
不久前,我们陆续发布并开源了百灵 2.6 系列模型,包括 Ling-2.6-flash、Ling-2.6-1T 和 Ring-2.6-1T。
今天,我们正式发布 Ling & Ring 2.6 Technical Report,系统公开百灵 2.6 系列在模型架构、预训练、后训练、Agent 强化学习与推理基础设施等方面的技术细节。
百灵 2.6 系列面向的是一个正在发生变化的大模型使用场景:模型不再只作为聊天系统回答问题,而是逐步进入 Agent、Coding、科研分析和企业工作流等真实复杂任务中。在这些场景中,模型需要同时具备三类能力:能够进行可靠推理,能够稳定使用工具,也能够在成本和延迟可控的前提下持续执行任务。
围绕这一目标,我们将百灵 2.6 系列设计为一个面向不同任务复杂度的模型家族:
Ling-2.6 面向即时响应和高 token efficiency,重点提升单位输出 token 的能力密度;
Ring-2.6 面向更深层推理和复杂 Agent 工作流,重点提升长链路规划、工具调用、代码执行、搜索和环境交互能力。
同时,百灵 2.6 系列的 base 与 post-training checkpoints 已面向社区开源。我们希望通过开放模型、技术报告与相关工具链,为开发者和研究者提供一个可复现、可扩展、可继续演进的 Agentic Intelligence 技术底座。


Key Features
百灵 2.6 系列并不是一次单纯的参数规模升级。我们更关注的是:在万亿参数规模下,如何让模型在真实工作流中更高效、更稳定、更可用。
围绕这一目标,百灵 2.6 主要在三个方向进行了系统优化。
更高效的长上下文能力
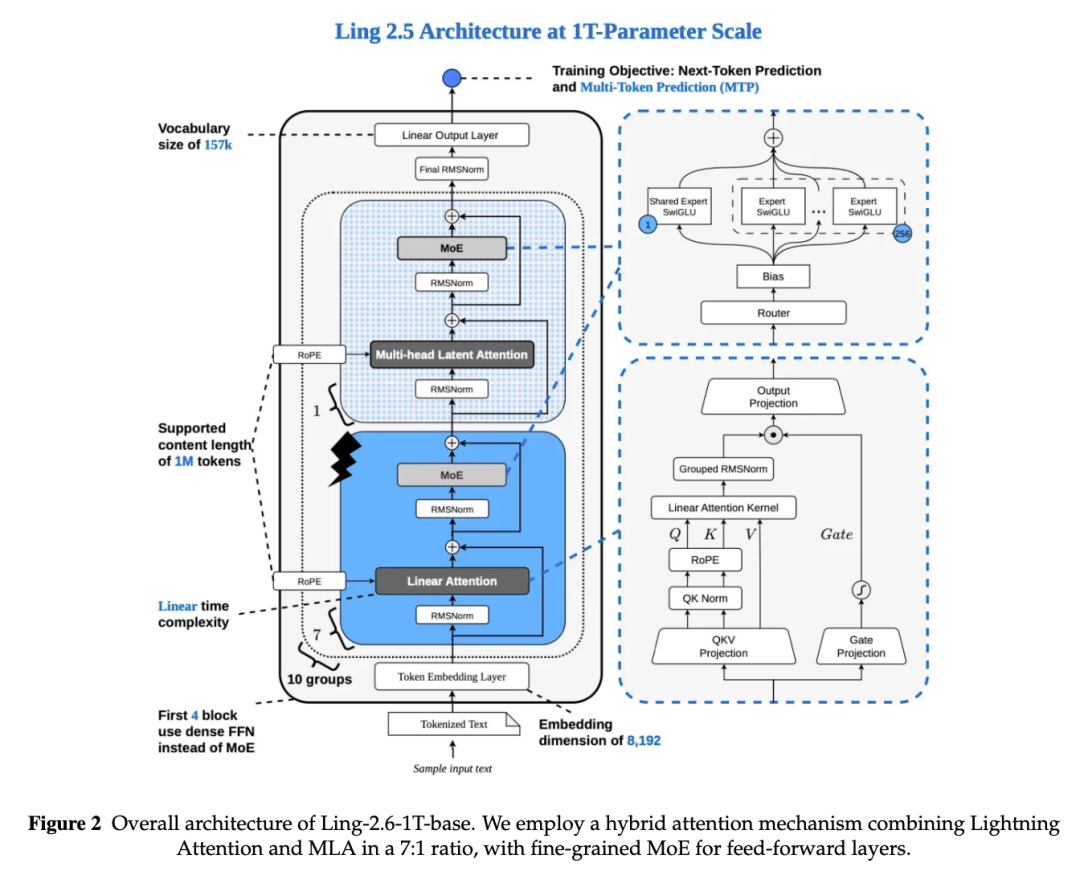
长上下文只有在足够高效时,才真正具备应用价值。此前基于 GQA 的架构在上下文长度超过 32K tokens 后,注意力计算会逐渐成为主要瓶颈。为此,Ling / Ring 2.6 采用统一的 Hybrid Linear Attention 架构,将 Lightning Attention 与 MLA 以 7:1 的比例结合,在尽量保持建模质量的同时,降低长上下文训练、解码和 KV Cache 成本。
在系统层面,我们进一步结合 continued MTP training、优化后的 context parallel 通信,以及 linghe fused kernel library,使新架构在长输出和长上下文训练场景中获得更好的吞吐表现,其中 Ling-2.6-flash 在 4×H20 硬件上达到 340 tokens/s。
更高的单位 token 能力密度
对 Ling-2.6 来说,token efficiency 是一个核心优化目标。我们并不把更短的输出视为表层风格优化,而是希望模型在更少输出 token 中承载更高的信息密度,并在减少冗余推理的同时保持回答质量。
在后训练阶段,我们结合 Evolutionary Chain of Thought(Evo-CoT)、Linguistic Unit Policy Optimization(LPO)、双向偏好对齐,以及 shortest-correct-response distillation 等方法,提升模型对有效推理步骤的选择能力,减少重复、循环和低信息密度输出。
在 Artificial Analysis Intelligence Index 上,Ling-2.6-1T 使用约 16M 输出 tokens 取得 34 分,相比 Ling-2.0-1T 在 reasoning workloads 上实现约 4 倍 token efficiency 提升。
原生优化 Agent 能力
百灵 2.6 系列的 Agent 能力不是简单从普通对话数据中“迁移”出来的,而是作为一个直接训练目标进行优化。
我们构建了覆盖工具调用、代码、搜索、工作流执行和多轮交互的大规模 Agentic Corpus,并将这些数据与可验证任务、结构化工具轨迹和环境反馈结合。在 Ring-2.6 上,我们进一步提出 KPop,用 binary KL divergence 替代 IcePop 中的统一固定比例约束,以更稳定地进行 MoE 模型的 Agentic RL 训练。同时,我们采用异步 RL,将 rollout 采集与参数更新解耦,使编码、搜索、工具调用和工作流执行等长链路任务能够在万亿参数规模下进行更高效训练。
这些设计使 Ring-2.6-1T 在多个真实任务和 Agent 评测中表现稳定。例如,Ring-2.6-1T high 在 PinchBench 上取得 87.60,在 ClawEval 上取得 63.82,并在 GAIA-2 Search 和 τ2-Bench Telecom 等任务中展现出较强的多步任务执行与工具调用能力。

注:上图展示 Ling-2.6-1T 在 Artificial Analysis Intelligence Index 中的 token efficiency;
下图展示 Ring-2.6-1T 在复杂推理与 Agent 任务 benchmark 中的表现。

模型定位:Ling 负责高效,Ring 负责深度推理与复杂执行
随着大模型从 Chatbot 走向 Agentic System,模型的优化目标也发生了变化。一个实用的大模型不仅要具备推理能力,还需要能够可靠调用工具,并在真实任务中保持稳定执行。与此同时,模型还必须在响应速度、token 成本和任务完成质量之间取得平衡。
因此,我们没有试图用单一模型覆盖所有任务,而是将百灵 2.6 系列设计成一个面向不同使用场景的模型家族。
Ling-2.6-flash 面向低延迟、高吞吐和高频调用,适合信息抽取、格式转换、长输出、批处理和 Agent 工作流中的轻量执行节点。
Ling-2.6-1T 面向更高能力密度和更强通用能力,强调在 instant / non-reasoning 场景下,以更少输出 token 完成高质量任务。
Ring-2.6-1T 面向复杂推理与长程 Agent 工作流,支持 high 与 xhigh 两种推理配置。其中,high 更适合高频 Agent 工作流和生产默认调用,xhigh 则用于需要更大思考预算的复杂推理任务。
2.6 系列模型分工的核心,是让开发者能够根据任务复杂度、成本约束和响应时延要求,选择更合适的模型与推理配置。

预训练:从 Ling-2.0 基座出发,完成长上下文架构迁移
在万亿参数规模上重新从零训练一个模型,成本极高,也会丢失上一代模型已经积累的大规模训练成果。因此,Ling / Ring 2.6 并没有从零开始训练,而是在 Ling-2.0 基座上进行架构迁移、继续预训练和大规模后训练。
Hybrid Linear Attention:兼顾长上下文效率与模型质量
在长上下文任务中,传统 Full Attention 的计算和缓存开销会随上下文长度快速上升。为解决这一问题,我们采用 Lightning Attention 与 MLA 结合的混合线性注意力架构。
Lightning Attention 将序列维度上的计算复杂度从 O(n²) 降低到 O(n),更适合长上下文训练和解码;MLA 则通过低秩隐空间压缩 KV Cache,降低长上下文推理中的显存压力。
我们通过 scaling law 实验比较了多种混合比例,包括 1:1、3:1、7:1 和 15:1。结果显示,7:1 的 Linear-to-Full ratio 在模型质量和推理成本之间取得了较优平衡,因此成为 Ling-2.6-1T-base 的最终架构选择。
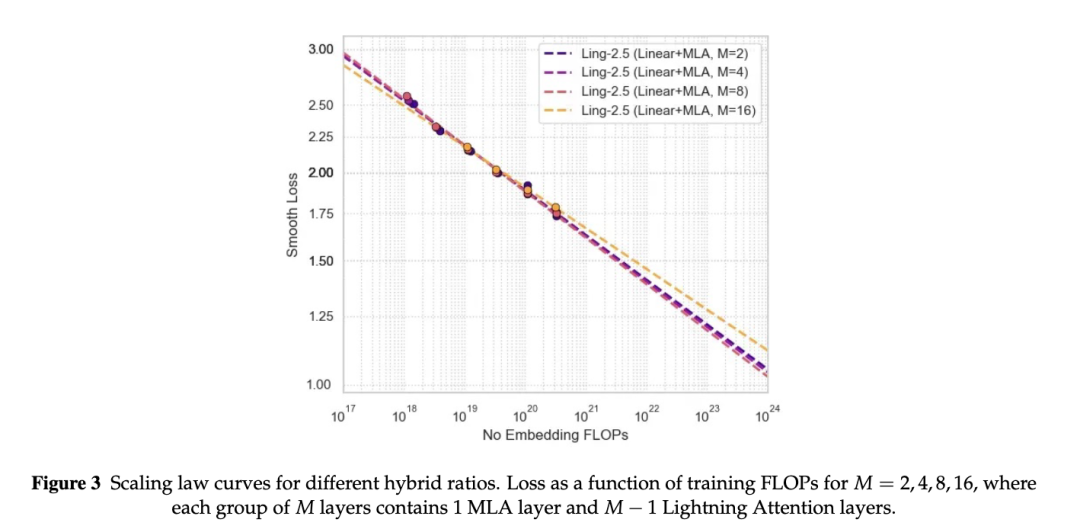
注:不同 Hybrid Attention 比例下的 scaling law 对比,7:1 在质量与效率之间取得较优平衡。
四阶段架构迁移:避免从零训练,平滑继承已有能力
从 GQA-based Softmax Attention 迁移到 Hybrid Linear Attention + MLA,并不是简单替换结构。我们采用了四阶段迁移流程:
第一阶段,将部分 GQA 层转换为 Lightning Attention;
第二阶段,通过 Linear Warmup 对新增参数进行对齐;
第三阶段,完成 MLA Conversion,包括 QK Norm removal、Partial RoPE adaptation;
第四阶段,通过 MLA Warmup 恢复 loss 到迁移前水平。
这一迁移阶段约使用 400B tokens,使模型在保留 Ling-2.0 已有能力的同时,逐步适配新的长上下文高效架构。
9.6T tokens 持续训练:从 4K 到 256K 上下文
完成架构迁移后,我们继续进行大规模全参数训练。Ling-2.6 的预训练总计处理约 9.6T tokens,分为三个阶段:
Migration Pre-Training:约 400B tokens,用于完成架构迁移;
Continue Pre-Training:约 8T tokens,4K 上下文,全参数继续训练;
Mid-Training:约 1.2T tokens,逐步将上下文窗口从 4K 扩展到 32K,再扩展到 256K。
在数据构成上,我们重点增强了数学、代码、Agentic Data、长上下文语料和多语言语料。Agentic Corpus 覆盖 500 多个真实 MCP 环境、3000 多个工具,以及多种 coding、bash、web QA 和软件仓库任务;Long-Context Corpus 则覆盖数学、复杂网页解析、长文档摘要、RAG 融合和多跳推理等任务。
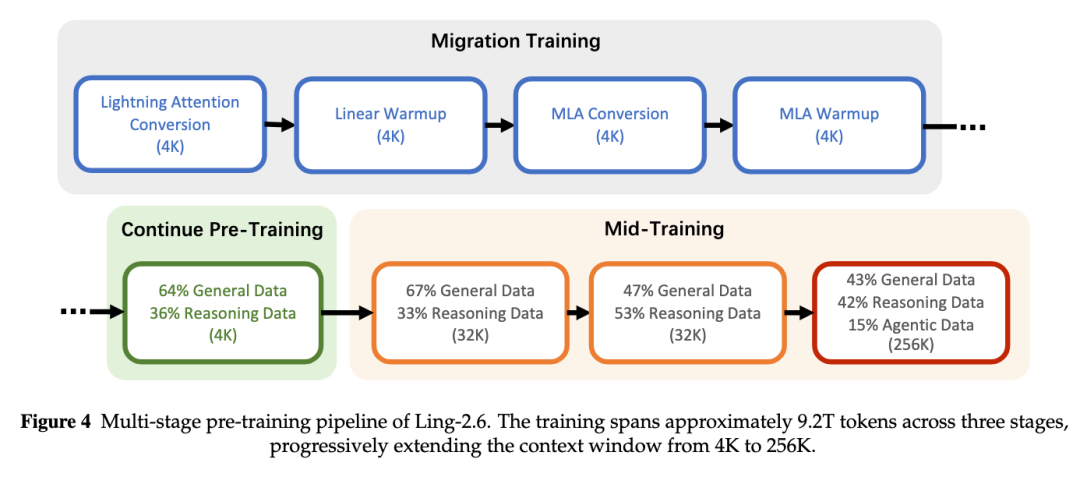
注:Ling-2.6 多阶段预训练流程:从架构迁移、继续预训练到长上下文 mid-training,逐步扩展至 256K 上下文。
Base model 评测:知识、长上下文、推理与代码能力同步提升
在 base model 评测中,我们使用覆盖数学、代码、通用推理、语言理解、世界知识和长上下文理解的 31 个 benchmark,对 Ling-2.6-flash-base、Ling-2.6-1T-base 与 2.0 代模型进行对比。
整体来看,Ling-2.6-1T-base 在世界知识、长上下文建模和推理能力上取得较稳定提升,同时保持了数学和代码能力。尤其是在 SimpleQA、C-SimpleQA、MMMLU、LongBenchv2 等知识和长上下文任务上,提升较为明显。这说明新的高质量数据与长上下文训练流程有效增强了模型的知识表达、长程依赖建模和多步推理基础能力。
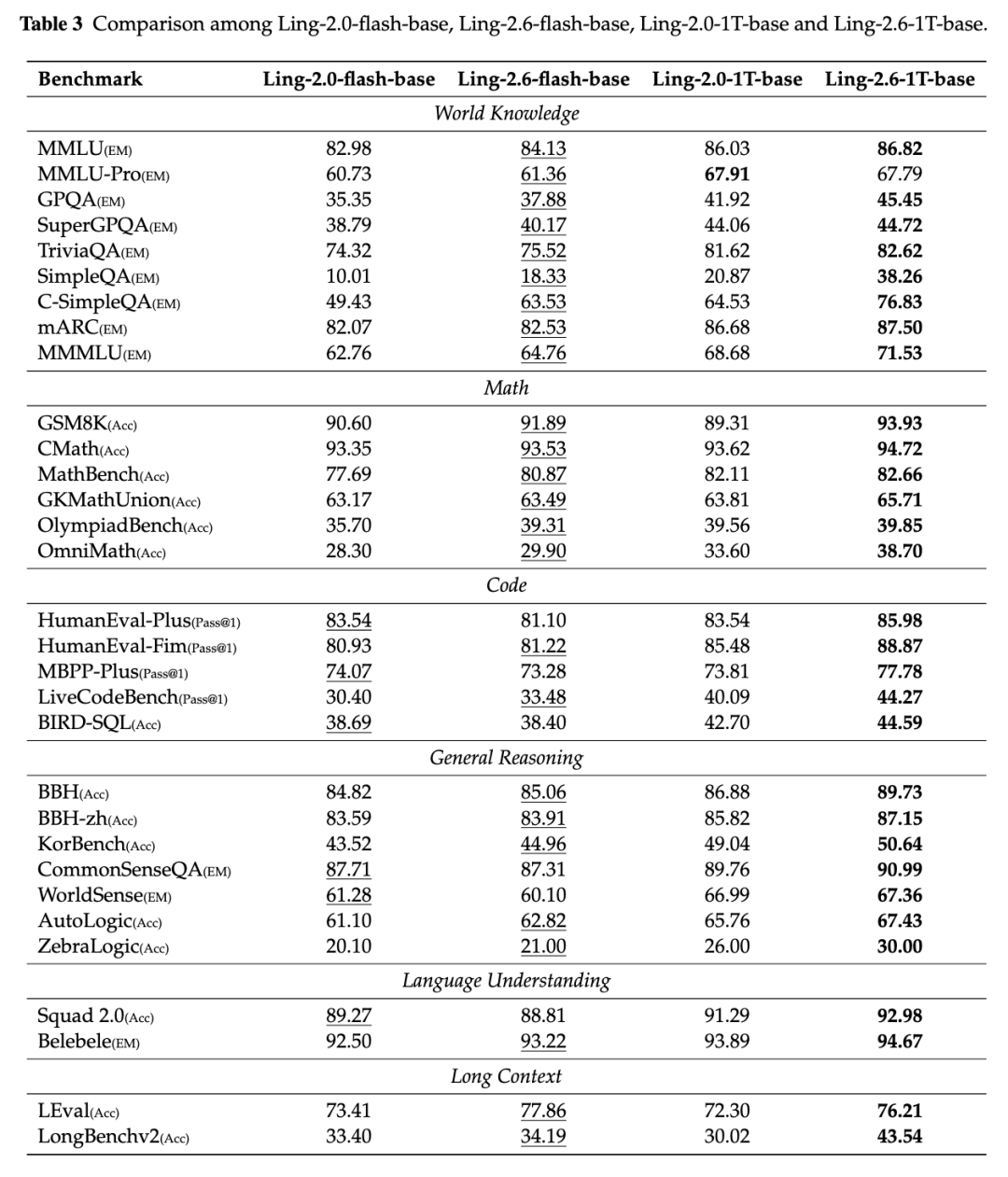
注:Ling-2.6-base 与 Ling-2.0-base 在知识、数学、代码、推理、语言理解和长上下文 benchmark 上的对比。

Ling-2.6 后训练:围绕 token efficiency 的专家化训练
Ling-2.6 的后训练目标,是得到一个更适合即时响应和高频调用的模型。因此,我们不仅关注模型能否答对,也关注模型是否能用更少的输出 token 给出更高质量的回答。
与 Ling-2.0 的统一式后训练不同,Ling-2.6 采用专家驱动的训练范式:先进行 cold-start SFT,再进行 reasoning specialist 与 agentic specialist 的专家化训练;随后通过 RL 强化各专家模型,最后将专家能力蒸馏回统一的 Ling-2.6 模型。
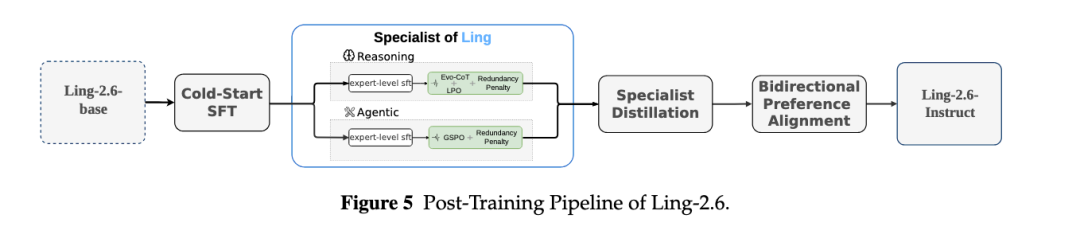
注:Ling-2.6 后训练流程:Cold-start SFT、专家训练、token-efficient RL、双向偏好对齐与能力蒸馏。
更少冗余,更高信息密度
在 reasoning 方向,我们首先利用专家模型生成候选回答,并保留最短正确答案。同时,我们使用 LLM judge 去除“已经找到正确答案后仍继续反思”的过度推理片段。这一数据层面的处理,使平均输出长度减少约 200 到 300 tokens。
在 RL 阶段,我们基于 Evo-CoT 进一步引入冗余惩罚,包括动态长度惩罚和语义冗余惩罚。动态长度惩罚允许模型在困难任务上进行更充分推理,但限制简单任务中的过长输出;语义冗余惩罚则通过分段评估推理过程,抑制循环、重复和低价值反思。
面向工具使用的 token-efficient Agent 训练
在 Agent 任务中,我们采用 GSPO,并引入两个奖励信号:一是工具调用轨迹与最优工具调用序列之间的一致性,二是基于 zlib 压缩率的重复惩罚。
压缩率惩罚的直觉很简单:高度重复和退化的输出更容易被压缩,因此会受到更强惩罚。这使模型在工具使用过程中更倾向于简洁、连贯和有效的执行路径。
同时,我们引入 Dynamic Pass Rating(DPR)进行动态样本选择。训练早期已经能够稳定解决的任务会被视为较容易任务;长期无法解决或表现不稳定的任务,则被优先用于后续训练。这样可以让训练资源更多集中在模型当前能力边界附近的高信息量样本上。
双向偏好对齐:兼顾质量与简洁性
Ling-2.6 的最后阶段引入双向偏好对齐。不同于只做单向奖励建模,我们将正向激励和负向惩罚统一到一个 reward model 中:既鼓励信息充分、满足约束的回答,也惩罚逻辑错误、幻觉和机械式冗长输出。
为了避免模型通过单纯增加输出长度来提高 reward,我们进一步使用 focus reward,根据不同维度的饱和程度动态调整训练权重,使优化重点转向仍需提升的维度。

Ring-2.6 后训练:面向长程 Agent 的强化学习
Ring-2.6 的后训练目标与 Ling-2.6 不同。它更关注复杂、长程、工具密集型的 Agent 行为。我们希望 Ring-2.6 不只是提升最终任务成功率,也能在真实执行约束下增强规划、搜索、工具调用和自适应交互能力。
在训练流程上,Ring-2.6 从 Ling-2.6-1T Base 出发,经过 cold-start SFT,再进入由 KPop 算法训练的 reasoning & agentic 专家,specialist distillation,并最终形成 high 与 xhigh 两种推理配置。
其中,high 通过适度长度惩罚,在推理深度与响应简洁性之间取得平衡;xhigh 则使用更小的长度惩罚,面向复杂推理任务释放更充分的思考空间。
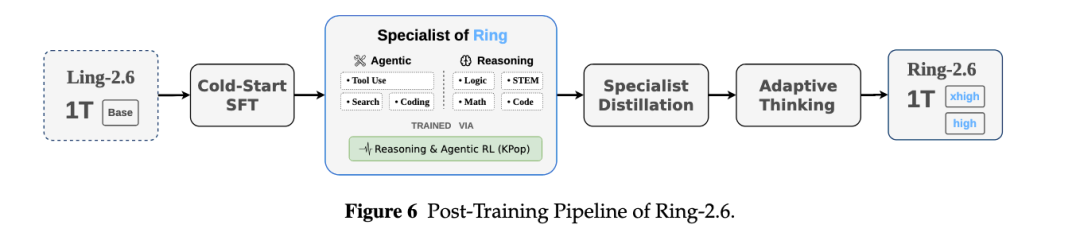
注:Ring-2.6 后训练流程:从 Ling-2.6-1T Base 到 high / xhigh 的 Adaptive Thinking。
Agentic Data:从代码、搜索到通用工具工作流
Ring-2.6 的 tool-use data 主要覆盖三类能力:repository-level coding、mobile / web search,以及需要多步规划和错误恢复的通用工具工作流。
在 Coding Agent 任务中,我们从 GitHub 大规模挖掘 PR-Issue pairs,保留 star 数超过 100、PR 已合并并关联 closed issue、且包含 test patch 的任务,最终得到约 300K raw pairs。为了防止与已有 SWE benchmark 重叠,我们会排除相关仓库,降低数据污染风险。
在 Search Agent 任务中,我们构建移动应用搜索和网页搜索两类环境。移动端任务模拟联系人、消息、邮件、日历、购物、出行、文件等状态化应用;网页搜索任务则从 Wikipedia 证据路径中构造多跳问答,关键事实用间接描述表达以避免关键词捷径。
在通用工具使用方面,我们构建了覆盖业务政策约束、多轮工具调用、harness-agnostic workflow、大规模 MCP 合成任务和一般工具调用任务的数据。其中,大规模 MCP 合成任务覆盖 197 个验证后的 MCP servers、12 个领域和 2400 多个工具。
Agentic RL:让模型在真实环境反馈中训练
在 Agentic RL 阶段,我们构建了一个轻量级 Agent 框架,并提供 execute_bash、search_replace 和 task_done 三类核心工具。训练期间最大对话长度为 200 turns,评估期间最大对话长度为 500 turns。
针对 SWE 类长程任务,我们在 sandbox 环境中进行强化学习训练。这类任务往往需要 30 到 200 个解决步骤,因此需要可复现环境、可靠验证信号和较高训练稳定性。
最终用于训练的数据集包含约 2500 个实例,来自 1550 个仓库,覆盖 Python、Java、C、Rust、JavaScript 等 30 多种编程语言。为了减少 reward hacking,我们限制了 git history 访问,并通过实时监控识别潜在作弊轨迹。分析显示,约 0.2% 的轨迹存在 cheating pattern,在实践中影响较小。
KPop:缓解强化学习中的训练-推理不一致
在 Ring-1T 中,我们提出 IcePop,通过双侧 masking 提升 MoE 模型强化学习稳定性。但在 Ring-2.6 的训练中,我们进一步观察到,固定比例约束会隐含假设所有 token 具有相同噪声结构,这与真实训练过程并不一致。
不同 token 的概率不同,训练策略与推理策略之间的 mismatch 也不同。固定比例 mask 容易对低概率 token 产生过度 masking。
因此,我们提出 KPop,用 symmetric binary KL criterion 替代 IcePop 中的固定比例约束。对每个输出 token,KPop 将整个词表视为“当前采样 token”和“其他所有 token”两个事件,分别计算训练策略与推理策略之间的 binary KL divergence。只有当两个方向的 binary KL 都足够小时,该 token 才被保留用于策略更新。
实验显示,KPop 能够让 coding task 上的 Agentic RL reward 曲线在训练过程中持续上升,并将轻量 agent 在 SWE-bench Verified 上的 solve rate 从 70.8% 提升到 76.28%,该结果为三次独立运行的平均值。
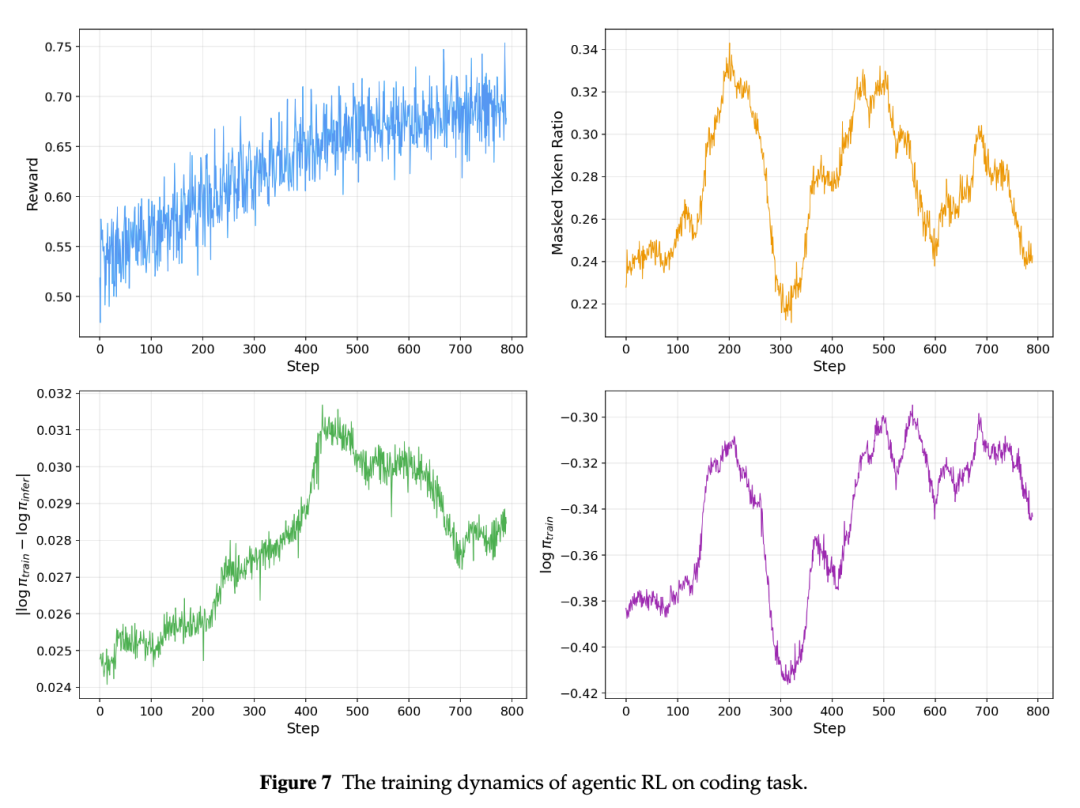
注:KPop 在 coding task 上的 Agentic RL 训练动态,reward 曲线随训练持续上升。
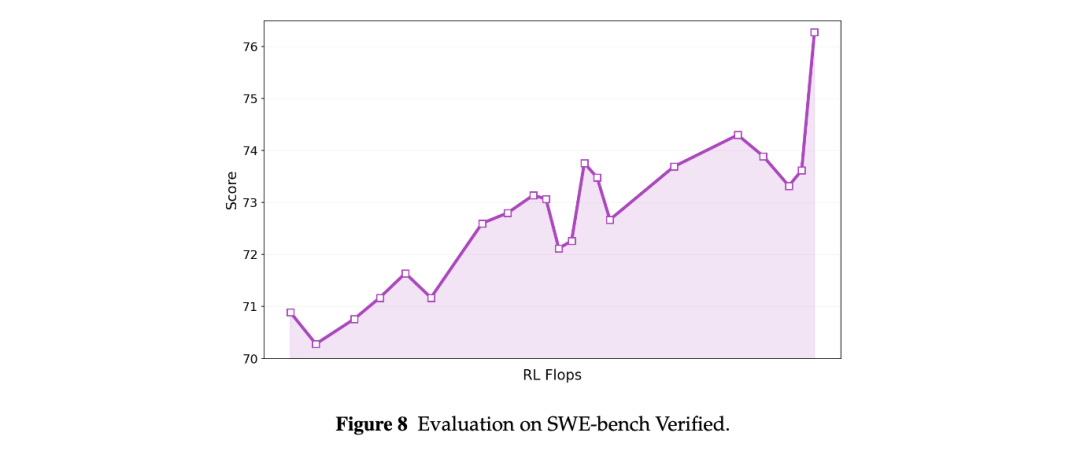
注:KPop 在 SWE-bench Verified 上的评测结果。

评测结果:Ling 更快更实用,Ring 更擅长复杂推理与 Agent 执行
我们分别对 Ling-2.6 与 Ring-2.6 进行了系统评测。
Ling-2.6 主要作为 instant model 进行评估,重点关注快速响应、token efficiency、指令遵循和长上下文能力;
Ring-2.6 则作为 long-horizon agentic model 进行评估,重点关注复杂推理、OpenClaw、Agentic Coding、Agentic Search 和 Function Calling。
Ling-2.6:高 token efficiency 下的通用能力
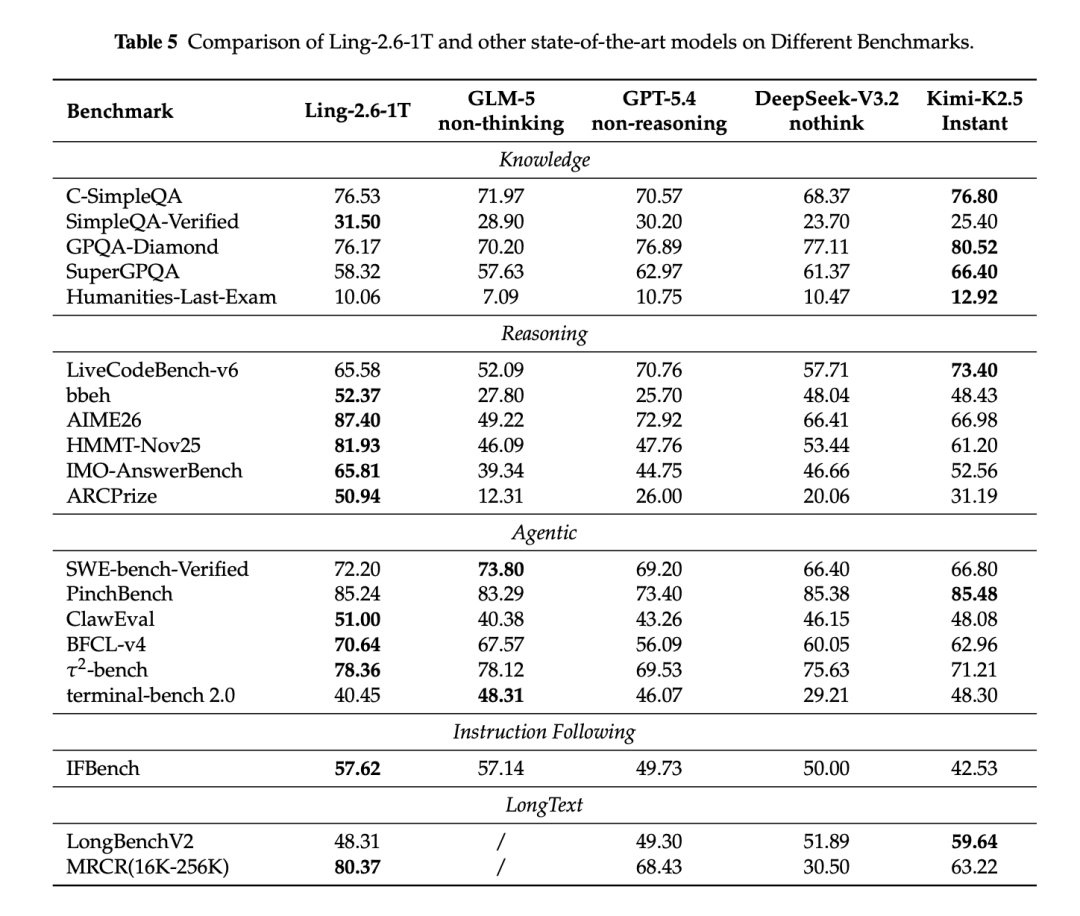
Ling-2.6-1T 在知识、推理、Agent、指令遵循和长上下文等任务上表现较为稳定。
在知识任务中,Ling-2.6-1T 在 C-SimpleQA 上取得 76.53,在 SimpleQA-Verified 上取得 31.50;在推理任务中,AIME26 得分 87.40,HMMT-Nov25 得分 81.93,IMO-AnswerBench 得分 65.81,ARCPrize 得分 50.94。
在 Agent 任务中,Ling-2.6-1T 在 PinchBench、ClawEval、BFCL-v4 和 τ2-bench 上均表现出较强的工具使用与任务执行能力。Ling-2.6-flash 虽然是轻量模型,但在 SWE-bench Verified、PinchBench、TAU2-Bench 等任务上也展现出较好的执行能力。
在长上下文与多轮对话方面,Ling-2.6-1T 在 MRCR 16K-256K 上取得 80.37;Ling-2.6-flash 在 MRCR 上取得 75.93,并在 Multichallenge 与 Multi-IF 上表现稳定。这说明 Ling-2.6-flash 在长输入、长输出和复杂交互场景中具备较好的部署效率与任务表现。
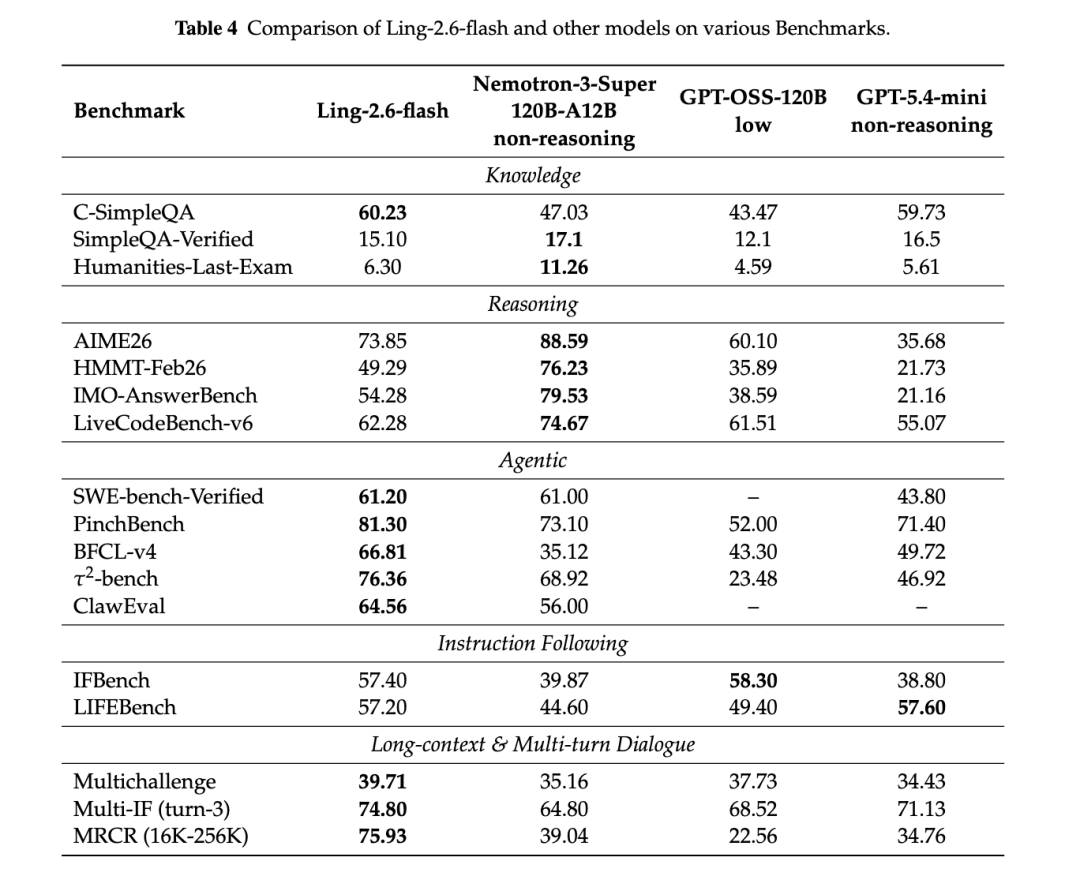
注:Ling-2.6-flash 与 Ling-2.6-1T 在知识、推理、Agent、指令遵循和长上下文 benchmark 上的评测结果。
Ling-2.6-flash:面向部署效率的轻量模型
Ling-2.6-1T 面向更高能力上限,而 Ling-2.6-flash 更强调部署时的推理效率。得益于混合注意力架构和高稀疏 MoE 设计,Ling-2.6-flash 在同类规模模型中具备较高 serving 速度。
在 4×H20 部署、batch size 32、4 个 tensor parallel ranks、输出长度 64K 的设置下,Ling-2.6-flash 的 decode throughput 分别达到 Nemotron-3-Super 的 1.3 倍、Qwen3.5-122B-A10B 的 2.4 倍、GLM-4.5-Air 的 4.3 倍。对于长输出、高频调用和吞吐受限的 Agent workload,响应速度本身就是模型可用性的重要组成部分。
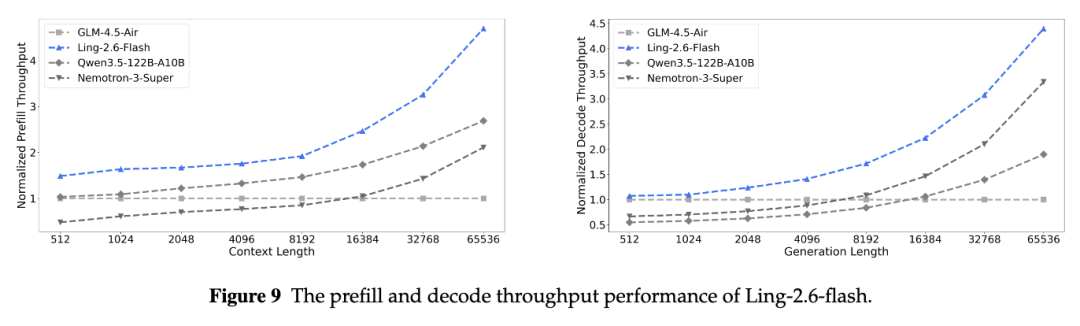
注:Ling-2.6-flash 在 prefill 和 decode 阶段的吞吐表现。
Ring-2.6:复杂推理与 Agent 执行能力
Ring-2.6-1T 提供 high 与 xhigh 两种推理配置。xhigh 使用更大的 thinking budget,用于最大化复杂推理深度;high 则减少推理开销,更适合 Agent 执行和高频调用。
在复杂推理任务上,Ring-2.6-1T xhigh 在 AIME 2026 上取得 95.78,在 LiveCodeBench-v6 上取得 86.95,在 ARC-AGI-2 上取得 66.18。报告中,Ring-2.6-1T xhigh 在 ARC-AGI-2 上是 top open-weights model,体现出较强的抽象推理和模式识别能力。
在 OpenClaw 相关评测中,Ring-2.6-1T high 表现更加突出:PinchBench 得分 87.60,在报告列出的模型中排名第一;ClawEval 得分 63.82,在开源权重模型中排名第一,超过 Kimi-K2.6-Thinking 和 GLM-5.1-Thinking。
在 Agentic Coding 方面,Ring-2.6-1T high 在 SWE-bench Verified 上取得 74.00,在 SWE-bench Pro 上取得 53.76,说明模型已经具备处理多文件推理、真实软件工程任务和迭代式 debugging 的基础能力。
在 Agentic Search 方面,Ring-2.6-1T xhigh 在 GAIA-2 Search 上取得 77.90,体现出多跳搜索与信息整合能力。在 Function Calling 方面,Ring-2.6-1T high 在 τ2-bench Average 上取得 84.26,在 τ2-Telecom 上取得 96.71,说明模型在结构化 API 交互和多轮函数调用任务中具备较好的可靠性
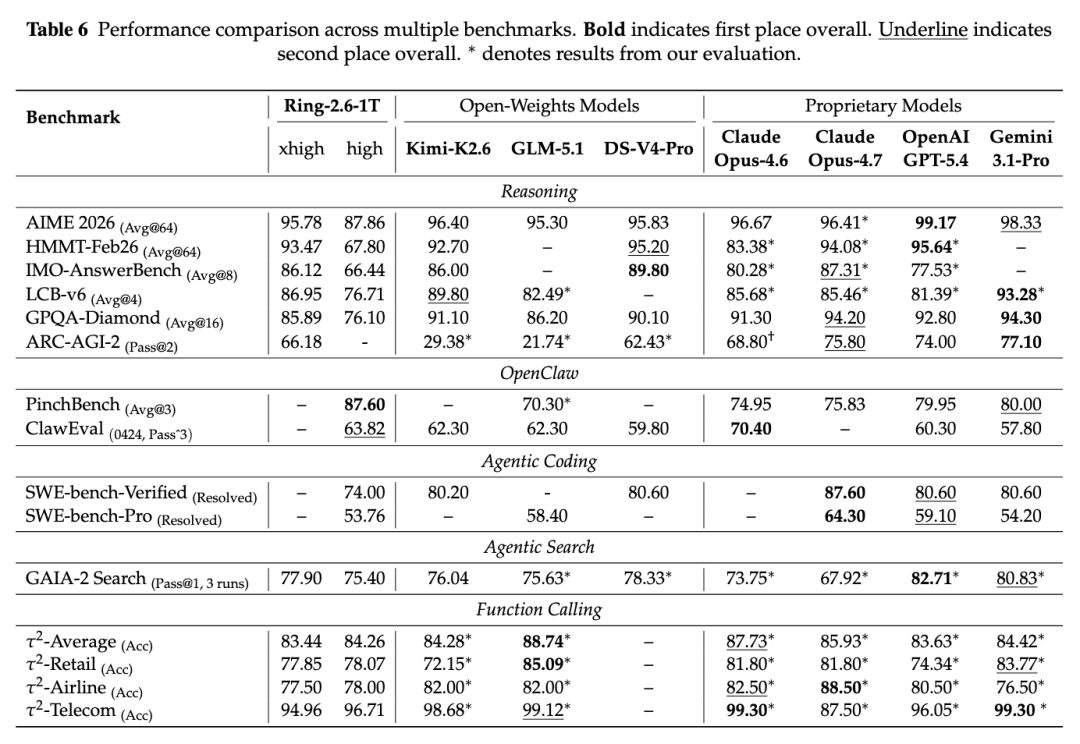
注:Ring-2.6-1T 在复杂推理、OpenClaw、Agentic Coding、Agentic Search 和 Function Calling 上的评测表现。

基础设施:训练、RL 与推理的系统协同
对于万亿参数模型来说,系统栈本身就是模型能力和成本的重要组成部分。百灵 2.6 的基础设施优化主要围绕三个层面展开:长上下文训练效率、大规模异步 Agentic RL 效率,以及推理 serving 效率。
长上下文训练:面向 Lightning Attention 的 Context Parallel
引入 Hybrid Linear Attention 后,长上下文训练不再是 Ling-2.0 训练栈的简单延伸。Lightning Attention 具有沿序列维度的递归依赖,不能直接套用传统 Softmax Attention 的 Context Parallel 方案。
因此,我们提出 AllGather-based CP,采用“本地递归 + 全局校正”的方式。每个 rank 先在本地序列分片上计算 hidden state 和 output,再通过 AllGather 汇聚状态并进行校正。该设计不依赖 head 数整除约束,更适合超长上下文训练。
同时,我们通过 Triton fused kernel 对 varlen sequences 进行 kernel fusion,将状态校正递归展开为向量化矩阵形式,并将多个子序列的 output correction 合并执行。在 256K 上下文长度下,该优化带来约 68% 的端到端加速。
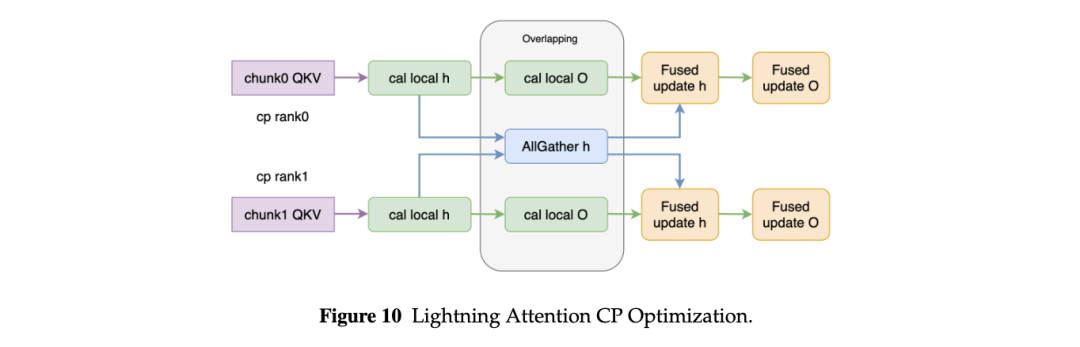
注:Lightning Attention 的 Context Parallel 优化。
ASystem 与 ARouter:支撑大规模异步 Agentic RL
Ling / Ring 2.6 的 RL 训练建立在 ASystem 之上。ASystem 是一个 hybrid SingleController-SPMD runtime,将控制流与数据流分离,并将训练、推理和 reward computation 作为可插拔后端。
在 RL rollout 中,少量长尾解码请求可能拖慢整个 batch,使 GPU 长时间等待。为此,ARouter 的目标不是最小化单个请求延迟,而是最小化整个 RL step 的完成时间。
ARouter 会跟踪推理实例负载和生成进度,将后期长尾请求从拥塞实例迁移到空闲实例;同时支持 spillover-based training-inference overlap,使主推理组释放计算资源并进入训练侧梯度累积。在长序列场景下,这一机制带来超过 80% 的端到端性能提升。
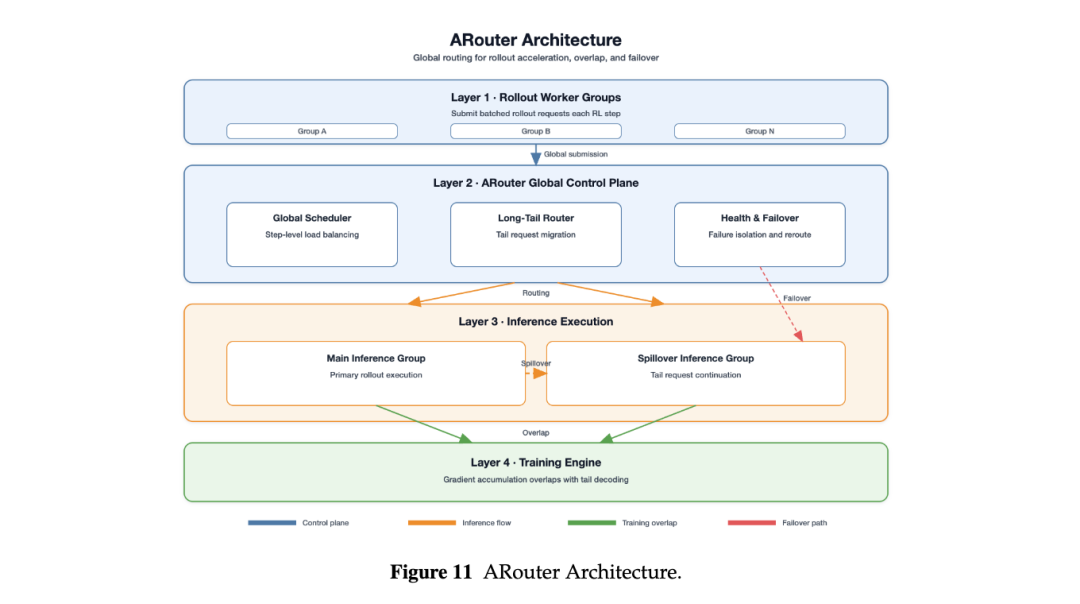
注:ARouter 架构:面向 RL rollout 的全局调度与长尾请求处理。
linghe:从训练到推理的一致性优化
在推理侧,我们将训练阶段积累的 fused kernels 进一步适配到真实部署场景,并尽可能保持训练与推理阶段的数值行为一致。这不仅提升推理效率,也有助于减少 RL rollout 中的训练-推理差异。
在 BF16 推理中,我们融合了 QK Norm + RoPE、Group RMSNorm + Sigmoid Gate 等关键算子,并优化 MLA RoPE 和 Top-K;在 FP8 推理中,我们进一步融合 RMSNorm、SwiGLU 和 quantization,并引入 Split-K Blockwise FP8 GEMM 以提升小 batch 场景吞吐。
结合 kernel fusion、prefix caching 与 multi-token generation,linghe 带来的不仅是整体吞吐提升,也包括更高的 per-user TPS、更短等待时间和更稳定的交互体验。
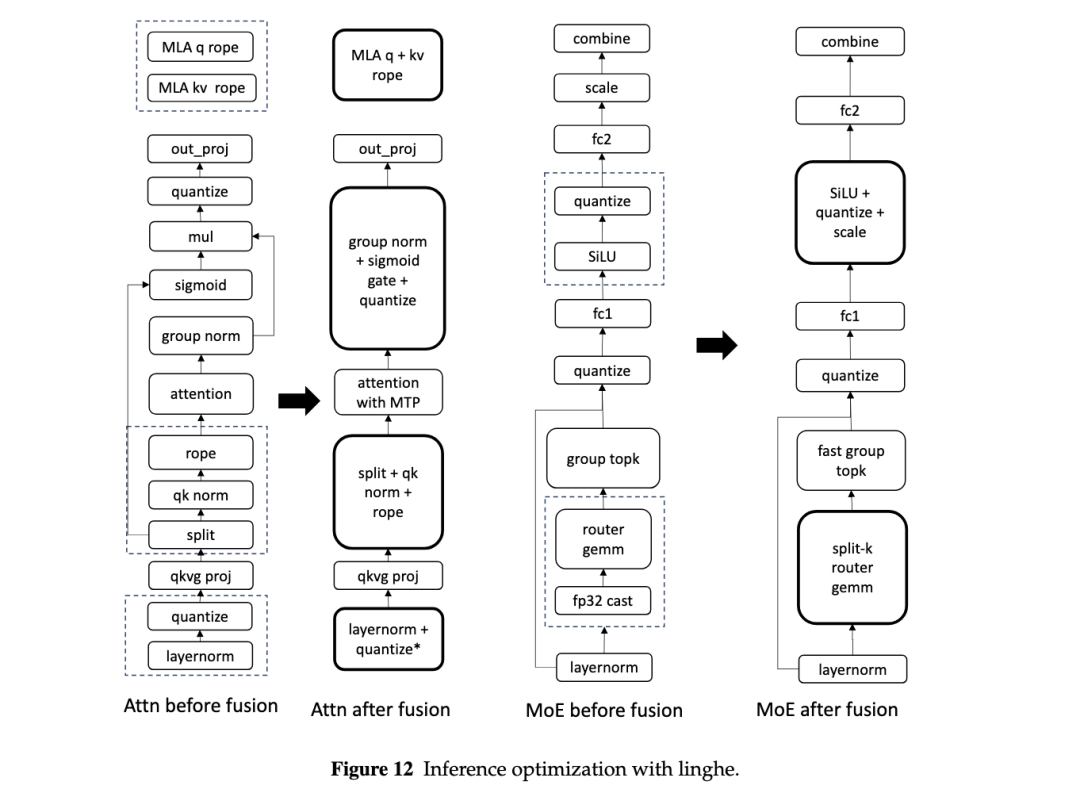
注:linghe 在 Attention 与 MoE 模块中的推理算子融合优化
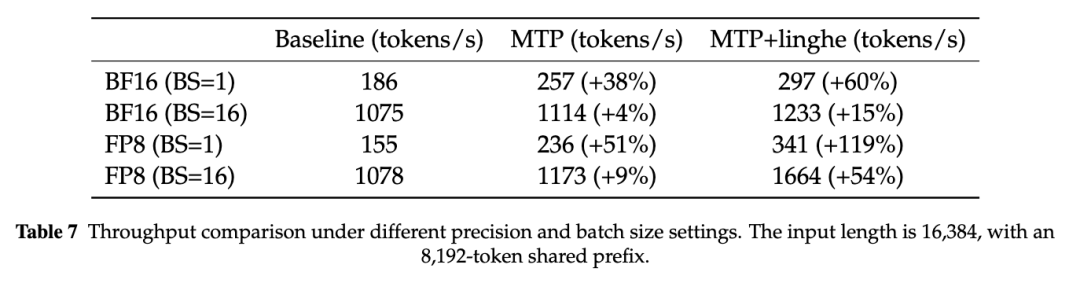
注:不同精度和 batch size 设置下,MTP 与 linghe 对吞吐的提升。

局限与未来方向
我们当前的模型仍然存在一些不足。
首先,Ling-2.6-flash 在吞吐和 token economy 上取得了明显收益,但更紧的思考预算也会限制其在高复杂度任务中的推理深度、复杂指令组合能力和工具调用可靠性。
其次,当前 token efficiency 目标仍有继续改进空间。它能有效压缩程序化推理过程中的冗余,但在知识密集型输出中,有时还不能完全区分低价值重复与必要事实展开。
第三,长程 Agent 的鲁棒性仍然弱于短程任务能力。模型可以在局部决策中表现较好,但在更长工作流、持续变化的工具状态和异构执行环境中,可靠性仍会下降。
最后,现有公开评测仍不能充分衡量 persistence、recovery behavior、cost-aware planning 和 deployment-time robustness 等真实生产环境中的关键能力。
下一阶段,我们会继续沿着 co-design 的方向推进:在模型架构、系统、低精度训练与推理、KV Cache 管理、优化方法和推理效率之间进行更深入协同;同时,我们也会推动 Ling / Ring 从 text-only system 走向 native multimodal agents,使模型能够更自然地处理视觉界面、文档、代码和混合模态环境。

让 Agentic Intelligence 更高效、更开放、更可落地
Ling / Ring 2.6 技术报告传递出的核心观点是:万亿参数模型的进展,不应只来自模型规模本身,而应来自架构、后训练、基础设施和 Agent 训练环境之间的系统协同。
Ling-2.6 更关注即时响应、token efficiency 和部署约束下的广泛可用性;Ring-2.6 更关注复杂推理、长链路任务和真实环境中的 Agent 执行。二者共同构成了百灵 2.6 系列面向实用 Agentic Intelligence 的技术路径:长上下文要高效,输出 token 要有更高信息密度,Agent 行为要能在真实环境反馈中稳定优化。
随着 2.6 系列模型、base 与 post-training checkpoints 的开源,我们希望把这一路径开放给更多研究者和开发者,共同探索高效、开放、可落地的 Agent 系统。
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢