

一个当前还能稳定完成任务的 Agent,在经历几轮系统版本更新之后,还能否继续保持可靠?
真正的难点,在于它需要适应不断变化的环境。过去的大多 Agent 基准默认面对的都是静态环境,但接口、规则、代码库和用户偏好都可能持续变化,因此很难评估 Agent 在持续演化环境中的可靠性。
针对这个问题,来自新加坡国立大学的研究团队及其合作者提出了评测基准 EvoArena,并设计了用于追踪状态更新的补丁式记忆框架 EvoMem。

论文链接:https://arxiv.org/abs/2606.13681
结果表明,现有 Agent 仍难以应对持续演化环境。在 EvoArena 上的平均准确率仅为 39.6%。但加入 EvoMem 后,Agent 的表现明显改善:不仅在衡量连续任务完成能力的链级(chain-level)指标上平均提升了 3.7%,也在 GAIA 和 LoCoMo 上取得了稳定提升。
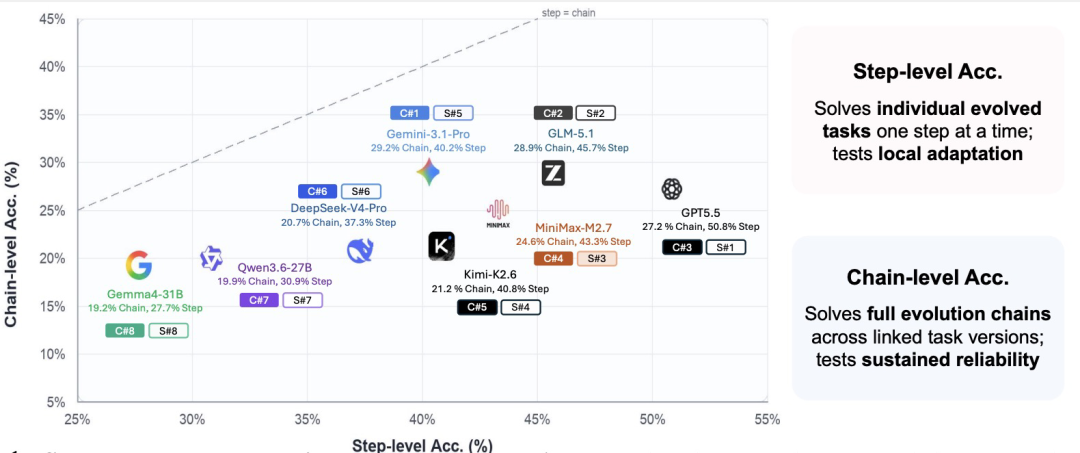
图|EvoArena 上的步骤准确率与链级准确率对比。
EvoArena 是如何设计的?
EvoArena 的核心思路,是在任务目标不变的前提下持续改变接口、规则、依赖、代码状态和用户偏好,以评测 Agent 的持续适应能力。研究团队据此设计了终端工作流、软件仓库和用户偏好三类任务。在评测指标上,step accuracy 反映单步任务的平均准确率,chain accuracy 则反映同一条演化链上的任务能否全部成功完成。
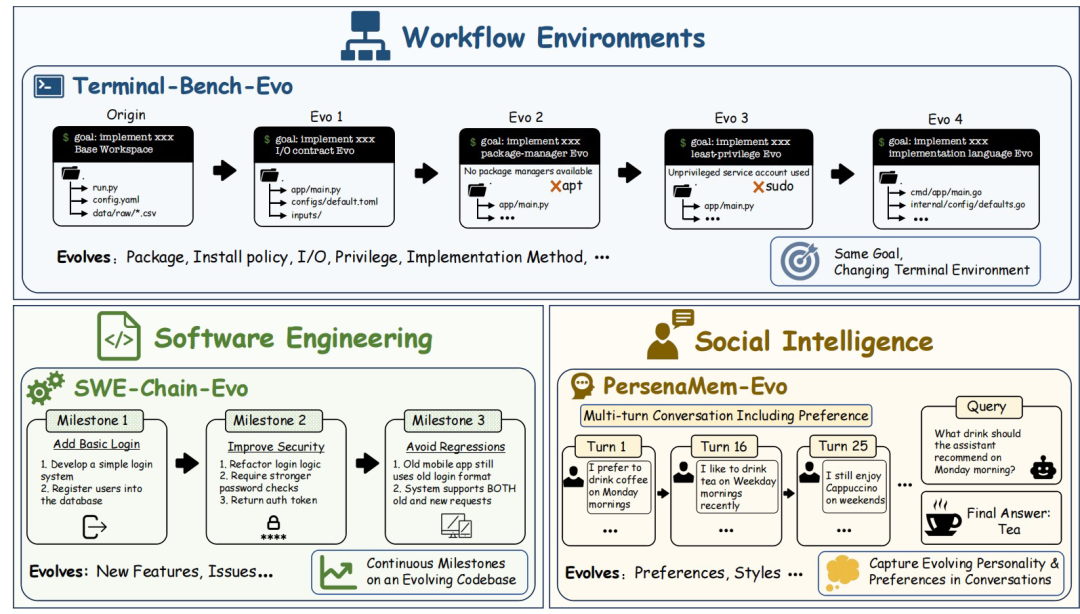
图|EvoArena 构建流程
终端工作流(Terminal-Bench-Evo):关注终端工作流随版本推进而发生的变化,任务目标不变,但部署方式、访问路径、权限要求、分支策略、依赖项和测试条件都会随着版本更新而改变。
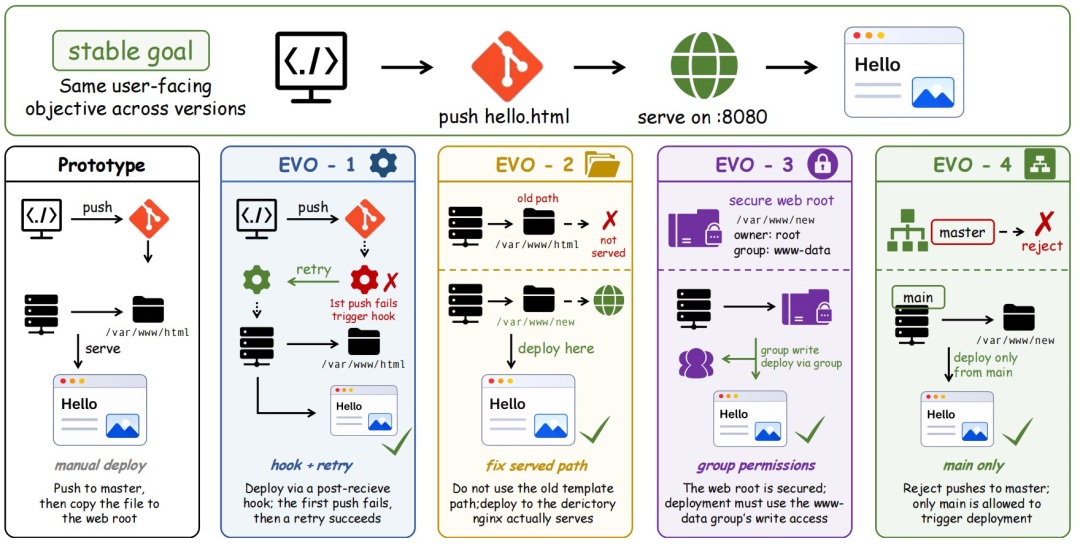
图|Terminal-Bench-Evo 示例。
软件仓库(SWE-Chain-Evo):关注软件仓库在连续迭代中的演化,新需求需要建立在不断累积的代码状态之上,同时保持旧功能稳定可用。
图|SWE-Chain-Evo 的一个演化链示例。
用户偏好(PersonaMem-Evo):关注长对话中的偏好变化。随着对话推进,新的偏好线索会不断出现,Agent 既要根据当前偏好作答,也要避免把已经过时的信息当作当前判断的依据。
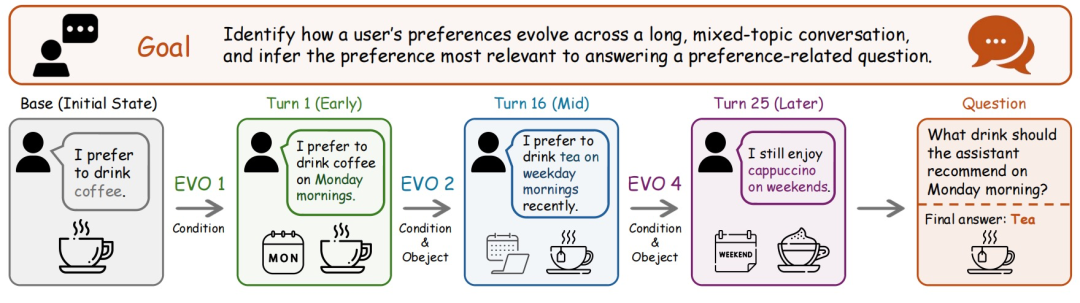
图|PersonaMem-Evo 的演化链示例。
配合这套评测,研究团队进一步提出 EvoMem,采用基于补丁的记忆演化机制(Patch- Based Memory Evolution)。它保留原有记忆系统,同时在关键记忆更新时追加补丁历史,记录修改前后内容、更新原因、摘要和相关证据。推理时,Agent 会同时检索最新记忆与相关历史补丁,在需要理解状态演化时获得更完整的上下文。与此同时,EvoMem 也保留了原有 Agent 接口,可直接适配 Terminus2、OpenHands、A-Mem 和 Memento-Skill。
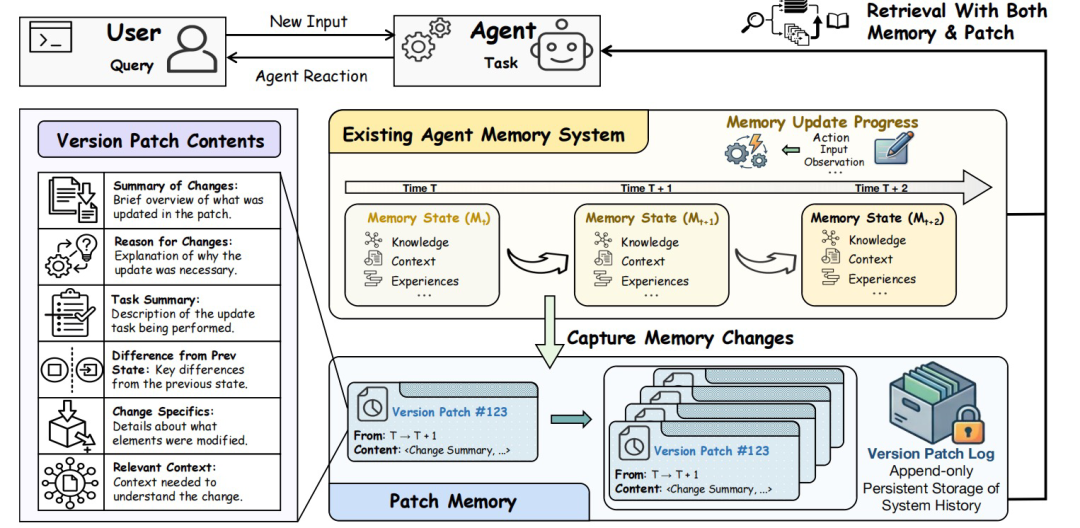
图|EvoMem 概述。
实验结果
EvoArena 上的整体结果显示,现有 Agent 对信息演化的持续追踪能力仍然有限。在 EvoArena 上,多种 Agent 与Backbone 组合的平均 Step 准确率仅为 39.6%,且进入 chain-level 评测后还会进一步下降。例如,GPT-5.5 在 Terminal-Bench-Evo 上的 Chain 准确率只有 31.8%,Gemini-3.1-Pro 在 PersonaMem-Evo 上也只有 38.8%。这说明,现有 Agent 即使能完成单步任务,也未必能在持续演化的环境中保持稳定表现。
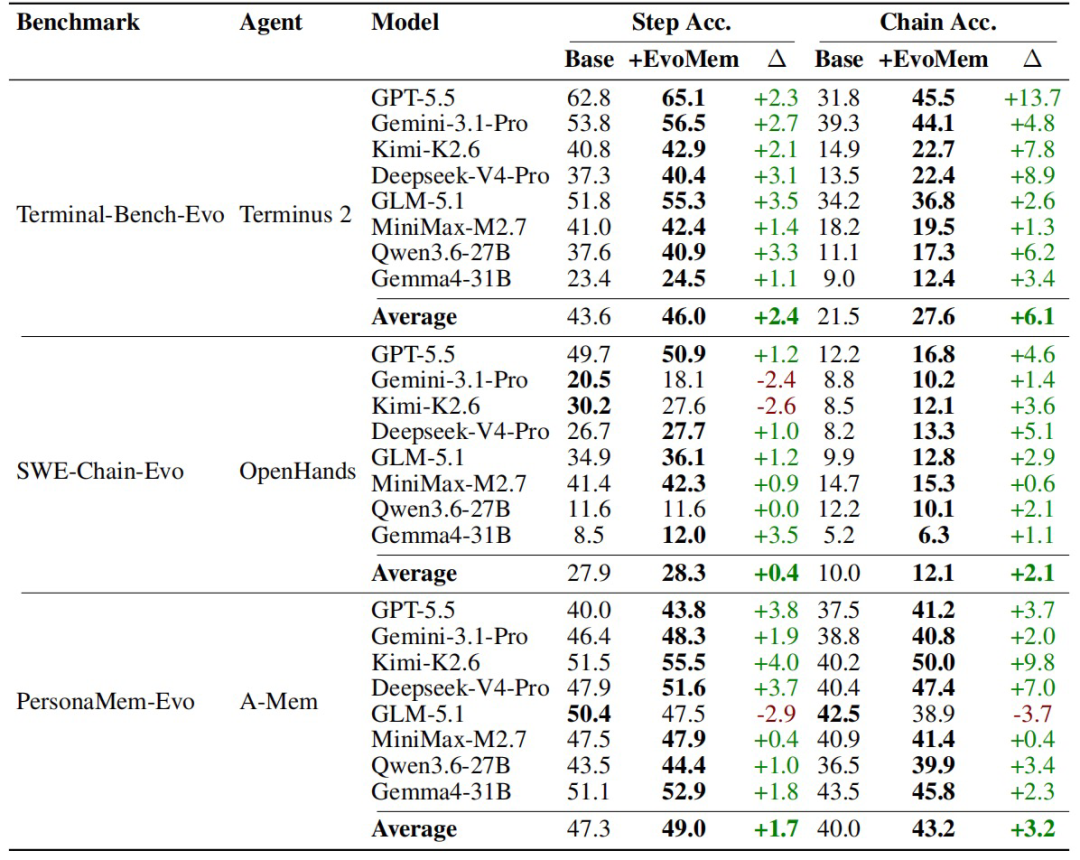
图|EvoArena 的主要结果。
引入 EvoMem 后,EvoArena 三个子任务的结果均有提升,而且对更严格的 chain 指标改善更明显。平均来看,Terminal-Bench-Evo 的 step 和 chain 准确率分别提升 2.4 和 6.1 个百分点,SWE-Chain-Evo 分别提升 0.4 和 2.1 个百分点,PersonaMem-Evo 分别提升 1.7 和 3.2 个百分点。这说明 EvoMem 的作用不只是增加记忆量,更在于帮助 Agent 抓住关键变化,并把这些变化用到后续任务中。
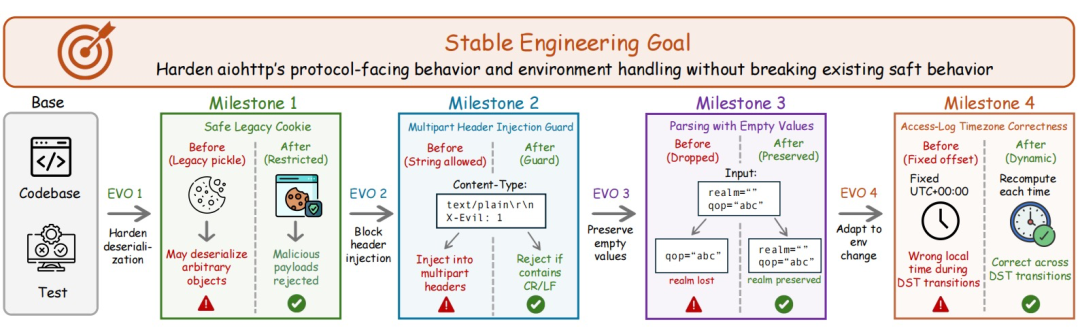
在 SWE-Chain-Evo 上,EvoMem 还降低了回归错误。具体来看,它将平均回归错误率降至 6.32%,说明 Agent 在适应新需求的同时,也更能保住已有功能,不容易因为新改动破坏旧行为。
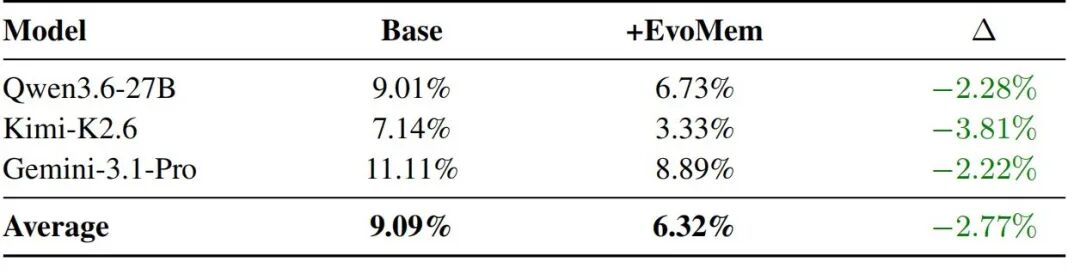
图|SWE-CHAIN-EVO 上的回归错误分析。
在 PersonaMem-Evo 上,EvoMem 对两类更依赖长期演化信息的问题帮助尤其明显: multi-pattern synthesis 和 temporal trajectory 两类题型的准确率都提升了 5.2 个百分点。同时,它也提升了对偏好证据的完整捕获能力,说明这种补丁式记忆不仅保留了更多历史信息,也更有助于模型恢复完整的偏好演化轨迹。
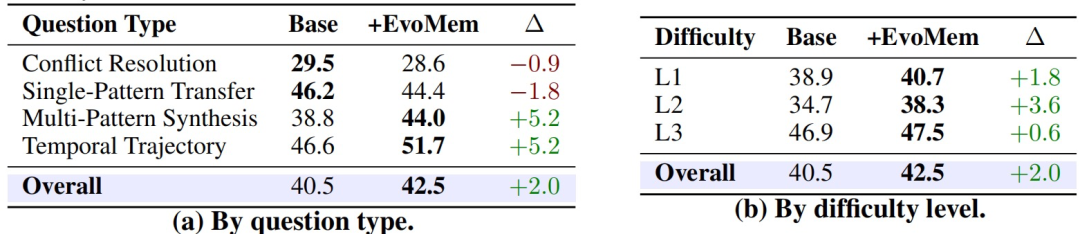
图|PERSONAMEM-EVO 准确率细分。
不过,EvoMem 的效果并不局限于 EvoArena。将其接入六个模型后,研究团队发现,GAIA 的平均成绩提升了 6.5 个百分点,LoCoMo 也提升了 3.3 个百分点。以具体模型为例,Deepseek-V4-Pro 在 GAIA 上从 70.0% 升至 80.0%,Gemini-3.1-Pro 在 LoCoMo 上 21.1% 升至 28.6%。
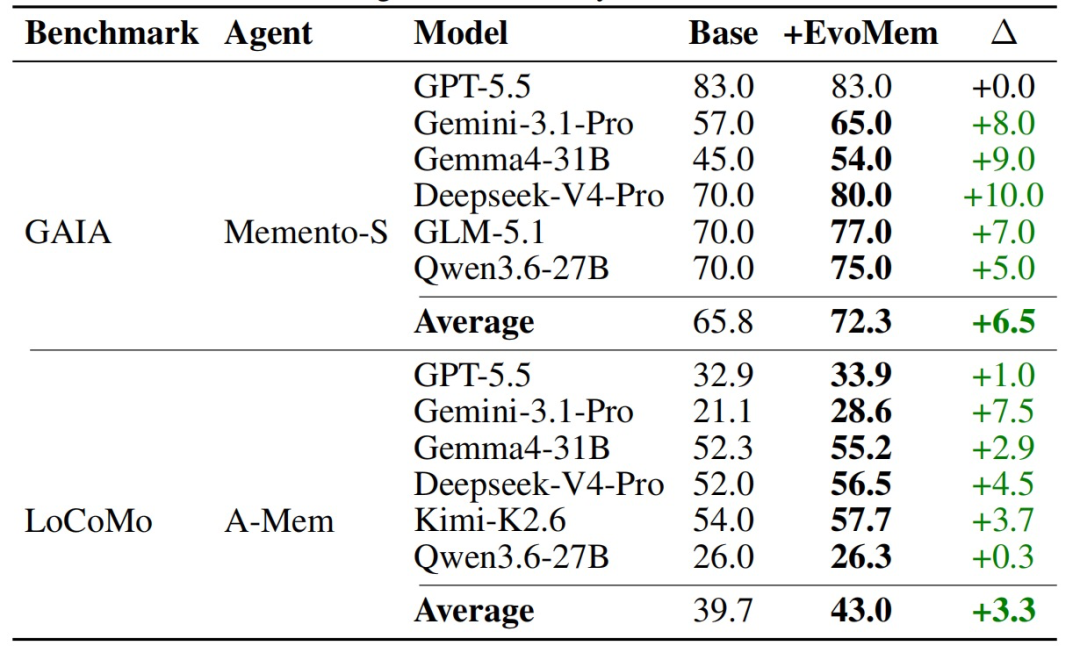
图|典型基准测试的主要结果。
不足与未来方向
当然,EvoArena 和 EvoMem 并非完美,依然存在一些亟待解决的问题。
目前,EvoArena 覆盖的环境变化形式仍主要集中在终端工作流、软件仓库和长程用户偏好三类场景。未来,这类持续演化过程还将扩展到更多环境中,包括机器人、具身交互、科学工作流、多智能体协作以及其他长周期运行系统。
研究团队指出,PersonaMem-Evo 目前对话规模和角色多样性仍然有限。未来,这一部分评测还需要继续扩充角色数量和数据规模,以提升覆盖范围。
其次,EvoMem 在部分设置下并不能稳定带来提升。因为历史补丁有时会引入歧义,使模型更难判断哪个状态才是当前有效版本。未来,还需要继续改进补丁检索和使用方式,减少这类干扰。
最后,EvoMem 在更长链条和更复杂场景下的检索效率,还有待进一步验证。未来,还需要继续优化补丁检索效率,并提升这类场景下的运行稳定性。
更多技术细节,详见原论文。
作者:夏千斯
如需转载或投稿,请直接在本文章评论区内留言

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢