

读完一篇论文,不等于理解一篇论文。
能总结摘要,也不等于能回答围绕方法设计、实验结果和结论依据的具体问题。
科研场景里的论文阅读,通常不是只问“这篇文章讲了什么”。更常见的问题是:
- 这个方法为什么这样设计?
- 和已有方法相比,差异到底在哪里?
- 实验设置是否足以支撑结论?
- 表格里的结果说明了什么?
- 作者提出的 claim,是否真的能从论文证据中得到支持?
RPC-Bench关注的正是这类能力:模型能否充分理解论文内容并给出可靠回答。不同于直接用大语言模型(LLM)从正文合成问题,RPC-Bench从真实review-rebuttal互动中构造QA。审稿人与作者围绕论文贡献、问题和证据链展开讨论,这些内容更贴近科研人员实际关心的论文理解问题。

论文: https://arxiv.org/abs/2601.14289
GitHub: https://github.com/zai-org/RPC-Bench
项目主页: https://rpc-bench.github.io/
HF dataset: https://huggingface.co/datasets/zai-org/RPC-Bench
RPC-Bench做了什么?
RPC-Bench是一个面向研究论文理解的问答基准,主要覆盖计算机科学论文,支持文本输入和PDF页面图像输入两种形式,可用于评测LLM、VLM、文档理解模型和RAG方法等。
从数据规模看,RPC-Bench最终包含4150篇论文和61.3K个QA。其中开发集和测试集经过人工验证,用于更稳定地评估模型表现;训练集则作为补充数据,供研究人员根据具体实验目标选择使用。
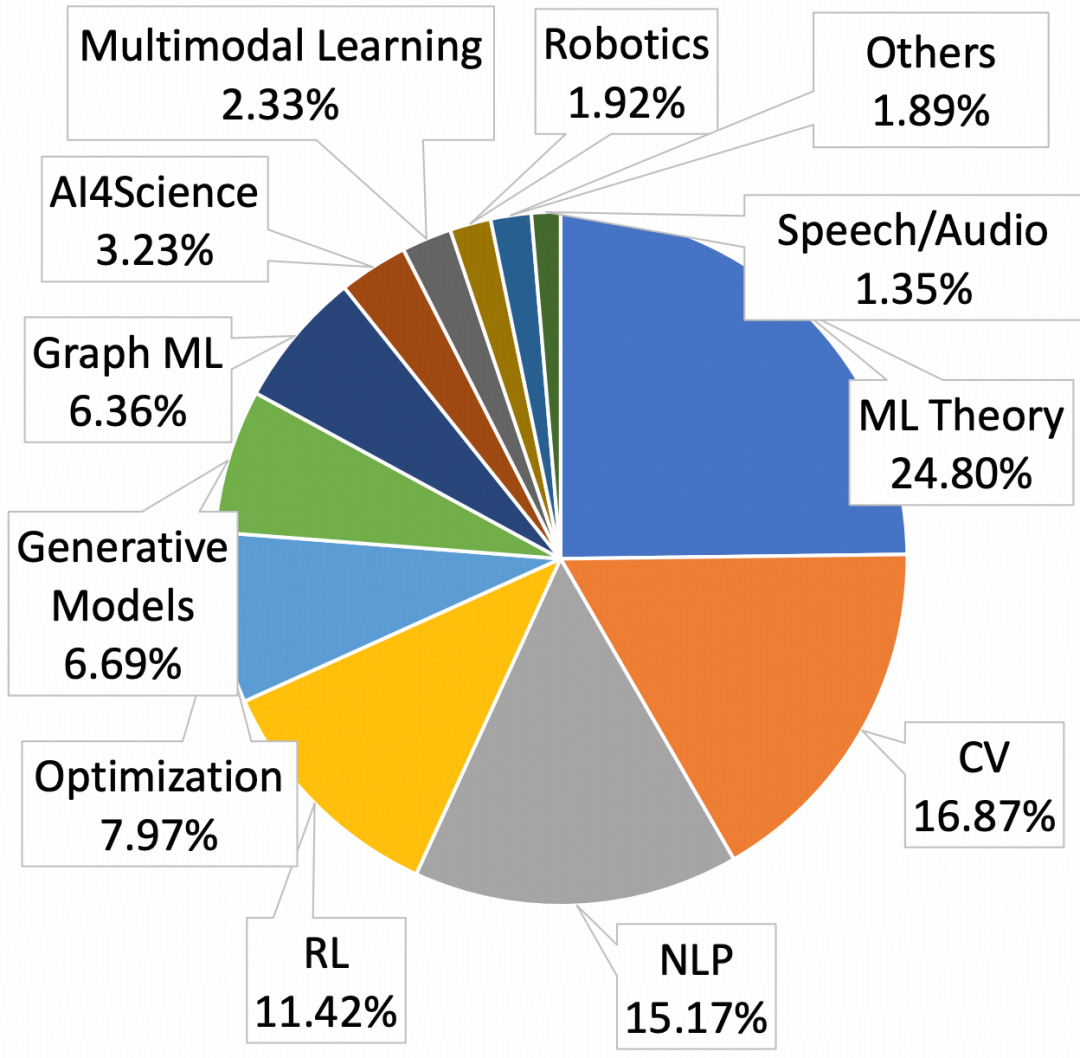
RPC-Bench的论文主要来自OpenReview,因此领域分布以AI和计算机科学子领域为主,包括ML Theory、CV、NLP、RL、Optimization、Generative Models等方向。
相比已有研究论文/文档问答基准,RPC-Bench的特点在于:真实review-rebuttal来源、内容导向的细粒度taxonomy、多维度回答质量评估,并同时支持文本与页面图像输入。

RPC-Bench是怎么构建的?

RPC-Bench的构建流程包括四个环节:
1. 数据收集与筛选:从OpenReview收集2013-2024年的论文、review、rebuttal和元数据,并结合AMiner引用信息进行质量筛选和影响力感知采样。 2. 拆解审稿互动:使用GPT-4o将长review/rebuttal拆分为更小的comment-response单元,使每个单元尽量聚焦一个问题或澄清点。 3. 改写为标准QA:使用GLM-4-Plus和DeepSeek-V3将comment-response单元改写为可独立理解的问题与答案,并分配taxonomy标签。 4. 过滤与人工复核:过滤编辑性问题、外部资源依赖和空泛承诺;开发集和测试集进一步人工复核,确保问题可回答、答案有依据、分类合理。
这种LLM-human collaborative annotation的设计,一方面利用模型降低大规模构建成本,另一方面通过人工复核控制开发集和测试集质量。
论文理解被拆成哪些能力?
RPC-Bench设计了一个对齐科学研究流程的细粒度taxonomy,用于考察模型在学术语境中回答what、how、why问题的能力:从理解概念与背景,到理解方法和实验如何运作,再到解释设计动机、结果原因和结论依据。

这套分类大致对应科研阅读中的几类核心能力:
what层面:模型需要解释概念、术语、图表信息和实验结果本身,回答“论文说了什么”; how层面:模型需要理解方法流程、模块机制、实验设置和评测协议,回答“论文是如何做的”; why层面:模型需要分析设计动机、实验现象、方法差异和结论边界,回答“为什么这样做、为什么得到这样的结果”; claim verification层面:模型需要判断具体科学主张是否能从论文证据中得到支持。
这样的设计让RPC-Bench不只评估摘要或事实定位能力,而是把“读懂论文”拆成可观察、可诊断的多个能力维度。
怎么评测:不只看答案像不像
开放式论文问答中,答案和参考答案“长得像”不一定代表答得对。因此,RPC-Bench没有只依赖ROUGE、BERTScore等表面相似度指标,而是采用LLM-as-a-Judge的方式,从三个维度评估开放式回答:
- Correctness:回答内容是否正确、是否忠实于论文(类似precision);
- Completeness:是否覆盖参考答案中的关键信息(类似recall);
- Conciseness:是否简洁,是否避免无关扩展(控制冗余和跑题)。
论文进一步用correctness和completeness的调和均值得到F1-like,再结合conciseness得到Informativeness。对于Claim Verification,则使用accuracy进行评价。
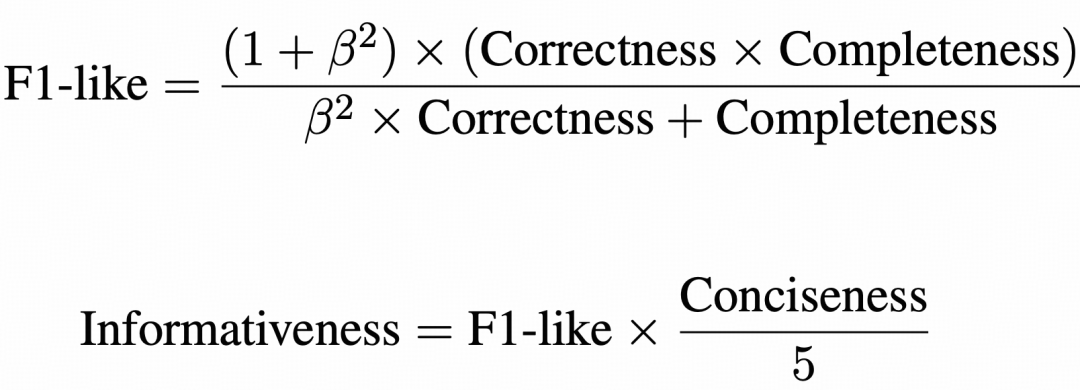
这套指标的出发点比较直接:科研问答既不能答错,也不能漏答,还不能用大量无关内容掩盖关键信息。
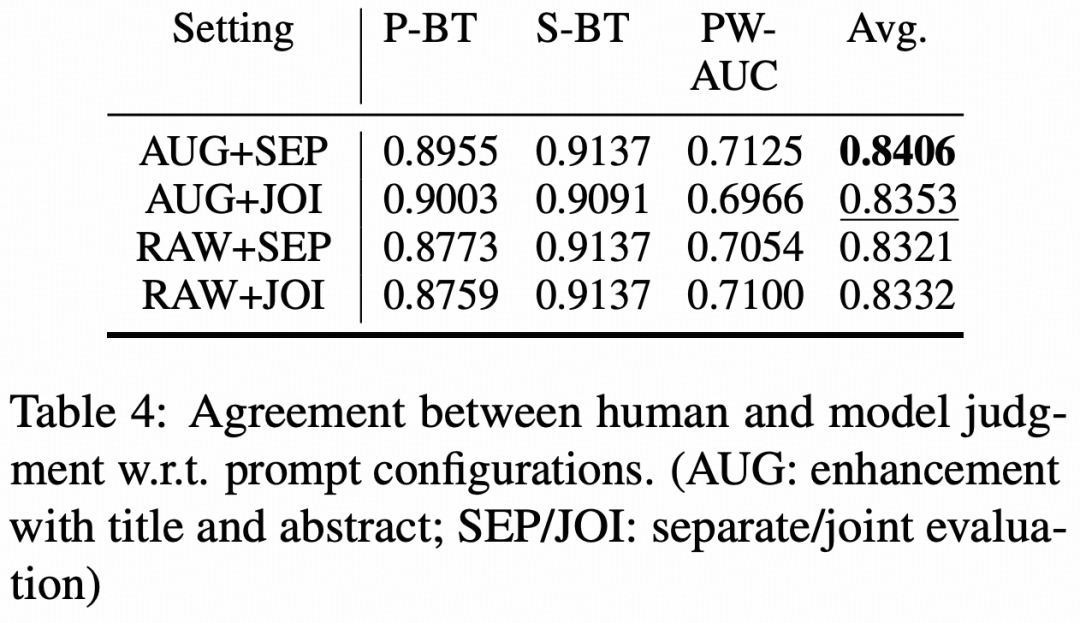
在评估配置上,论文通过人工一致性实验校准LLM-as-a-Judge设置,最终采用加入标题和摘要、分维度评估、decimal scoring的配置,并选择GPT-5与Gemini-3-Pro作为主实验的评估模型组合。
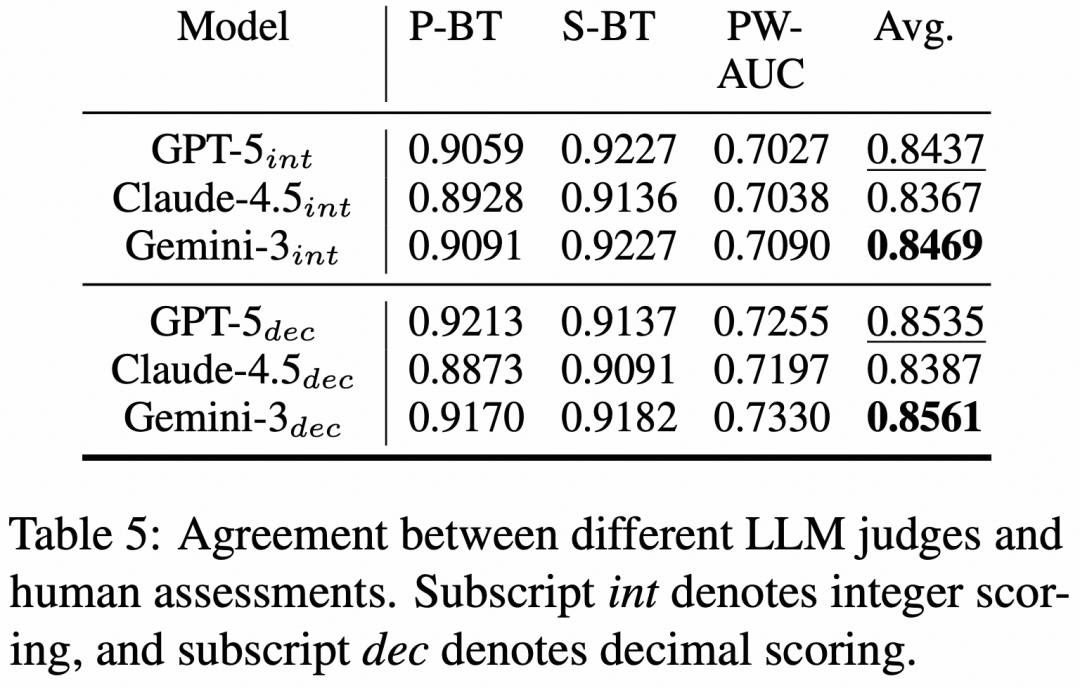
实验结果说明了什么?
论文评测了28个模型,包括LLM、Document-Centric Model、VLM和RAG方法:
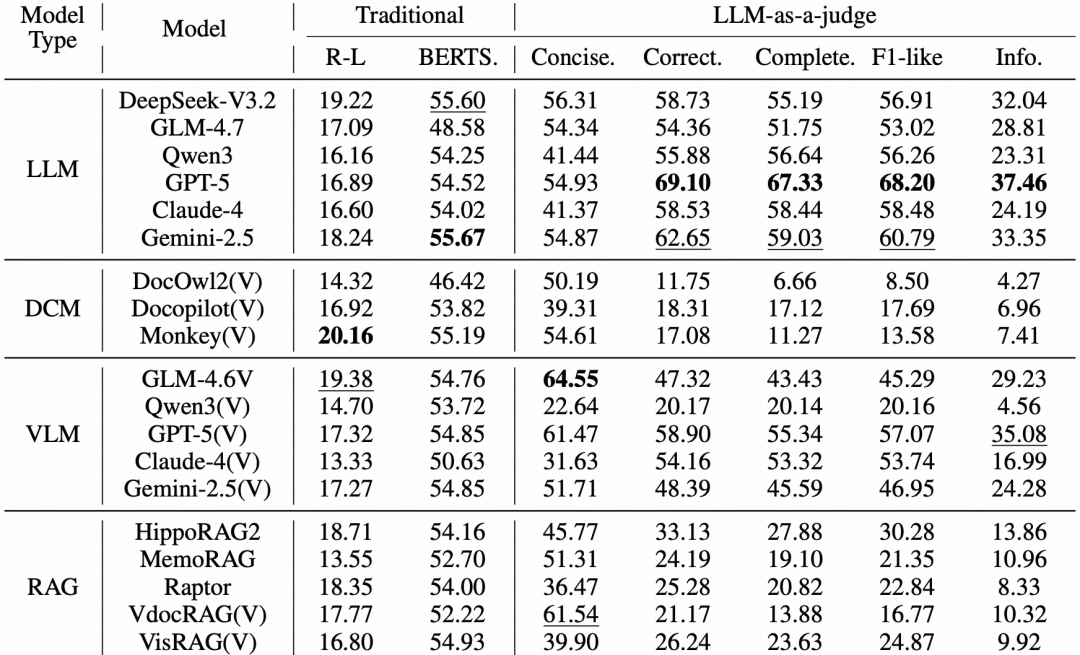
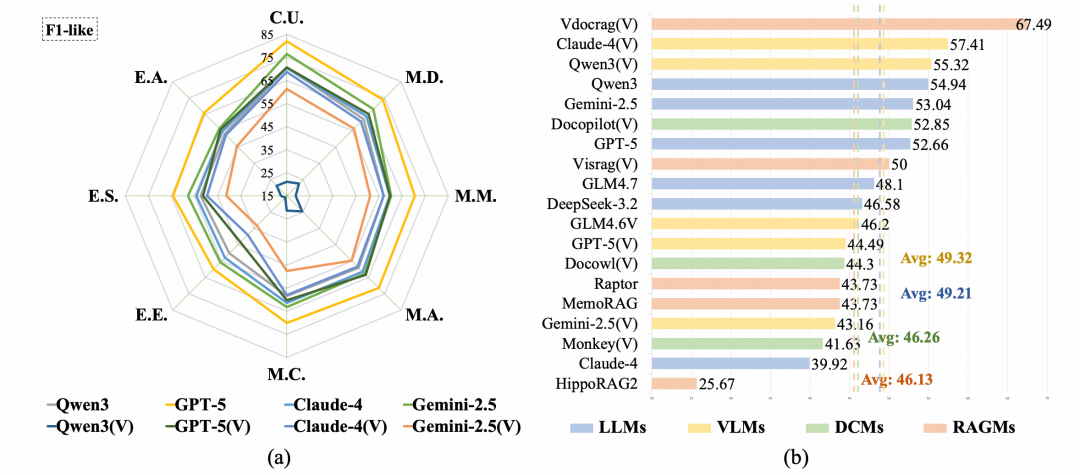
从这些结果中,可以观察到:
- 强模型仍有明显提升空间。GPT-5的F1-like为68.20,但加入简洁性约束后的Informativeness为37.46。
- 页面图像输入并不天然优于文本输入。当前VLM在长篇论文、图表、公式和跨页信息整合上仍然不稳定。
- RAG不是自动解法。检索片段不完整,或生成阶段不能整合方法与实验逻辑,都会导致错误或遗漏。
- 传统字符串指标信号有限。答案“看起来相似”不等于真正正确、完整。
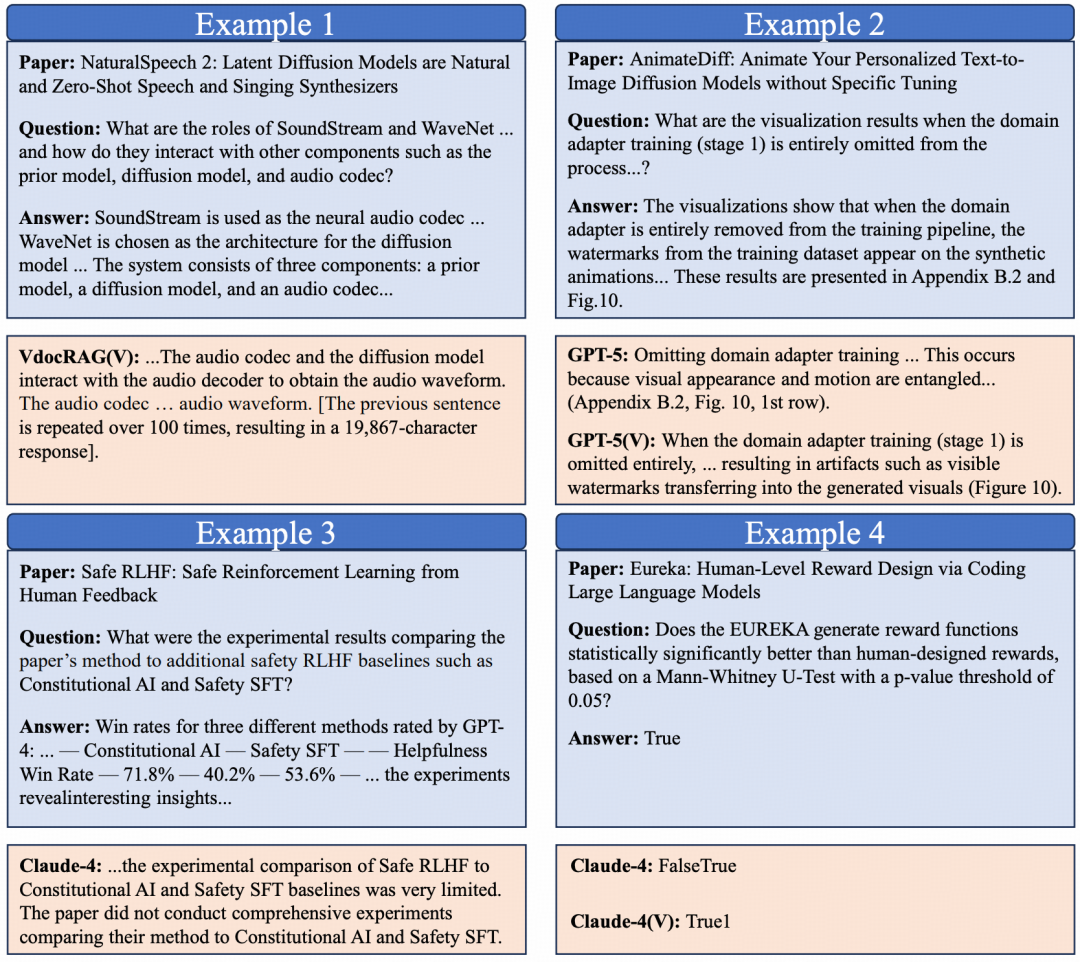
论文还通过case study总结了常见失败模式,包括退化重复输出、多模态证据利用不足、错误否认论文中已有信息,以及True/False等精确输出格式不合规。
当然,RPC-Bench也有清晰边界。它当前主要覆盖计算机科学领域,数据来自OpenReview,任务重点是单篇论文理解。跨论文综述、跨领域迁移、多轮科研讨论、真实代码复现和实验验证等能力,还需要进一步的评测设计。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢