
Crayotter团队 投稿
量子位 | 公众号 QbitAI
无需从头重来,只要定位一个故障的中间工件,就能让跑偏的AI剪辑“悬崖勒马”?
近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。
但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。
为了解决这个问题,业界尝试了各种宏观层面的手段,比如,增强长上下文模型、复杂提示词工程等等。
然而,这些方法大多将视频编辑视为一个黑盒,试图从潜变量的推理轨迹中寻找答案。
但是,剪辑内部究竟发生了什么?一旦出现错误,为什么整个流程往往需要推倒重来?是否存在可被精确定位、分析乃至局部干预的生产结构?

围绕这一问题,中科大等团队一项近期的开源工作(Crayotter: Traceable Multi-Agent Workflows for Long-Form Video Editing)从系统工程视角出发,系统研究了多模态智能体在长视频编辑中的机制。
不仅找到了长视频频频“翻车”的关键症结,更揭示了一个令人意外的真相:
高质量的AI视频不只依赖于更强的生成器,更是为了顺应可观测的外部状态而进行的“工件溯源”。
核心贡献
团队从工件(Artifacts)层面系统重构了长视频剪辑管线,围绕“如何规划、如何执行、如何修正”三个核心问题,给出了相对完整的机制性回答,论文的主要贡献如下:
将长篇多模态视频剪辑表述为一个基于工件溯源的智能体轨迹问题,使得规划、执行和修改过程都以显式的外部状态为条件。
引入了一种覆盖率感知的多模态素材检索循环,将抽象的剪辑请求分解为视觉、叙事、风格等维度的覆盖标签,并迭代搜索缺失的语义证据。
通过环境驱动的反射机制,团队发现智能体并非只能依赖潜在推理轨迹,而是可以通过观察具体的外部工件(如检索报告、时间轴计划、渲染输出等)来更新策略并进行局部修复。
提出了一个轨迹级的RLVR(具有可验证奖励的强化学习)框架,利用GRPO算法优化,并结合了可验证的剪辑信号、LLM作为评委的多维度评分以及人类偏好校准。
核心方法
拒绝黑盒:寻找可定位的“工件”(Artifacts)
在长视频剪辑中,是否存在一种机制,能够稳定地锁定并修改“翻车片段”而不影响全局?
如果剪辑决策在模型内部高度耦合,那么针对错误的干预只能停留在重新生成;
相反,若动作能够被归因到具体的工件,则意味着背后存在更加清晰、可操作的机制。
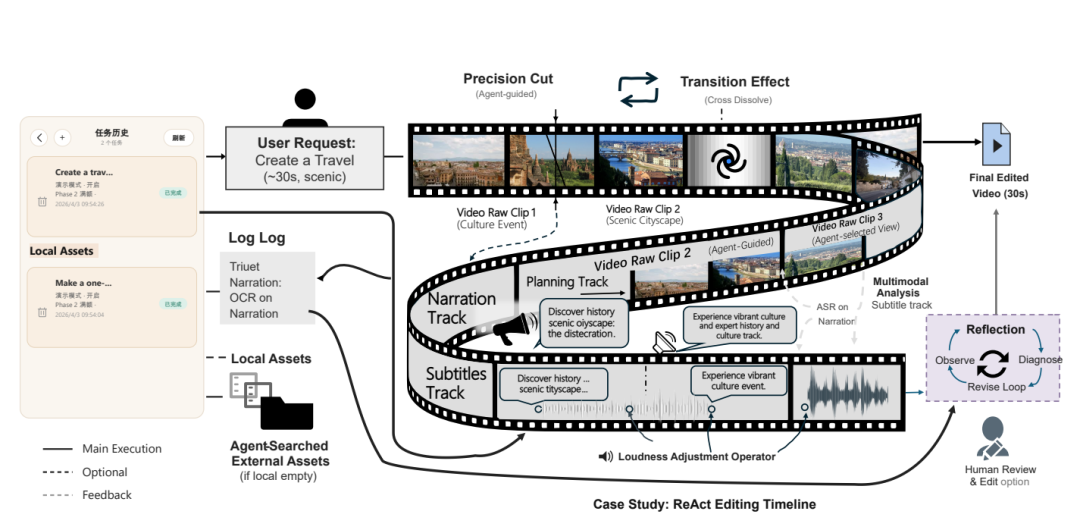
基于这一考虑,系统没有将LLM对话视为唯一的状态,而是将状态外化为可检查的工件:
检索覆盖率报告、分析JSON、时间轴计划、转场计划、工具调用、中间渲染和最终输出。
团队甚至引入了带有时间戳水印的技术,将时间坐标直接渲染在感知证据上,以绑定语义观察与绝对剪辑坐标。
在此基础上,研究阶段的智能体不调用任何处理工具,而是进行深度的叙事推理,输出一份极度详尽的结构化“剪辑蓝图”。这份蓝图包含了叙事结构、镜头顺序、节奏、转场和旁白意图。
这意味着,剪辑动作在模型内部是有清晰、可定位的结构基础的。
这使得后期的任何失败都能被定位到特定的源片段、时间戳跨度或规划理由上。
纠错本质:基于环境的反射(Environment-Grounded Reflection)
确立了外部工件的存在后,一个更深层的问题浮出水面:
这些工件到底在干什么?
仅凭规划,很难保证最终执行不偏离轨道。
因此,该团队进一步从工具执行的角度检验了工件在模型行为中的作用。
具体而言,中科大等团队在执行阶段让ReAct Editor基于蓝图和素材,熟练调用超过20个模块化的视频编辑工具(包括裁剪、合并、插入转场、生成字幕、调整响度等)。
实验结果揭示了智能体纠错背后的真正机制:
基于环境的反射(Environment-grounded reflection)。
当某个工具调用触发诊断失败时(例如时间戳不准确、转场不平滑或旁白未对齐),智能体观察到的是发生故障的具体工件,并仅修复受影响的片段,而不是重新启动完整的剪辑过程。
从这一视角看,长视频剪辑不再是一次不透明的单次生成尝试,而是一条由规划、执行和修复组成的可复现轨迹。

溯源素材:源于内容覆盖,而非盲目生成
在确认了蓝图和反射机制的作用后,团队进一步追问一个更为根本的问题:
视频质量的上限,是在剪辑阶段决定的,还是在找素材阶段就已经注定?
如果素材本身缺乏支撑,无论后期工具多么强大,也无法凭空捏造合理的叙事。
长视频剪辑的核心瓶颈往往在于素材准备。
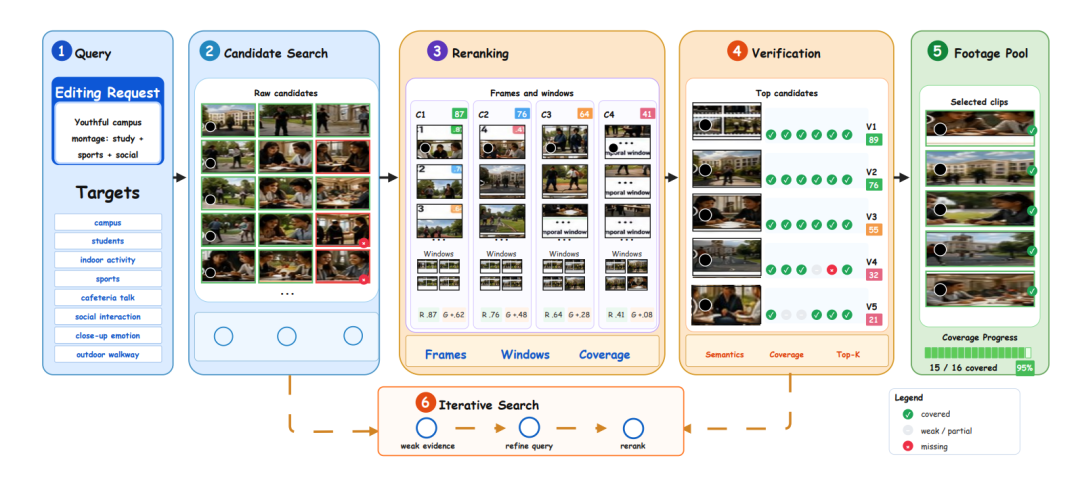
为此,团队构建了第一阶段:覆盖率感知的多模态素材检索。
该系统将用户请求扩展为场景、人物/动作、风格等覆盖标签,并根据候选视频的边缘覆盖增益进行重新排序。
结果表明,系统会持续进行后续搜索,直到所选素材池的覆盖率达到目标阈值或耗尽预算。
这说明,消除长视频的断层问题必须从更底层的素材准备阶段抓起,将抽象意图转化为可验证的视觉证据,确保后续剪辑拥有充足的“原材料”。
实验评估
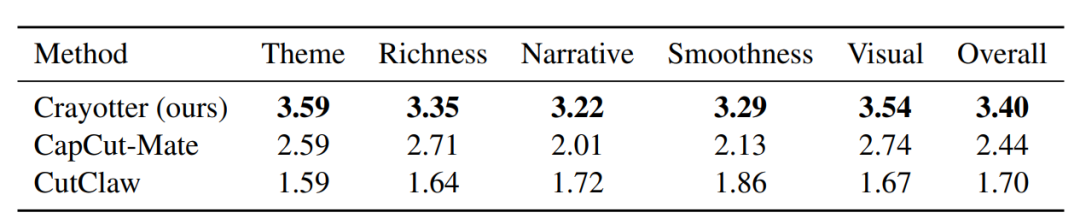
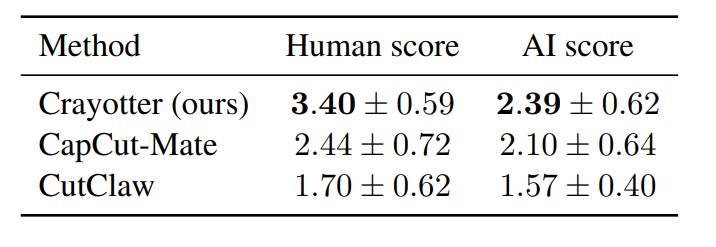
在23个固定编辑主题的综合评估中,Crayotter与现有的实用基线方法(CapCut-Mate和CutClaw)进行了对比。
在主题一致性、内容丰富度、叙事连贯性、剪辑流畅度和视觉质量五个维度上,Crayotter的人类评估及AI评估得分均显著优于对比基线。
实验证明,明确的素材准备和基于工件的规划阶段能大幅提升长视频自动编辑的质量与可控性。
小结一下
该工作为理解与实现可控长视频自动剪辑提供了全新思路。
首先,中科大等团队提供了一种基于明确工件的编辑范式:
检索覆盖率报告、多模态分析、时间轴文件和渲染反馈等成为了可被智能体和用户共同观测的实体状态。
其次,执行阶段的反射机制表明,纠正生成的视频错误不一定依赖反复生成,也可以通过局部编辑特定时间轴、重新调用特定工具来完成。
这为开发更可控、更稳定的AI视频系统开辟了新的物理干预路径。
最后,这一工作对多模态智能体的评估与优化本身提供了新的视角。
结合RLVR的优化思路表明,长视频生成的优化需要超越传统的黑盒评分,从更底层的工具调用准确度、时长匹配度和工件有效性出发,重新审视智能体的训练目标设计。
项目代码与示例:https://github.com/idwts/Crayotter
论文链接:https://arxiv.org/abs/2606.07636
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢