
【论文标题】MELINDA: A Multimodal Dataset for Biomedical Experiment Method Classification 【作者团队】Te-Lin Wu, Shikhar Singh, Sayan Paul, Gully Burns, Nanyun Peng 【团队介绍】Nanyun Peng是加利福尼亚大学助理教授, 主要研究方向是自然语言处理,近年常担任计算机顶级会议ACL、EMNLP等的区域主席 【发表时间】2020.12.16 【推荐理由】论文收录于AAAI-2021会议,研究人员引入一个新的数据集MELINDA,用于多模态生物医学实验方法分类。
MELINDA是以全自动远程监督的方式收集的,其中的标签是从现有的策划数据库中获得的,而实际内容则是从与数据库中每条记录相关联的论文中提取的。研究人员对各种最先进的自然语言处理和计算机视觉模型进行了基准测试,包括只取标题文本或图像作为输入的单模态模型以及多模态模型。广泛的实验和分析表明,多模态模型尽管表现优于单模态模型,但仍需要改进,尤其是以少监督的方式将视觉概念与文本语言建立在一起,以及更好的迁移到低资源领域。研究人员将数据集和基准全部公开,以促进未来多模态学习的研究,特别是激励在科学领域的应用进行有针对性的改进。
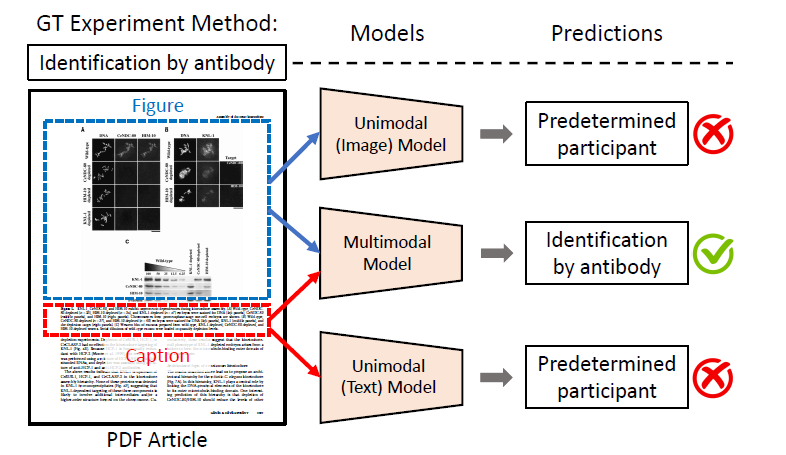
图:MELIND数据集以及生物医学实验分类任务模型图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢