
DRUGONE
对比语言—图像预训练(CLIP)模型依托数十亿规模的自然图像—文本配对数据训练,在零样本学习和跨模态理解方面展现出强大的能力。然而,将这类模型应用于生物医学领域仍面临显著挑战,其主要原因在于高质量医学图文数据规模有限,同时医学影像模态高度异构。研究人员提出了一种基于多模态医学知识蒸馏构建通用生物医学基础模型的方法——MMKD-CLIP。该模型通过融合九种生物医学CLIP模型中的互补知识,构建统一的视觉语言表示空间。
研究采用两阶段训练框架:首先利用覆盖26种医学影像模态的291万图文配对数据进行CLIP式预训练;随后利用大规模特征级知识蒸馏,将多个教师模型的知识整合到单一学生模型中。研究在58个数据集上进行了系统评估,涵盖九类医学影像模态和六种任务类型,包括图像分类、跨模态检索、视觉问答、生存预测以及癌症诊断等。结果表明,MMKD-CLIP整体性能达到或超过教师模型水平,并展现出良好的跨模态泛化能力和鲁棒性。

近年来,大规模视觉语言基础模型推动了通用人工智能的发展,使零样本分类、图文检索以及开放式视觉问答等任务取得突破。与此同时,医学人工智能领域也开始构建针对专业场景的CLIP类模型,用于学习医学图像与语义描述之间的对应关系。这些模型已经广泛应用于放射学、病理学、眼科学等领域,并在疾病分类、预后预测以及视觉问答等任务中取得成功。
然而,目前大多数生物医学CLIP模型都针对特定领域进行训练。例如,有些模型专门针对病理切片,有些则聚焦于胸部X线或眼底影像。当这些模型被应用于其他医学领域时,性能往往明显下降。
现实中的临床决策并非局限于单一模态。医生通常需要综合分析CT、MRI、病理切片、内窥镜图像以及临床文本等多种信息。因此,一个能够统一理解不同医学影像和文本信息的通用生物医学基础模型具有重要价值。
构建这样的大模型面临两大挑战。首先,不同机构和数据库的数据格式差异巨大,难以构建统一的大规模训练集。其次,目前公开可获得的医学图文数据规模远小于自然图像领域,限制了模型的语义覆盖范围。受自然图像领域知识蒸馏成功经验启发,研究人员提出利用多个已经训练完成的医学CLIP模型作为教师模型,通过知识蒸馏训练一个统一学生模型,从而实现跨领域知识融合与能力迁移。
方法
研究人员提出的MMKD-CLIP采用两阶段训练框架。第一阶段利用PMC开放获取文献数据库中的291万医学图文配对样本进行预训练,这些数据覆盖26种医学影像模态,包括病理图像、CT、MRI、眼底图像、OCT以及内窥镜图像等。第二阶段引入九个生物医学CLIP模型作为教师网络,从同一批数据中离线提取图像特征和文本特征,构建超过1650万个蒸馏样本。学生模型通过特征蒸馏和交互式对比学习同时学习教师模型的视觉表示与文本表示,从而在单一模型中融合多个领域专家模型的知识。模型骨干采用MetaCLIP视觉编码器和BioMed-BERT文本编码器,以实现统一的医学视觉语言表征学习。
结果
大规模生物医学蒸馏数据集构建
研究首先构建了用于预训练和知识蒸馏的大规模数据集。从BIOMEDICA数据库中筛选出291万高质量图文配对样本,其中包括约142万张单图像和149万张多面板图像,覆盖26种医学影像模态。
在蒸馏阶段,研究进一步构建了包含1653万个四元组样本的大规模知识蒸馏数据集。每个样本不仅包含图像和文本,还包含教师模型生成的视觉特征和文本特征。通过这种方式,学生模型能够同时学习多个教师模型所掌握的跨模态知识,从而获得更加全面的医学语义表示能力。
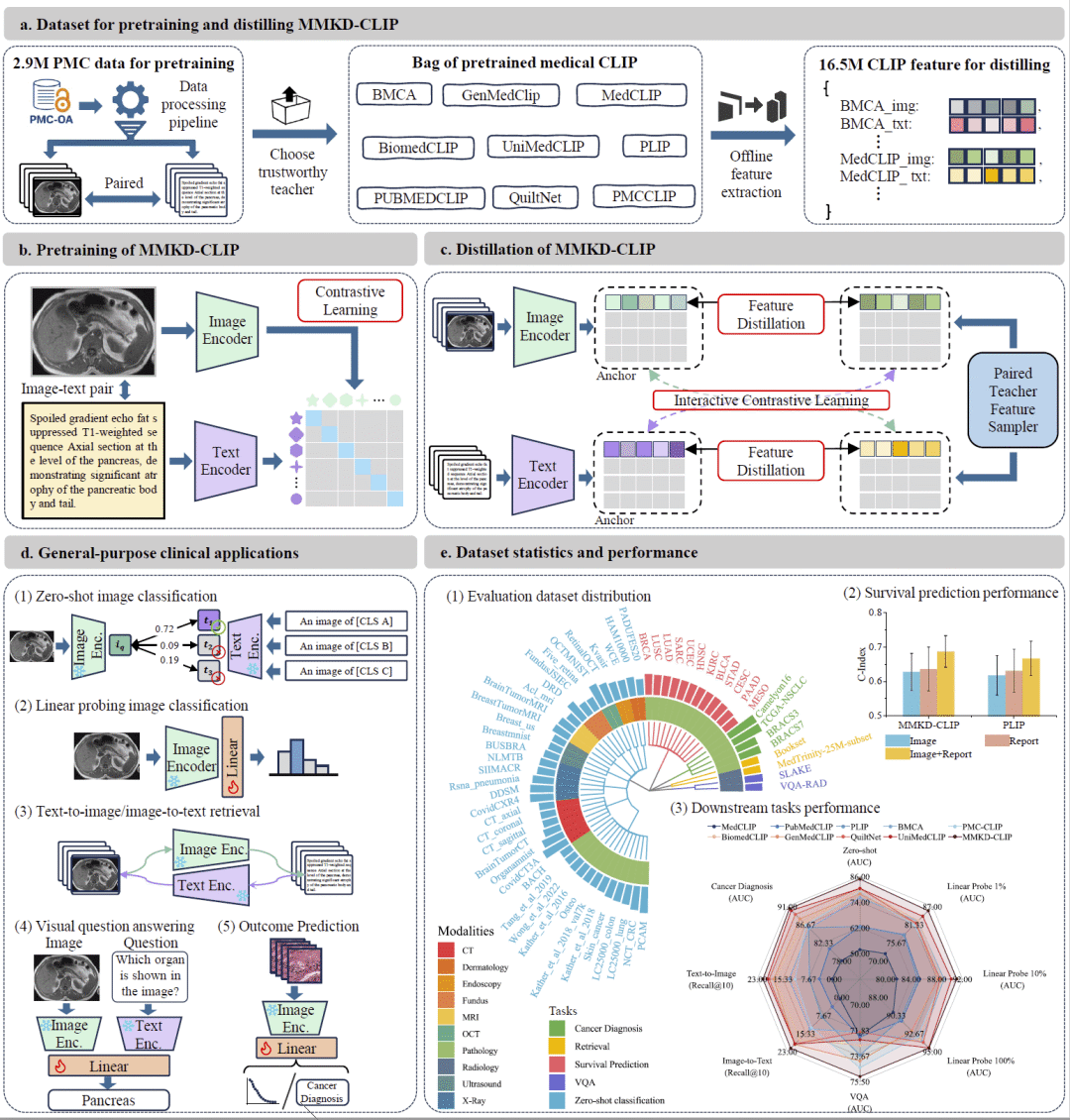
图1: MMKD-CLIP总体框架。
零样本医学图像分类
研究在38个数据集、9种医学影像模态上评估了模型的零样本分类能力。
结果显示,MMKD-CLIP在MRI、眼底图像、OCT、CT、X线、内窥镜以及病理图像七种模态中获得最高平均AUC,在其余两种模态中也位列前三。特别是在X线领域,相较于第二名模型取得超过3%的AUC提升;在病理图像和MRI任务中也表现出明显优势。
进一步分析发现,MMKD-CLIP不仅在个别数据集上表现优异,更重要的是在不同模态之间保持稳定性能。相比之下,一些现有模型虽然在某些特定数据集上排名第一,但跨模态泛化能力较弱。研究结果表明,多教师知识蒸馏使模型获得了更加均衡和稳定的医学视觉表征。
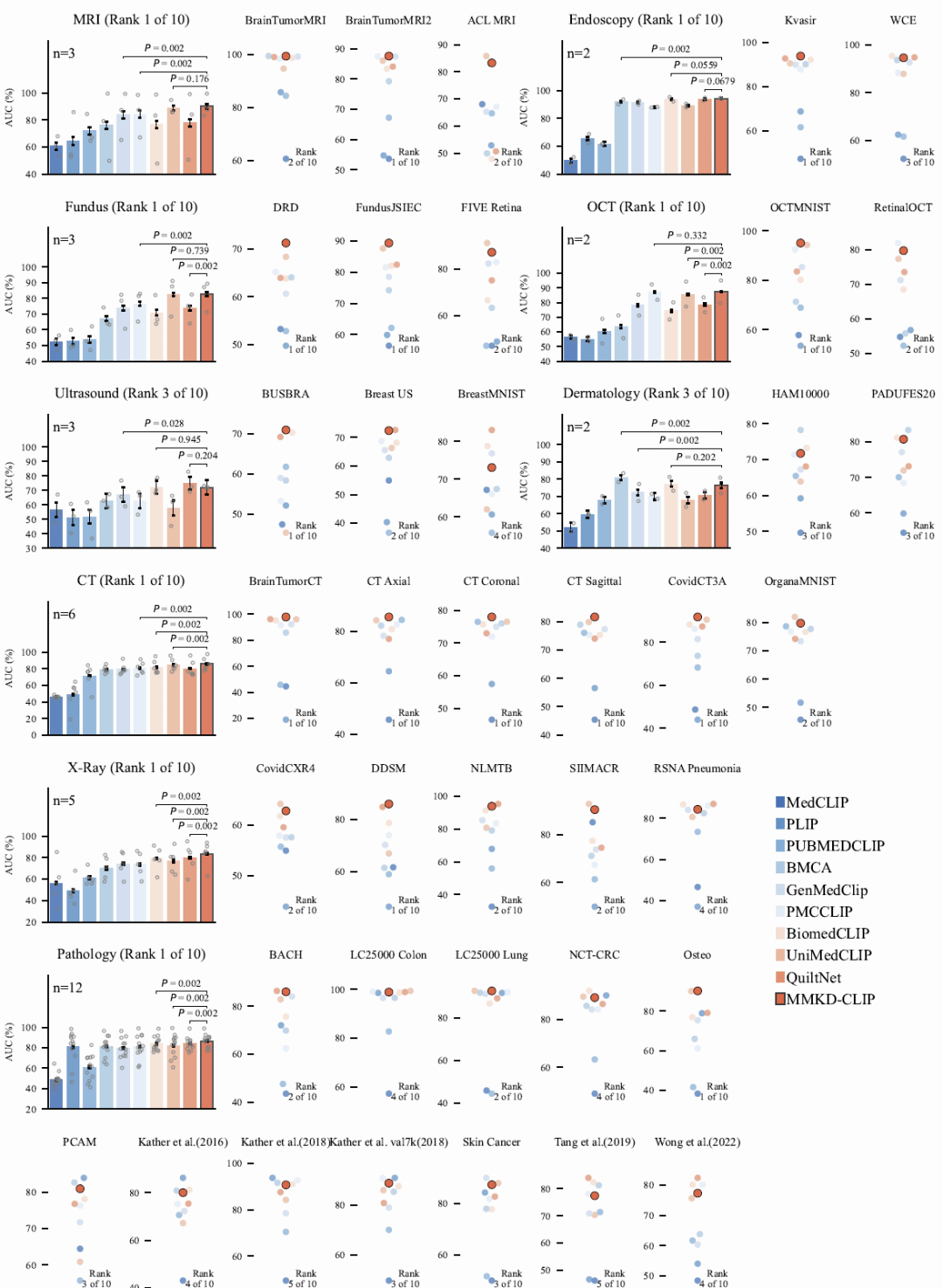
图2: MMKD-CLIP在零样本医学图像分类中的性能比较。
线性探针图像分类
为了评估模型在监督学习场景下的特征质量,研究采用1%、10%和100%训练数据比例进行线性探针实验。
在仅使用1%训练数据时,MMKD-CLIP已展现出显著优势。例如在MRI任务中达到94.44%的AUC,领先第二名超过5个百分点;在眼底图像任务中同样取得接近6%的优势。
随着训练数据增加,各模型性能均有所提高,但MMKD-CLIP始终保持领先地位。在全部训练数据条件下,其在多个模态中仍取得最佳结果。
这些结果说明,MMKD-CLIP学习到的表示具有较强的迁移能力,即使在标注数据极其有限的条件下,也能够支持高质量下游任务学习。
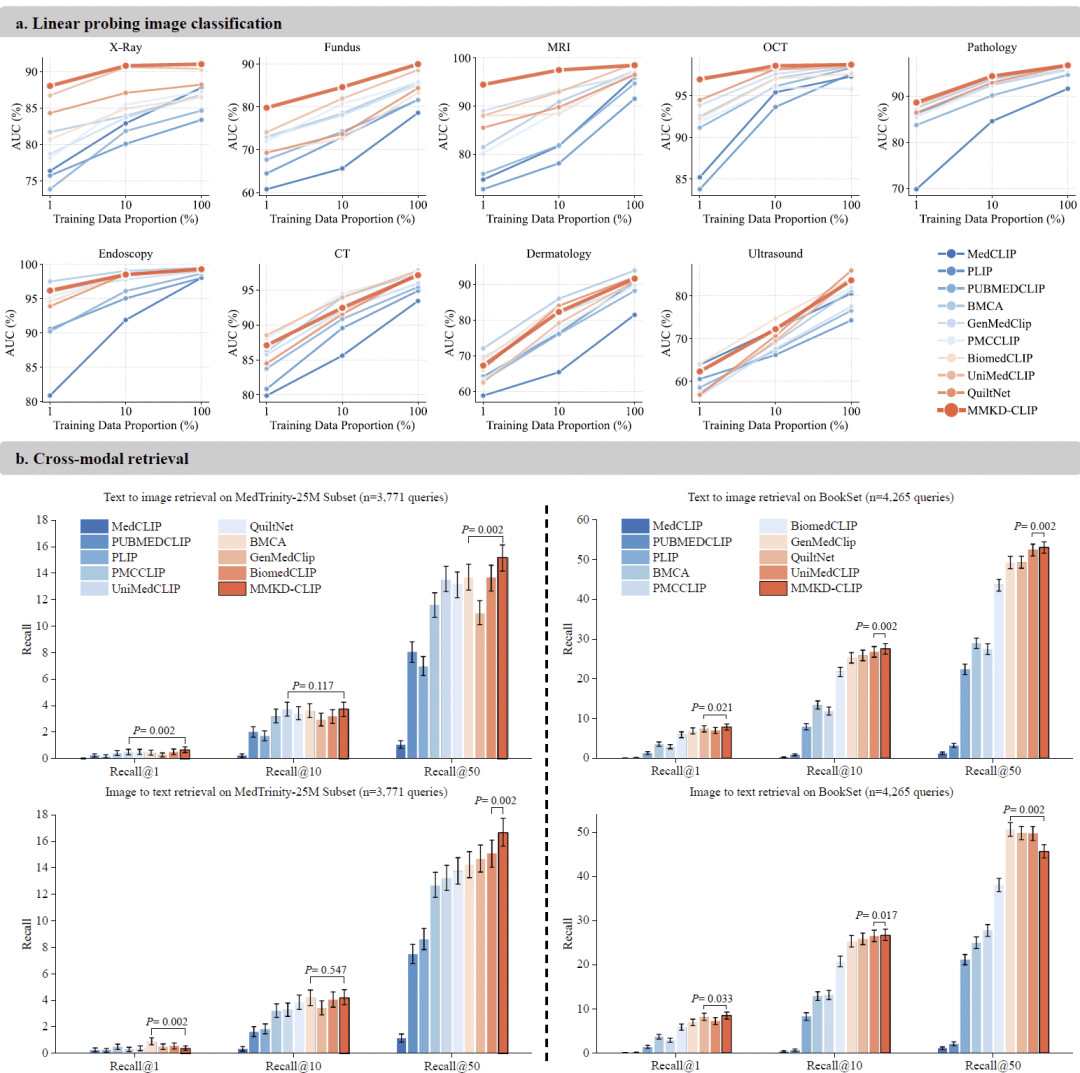
图3: MMKD-CLIP在线性探针分类与跨模态检索任务中的表现。
跨模态图文检索
为了评估视觉与文本之间的对齐能力,研究在MedTrinity和BookSet两个检索数据集上进行了测试。
在临床数据集MedTrinity中,MMKD-CLIP在文本检索图像和图像检索文本两个方向均取得最佳结果。其中,文本检索图像任务的Recall@50达到15.16%,明显高于现有模型。
在更加规范的BookSet数据集上,模型同样保持领先优势。尤其在Recall@1指标上取得最佳表现,表明模型具备较强的细粒度图文匹配能力。
研究认为,这种性能提升反映出多教师蒸馏有效增强了视觉和文本表示之间的语义对齐能力。
医学视觉问答
研究在SLAKE和VQA-RAD两个经典医学视觉问答数据集上进行了评估。
结果显示,MMKD-CLIP在总体准确率、开放式问题以及封闭式问题等多个指标上均取得最高成绩。
案例分析表明,模型能够准确识别复杂解剖结构、空间关系以及病理征象。例如能够正确定位肝脏、小肠、前纵隔等解剖区域,并识别动脉粥样硬化钙化等医学异常表现。
相比其他模型,MMKD-CLIP在处理语义模糊问题以及图像遮挡情况下仍能保持较好的推理能力,体现出更强的跨模态理解能力。
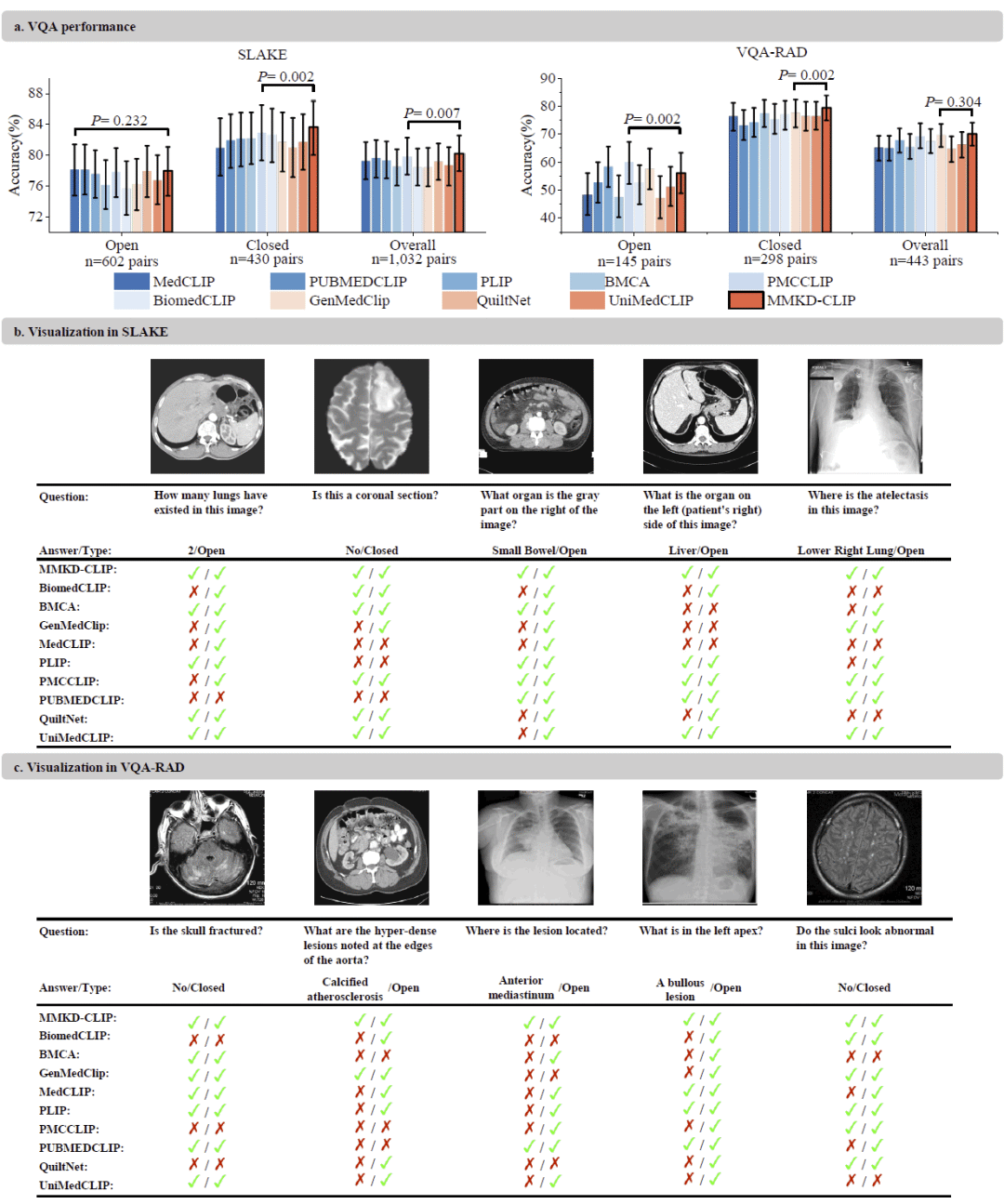
图4: MMKD-CLIP在医学视觉问答任务中的表现。
癌症生存预测
研究进一步评估了模型在TCGA数据库12种癌症中的生存预测能力。
通过融合病理切片图像和病理报告文本,MMKD-CLIP能够有效将患者划分为高风险和低风险群体。在乳腺癌、肺腺癌、头颈癌以及胰腺癌等多个癌种中,两组患者的生存曲线呈现显著分离。
与病理专用模型PLIP相比,MMKD-CLIP在大多数癌种上均获得更高的一致性指数(C-index)。研究发现,图像和文本信息融合后的预测性能明显优于单独使用任一模态。
这说明统一视觉语言表示能够同时捕获组织形态学特征和临床文本中的预后信息,从而提高生存风险预测能力。
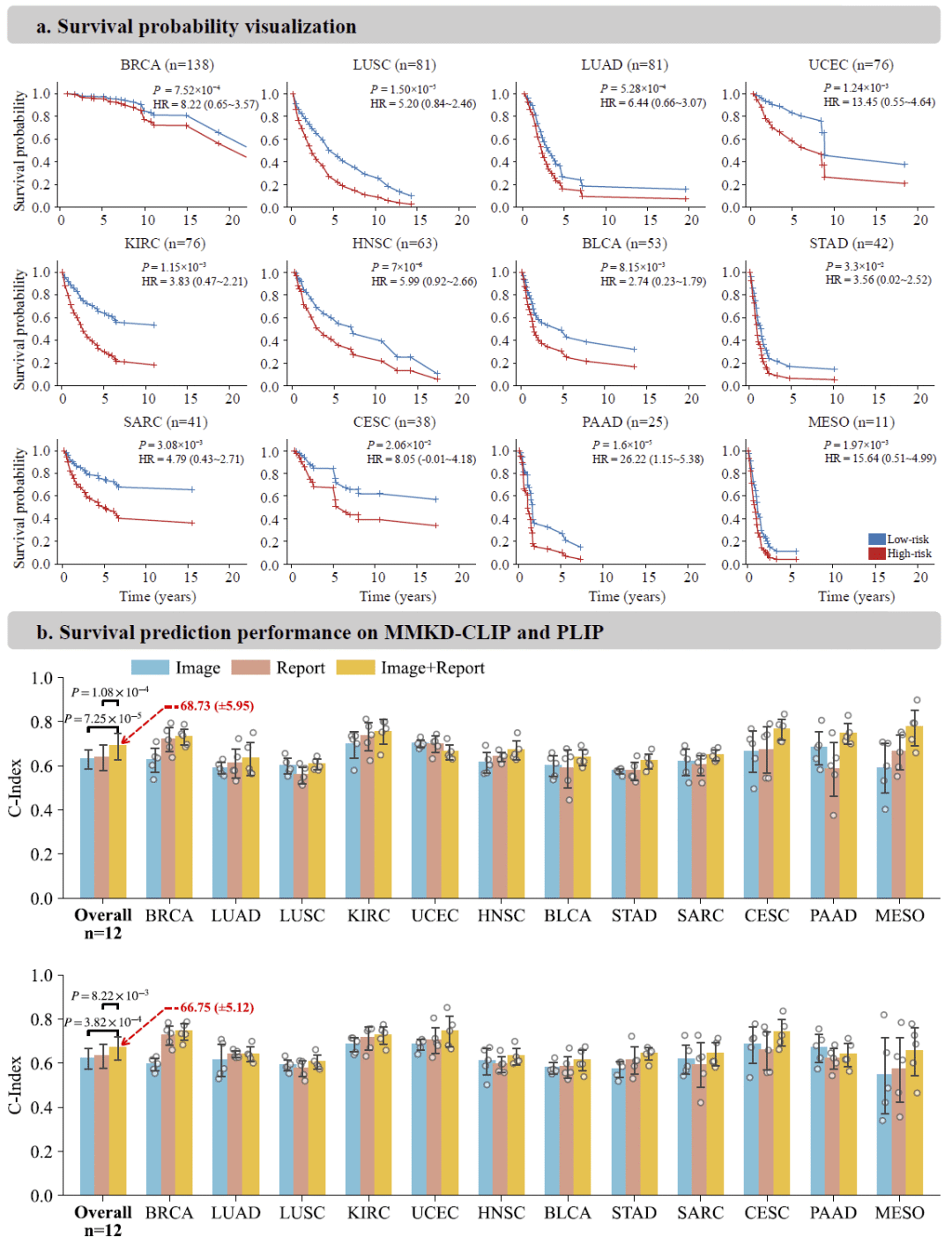
图5: MMKD-CLIP在TCGA癌症队列中的生存预测结果。
监督癌症诊断
在BRACS、TCGA-NSCLC以及Camelyon16等癌症诊断数据集上,研究对MMKD-CLIP进行了微调评估。
结果显示,模型在多个数据集上取得最高AUC。例如在TCGA-NSCLC数据集中达到97.28%的AUC,在BRACS多分类任务中也优于病理领域专用模型PLIP和QuiltNet。
研究认为,多教师蒸馏所获得的统一视觉语言表示使模型能够在病理学和放射学等多个领域保持稳定性能,从而成为一种通用癌症诊断基础模型。
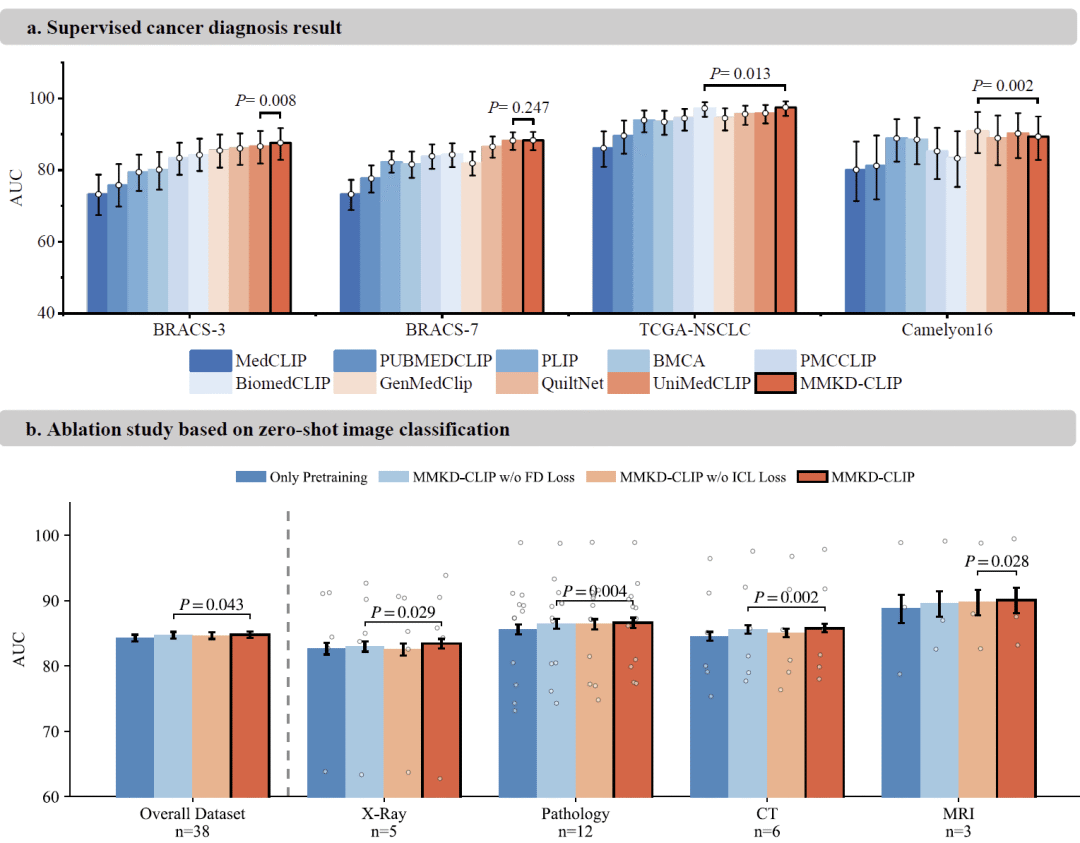
图6: MMKD-CLIP在癌症诊断与消融实验中的表现。
讨论
研究提出的MMKD-CLIP尝试解决现有生物医学视觉语言模型泛化能力不足的问题。通过将多个领域专家模型的知识蒸馏到单一学生模型中,研究构建了一个覆盖多种医学影像模态和临床任务的通用基础模型。
大量实验表明,该模型不仅在零样本分类、图文检索和视觉问答等任务中取得优异表现,还能够扩展到生存预测和癌症诊断等临床决策任务。尤其是在低标注数据条件下,模型依然保持较强性能,显示出良好的迁移学习潜力。
研究还发现,多教师蒸馏优于简单的模型集成策略。相比后期融合多个模型预测结果,蒸馏方法能够在训练阶段实现知识整合,从而获得更稳定、更高效的统一表示空间。
不过,研究人员也指出,该方法仍可能继承教师模型中的潜在偏差,包括数据来源差异、机构特异性特征以及标注不一致等问题。未来需要进一步研究偏差感知蒸馏策略,并引入更多医学模态和临床场景进行验证。
总体而言,MMKD-CLIP展示了一条构建通用生物医学基础模型的新路径。研究结果表明,通过融合多个领域专家模型,可以获得兼具泛化能力与专业知识的统一视觉语言模型,为未来临床智能系统和多模态医学人工智能的发展提供了重要基础。
整理 | DrugOne团队
参考资料
Wang, S., Jin, Z., Hu, M. et al. A generalist biomedical vision-language model via multi-CLIP knowledge distillation. Nat Commun (2026).
https://doi.org/10.1038/s41467-026-74120-x

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢