,PBCNet2.0 均能预测突变前后的相对结合活性变化(图5e)。这一结果提示,模型在大规模蛋白质-配体数据训练中学习到的相互作用模式,可在一定程度上迁移到口袋突变导致的结合差异分析中。
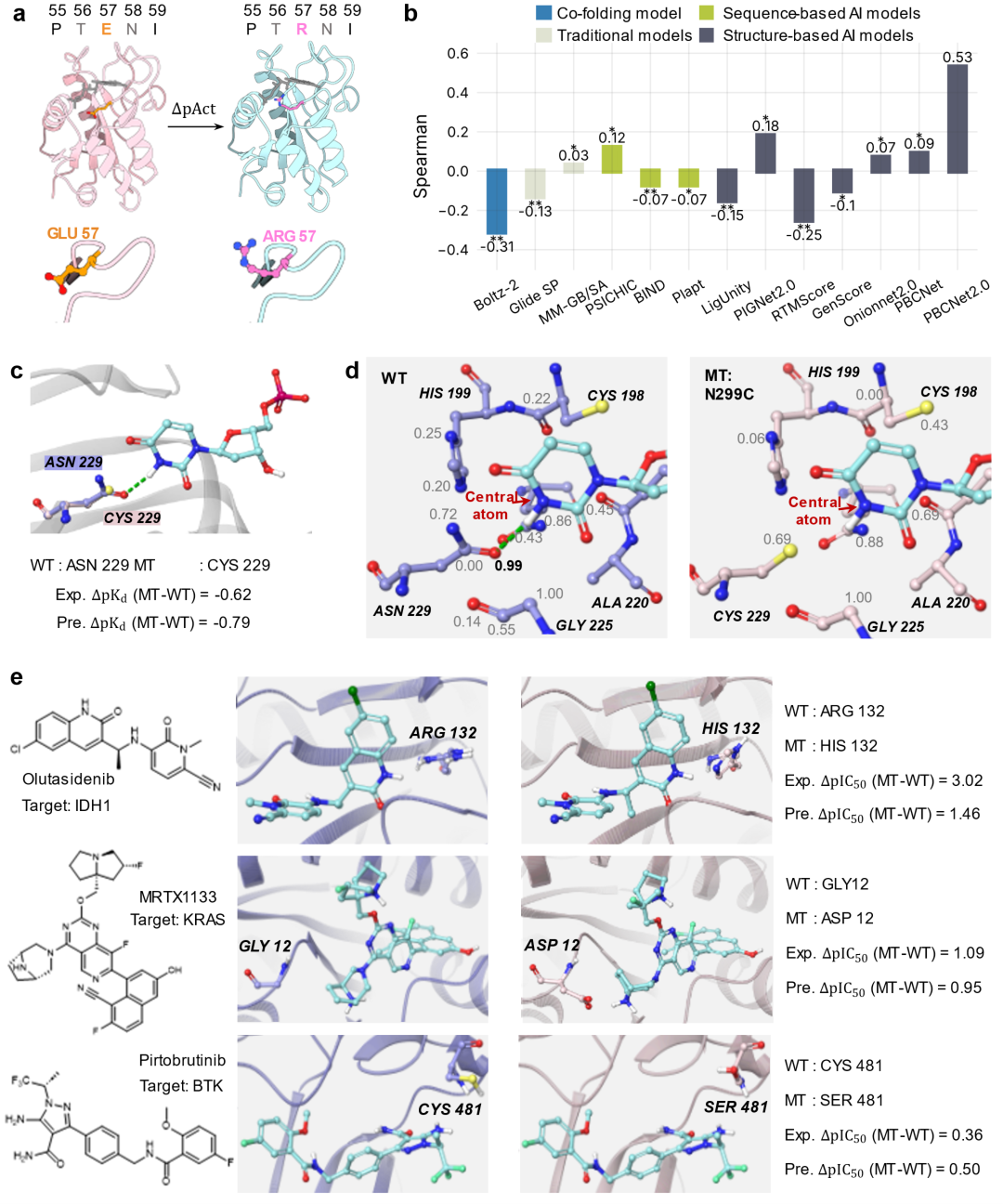
实验验证:从计算预测到湿实验确证
基于上述回顾性分析,研究团队进一步开展实验验证,以检验 PBCNet2.0 对微弱相互作用、立体选择性和关键结合残基的预测能力。
在 ENPP1 抑制剂体系中(图6a),团队此前已鉴定出活性化合物 A1。可解释性分析提示,A1 的氟原子与靶蛋白羰基氧之间可能形成氟正交多极相互作用(权重 0.94,图6b)。为验证这一点,团队将该氟原子替换为氢,得到类似物 A2。PBCNet2.0 预测该替换将导致活性下降约 40 倍(ΔpAct = 1.61)。后续实验支持了这一预测(图6c-f):A1 的酶抑制活性(IC50 = 13.3 nM)明显强于 A2(IC50 = 2284 nM);蛋白热迁移实验中 A1 对 ENPP1 的热稳定作用(ΔTm = 3.8 °C)也强于 A2(ΔTm = 2.7 °C);SPR 测得实测 ΔpKD 为 1.46,与预测值 1.61 接近。上述结果支持 A1 与 ENPP1 之间存在氟正交多极相互作用,并定量验证了该相互作用对结合亲和力的贡献,表明 PBCNet2.0 可用于支持基于精细非共价相互作用假设的先导优化设计。
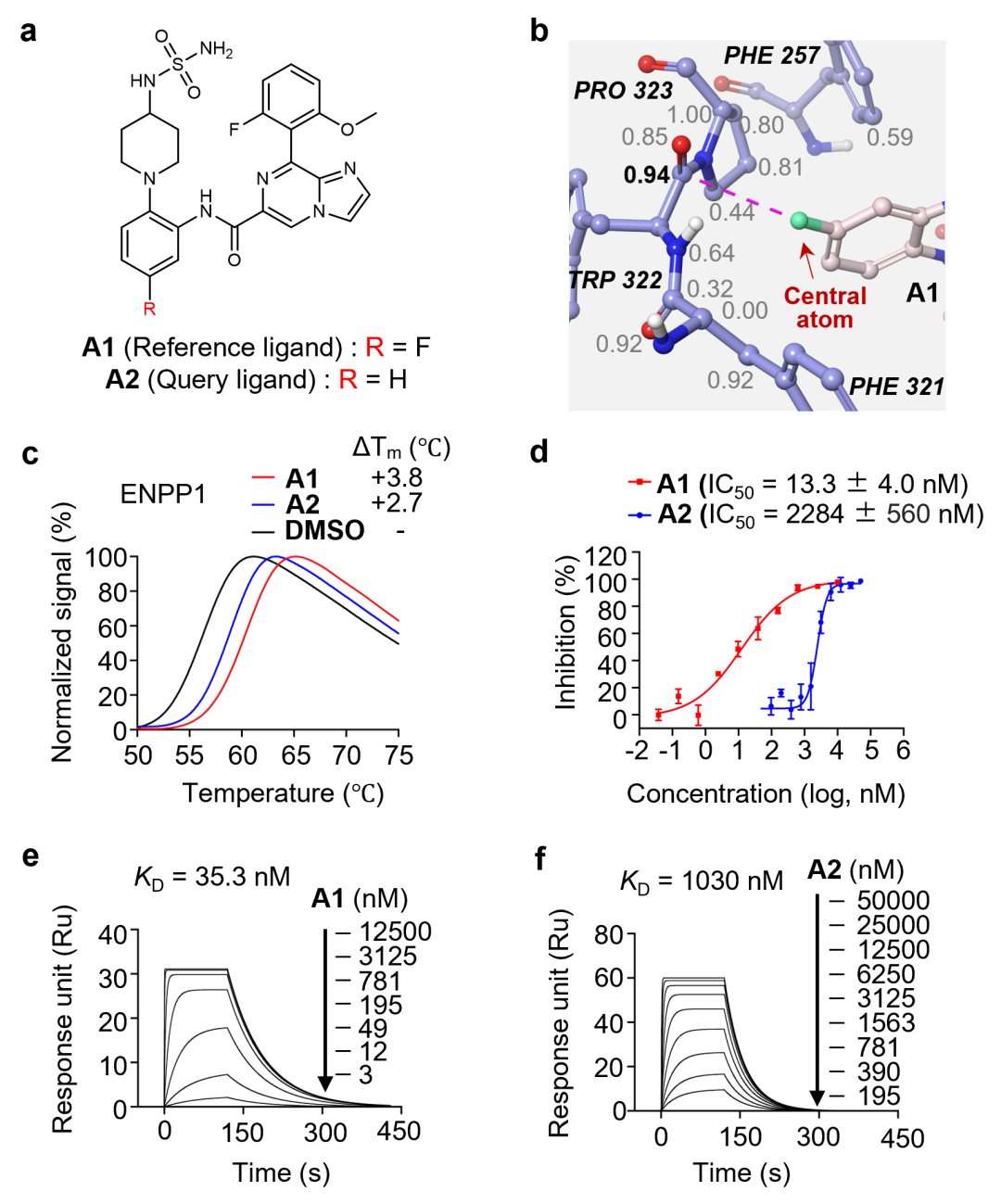
在 ALDH1B1 抑制剂体系中(图7a-c),研究团队围绕两个问题开展验证。其一是立体选择性:对于一对对映异构体 B1 和 B2,分子对接显示 B1 可与 PHE296 形成有利的 π-π 堆积,而 B2 不能(图7b,c);模型据此预测 B1 活性约为 B2 的 10 倍。实验结果显示,B1(IC50 = 20 nM)明显强于 B2(IC50 = 5574 nM),SPR 结果也与该趋势一致,表明模型能够捕捉立体化学差异带来的活性变化(图7d-g)。其二是耐药突变预测:团队通过计算机模拟丙氨酸扫描逐一评估口袋残基突变对 B1 结合的影响,并选取 6 个残基进行定点突变实验验证(图7h)。结果显示,其中 5 个残基突变显著削弱 B1 结合(命中率 5/6),优于传统 MM-GB/SA 方法在该实验设置下的表现。
3.结论
本研究围绕相对结合亲和力预测这一先导化合物优化中的核心任务,提出了基于笛卡尔张量等变图神经网络的 PBCNet2.0 模型。在前期 PBCNet 工作基础上,研究团队从模型架构与训练数据两个层面进行了改进。架构上,PBCNet2.0 引入基于笛卡尔张量的等变消息传递机制,将原子节点表示拆解为标量、矢量与张量三类不可约分量,使模型在满足三维空间旋转和平移对称性的同时,能够从原子坐标中学习距离、方向和角度等几何约束。数据层面,研究团队构建了包含约 860 万对蛋白质-配体相对活性的大规模数据集,覆盖约 28 万个小分子和 1122 个靶点,并通过“相似共晶结构筛选 + 对接 + MCS-RMSD 过滤”的流程控制对接构象质量,在保证结构合理性的前提下扩大训练数据的化学空间和靶点覆盖范围。
在性能评估方面,PBCNet2.0 使纯深度学习方法在系列化合物排序任务上达到与 Schrödinger FEP+ 接近的水平。在 FEP 基准集的零样本预测场景下,PBCNet2.0 取得斯皮尔曼相关系数 ρ = 0.67、皮尔逊相关系数 R = 0.66 的排序表现,与 Schrödinger FEP+ 报道的 ρ = 0.70、R = 0.70 在统计上无显著差异。在少样本微调场景中,模型利用少量靶点特异性 SAR 数据即可进一步提升排序能力,并在该评估设置下超过 FEP+ 与前代 PBCNet。在模拟真实药物化学决策的主动学习挑选实验中,PBCNet2.0 平均可降低约 40% 的合成与测试资源投入,并使先导化合物优化效率提升至 7.18 倍,显示出用于 DMTA 循环中候选分子优先级排序的应用潜力。
围绕模型可信度,研究团队从多角度分析了 PBCNet2.0 的预测依据。基于不完整图的训练动态分析表明,模型在训练初期主要依靠配体结构特征,而训练约 12,500 步后逐渐转向以蛋白质-配体相互作用信息为主要驱动;结合专门设计的 SAR-Diff 测试集,PBCNet2.0 在“相同修饰、不同构效关系”的化学系列对上仍保持排序能力,支持其并非单纯依赖配体记忆。活性分层误差分析也显示,模型在不同活性区间保持相对接近的误差水平,未观察到明显偏向高活性样本的系统性偏倚。
为进一步提升模型可解释性,研究团队建立了基于门控权重的相互作用解释框架,通过分析等变消息传递层中的标量门控因子,构建原子-原子级相互作用重要性度量。以具有严格距离和角度约束的氟正交多极相互作用为案例,结合 F-Opt 基准、权重可视化和角度扰动实验,研究显示模型能够识别并量化这一精细相互作用:参与 F···C=O 作用的羰基碳原子被赋予高重要性权重,而当作用角度人为偏离合理范围时,该权重明显下降,表明模型对几何约束具有一定感知能力。
值得注意的是,PBCNet2.0 在未使用蛋白突变数据训练的情况下,对结合口袋突变引起的亲和力变化表现出一定迁移预测能力。模型在 8 个靶点的突变基准测试中取得平均 ρ = 0.53 的排序性能,优于多种序列模型、结构模型和蛋白质共折叠模型 Boltz-2。结合可解释性分析,模型能够捕捉如 N229C 突变导致关键氢键丢失并引起亲和力下降的分子机制。这提示,蛋白残基改变与化合物结构修饰都可被视为对蛋白质-配体相互作用网络的扰动,模型在相对亲和力学习中获得的相互作用规律可在两类任务之间部分迁移。
模型在真实药物发现项目中的实用性通过前瞻性湿实验得到进一步验证。在 ENPP1 和 ALDH1B1 两个靶点体系中,PBCNet2.0 对氟正交多极相互作用、对映体立体选择性以及结合口袋关键残基识别等问题的预测均得到实验支持,说明该模型可为先导化合物优化和分子探针发现中的具体设计假设提供计算依据。
总体而言,PBCNet2.0 结合了物理先验、成对学习范式和大规模结构化训练数据,在相对结合亲和力预测、蛋白质-配体相互作用解释和前瞻性实验验证中展现出较好的综合性能。该方法有望作为先导化合物优化、分子探针发现和耐药突变分析中的辅助工具。与此同时,论文也指出,PBCNet2.0 仍依赖可靠的结合构象或高置信度 anchor pose,更适合具有合理结合模式的同系物系列优化;对于缺乏结构锚点或存在明显结合模式改变的体系,仍需结合构象验证、蛋白质-配体共折叠和更高质量突变数据等后续方法发展。
上海药物所、临港实验室和上海科技大学与联合培养博士生虞杰,上海药物所博士生盛夏、范哲欢,上海药物所硕士生王照坤和同济大学研究员曹端华为论文共同第一作者。上海药物所郑明月研究员、张素林研究员和王明亮研究员为论文共同通讯作者。该研究由上海药物所、临港实验室、上海科技大学、同济大学等多家单位合作完成,得到中国科学院战略性先导科技专项、国家自然科学基金、国家重点研发计划、临港实验室、中国科学院青年创新促进会和中国科协青年人才托举工程等项目支持。研究团队感谢上海国家蛋白质科学中心、上海高等研究院和中国科学院大型蛋白质制备系统相关工作人员在数据收集与分析中提供的技术支持。
Yu, J., Sheng, X., Fan, Z. et al. Atomic-level protein–ligand recognition with PBCNet2.0 for probe discovery. Nat Chem Biol (2026).
https://doi.org/10.1038/s41589-026-02241-x
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢