
AIGB-Pearl团队 投稿
量子位 | 公众号 QbitAI
阿里妈妈生成式出价算法AIGB,升级了。
在线广告中,自动出价(Auto-bidding)是优化广告主投放效果的核心算法。
它需要根据广告主的营销目标,在高动态、非平稳的流量上进行实时竞价决策,以实现全投放周期内的广告投放效果最优。
本质上,自动出价是一个在高不确定性环境下进行的长序列决策难题,传统离线强化学习方法常因“自举”机制导致严重累计误差,难以保证长序列的训练稳定性和效果。
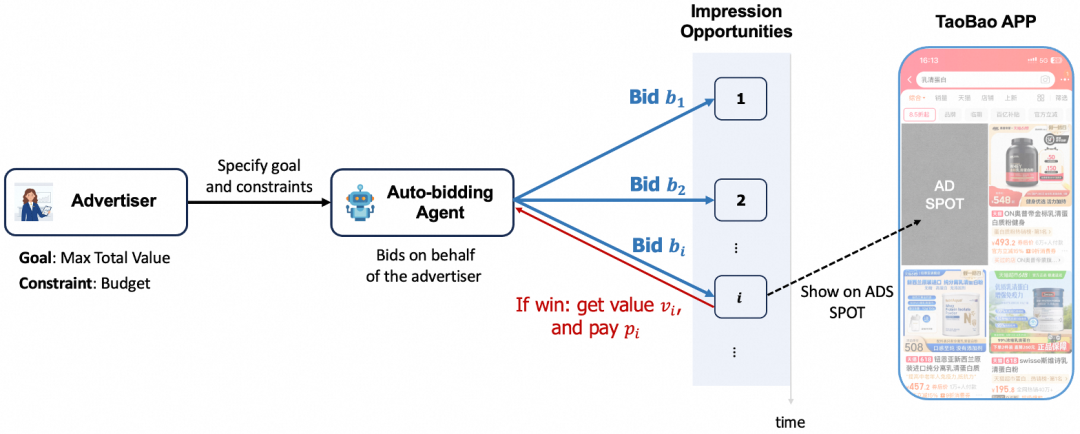
*自动出价为每个广告主构建一个出价Agent,在海量流量上进行自动出价以优化整体投放效果。
2023年,阿里妈妈将生成式AI引入自动出价任务中,首次提出「生成式出价算法」(AI-Generated Bidding, AIGB),创造性地将这一复杂的序列决策问题重构为“条件生成”任务,有效规避了离线强化学习算法面对长序列决策时累计误差较大的痛点。
凭借卓越的训练稳定性与性能表现,迅速刷新行业标杆,成为领域SOTA。
然而,初代AIGB遵循“训练时模仿,应用时外推”的范式:
一方面模仿学习性能上限受制于训练数据的分布边界; 另一方面,在新条件下的外推生成过程缺乏反馈闭环,这种「开环」决策机制导致轨迹质量难以保障,并且容易产生异常生成结果。
2025年初开始,阿里妈妈联合清华大学自动化系季向阳教授团队提出了基于强化学习后训练的增强版AIGB算法:AIGB-Pearl(Planning with EvaluAtor via RL)。
针对初代模型的“缺乏反馈”困境,AIGB-Pearl引入了基于评估器的强化学习后训练机制,构建起“生成-评估-优化”的「闭环」反馈体系。
特别地,他们从理论层面推导并实施了Lipschitz连续性与KL散度的双重约束,为模型OOD挑战下的探索划定了严格的“安全边界”,从理论上保障了强化学习训练的鲁棒性。
2025年以来,AIGB-Pearl在阿里妈妈全站推场景上全量落地,历经三次线上迭代,累计为全站推带来广告消耗+9%/GMV+10%。
相关成果已被ICLR 2026 Oral接受。

初代AIGB“训练时模仿,应用时外推”的局限性
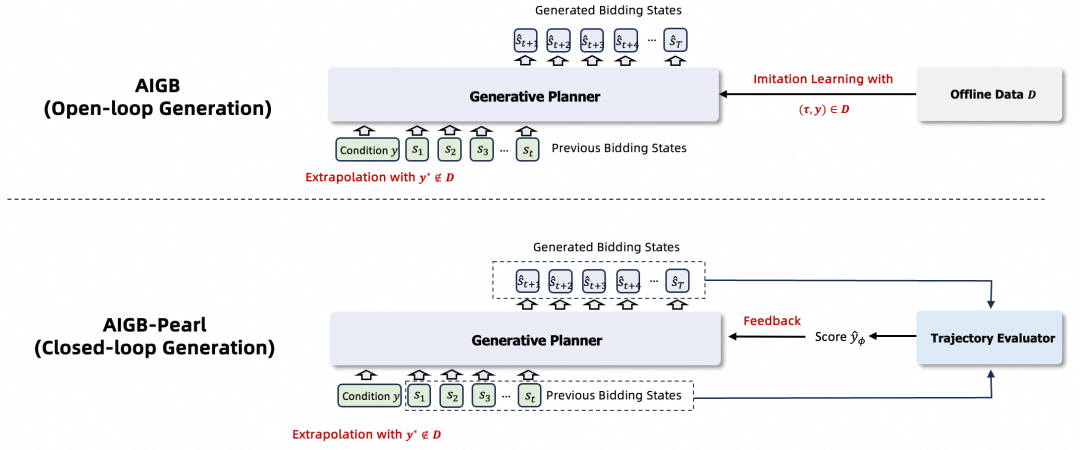
初代AIGB遵循“训练时模仿,应用时外推”的框架,其在训练阶段拟合历史数据𝓓中的轨迹条件分布:
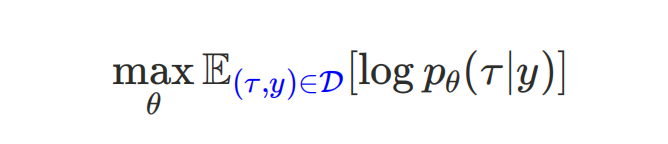
其中τ表示出价状态轨迹(例如消耗曲线,具体出价再经过逆动力学模型控制器得到),𝓎表示轨迹效果,𝑝𝜃表示生成式轨迹规划器;
而在线上应用时,为了追求更好的广告效果,目标条件往往会偏离训练集的覆盖范围,即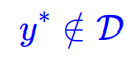 。
。
然而,初代架构面临双重困境:
一方面,模仿学习性能上限受制于训练数据的分布边界;
另一方面,在新条件下的生成过程缺乏实时反馈闭环,这种「开环」决策机制导致轨迹质量难以保障,并且容易产生异常生成结果。
一种自然的改进方式是引入强化学习进行后训练(RL Post-training),构建可以评估生成轨迹质量的评估器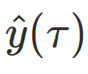 ,形成“生成-评估-优化”的「闭环」反馈机制,使模型基于评估分数进行自我修正。
,形成“生成-评估-优化”的「闭环」反馈机制,使模型基于评估分数进行自我修正。
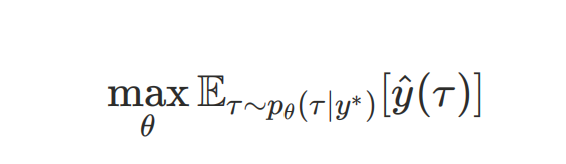
然而,该方法的高度有效性依赖于评估器的准确性。
特别是在无法在线交互训练的自动出价场景下,分布偏移问题(OOD)严重制约着训练有效性。
一种常用的缓解方法是引入KL散度正则化,但仍存在两大局限:
仅靠KL约束效力不足:KL仅约束模型在训练数据支持域(即𝓎∈𝒟)内的生成轨迹,当目标条件
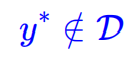 落在数据分布之外时,KL正则化无法保证推断阶段的可靠性,难以有效应对外推风险。
落在数据分布之外时,KL正则化无法保证推断阶段的可靠性,难以有效应对外推风险。缺乏理论保障:单纯的KL约束并未提供关于生成轨迹质量的严格理论保证,无法从数学层面确保生成结果的鲁棒性与最优性。
理论洞察:防止“分数迷信”需要双重约束
为了让评估器可靠地对AIGB模型生成进行反馈指导,他们从理论上分析模型评分L(θ)与实际性能J(θ)之间的偏差(Sim-to-Real Gap),并限定模型在Gap可控的范围内进行优化。
通过理论推导可以得出:
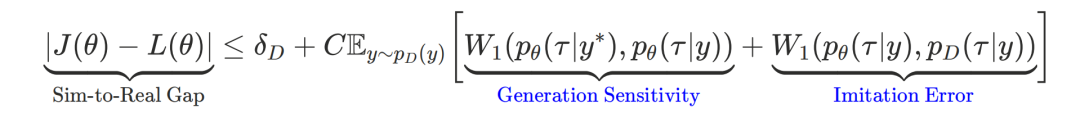
其中δD是Evaluator在训练集上的误差,可以通过训练控制在较小值;C为常数,与任务本身有关。
因此要控制Sim-to-Real Gap,需要约束上式中的两项Wasserstein距离,其中:
第一项约束旨在限制模型生成结果对于条件外推的敏感度。
这一设计直观且必要,弥补了标准OOD正则化方法被忽视的关键盲区:
在生成式模型进行外推时,需要确保生成结果整体上的平滑性,以防止输入条件的微小变化引发的震荡。
为此,他们通过限定模型的Lipschitz常数来控制敏感度,并证明了第一项Wasserstein距离的上界可由模型的Lipschitz系数界定。
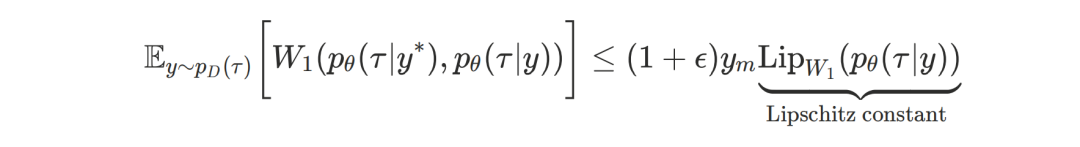
第二项约束旨在限制模型在数据集内拟合的误差。
这与标准OOD正则化理念一致,且可以证明在AIGB场景下,仍可以通过限定KL距离的方式限定第二项Wasserstein距离,即若控制在𝓎∈𝒟条件下模型生成结果与数据集轨迹的KL散度不大于δK,则:
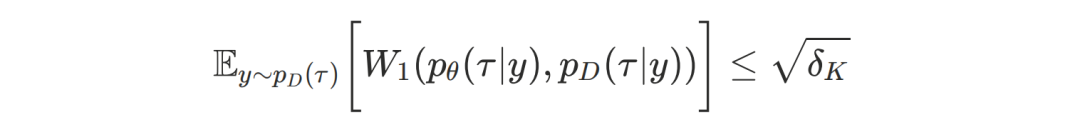
本质上,这两项约束让模型在外推时在数据集附近进行探索,并且Lipschitz约束让探索轨迹离中较好的轨迹附近探索,从理论上缓解了评估器偏差导致的OOD问题。
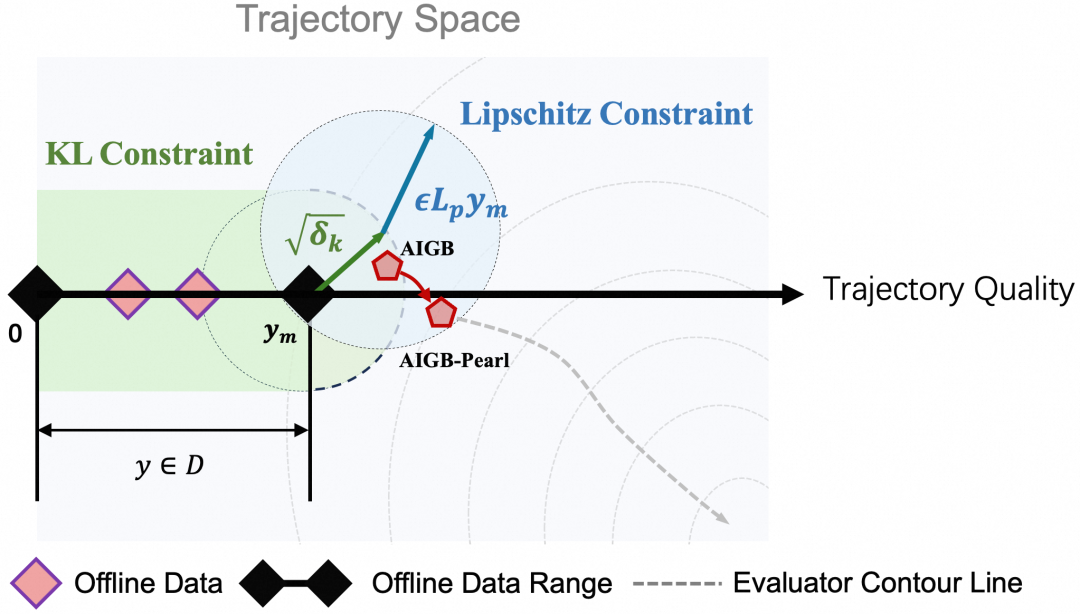
*AIGB-Pearl让模型外推轨迹在数据集中较好的轨迹附近探索,从理论上缓解了评估器偏差导致的OOD问题。
基于这一理论分析,团队提出基于Lipschitz+KL的双约束的强化学习生成式出价算法AIGB-Pearl(Planning with EvaluAtor via RL)。
其中,双重约束为RL的训练过程提供了数学层面的“安全边界”,实现AIGB的生成质量可靠提升。
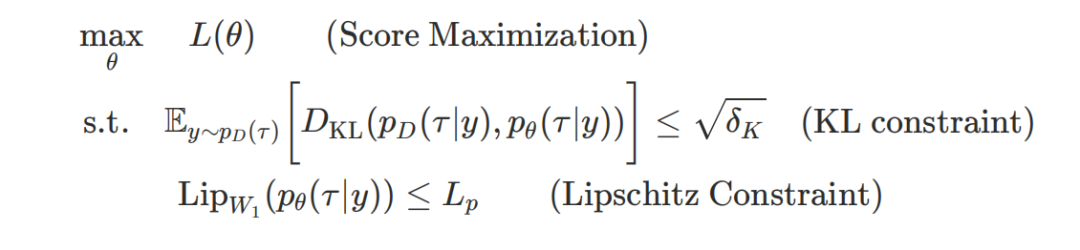
具体实现
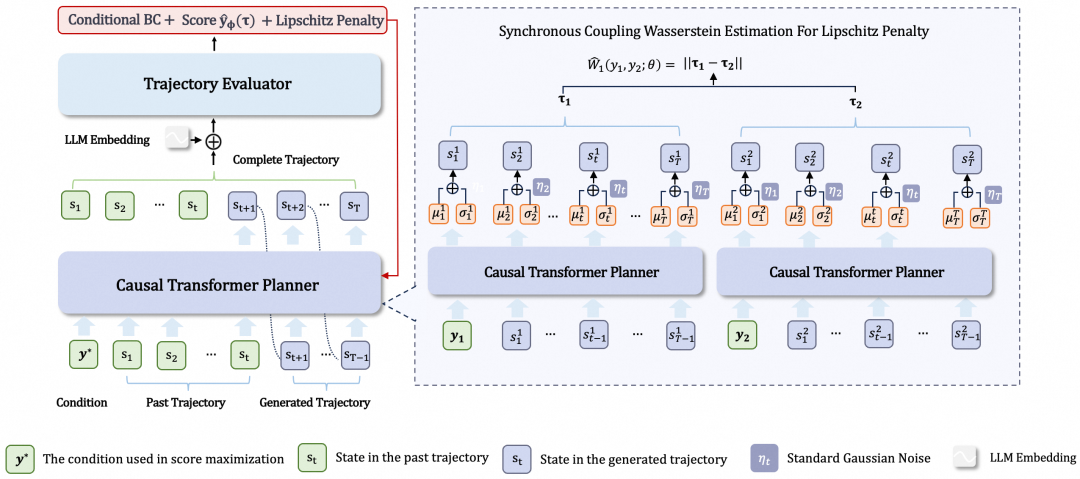 △AIGB-Pearl算法实现框架
△AIGB-Pearl算法实现框架
AIGB-Pearl算法框架主要由轨迹评估器和轨迹规划器两部分组成,采用先监督学习训练评估器,再在评估器指导下强化学习训练规划器的两阶段训练框架。
在具体设计细节上:
轨迹评估器(Evaluator)
评估器基于双向Transformer构建,并融合LLM提取的计划专属LLM Embedding以增强个性化信息。
训练采用Point-wise与Pair-wise联合Loss;其中Pair-wise样本通过同计划等分预算投放的预算AB实验数据构建,以控制混杂变量并获取高质量标签。
实验表明,LLM Embedding结合Pair-wise Loss显著优化了值准度(SMAPE)与序准度(AUC),有效支撑后续规划器的RL训练。
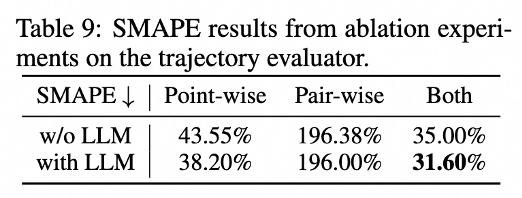
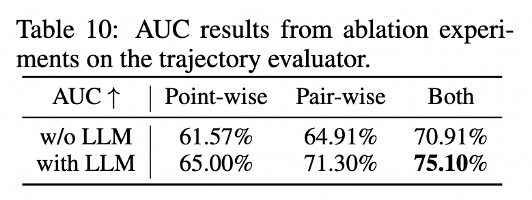
轨迹规划器(Planner)
规划器采用Causal Transformer,自回归的方式生成出价轨迹。
为确保策略满足 Lipschitz 连续性约束,他们引入了同步解耦Wasserstein估计(SDWE)方法。
其核心思想在于:通过将联合分布的 Wasserstein 距离分解为边际分布与条件分布的距离之和,并在训练过程中同步优化这两部分,从而在降低计算复杂度的同时,严格约束模型输出对输入扰动的敏感度,保证轨迹生成的平滑性与稳定性。
实验表明,SDWE可以成功保障规划器的Lipschitz特性。
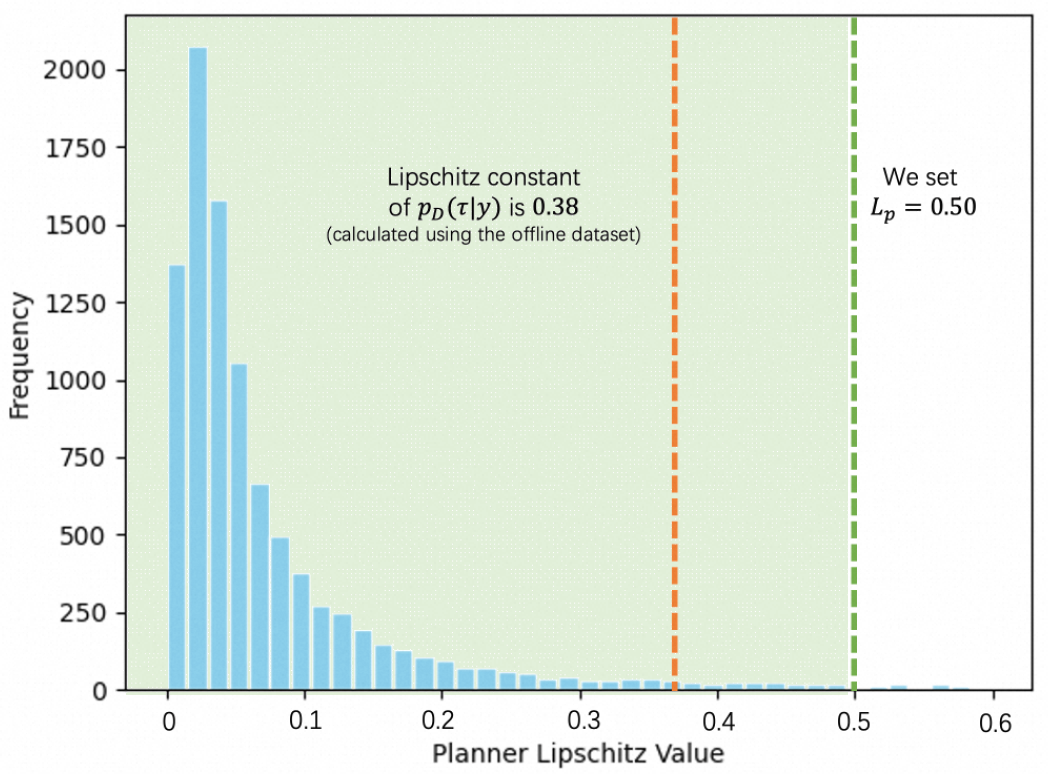
此外,论文给出了AIGB-Pearl的理论次优界,并从理论上讨论了其性能上界与重要超参数的关系。
实验结果:提升生成质量,避免异常轨迹
整体效果
团队在离线仿真环境与淘宝真实广告系统中对AIGB-Pearl进行性能评估。实验结果显示:
离线实验中AIGB-Pearl在各预算分层下均取得了SOTA性能;在19天的在线AB实验中,AIGB-Pearl在BCB和TargetROAS两种计划类型上分别取得GMV+3%和GMV+5%的效果提升。
后续他们继续对AIGB-Pearl在全站推TargetROAS计划上进行两次改进提效,整体为全站推带来GMV+10%的提升。
这证明了提出的强化学习增强方法可以有效提高AIGB的生成质量。
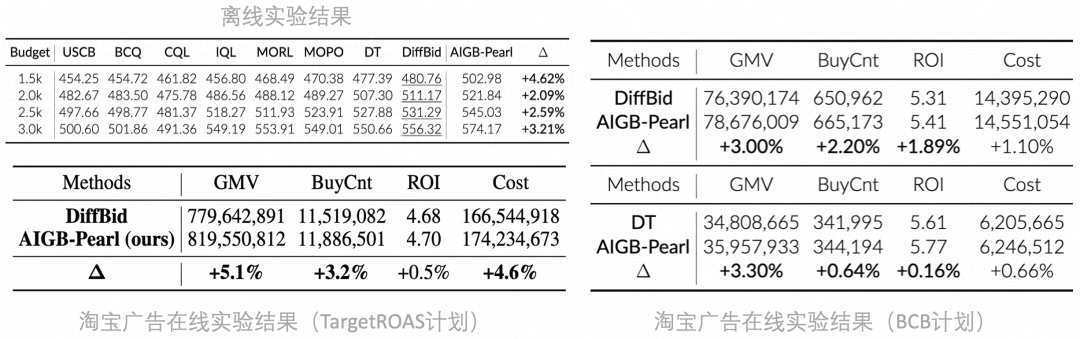
特别地,在训练阶段从未见过计划的在线A/B测试中,AIGB-Pearl相比AIGB仍实现了GMV+3%的提升,充分验证了其泛化性能。

消融实验
他们通过在线AB实验,量化了KL散度与Lipschitz约束的独立贡献。
实验数据显示,两项约束机制均提升了模型生成质量并转化为效果收益。
其中,KL散度约束带来GMV+1.1%的提升,而Lipschitz约束则贡献了GMV+1.8%的增长。
此外,轨迹可视化分析进一步显示,引入双重约束后,模型生成的出价轨迹显著优于未加入约束的RL增强的AIGB方法——有效规避了集中消耗、消耗不足及过度前倾等常见异常模式,生成出更平滑、合理的消耗轨迹。
 △Ablation Study证明KL和Lipschitz约束分别的有效性
△Ablation Study证明KL和Lipschitz约束分别的有效性
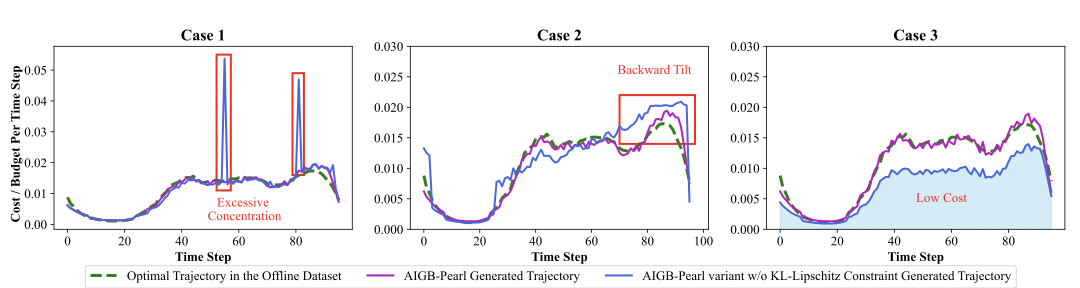 △双重约束有效避免常见异常轨迹生成
△双重约束有效避免常见异常轨迹生成
总结
自动出价是在高动态、非平稳的市场环境中进行长序列决策。
初代AIGB通过生成式范式突破了传统离线的累积误差瓶颈,但陷入了“缺乏反馈”的困境。
AIGB-Pearl 的核心在于构建了一个「生成-评估-优化」的闭环生态:
引入RL评估器引导模型超越历史数据的分布边界; Lipschitz+ KL双重约束则作为数学上的“安全阀”,确保模型在追求高分的同时,不脱离现实世界的物理规律。
线上消耗+9%/GMV+10%的提升,验证了这一范式的有效性。
AI不再仅仅是数据的模仿者,而是理性探索者。
尽管AIGB-Pearl在轨迹生成的安全性上取得了显著进展,但智能决策系统还需应对更底层的挑战:
在真实的广告系统中,观测空间(Observation Space)往往是高维、稀疏且充满噪声的(如用户瞬时意图的波动、竞争环境的随机扰动等)。
如何在高维高噪状态空间中进行更稳定有效的强化学习将会是后续迭代的重点之一。
论文链接:https://arxiv.org/abs/2509.15927
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢