

投稿作者:新南威尔士大学团队
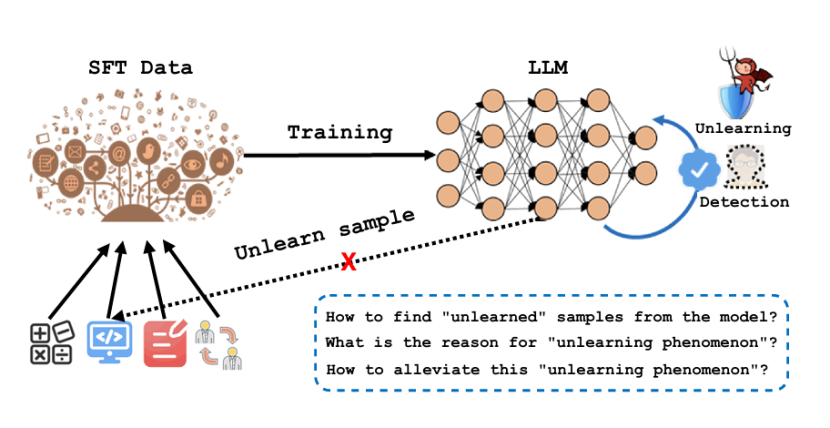
监督微调(SFT)是当前大语言模型(LLM)应用落地的核心环节。然而,每个做过 SFT 的工程师几乎都遇到过这样一个反直觉的现象:
训练 loss 已经收敛、benchmark 分数在涨、所有超参都调整到了最佳状态,但当把训练集重新输入模型让它逐条回答时,总有一批样本模型就是答不对。
这不是个例,不是超参问题,也不是数据噪声问题,而是 SFT 范式中一个长期被忽视的系统性缺陷。
这个问题之所以长期未被正视,核心原因在于缺乏有效的检测工具。SFT 的输出是自由文本,语义等价但字面不匹配的答案(如“发烧 38 度需就医”vs“体温 38 度要去看医生”)无法通过简单的字符串匹配来判定对错,导致“模型到底学会了没有”始终是一个模糊问题。
在这项工作中,新南威尔士大学团队及其合作者首次将这一现象系统化为不完全学习现象(Incomplete Learning Phenomenon,ILP),并提出了一套完整的「检测→归因→干预」三段式框架。
图|不完全学习现象,SFT 后训练集回测仍有大量答错样本。
相关研究论文已发表在预印本网站 arXiv 上,并被 AI 顶会 ACL 2026 收录。

论文链接:https://arxiv.org/abs/2604.10079
在检测层面,研究团队设计了 MC 转换(Multiple-Choice Conversion,多项选择转换)方案,将每条 SFT 样本转化为选择题,用 pass@5 多轮采样取代自由文本匹配,使 ILP 成为可量化、可复现的研究对象。
在归因层面,他们将未学习样本分为五类根因,预训练知识缺失(根因 I)、预训练知识冲突(根因 II)、数据内部矛盾(根因 III)、左侧遗忘(根因 IV)、优化不足(根因 V)。
在干预层面,为每个根因设计了针对性方案,其中最优方案(CPT 知识增强)在 MedQA 上取得了 12.5% 的提升,而传统加 epoch 方案仅提升 1-2%,差距达一个数量级。

图|“检测→归因→干预”三段式诊断框架。
这篇论文的价值不限于发现了一个新现象,还在以下三个层面具有重要意义:
学术层面:首次将“训练集内学习完整性”确立为 SFT 评估的一个独立维度,打破了“loss 收敛 = 学习完成”和“benchmark 涨 = SFT 成功”两个隐含假设。ILP 不是过拟合、不是灾难性遗忘、不是数据噪声,是一个独立的、新的研究问题。
工程层面:提供了每个 SFT 团队都能立即部署的诊断工具和修复策略。最基础的“打乱数据顺序+自适应epoch停止”为零成本优化,而完整的诊断框架可以系统性降低 15% 左右的未学习率。
方法论层面:展示了“先检测、再归因、后干预”的因果研究范式在 LLM 训练领域的应用。5 种干预方案同时也是对 5 种根因假设的因果验证,方案无效则归因错误,形成可证伪的闭环。
研究方法
1.检测方法: MC 转换与 pass@5 判定协议
SFT 输出是自由文本,无法直接判断“学会了没有”。论文提出的创新解决方案是 MC 转换(Multiple-Choice Conversion),将每条训练样本的正确答案设为选项 A,用 GPT-4 构造 3 个语义合理但错误的干扰项(B/C/D),将开放生成问题转化为选择题判定问题。
为避免单次解码的随机性导致的误判,研究采用多轮采样策略(pass@5):每个 MC 问题独立采样 5 次(温度 0.7),5 次中答对 ≤1 次(pass@5<0.2)判定为未学习。消融实验显示,pass@5 与 pass@10 的 Kappa 系数高达 0.93,说明 pass@5 已足够稳定。同时,通过跨模型交叉验证(Qwen、LLaMA、OLMo2 三模型同时检测),确认了 ILP 不是某个特定模型的偶发现象,而是数据本身的固有特征。
干扰项的质量控制是 MC 转换方案中经常被忽视但至关重要的一环。作者测试了三种干扰项构造策略:随机替换关键词测出 19.7% 的未学习率(干扰项太简单,模型靠排除法蒙对了很多实际没学会的样本,高估了学习率、低估了 ILP),同领域硬负例只测出 11.8%(干扰项太接近正确答案,模型答错不一定代表没学会,高估了 ILP)。逐级构造方案平衡了这两个极端——一级干扰替换关键实体、二级干扰颠倒因果关系、三级干扰引入同领域不同事件的混淆。干扰项通过四级质量过滤:语义合理性 >0.7、与正确答案区分度 >0.3、与领域事实一致性、人工抽查 10% 样本。将全部干扰项重新生成后重复检测,与原始结果的 Kappa 系数为 0.91——说明干扰项的具体选择对总体结论影响不大。
检测方法的稳定性验证同样充分:跨温度验证(0.5→14.8%、0.7→15.3%、0.9→15.6%,差异在 ±0.5% 以内)、重测信度验证(隔一周重新检测,Kappa=0.89)、跨模型验证(三模型判定差异 ±0.8% 以内)。这些验证保证了 ILP 检测的不是检测噪声,而是数据本身的固有特征。

图|MC 转换示例:将 SFT 监督响应转化为多项选择格式,保留正确答案为选项 A,构造 3 个语义合理但错误的干扰项。
2.归因框架:五大根因的决策树
每个未学习样本按两步决策树进行归因:
第一步(模型层面):评估基模型在SFT前对该知识的掌握状态。
Zero-shot 准确率 < 25%(随机水平)→ 基模型不具备该知识 → 根因I:知识缺失;对错误答案置信度 > 0.9 → 基模型有相关知识但方向错误 → 根因II:知识冲突。
第二步(训练过程层面):如果基模型具备相关知识但SFT后仍未学会。
训练集中存在语义相似度 > 0.85但标签矛盾的样本对 → 根因III:数据内部矛盾;样本位于训练序列前25%位置 → 根因IV:左侧遗忘;难样本loss仍在下降而训练已停止 → 根因V:优化不足。
每个根因都有明确的、可计算的诊断信号,使归因从「模糊判断」变成了可重复的计算流程。
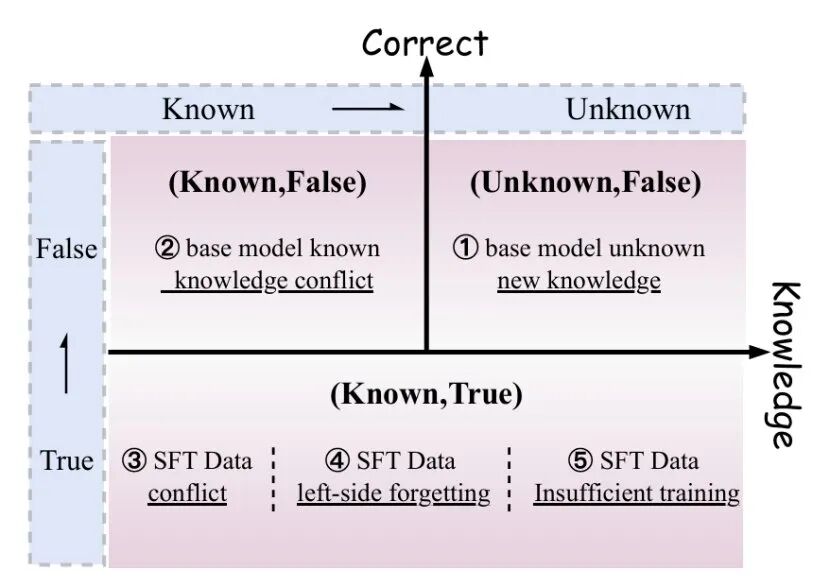
图|未学习样本归因框架——横轴“基模型是否已知该知识”,纵轴“SFT 标签是否正确”。
3.验证方法:OLMo2 开源全链路溯源
研究利用 AI2 完全开源的 OLMo2-7B 模型及其完整预训练语料 Dolma(5T token),对根因 I 和根因 II 做了物理层面的溯源验证。操作流程包括:从被判定为根因 I/II 的未学习样本中提取核心知识三元组→用 Elasticsearch 在 Dolma 5T token 中做三层检索(精确匹配、语义模糊匹配、人工判定)→判定该知识在预训练语料中的覆盖状态。OLMo2 溯源的核心发现通过量化数据呈现:检索结果分三个层级解读:
第一层精确字符串匹配显示,根因 I(知识缺失型)样本的精确匹配率仅 8.2%,说明模型在预训练语料中几乎没见过这些知识的准确表达方式;根因 II(知识冲突型)样本的精确匹配率为 21.7%,高于根因 I,但这些匹配全部以语义冲突的形式存在。
第二层语义嵌入模糊匹配发现,根因 I 的 72.5% 和根因 II 的 63.8% 样本能在更广泛的语义空间中找到相关语料,但根因 I 的匹配内容信息不完整,根因 II 的匹配内容与 SFT 标签存在矛盾。
第三层人工判定确认了最终状态:19.3% 的根因 I 样本在 5T token 的 Dolma 语料中完全不命中(即预训练知识缺失),14.5% 的根因 II 样本以冲突形式存在于预训练语料中(即预训练知识冲突)。两种根因都需要 CPT 干预,但所需数据性质完全不同,根因 I 需要补充缺失知识,根因 II 需要纠偏错误信息。
4.五种干预方案
五种干预方案针对不同根因设计。
根因 I(知识缺失)效果最显著,通过检索权威外部知识进行 CPT 再 SFT,在 MedQA 上提升了 12.5 个百分点,说明补充缺失知识是修复 ILP 最高杠杆的手段。
根因 II(知识冲突)的修复效果相对有限(ARC +2.8%),因为纠偏错误表征比补充新知识更困难,需要更精细的 CPT 数据筛选。
根因 III(数据内部矛盾)通过动态分桶将矛盾样本隔离到不同 batch,解决了标签冲突导致的梯度相互抵消问题,总体提升了 2.8%。
根因 IV(左侧遗忘)的修复效果最为明显——全局打乱+动态重采样使前 10% 数据 ROUGE-L 提升了 29%,说明数据顺序对学习效果的影响被严重低估。
根因 V(优化不足)通过渐进 Epoch 策略(验证不涨即停)实现了 1.8%-1.9% 的提升,虽然幅度不大,但几乎不增加额外计算成本。
研究结果
1.ILP 的普遍性:15.3% 的平均未学习率
在 10 个标准 SFT 数据集上,覆盖 Qwen(1.8B/7B/14B)、LLaMA(3B/8B)、OLMo2(7B)等模型家族的检测结果显示:
未学习样本呈不均匀分布:罕见实体样本的未学习率达 23.4%,多步推理达 19.8%,而简单陈述仅 8.1%。模型「选择性放弃」的恰恰是最有价值、标注成本最高的复杂样本。
2.归因结果:预训练语料贡献了约 1/3 的 ILP
在 OLMo2-7B 的溯源验证中,研究发现:通过三层检索对根因 I/II 样本在 Dolma 5T token 语料中进行全链路追踪,19.3% 的根因I样本在预训练语料中完全不存在(零命中),这意味着模型在预训练阶段从未接触过这些知识,SFT 却要求模型学会——巧妇难为无米之炊;14.5% 的根因II样本在预训练语料中以冲突形式存在,即模型在预训练中形成的知识版本与 SFT 标注不一致,产生了知识竞争;合计 33.8% 的 ILP 可直接追溯到预训练语料的覆盖缺陷。
超过 1/3 的 ILP 可在预训练语料中找到直接物理证据。冲突案例有一个明显模式:Dolma 中的信息多来自较早的时间窗口,而 SFT 标注的是最新信息,模型在预训练中形成的「旧事实」强先验使 SFT 难以纠偏。
五大根因在各数据集上的分布差异,进一步揭示了 ILP 的病因结构,不同数据集的ILP病因结构截然不同。
MedQA(医学问答)的主要病因是根因 I(8.3%),预训练知识缺失占比最高,医疗领域知识更新快,预训练语料覆盖不足;LegalBench(法律)的根因 I(6.1%)和根因 II(4.8%)均较高,法律领域既有专业术语缺失又有版本冲突问题;ARC(推理)的主要病因是根因 II(5.5%),推理型知识在预训练中更可能以矛盾形式存在;Alpaca(指令)的主要病因是根因 IV(5.2%),指令数据量大且训练顺序影响明显,左侧遗忘问题突出;ShareGPT(对话)的主要病因是根因 III(4.8%)和根因 IV(4.3%),对话数据中语义相似的样本容易产生标签矛盾。
总体规律是:知识密集型领域主要病因在预训练语料层面(根因 I+II),指令和对话数据主要病因在训练过程层面(根因 III+IV+V)。不同数据集的 ILP 结构截然不同,这正是「对症下药」的实验依据。
3.干预效果:CPT vs 加 epoch 的降维打击
为每个根因设计了针对性方案并做了对照实验,关键结果如下:
根因 I 的最优方案 CPT 知识增强在 MedQA 上提升 12.5%,而对照方案加 epoch 仅提升 1-2%,两者差距达一个数量级——这是论文最核心的发现之一:SFT 自身能力有限,知识缺失只能靠 CPT 补充。根因 II 的 CPT 校准仅提升 2.8%,且对照方案加 epoch 效果同样弱,说明知识冲突比知识缺失更难修复,纠偏比补新更难。根因 III 的动态分桶提升 2.8%,对照的直接删除方案也能提升 1.5%,说明数据内部矛盾对学习有实质性拖累,但隔离比删除更优(保留了数据量)。根因 IV 的全局打乱+重采样效果最为惊人,前 10% 数据 ROUGE-L 提升 29%,而加 epoch 几乎无效,说明左侧遗忘本质上是数据顺序问题,不是训练量问题。根因 V 的渐进 Epoch 提升1.8%-1.9%,虽然幅度不大但几乎零成本,是一个白捡的优化。
值得注意的是,CPT 也有代价——在 OLMo2 上,CPT 后 MMLU 下降了 2.1 个点(65.2→63.1),即「表征重校准」效应,提示 CPT 应作为靶向手术刀精准使用,而非盲目施加。
不足与未来方向
1.局限性
检测方法的评估 gap:MC 转换虽然精妙,但 MC 环境与自由生成环境不完全等价。模型可能在 4 选 1 中蒙对(基线 25%),也可能在 MC 中答错但在自由生成中输出部分正确信息。15.3% 是 ILP 的下界估计,实际未学习率可能更高。
根因的叠加效应:归因框架假设每个样本可映射到唯一根因,但实际中可能存在多个根因叠加的情况(如一个样本同时是「知识缺失」和「优化不足」)。论文采用优先级策略(先 I/II 后 III/IV/V),可能低估了训练过程层面根因的占比。
CPT 的泛化性:CPT 方案已在 Qwen、LLaMA、OLMo2 上验证有效,但最佳 CPT 数据配比(领域:通用=0.8:0.2)和 CPT 步数在不同领域和模型规模下可能需要调整,目前缺乏系统性的调参指南。
外部知识的可及性:CPT 需要检索外部权威知识,对于某些高度专业或资源受限的领域(如小语种法律条文),多源检索的覆盖率和质量可能不足。
2.未来研究方向
从诊断到预防:当前框架是「诊断-治疗」范式,下一步可发展为「预防」——在 SFT 开始前根据基模型 zero-shot 表征和高相似度样本对检测,预先生成「风险热力图」,提前调整数据策略。
实时监控集成:将 ILP 检测集成到 SFT 训练过程中,当检测到某个样本的未学习风险持续升高时,自动调整其采样权重或学习率,而非等到训练结束后才做诊断。
检测方法的泛化:探索不依赖 GPT-4 生成干扰项的自监督检测方案,降低检测方法对第三方模型的依赖,提升在高度专业化领域的适用性。
跨训练范式的 ILP 研究:ILP 是 SFT 的专属问题,还是在 RLHF(基于人类反馈的强化学习)、DPO(直接偏好优化)等其他对齐方法中也存在?这是一个开放且值得探索的问题。
多根因联合优化:当前五种策略是独立使用的,未来可研究多种策略联合使用时的协同效果和最优组合顺序。例如,CPT + 动态分桶是否产生叠加增益?初步实验显示CPT + 打乱重采样的联用可将 ILP 降至 4.7%,但五种策略的完整组合矩阵尚未系统探索。
低成本工业部署方案:MC 转换需要 GPT-4 生成干扰项(每次约 $0.01/样本),全量回测的成本较高。开发基于规则或小型模型的低成本检测方案是推动工业落地的关键方向。
ILP 与幻觉的内在关联:初步实验发现 ILP 样本中有较高比例涉及安全敏感知识且与模型生成幻觉存在相关性。15.3% 的训练集未学习样本是否与模型的幻觉行为存在因果关系?这是一个值得深入探索的方向。
跨语言 ILP 研究:当前实验集中在英文数据集,中文、日文等低资源语言场景中的 ILP 比例和根因分布是否不同?预训练语料更稀疏的低资源语言 ILP 率可能更高(预计在 20%-25%),对多语言模型开发有直接指导意义。
行动建议
如果你正在从事 SFT 相关工作,建议从以下三项行动开始:
1. 做一次 ILP 审计:在自己最新的 SFT 模型上运行 MC 转换 + pass@5 检测,了解 ILP 基线。比较不同数据集、不同领域的 ILP 差异。 2. 诊断根因分布:对未学习样本执行归因决策树,统计五大根因在场景中的分布——根因 I >30% 优先 CPT,根因 IV>20% 优先打乱顺序。 3. 从低成本策略开始修复:先做全局打乱和动态分桶(零成本),再评估是否需要启动 CPT(较高成本)。不要一上来就加 epoch——先诊断再干预。
正如论文作者所言:“SFT 不是银弹,ILP 是一个系统性现象。理解它、检测它、修复它,是让 SFT 从经验驱动走向诊断驱动的关键一步。”
对 SFT 实践者最后的建议:ILP 是你工具箱中的一个新工具,不是对现有 SFT 实践的否定。在下一个 SFT 项目中,花半天时间做一次 ILP 审计——你将获得对训练数据的全新视角,这是提升模型质量性价比最高的投入。
本文以系统解读论文核心发现为目标,从现象到方法到结果到局限层层展开。理解 ILP,就是理解 SFT 的边界在哪里,以及如何在这边界内做到最好。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢