
分子生成(molecular generation)这个方向走到今天,其实整个社区都在跟一个幽灵搏斗——化学有效性(chemical validity)。无论是早期的VAE/GAN路线还是后来的图扩散模型(Graph Diffusion),绝大多数方法都在做同一件事:用一个巨大的参数空间去"学着别生成非法分子",然后用各种后处理、过滤、奖励塑形去修补剩下的漏洞。这条路不是不行,但它把大量建模容量浪费在了本应被硬约束解决的问题上。
而这正是CoCoGraph(Collaborative Constrained Graph Diffusion) 这篇工作的破局之处:它干脆不让非法分子出现在扩散轨迹上。 通过把化学价键约束"焊死"在扩散过程的结构层面,CoCoGraph实现了 100% 化学有效性(按GuacaMol最严格的定义),同时在分布匹配质量上击败了DiGress、GDSS、GruM、DeFoG等一众强劲对手——而且用的参数量只有别人的十分之一不到。

论文:A collaborative constrained graph diffusion model for the generation of realistic synthetic molecules
单位:罗维拉维尔吉利大学、ICREA
请索引第105篇论文
 |  |
01 为什么"换边"比"加噪"聪明得多
传统离散图扩散的思路,本质上是给邻接矩阵或边类型施加一个带噪声的转移过程——比如DiGress在节点/边类型上做多项分布的逐步"洗白"。但分子不是任意图:每个碳只能有四根键,氮三对电子、氧两对……这些化合价(valence)和度序列(degree sequence)约束是硬物理规律。
CoCoGraph的做法非常优雅:它的前向噪声过程不做任何破坏价键规则的"删除/添加",而是采用 Double Edge Swapping(DES)——随机选中两条边 AB 和 CD,拆掉它们,然后交叉重连为 AC 和 BD。
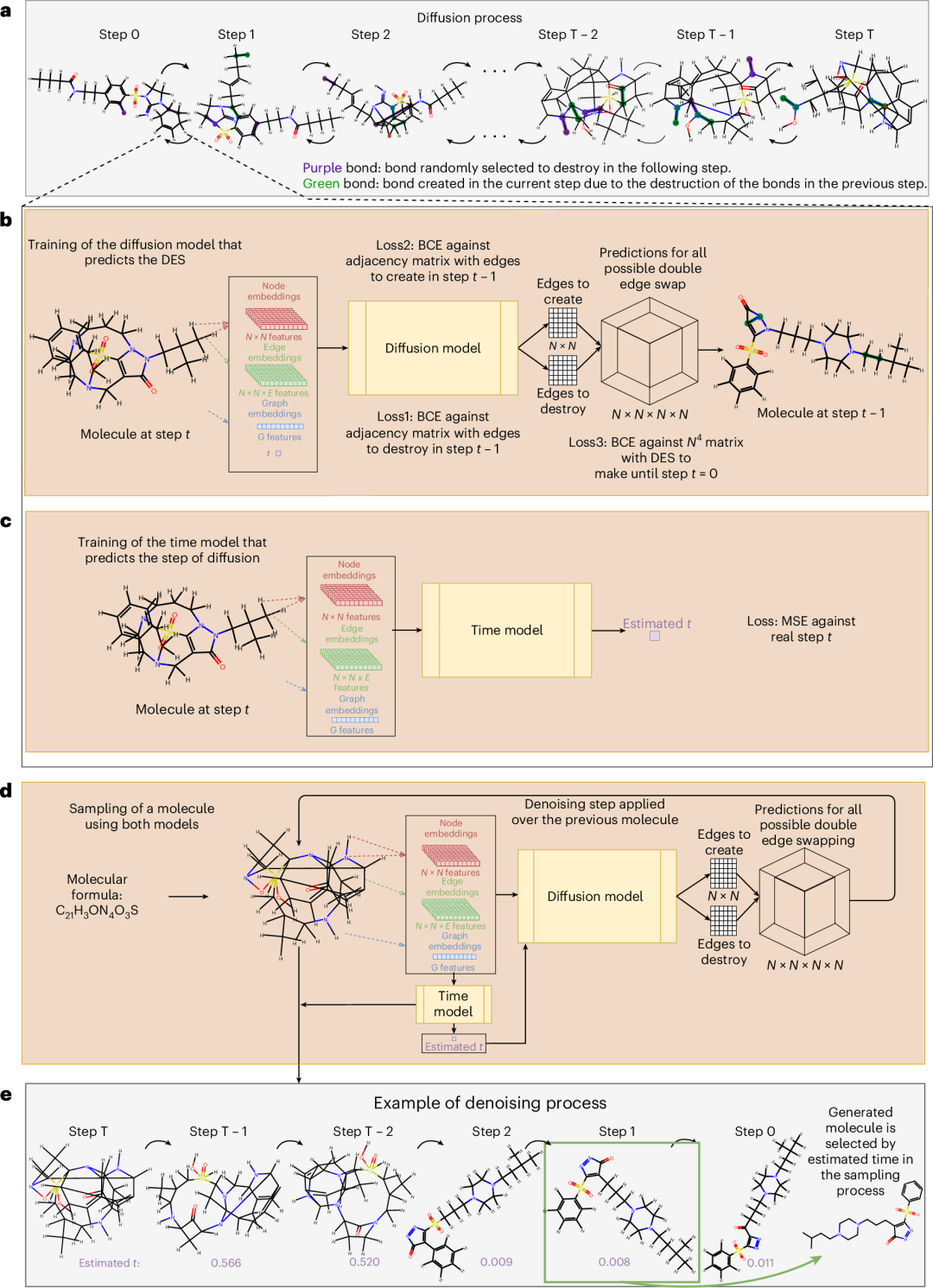
图 1:约束协作图扩散模型,CoCoGraph。a,约束扩散过程。我们通过在每一步交换两个化学键,在分子图中引入噪声。然后,我们训练扩散模型和时间模型来逆转这一过程。b,扩散模型。在每一步,它接收分子特征和时间步长作为输入,并对所有可能的边交换进行评分。c,时间模型。它接收分子特征并估计当前分子图的时间步长。d、e,采样模型(d)和示例(e)。我们协同使用训练好的扩散模型和时间模型,从一个具有特定分子式的随机分子图生成去噪轨迹。然后,我们选择预测时间最短的分子作为生成的分子(e)。
这一步的妙处在于: 每条边被拆掉一根键的同时,原子的总连接数不变——即每个节点的度(degree = 该原子的键数 = 化合价占用)严格守恒。分子式不变、原子不变、价键合法性不变。扩散只是在同分异构体的连接空间里翻滚,逐步走向一个最大熵的Molloy-Reed分布(固定度序列下的随机图分布)。这相当于把一个 级的分子空间,收缩到了每个分子式对应的合法连接子空间内。搜索空间急剧收窄,模型就不需要再花参数去"学化合价"了。
反过来说,去噪过程学的东西也变得纯粹得多:只学"哪一对边应该undo这个swap"——即预测当前图上哪个DES操作能把图拉回真实分子流形。
02 扩散模型 × 时间模型的双引擎
这里有个很容易被忽略但极其精妙的观察。作者发现:即便用了DES,扩散进度在不同分子上并不是均匀的。有些稠环骨架"抗噪"(结构稳定,很多swap之后仍像分子),有些松散侧链"速溶"(很快就被打乱)。这意味着你在去噪时喂给模型的那个标量时间步 ,实际上并不是一个好指标——它只是"名义时间",不一定反映"这张图离真实分子有多远"。
于是CoCoGraph引入了第二个小模型——Time Model:
Diffusion Model:输入当前分子图 Gt+ 时间信号,输出每个可行DES操作的"应该undo的概率";
Time Model:输入当前分子图,预测归一化时间 (即这张图在扩散轨迹上的真实位置),然后把 tpred回喂给扩散模型来指导采样。
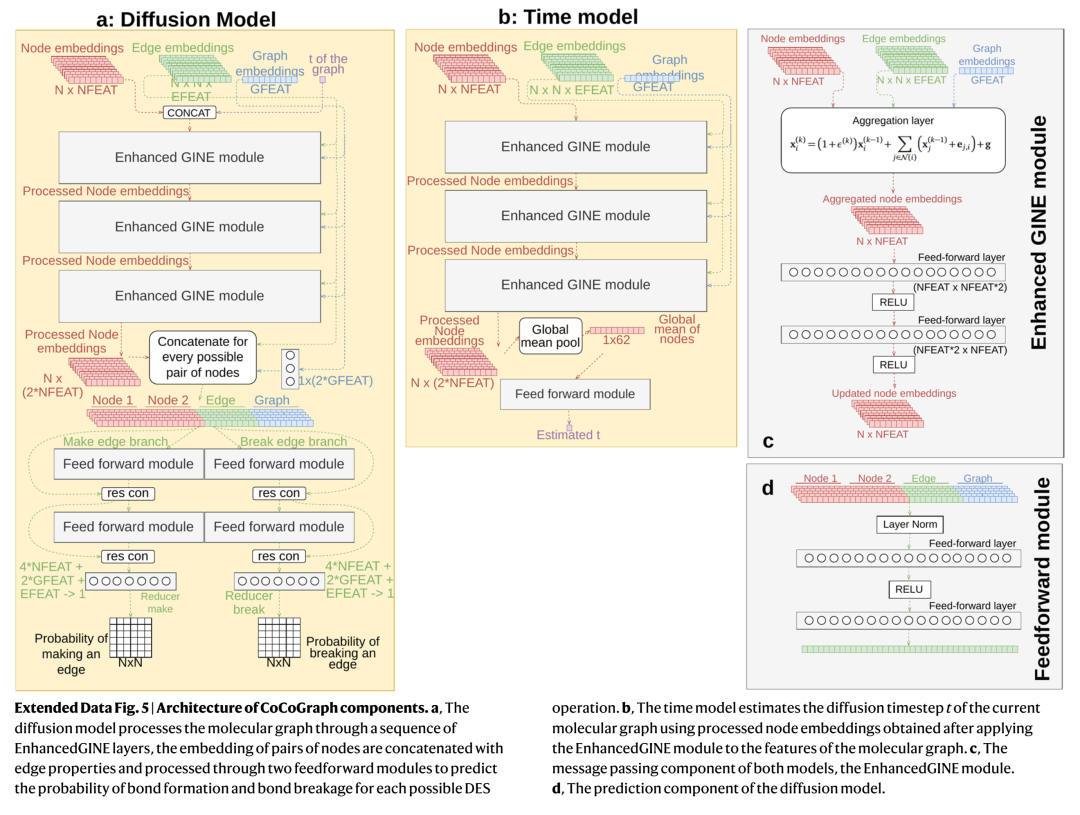
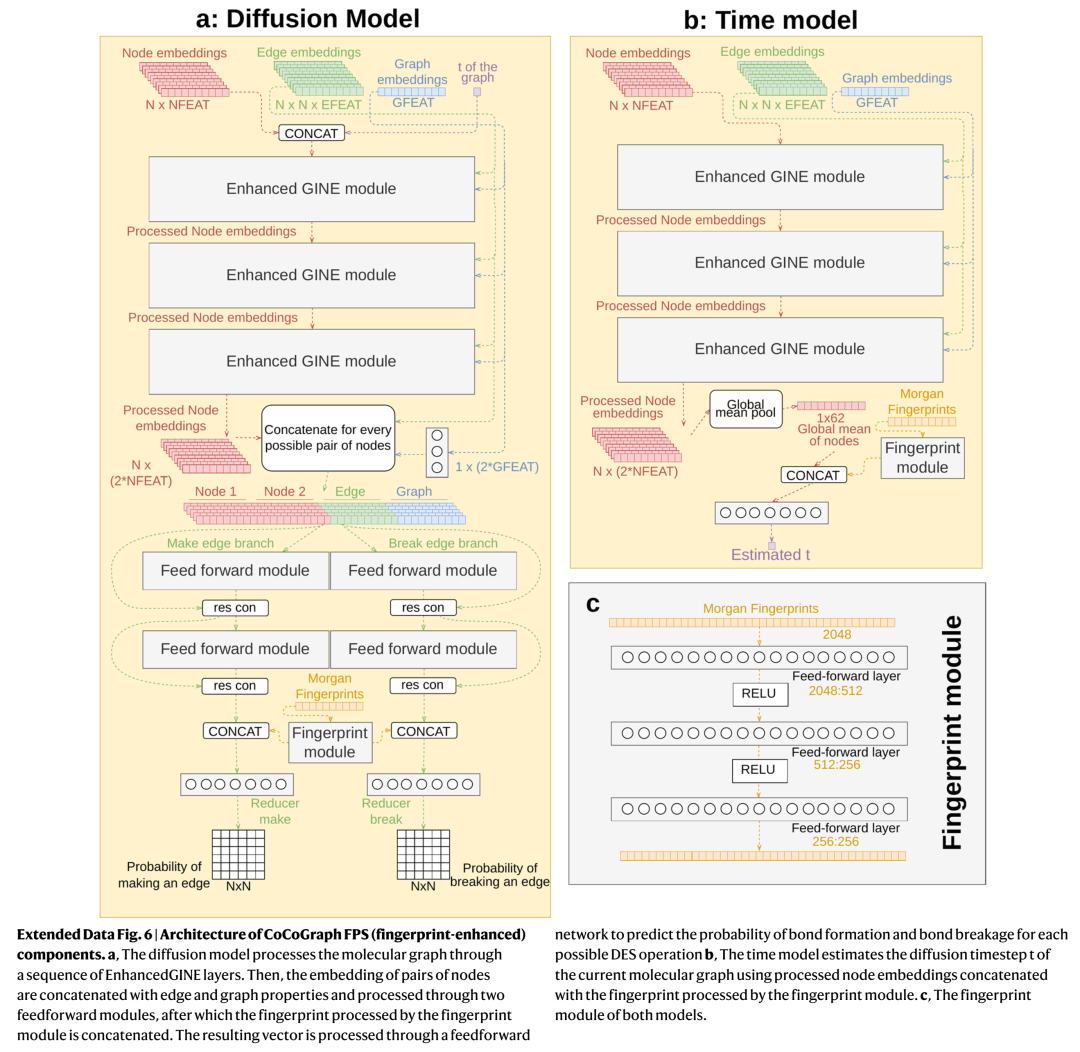
更关键的是,在最终采样输出时,CoCoGraph不是简单取轨迹末端,而是从整条去噪轨迹中选出 最接近0的那一帧——也就是时间模型认为"最像真分子"的那一步。这是一个非常经典的best-of-trajectory策略,但因为它依托于一个独立训练的时间预测器而非手工阈值,所以比固定schedule灵活得多。
消融实验也印证了这点:去掉时间模型(只用名义 )的FPS变体,KL divergence从96.3%掉到94.4%——协作机制带来的提升虽然不如约束本身那么决定性,但在分布保真度上是实打实的。
03 Benchmark结果
下表是整个工作的硬核名片。注意看 Valid (%) 那一列:
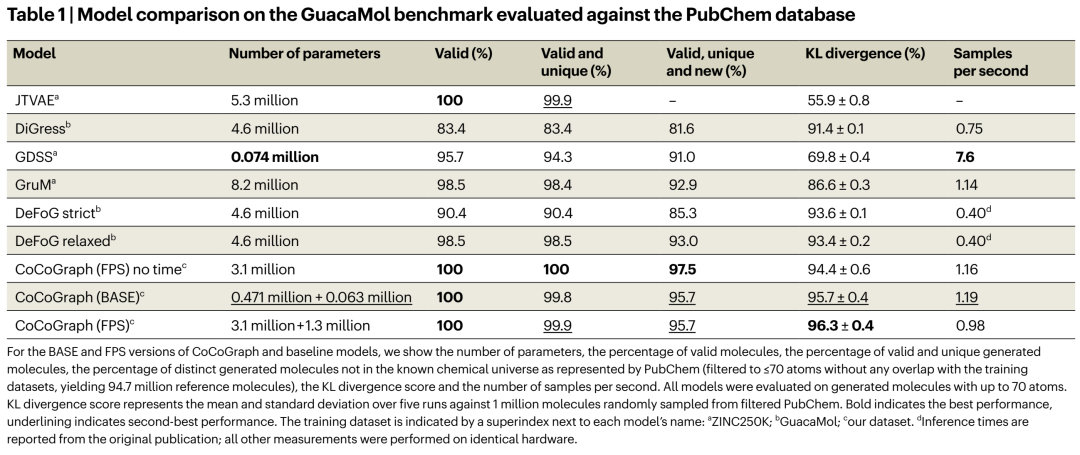
几个要点值得停下来品:
第一,100% validity 不是靠后过滤堆出来的,是 by construction。 这在分子生成里是真正的奢侈品——意味着你可以信任采样输出,不需要有效性检查-重采样的循环,这也是CoCoGraph吞吐可观的原因之一(BASE 1.19 mol/s 在单卡4090上)。
第二,KL divergence(越高越好,衡量属性分布与PubChem参考的重合程度)达到95.7%~96.3%,显著高于所有baseline。 特别值得注意的是GuacaMol的KL得分对"属性分布覆盖"很敏感——高分意味着生成的分子不仅在合法性上过关,而且在分子量、LogP、芳香环数、复杂度等维度上呈现出接近真实化学宇宙的texture,而不是塌缩到某个窄区域。
第三,参数量的对比几乎带着一点讽刺意味。 BASE版总参仅 ~534K(扩散471K + 时间63K),比4.6M的DiGress小近十倍,却做到了后者做不到的事。原因也直白:当你把硬约束从学习负担中剥离出去,模型只需要专注学"分子连接模式的统计结构"——而这恰恰是小GNN就能做好的事。
属性层面的逐维对比进一步揭示了差异。下图展示了CoCoGraph FPS在GuacaMol十个关键属性上与各baseline的分布对比(实线为PubChem参考):
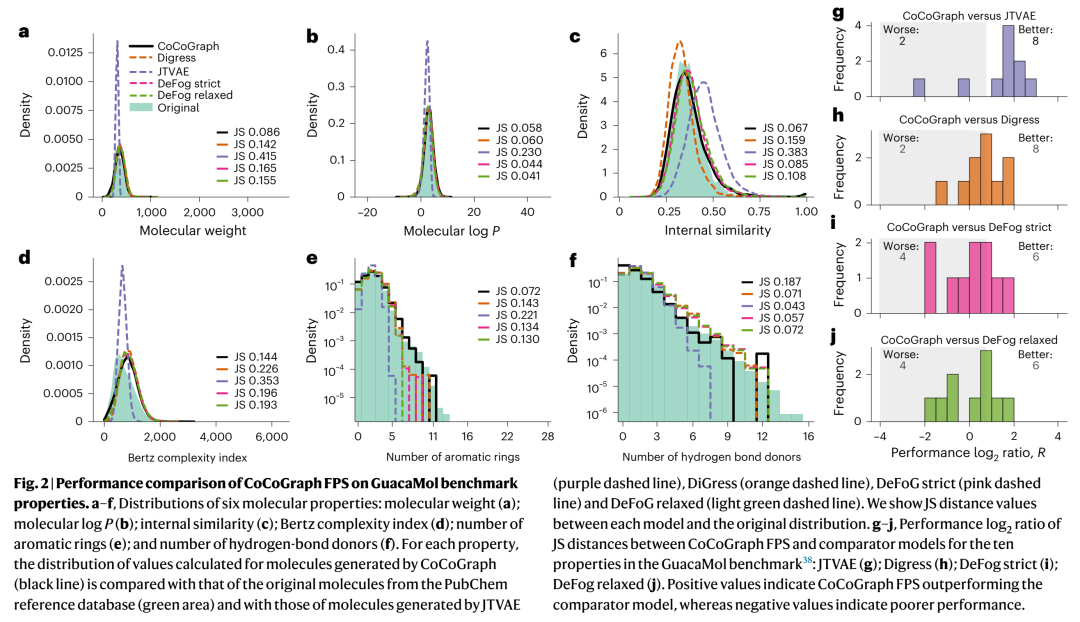
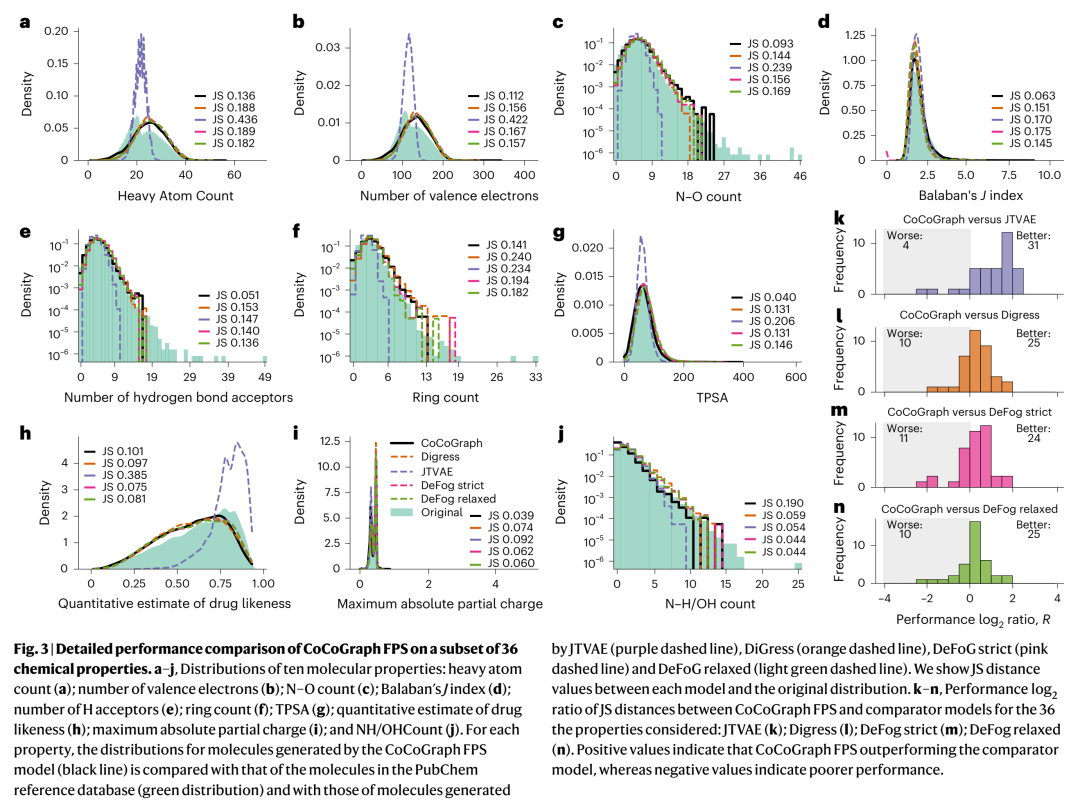
可以看到在 Molecular Weight、Bertz Complexity、#Aromatic Rings、Internal Similarity 这类结构性指标上,CoCoGraph的分布曲线贴得最紧。而在LogP这样的"经典易拟合"属性上,DeFoG略有优势——这其实也合理,因为DeFoG走flow-matching路线,对连续化表示更友好。但综合36个属性的大panel(含拓扑、电子、VSA等),CoCoGraph在 66.6%+ 的属性上胜过每个baseline(见Extended Data的全面JS-distance对比),这才是更扎实的结论。
04 820万分子的"合成宇宙"与一场分子图灵测试
效率允许他们干一件漂亮的事:用单张中端GPU跑出 8.2 million个合成分子 的数据库(冗余率仅7.1%,约7.3M全新结构不在PubChem中),并把数据集公开在Zenodo(10.5281/zenodo.18939448)。
但真正让这个故事出圈的是他们设计的 Turing-like test。不是让模型跟另一个模型打分互搏,而是让121位有机化学/生化领域的真实专家来判断:给你一对分子式完全相同的分子,一个是真实数据库里的,一个是CoCoGraph生成的——你猜哪个是真的?
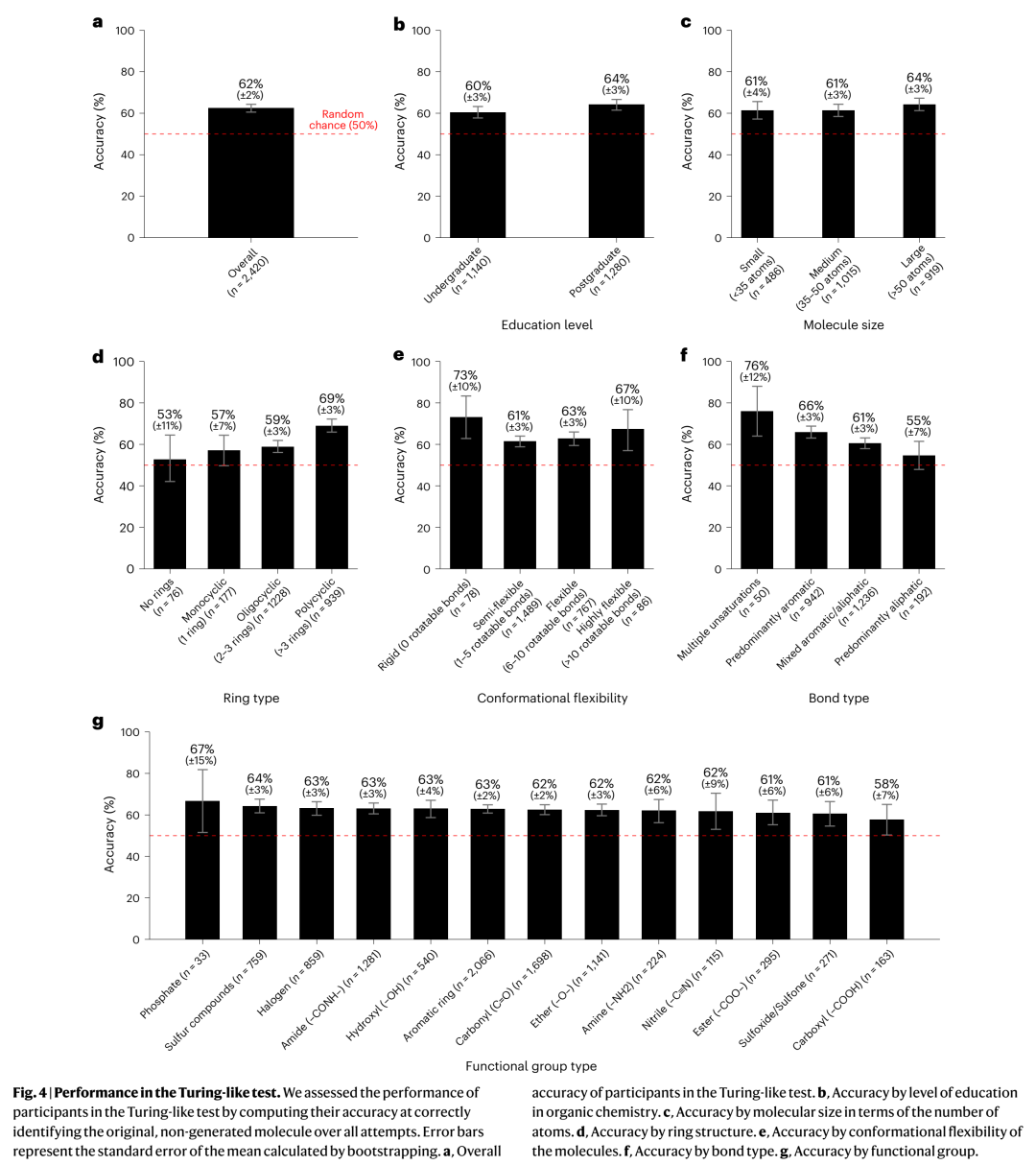
全局准确率 62%——显著但贴近50%。本科生组60%,研究生组64%,差距很小。更有趣的是分层分析:
无环/高度脂肪族 分子对的判断精度直接兼容随机猜测(50%);
大分子稍好辨(更多结构线索可抓),但也没有哪类分子出现"系统性露馅";
Bayesian model selection甚至偏好"参与者无法区分"的模型假设。
这个结果的解读需要克制:它不等于"生成分子与真分子不可区分"的数学证明,但它给出了一个非常强的信号——CoCoGraph产出的结构在专家的视觉-化学直觉层面上已经跨过了"明显假"的阈值,进入了需要专业知识+运气才能分辨的灰色地带。对AI+化学交叉领域而言,这种来自domain expert的"人肉判别器"远比又一个自行报告的FCD分数有说服力。
05 Inpainting:把分子生成变成"脚手架上的装修"
除了无条件生成,作者还展示了 inpainting-based conditional generation 的应用路径:从训练集中提取常见碎片库(2–5 / 6–15个重原子的断开片段),将选定碎片以随机噪声图的形式挂接到一个固定核心(如扑热息痛/paracetamol)的附着点上,然后只在碎片区域做masked DES去噪、核心骨架冻结。
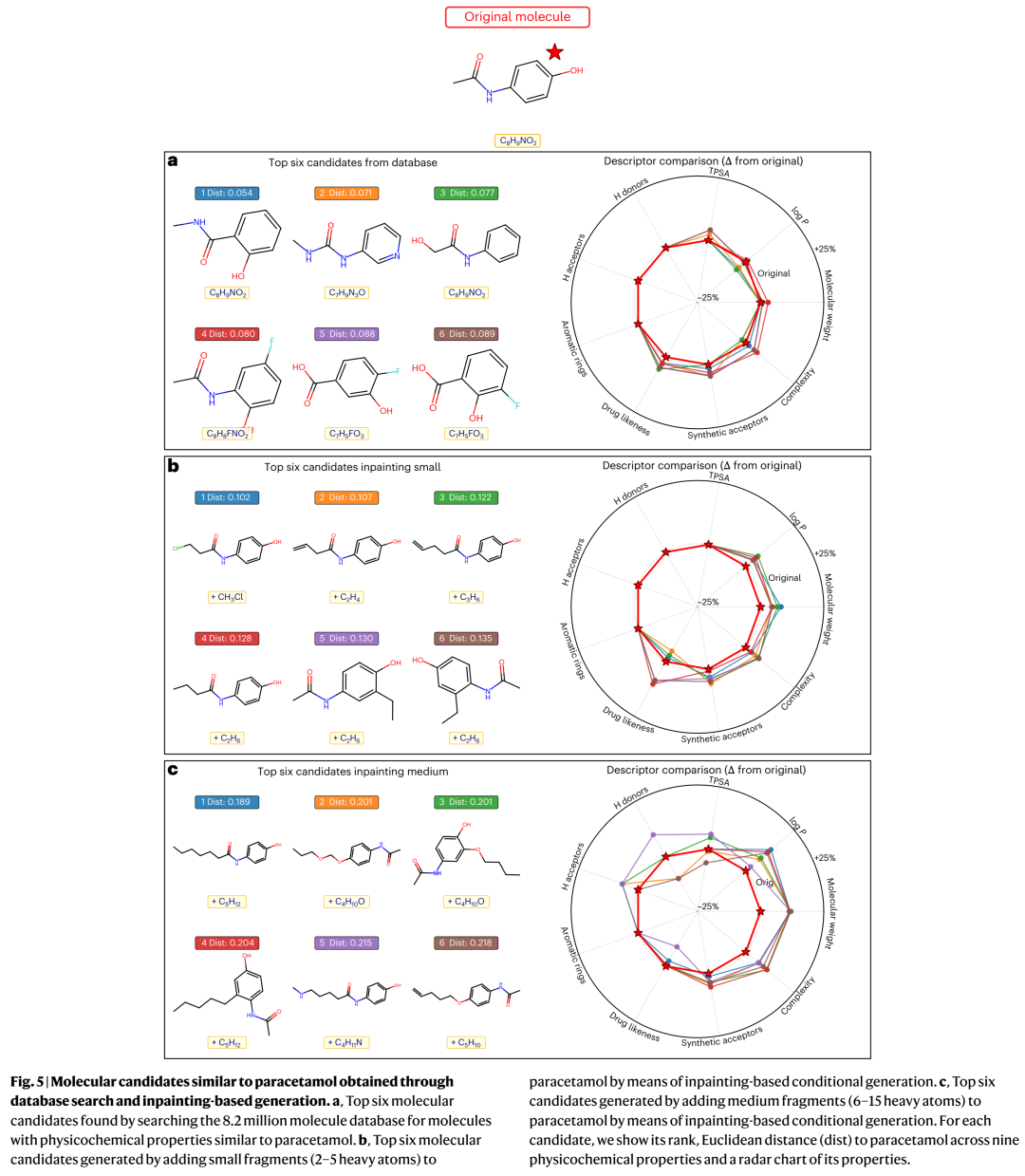
这在药物发现的lead optimization语境下非常自然——你要保留结合位点锚定的母核,只在边缘探索取代基变体。CoCoGraph的DES框架恰好让"局部编辑+全局价键合法"变得天然可操作:掩码把DES的选择空间限制在涉及至少一个碎片原子的边上即可。生成的候选在9维理化空间中距paracetamol的欧氏距离排名靠前,且结构多样——这不是纯粹的相似性搜索,而是在合法化学空间的指定邻域里做受控采样。

06 对AI+交叉学科研究者的启发
① "硬约束前置"永远比"软惩罚后修"高贵。 CoCoGraph本质上是在提醒图生成社区:如果你的问题域有已知的组合约束(度序列、连通性、对称性……),别全推给Transformer的参数——设计一个满足约束的转移核(DES就是例子),让模型学到的每一bit都花在刀刃上。图扩散里"什么样的噪声过程"常常比"网络多深"更决定上限。
② 双模型协作也可以极不对称。 时间模型仅63K参数,却纠正了"名义时间 ≠ 真实进度"的misalignment。这跟扩散社区正在复兴的 self-conditioned/ learned noise schedule思路同源——但CoCoGraph把它包装成了一个干净的两两协同架构,且明确给出了消融证据。轻量辅助网络做"状态估计",主力网络做"策略",这个pattern在很多科学生成的setting里都能复用。
③ 评估不能只活在benchmark里。 36个属性panel + 820万规模数据集 + 121人专家盲测——这篇工作的方法论完整度本身就是礼物。尤其对做AI for Science的人来说,最终的裁判不是另一个神经网络的距离函数,而是domain expert能否被你生成的伪物骗到(哪怕只骗到62%)。
如果你在做图扩散、分子设计、或任何"生成对象有组合硬约束"的交叉方向,CoCoGraph的DES转移核 + 轻量时间预测器的组合,非常值得放进你的工具箱里拆一遍。



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢