
阿里ATH-Token Foundry联合中国人民大学高瓴人工智能学院正式开源LOGOS(Language Of Generative Objects in Science)—— 一个基于统一"科学语法"的多领域科学生成基础模型。LOGOS将蛋白质、抗体、小分子、化学反应、材料及其空间相互作用等异构科学对象统一编码到共享的离散 token 空间中,在纯序列自回归范式下实现跨领域科学任务的统一生成建模。
开源内容一览:
LOGOS-1B/LOGOS-3B/LOGOS-8B 预训练模型权重
LOGOS-8B 后训练(Post-training)模型权重
推理代码
技术报告
HuggingFace
https://huggingface.co/LOGOS-Hub
GitHub
https://github.com/LOGOS-Hub/LOGOS
――――――――――――――――――――――――――――――――――――――――
性能概览
在六大代表性科学任务上,LOGOS以纯序列建模范式一致性地匹配或超越领域专用方法:
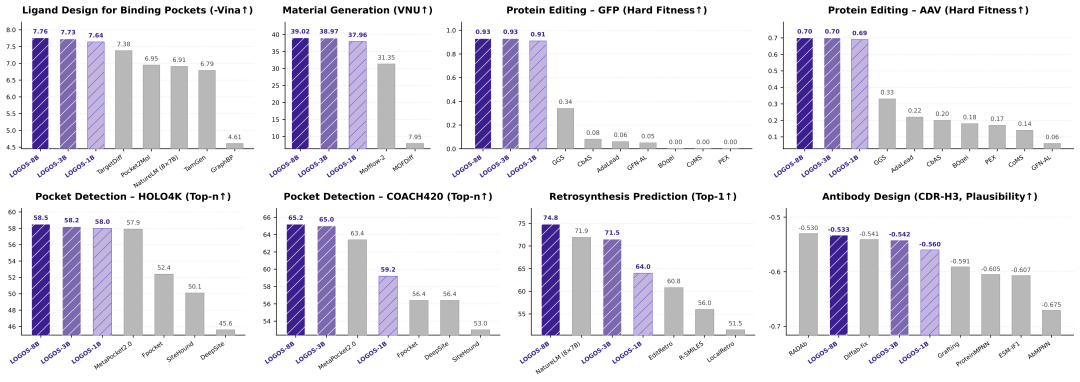
特别值得注意的是:LOGOS-1B仅用1/56的参数量(1B vs 8×7B),即在多个任务上超越 NatureLM,展现了极高的参数效率。
为什么需要 LOGOS?—— 问题与动机
AI for Science 的范式变革
近年来,AI驱动的自然科学研究正在从"对既有体系的理解与判别"演进为"在给定目标与约束下对新对象的生成与设计"。无论是新候选配体的发现、功能材料的设计,还是反应路径的规划,核心挑战已从"选择最优"变为"在复杂设计空间中创造满足多重约束的新实体"。
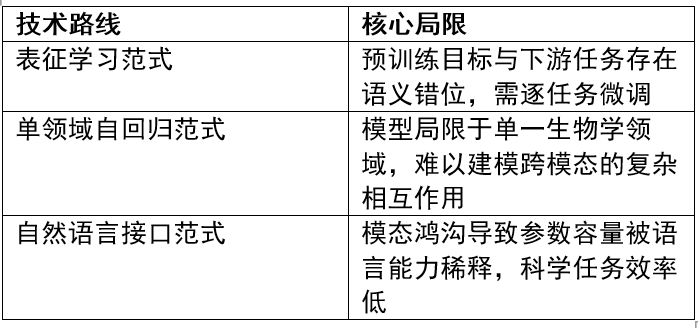
现有路线的局限
围绕 AI 驱动的科学建模,已形成三条主要技术路线,但各有瓶颈:
LOGOS 的核心洞察
尽管蛋白质、小分子、材料等在符号表示层面高度异构,但它们在底层都遵循特定的组成规则、结构约束和相互作用语义——可以被视为同一种"科学语言"的不同方言。通过设计一套统一的形式语法,可以将多领域科学任务映射为同一语法空间下的序列预测问题,从而实现:
跨领域知识迁移;
多任务协同优化 ;
预训练与下游目标的紧密对齐。
核心技术创新 —— 统一科学语法
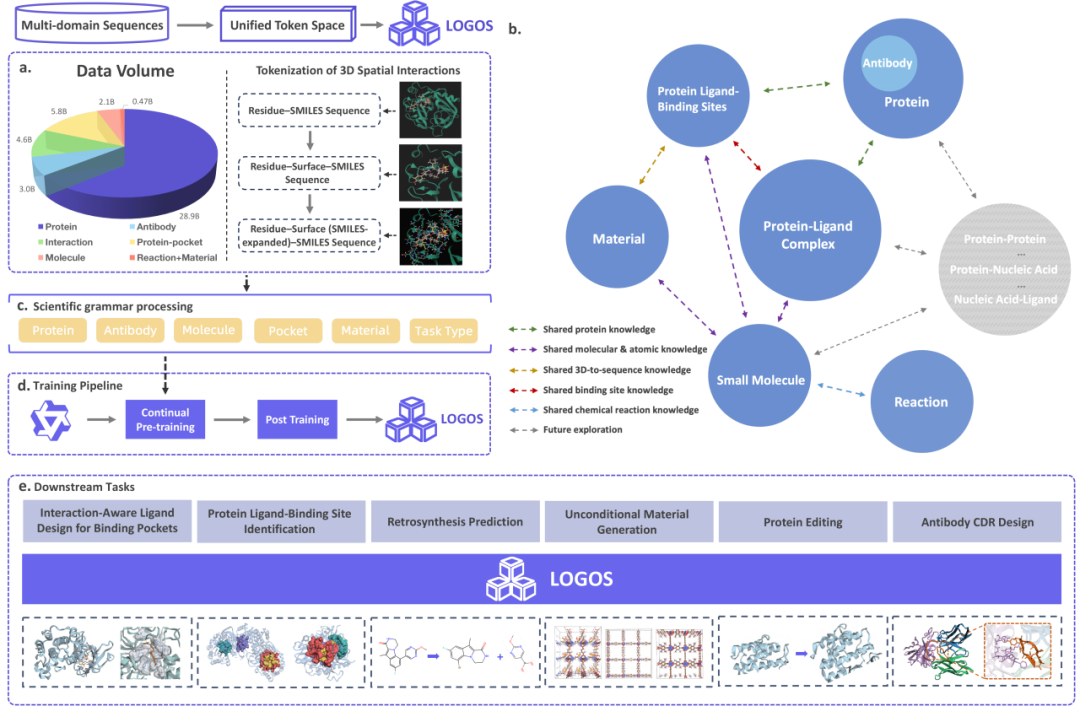
设计理念
从知识体系出发的模态选择
在自然科学领域,对生命系统中分子基础与整体行为的机制阐释,以及从分子组分出发构筑与调控复杂功能化学体系,已形成贯穿生命科学、化学及其交叉研究的重要发展方向。在这一背景下,蛋白质与小分子分别成为表征生命活动与实现化学干预的两类核心科学对象——前者作为生命活动的核心执行者几乎参与所有细胞生化过程,后者则是调控蛋白质功能、干预生命过程最重要的化学手段,构成了药物发现与化学生物学的物质基础。
围绕这两类核心对象,相关知识体系可进一步从对象家族扩展与分子界面互作两个维度展开:
家族扩展维度:抗体作为具有高度序列多样性与特异性识别能力的特殊蛋白质,是生物大分子家族中不可忽视的成员;化学反应与功能材料则从转化过程与物质组成的角度,进一步拓展了小分子化学空间的知识覆盖;
界面互作维度:蛋白质与小分子并非孤立存在,二者之间的界面互作——尤其是蛋白质结合口袋对小分子配体的选择性识别——构成了连接生物大分子与化学实体的关键纽带,也是理解分子识别机制与药物作用机制的基础。
基于上述以蛋白质与小分子为核心、兼顾其家族延伸与界面互作的知识体系,LOGOS 构建了一个涵盖 7 类模态 的大规模预训练语料库(共 44.87B tokens),并在统一科学语法框架下将其编码为共享词表下的离散 token 序列:

关键创新点 1:统一"科学语法" + 空间交互的离散化
这是 LOGOS 最具突破性的设计,由两个相辅相成的部分构成。
(a) 统一的"科学语法"表示体系
LOGOS 设计了一种共享词表下的离散 token 表示体系,将异构科学对象(蛋白质、抗体、小分子、材料、化学反应等)及其跨对象关系编码为统一语法空间下的 token 序列。这一语法不仅为每类模态定义了规范化的序列形式,更通过共享词表与统一边界标记,使原本相互割裂的领域表示得以在同一个生成空间中被自回归地建模——这是LOGOS能够进行跨领域联合预训练与知识迁移的形式基础。
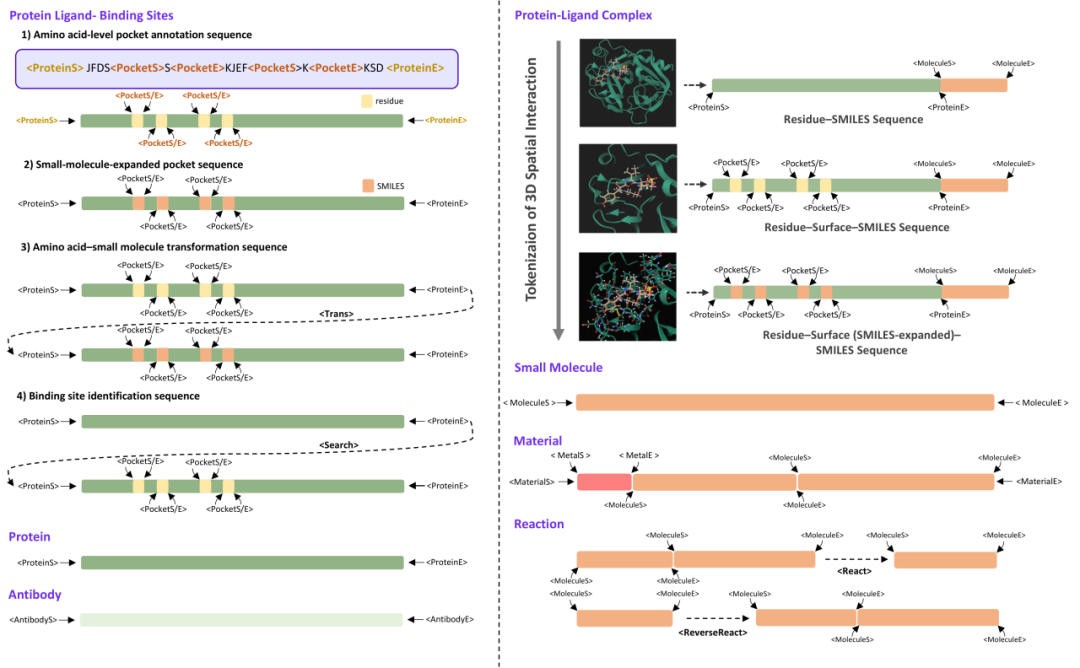
(b) 空间交互的离散化 —— 无需显式坐标
在统一语法的基础上,LOGOS进一步将空间交互纳入语法体系。传统方法处理蛋白质-配体相互作用必须依赖显式3D坐标和几何神经网络(如GNN、扩散模型);LOGOS则将空间接触模式和约束关系语法化为离散 token,在纯序列范式下捕获复杂的三维结构信息。
具体而言,蛋白质口袋的三维空间关系被编码为三种递进的序列表示:
残基-口袋标注序列:先标出氨基酸级别的基本信息;
残基-口袋-小分子展开序列:加入表面接触信息,让结构更立体;
残基-口袋转换序列:通过<Trans>标记实现氨基酸到分子结构的显式对齐。
这一设计使得LOGOS无需任何3D坐标输入,仅通过序列预测来学习蛋白质口袋与配体之间的空间互作规律。
(a) 提供"统一的语言",(b) 把"空间结构"也写进这门语言中 —— 二者结合,使 LOGOS 能够在同一个序列建模框架下,同时表达多领域的自然科学实体。
关键创新点 2:预训练-下游任务的形式一致性
传统范式中,预训练目标(如掩码预测)与下游任务(如分子生成)之间存在显著的"目标偏差"。LOGOS的科学语法设计确保:
预训练数据的序列形式 = 下游任务的输入输出形式
预训练的next-token prediction 目标 = 下游的条件生成目标
这种form-objective alignment有效消除了预训练与下游应用之间的 gap,无需复杂的适配层或大量微调即可激活生成能力。
关键创新点 3:跨领域知识协同迁移
统一语法不仅是形式上的表示统一,更通过共享 token 空间建立了跨模态的深层语义桥接:
实证 1 —— 口袋翻译实验:模型在给定氨基酸口袋序列后,能准确"翻译"为对应的分子SMILES结构,证明了跨表示体系的系统性对应关系的习得。
实证 2 —— 语法组分消融:
- 去除口袋与复合物数据 → 性能接近随机(Vina -3.57)
- 加入口袋数据但去除翻译组分 → 显著提升(Vina -6.25)
- 加入全部语法组分 → 性能跃升(Vina -7.64)
实证 3 —— 多任务联合训练:四个任务联合 SFT 的性能 全部优于 各自独立 SFT,证明了跨领域的正向知识迁移。
实验亮点 —— 六大任务全面验证
结果详见技术报告
口袋条件配体生成
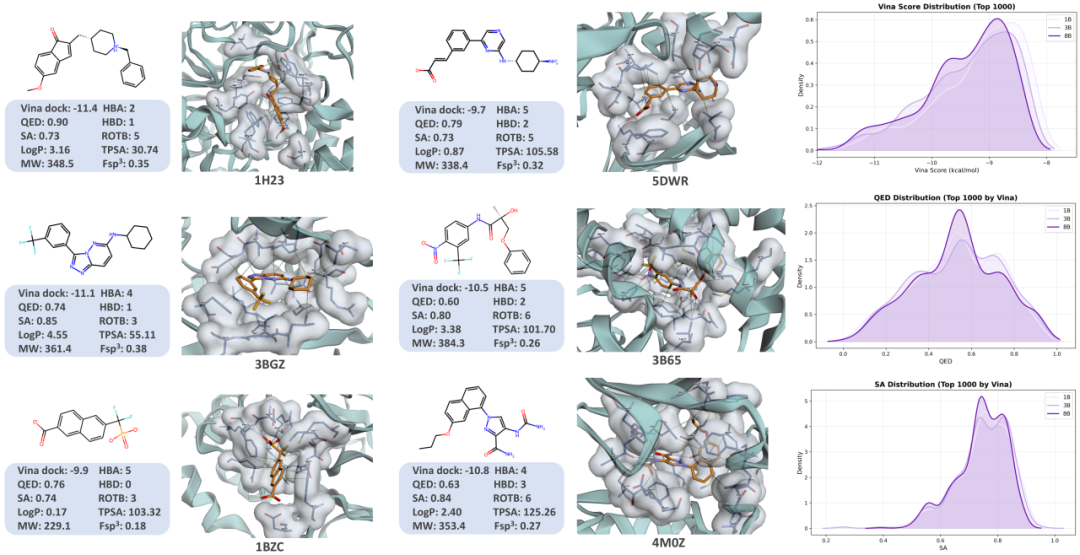
LOGOS 口袋条件配体生成结果
核心发现:
LOGOS-1B(约 1/56 参数量)即超越 NatureLM (8×7B),展现极高参数效率
纯序列范式首次超越显式依赖 3D 坐标的扩散模型
生成配体同时满足结合亲和力、药物相似性、合成可及性等多维药化属性
蛋白质配体结合位点识别
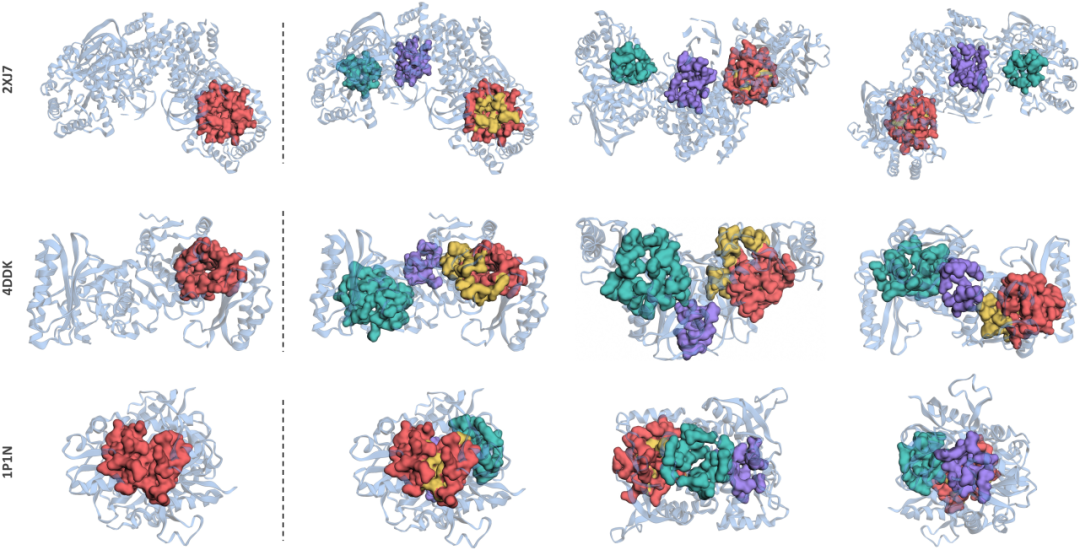
LOGOS 蛋白质口袋识别结果
LOGOS仅使用氨基酸序列(无需3 结构)即可预测蛋白质结合口袋,将口袋识别从"依赖3D结构"扩展至"仅需序列信息"的全新范式。LOGOS-8B在HOLO4K数据集上Top-n达到58.5,超越所有传统3D方法(除 P2Rank 外)。
逆合成预测
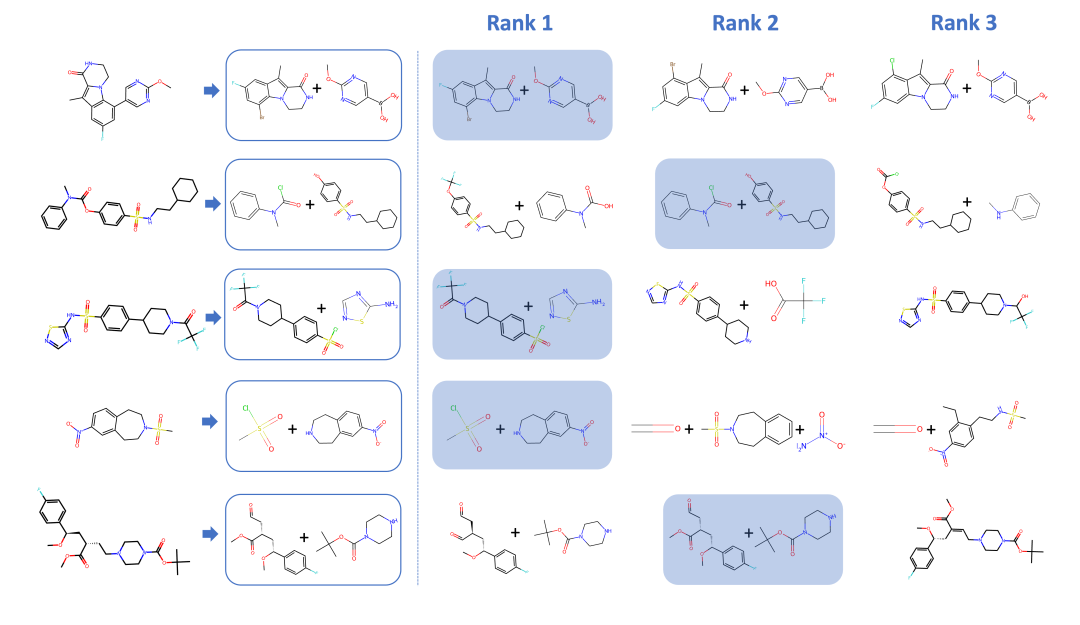
LOGOS 逆合成预测结果
LOGOS-8B的Top-1准确率达到74.8%,全面超越所有基线方法。
MOF 材料生成
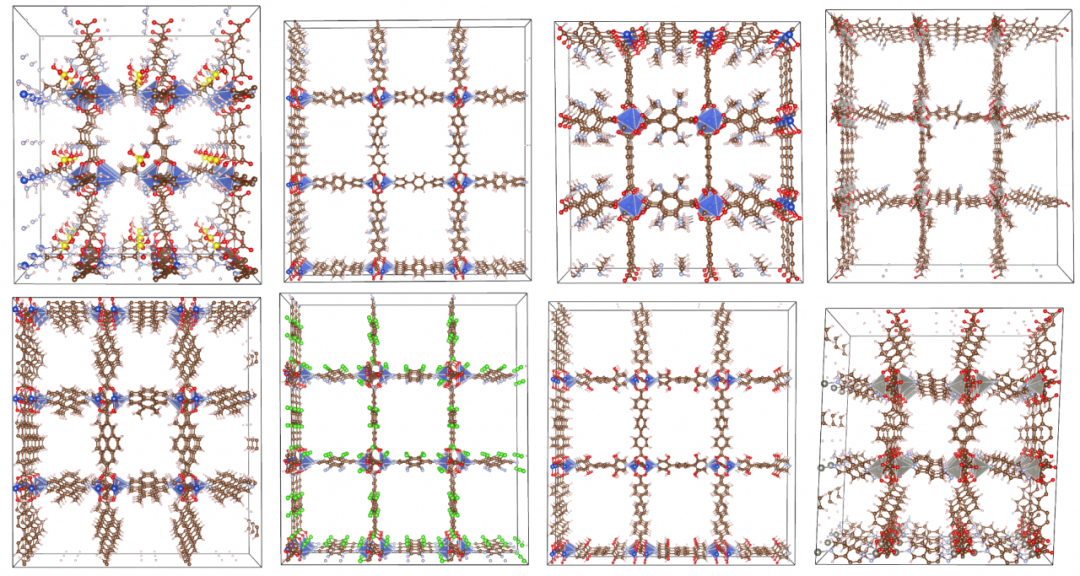
LOGOS MOF材料生成结果
亮点:
NBB(新型构建单元比例)从MOFFlow-2的10.10%提升至17.78%(+76%),证明模型具备超越已知训练数据、生成全新分子构件的能力 —— AI对科学的推动不应止步于再现已知,更应面向未知空间的生成与创造。
蛋白质编辑
LOGOS 在AAV和GFP两个蛋白质定向进化任务上,Hard难度下Fitness达到 0.93,展现出在预训练格式外任务上的强泛化能力。
抗体 CDR 设计
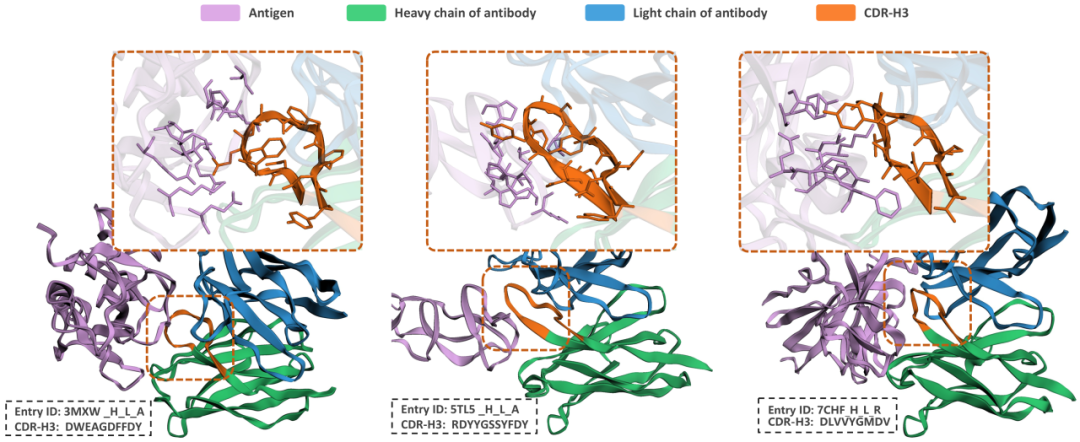
LOGOS 抗体CDR设计结果
LOGOS-8B在 具有高度多样性的CDR-H3区域 的恢复率超越部分结构依赖的逆折叠方法,并在序列合理性指标上取得了具有竞争力的表现,验证了大规模抗体序列预训练对序列模式学习的有效性。
Scaling Behavior
在全部任务上,LOGOS从1B → 3B→8B展现出一致且稳定的性能提升趋势,验证了统一科学语法框架下scaling law在科学领域的成立性。
展望与价值
对自然语言基础模型研究的贡献
LOGOS 的工作不只是一个AI4S下游应用,它在多个维度上回答了基础模型研究的核心开放问题:
离散化 tokenization 的普适性验证
基础模型社区的核心假设之一是:连续世界可以被有效压缩为离散token序列并通过next-token prediction建模。LOGOS在自然语言之外的七类异构科学对象(蛋白质、小分子、反应、材料、蛋白口袋、蛋白口袋小分子)上验证了这一假设的成立边界——设计恰当的 tokenizer(即科学语法),离散自回归范式可以推广到形式结构迥异于自然语言的领域,且展现出稳定的scaling behavior。这为基础模型技术栈向非语言模态的迁移提供了方法论参考。
跨模态统一表示的可行性与瓶颈刻画
大量基础模型研究关注"如何在一个模型中统一多种模态"。LOGOS提供了一个极端案例:将化学、生物、材料等看似毫无语法共性的科学对象统一到一个 token 空间中。实验表明在 1B–8B 参数范围内观察到了跨领域正向迁移和稳定scaling,但也精确刻画了瓶颈——自然语言的注入在当前参数规模下反而导致科学任务性能下降(模态鸿沟 / 参数容量错配),这为后续研究"多模态融合的参数效率边界"和"模态间干扰机制"提供了定量实验依据。
预训练-下游一致性的范式探索
当前基础模型的一个核心痛点是pretraining objective 和 downstream task 之间存在gap(alignment tax)。LOGOS 通过让预训练直接操作领域原生表示(而非翻译为自然语言中间形式),实现了预训练与下游任务在形式和目标上的一致性(form-objective alignment)。这一设计思路对基础模型探索"减少 alignment tax"和"更原生的task formulation"有方法论启发。
科学域Scaling Law的验证
LOGOS 在1B–8B参数范围内观察到了稳定的scaling behavior,为基础模型提供了科学域上的scaling law数据点,补充了当前主要集中在NLP/Code/Vision上的 scaling 经验,有助于回答:基础模型的scaling law是否具有跨域普适性?
AI4S 基础模型拥抱 LLM 的潜力
LOGOS 的一个关键发现是:大语言模型的预训练权重可以高效迁移到科学领域。
实验表明,当模型的embedding、backbone 和head全部继承LLM预训练权重时,在科学任务上的性能达到最佳。可迁移的核心能力可能来自Transformer的深层序列建模层——包括长程依赖捕获、上下文条件推理和层次化表征构建——而非简单的基模token表示。
这一发现具有重要的生态意义:
AI4S不需要从零开始:继承LLM的通用序列建模先验,可以大幅降低科学基础模型的训练成本
LLM技术栈可复用:推理优化(vLLM、量化)、训练框架(DeepSpeed、Megatron)、部署方案等LLM 生态工具可应用于科学模型
促进两个社区的深度融合:AI4S领域拥抱LLM技术生态,LLM社区获得新的应用场景和 scaling 验证,交叉创造更大价值
LOGOS 的实践表明:AI for Science 的未来可能不在于构建与LLM割裂的独立技术栈,而在于让科学基础模型与大语言模型深度对齐——共享架构、共享训练范式、共享推理基础设施——从而使基础模型真正成为AI4S的新入口。
未来方向
LOGOS 推动 AI for Science 从"特定模态的专用模型"向"统一语法空间下的通用生成模型"演进,对应研发范式从"筛选驱动"向"设计驱动 / 发现驱动"的根本转变,具备成为下一代科学研发基础模型的潜力。
未来,LOGOS计划将这套“科学语法”扩展至基因组等更多领域,并探索科学语言与自然语言的深度融合,致力于构建一个真正通用的科学基础模型。
LOGOS —— 让 AI 说科学语言,推动自然科学走向"设计驱动"与"发现驱动"的新范式。
参考资料
Mingyang Li, Yurou Liu, Jieping Ye, Bing Su, Ji-Rong Wen, and Zheng Wang. "Speaking the Language of Science: Toward a General-Purpose Generative Foundation Model for the Natural Sciences." arXiv preprint arXiv:2606.16905 (2026).
https://arxiv.org/abs/2606.16905
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢