
Qwen团队 投稿
量子位 | 公众号 QbitAI
传统认知默认:随着网络深度单调递增,思考结果也会变得更准确。
各类开源自回归大语言模型(LLM)的生成,也总是从最后一层输出。
然而,来自Qwen团队、清华大学、南洋理工大学的最新研究成果打破了这一固有假设。
他们揭示了一个普遍存在的“猜想-精炼-扰动”(Guess-Refine-Perturb)动态过程:
模型的中间层往往已经凝聚了最精准的推理语义,而对齐post-training(如 RLHF/DPO)则会在最末几层强加低秩steering扰动,使输出分布向通用、高频的“安全词”倾斜。这种现象被称为“对齐税”(Alignment Tax)。
为应对此种情况,研究团队提出了一种无训练、即插即用的解码策略——Confident Decoding(置信解码)。
实验表明,该方法在Dense和MoE架构上均可取得显著增益,在极难的科学、数学、代码评测集上实现明显的性能增长,且端到端wall-clock延迟增加不足 2%!

灵魂拷问:最后一层,真的总是最好的吗?
大模型在生成下一个Token时,标准做法(Standard Decoding)是将最后一层的隐状态经过Normalization和Unembedding映射到词表。这种方法暗含了一个底层假设:模型层数越深,表征能力越强,最后一层是模型内部计算与最终输出之间的“自然且最优接口”。
然而,真的是这样吗?
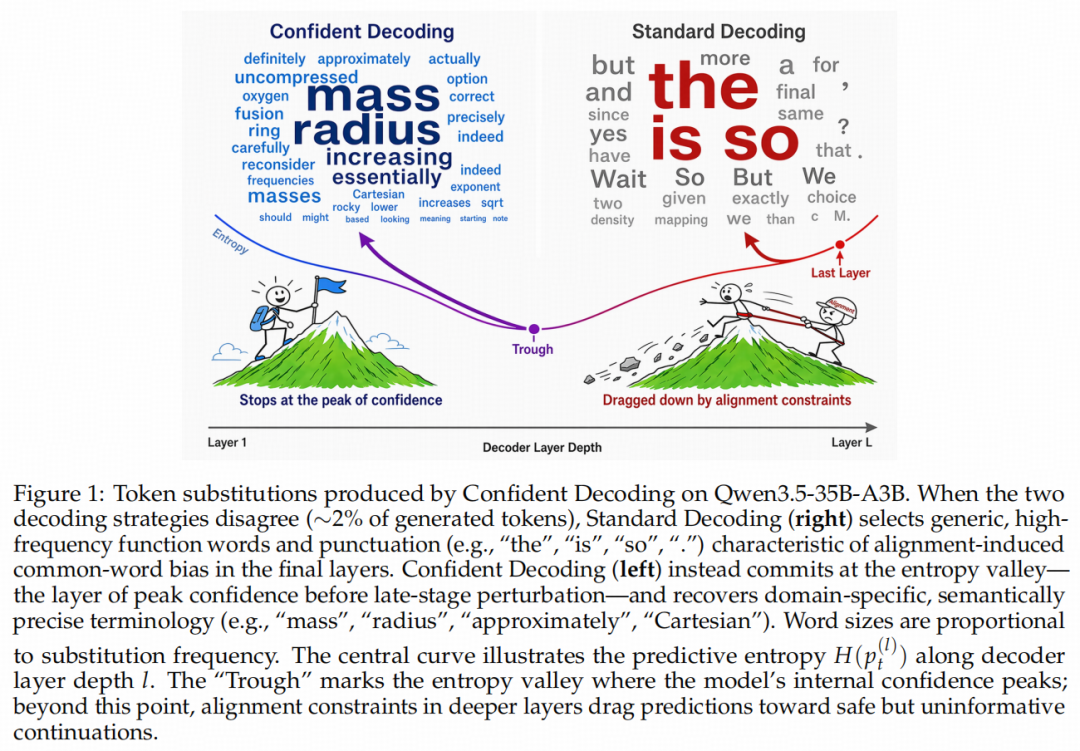
在处理复杂的数理问题时,模型的中间层(熵谷Trough处)其实已经胜券在握,其内部高度确信应该输出mass(质量)、radius(半径)、Cartesian(笛卡尔)等领域内高精度、强语义的词汇。
然而,一旦进入最末几层,受到对齐约束(Alignment Constraints)的强行拉扯,模型在最终层往往屈服于那些泛泛的高频功能词或标点,如the、is、so等。这种现象在复杂推理中导致了致命的“规划-语用权衡”(Planning-Pragmatics Tradeoff):模型内部明明算出了正确的推理路径,却在临门一脚的表达上被带偏了。
为了探究这一底层机理,研究人员深入解构了LLM前向传播过程中残差流(Residual Stream)的动力学特征,量化分析了两个核心指标:
相对贡献模长(Relative Contribution Norm):刻画每一层对残差流的写入强度。 残差输入输出余弦相似度(Residual I/O Cosine Similarity):刻画每一层更新的方向保真度(Directional Fidelity)。
令人惊讶的是,模型的前向传播呈现出极其稳固的三阶段演流规律:
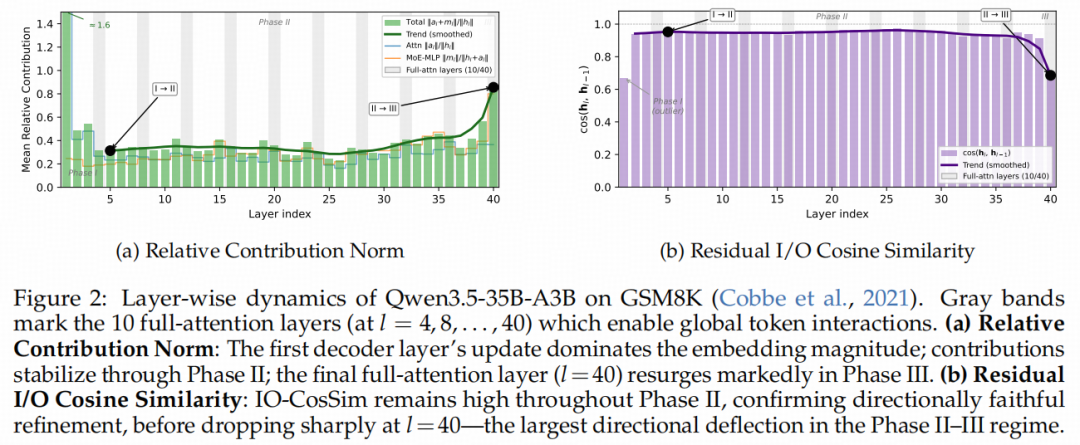
阶段I:猜想(Guess,浅层区,l≤0.15):写入强度极高(Norm Ratio约1.6),方向发生剧烈偏转。模型在极高的不确定性中迅速构建初始的潜在表征。 阶段II:精炼(Refine,中间层,0.15L≤l≤0.95):写入强度骤降并保持稳定(0.23-0.57),而方向相似度极高(0.91-0.97)。这意味着中间层在沿着一条稳定的语义轨迹进行方向保真的增量修正,不断融入上下文。 阶段III:扰动(Perturbation,最末几层,l≥0.95):在最后一层,写入强度反弹,同时方向相似度出现断崖式下跌。这一显著的方向性偏转表明,最末层引入了一个结构上不可忽视、且方向不一致的更新,部分重写并污染了阶段II辛辛苦苦精炼出的推理语义。
机理剖析:“对齐税”与“对齐安全护栏”的博弈
为什么大模型某些情况下会在最后一层发生这种语义偏转?这需要从后训练对齐(Post-training Alignment,如RLHF、RLAIF、DPO)说起。
表示工程(Representation Engineering)的研究表明,人类偏好对齐倾向于激活最末几层的低秩Steering向量。在形式化上,最末层的表征在优化一个正则化风险,被迫向一个通用、安全的分布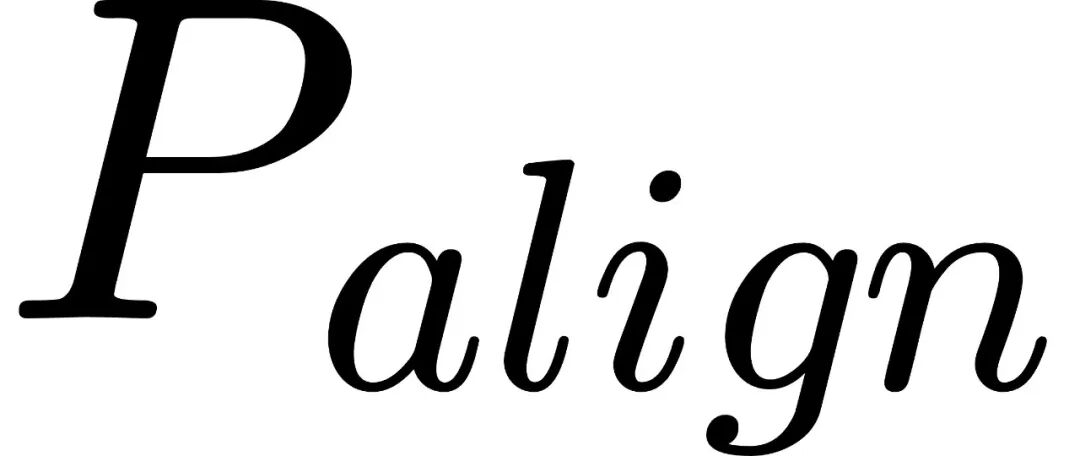 靠拢。
靠拢。
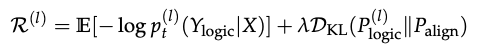
这种机制的影响是严格条件饱和的:
对齐作为安全护栏(Safety Guardrail):在普通的闲聊或涉及安全的Prompt中,推理逻辑分布  本就与安全分布
本就与安全分布 相近,最末几层的微调只会优化格式,而不会破坏语义。
相近,最末几层的微调只会优化格式,而不会破坏语义。对齐作为对齐税(Alignment Tax):但在严谨的数学、物理和代码世界中,特异性的逻辑分布 与通用的存在严重的空间冲突。最末层的Steering强行将潜在状态拉离推理子空间,在数学上直接表现为一种破坏逻辑链的“熵值反弹”(Entropy Oscillation)。
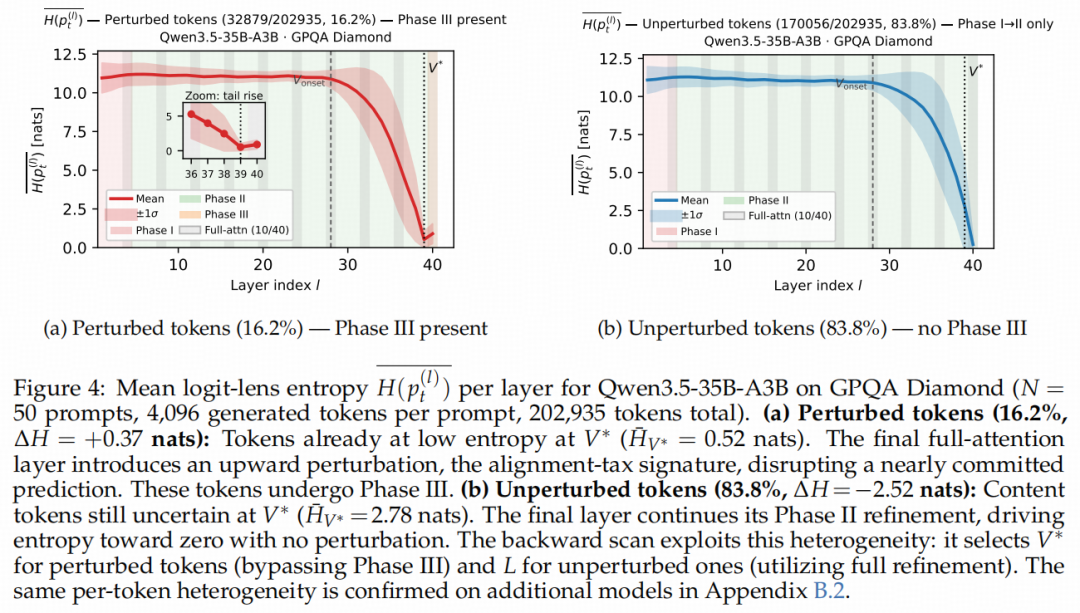
如上图(a)所示,在对Qwen3.5-35B-A3B进行Token级别的追踪时,有16.2%的Token表现出了显著的预测熵(Entropy)在末级回升的特征。这群Token恰恰是推理走向崩溃的“重灾区”(即发生了阶段III扰动)。而其余83.8%的Token(上图(b))则没有表现出扰动,末层依然在老老实实做精炼。
因此,一种理想的提取机制必须是Token自适应(Token-adaptive)的:既能在perturbed token上绕过阶段III,又能在unperturbed token上完整利用最后一层的精炼能力。
破局之法:Confident Decoding(置信解码算法)
为了捕捉这一动态边界,研究团队引入了“熵谷”(Entropy Valley)的概念。既然预测熵(Shannon Entropy)越低代表模型的内部确定性越强,那么扫描靠近末尾的隐层,寻找第一个局部熵最低点,就能近似地锚定模型在受到扰动前的“最自信、最纯净”的语义状态。
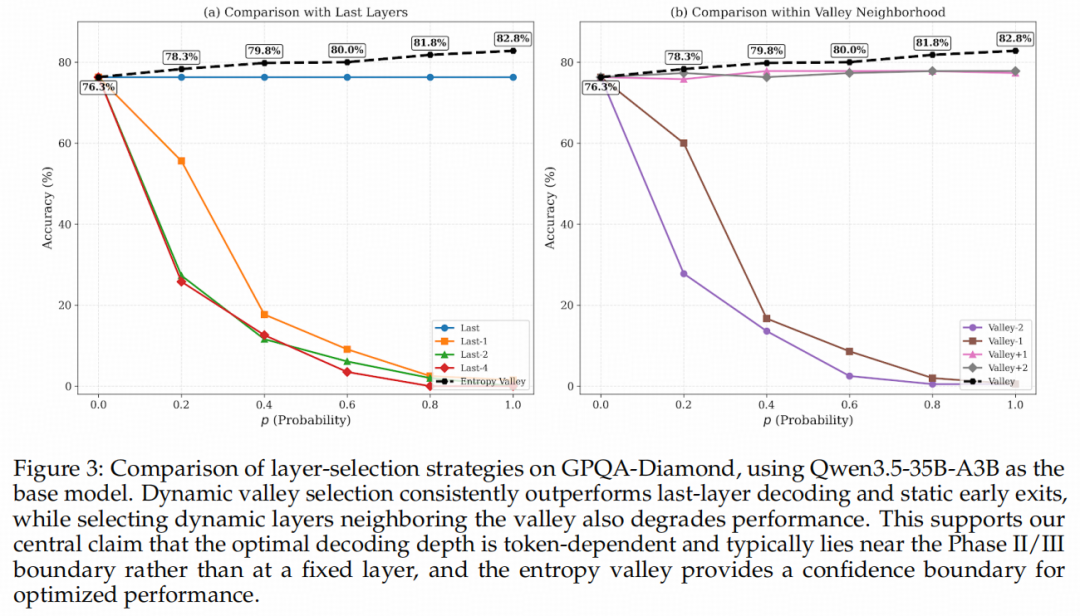
下图提供了与传统算法的鲜明对照。静态提早退出(Static Early Exit)策略由于对所有Token一刀切,会粗暴地掐断困难Token必需的计算量,导致推理正确率雪崩。而基于熵谷(Entropy Valley)的动态选择策略不仅能保持极高准确率,甚至显著超越了标准最后一层输出。
下面是Confident Decoding的核心执行逻辑:

在每一代Token生成步:
模型依然完整执行所有L层的正向传播(这保证了KV Cache、Attention Kernel的行为完全不受干扰,具有工程兼容性)。 从最后一层L开始,沿着一个近末端的候选窗口C,逆向扫描(Backward Scan)预测熵 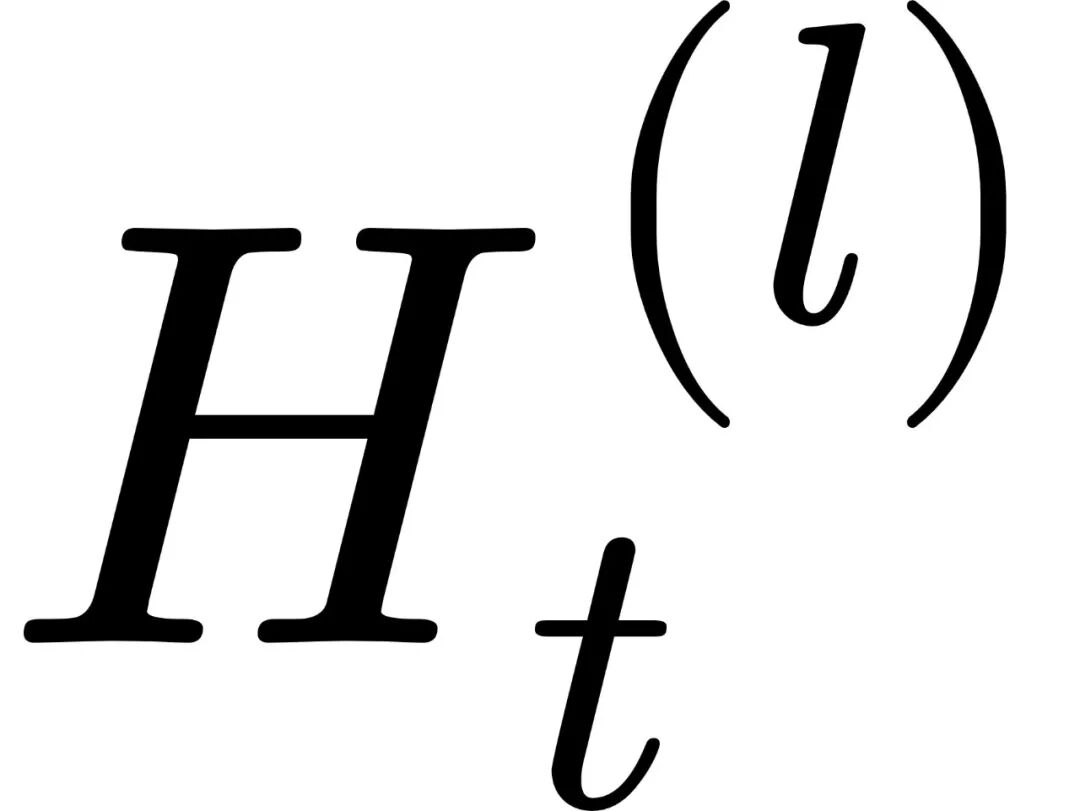 。
。同时一旦发现熵值不再随着层数变浅而严格单调下降(即遇到了第一个局部熵谷),便立刻冻结选择,将该层计算出的Logits送入Sampler。
理论保证:极小极大最优性(Minimax Optimality)
团队将动态层选择建模为一个最优停止问题(Optimal Stopping Problem)。在数学上证明了(Theorem 1),在投影噪声有界的前提下,这种保守逆向扫描机制能严格将选择层控制在对齐扰动发生前的区间内。它充当了一个确定性的过滤器,消除了对齐税带来的无界风险,同时将投影噪声的惩罚控制在渐进可忽略的界内。这也是为什么该算法天然具备“哪怕无益,损失也在可控范围内”的性能下界保证。

实验结果:全面激活模型的隐藏推理天花板
研究团队在Dense(Gemma-4)和高稀疏MoE(Qwen3.5、gpt-oss)等多种主流架构、不同参数量级上进行了大面积的横向评测。评测集涵盖研究生级科学难题(GPQA-Diamond)、多学科前沿评测(HLE)、奥林匹克级数学难题(Omni-MATH)、代码生成(LiveCodeBench v6)、安全对齐(Air-Bench 2024)以及长文本(LongBench v2)等。
全架构的通用普适性
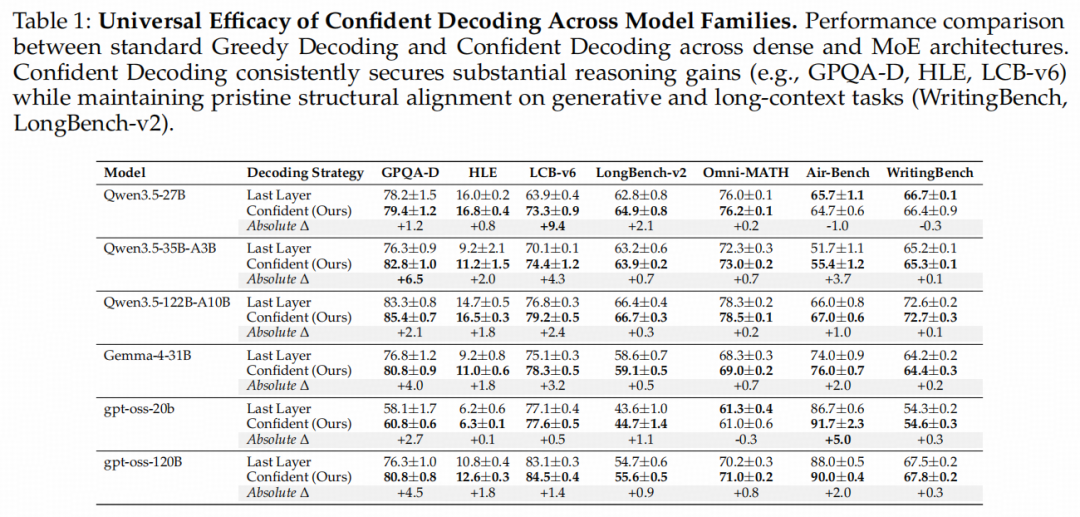
实验表明,Confident Decoding在所有模型家族上均取得了稳健的平均性能拉升:
在极其考验推理结构一致性的代码任务LiveCodeBench上,Qwen3.5-27B斩获了惊人的+9.4%绝对性能飞跃。 在硬核前沿科学推理GPQA-Diamond上,Qwen3.5-35B-A3B斩获了+6.5%的绝对提升。 同时,在安全对齐、长文本和开放式写作任务上,模型表现出了极佳的推理稳定性,这表明该算法完美保留了精炼阶段产生的stylistic及约束结构,而没有陷入末期的谄媚(Sycophancy)。
Instruct模型vs Base模型——确证“对齐税”的存在
为了彻底确证最后一层的生成退化(阶段III扰动)究竟是模型架构固有的缺陷,还是后训练偏好对齐(Post-training Alignment)带来的副作用,研究团队进行了一个因果隔离实验:对比Qwen3.5-35B-A3B-Base(纯预训练基座)与其经过人类偏好对齐的Qwen3.5-35B-A3B(Instruct指令微调版)。
按照理论推导,只进行了下文预测优化的Base模型,在残差流末端应当保持高度稳定的语义轨迹;而经历了密集DPO/RLHF策略优化的Instruct模型,在面对复杂逻辑时,最后一层会受到强烈的通用安全分布拉扯,从而产生更剧烈的阶段III扰动。
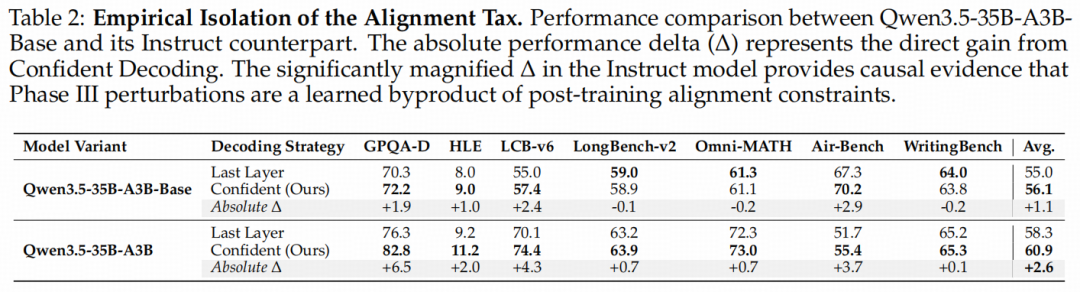
通过实验数据,我们可以得出三个具有启发性的洞察:
洞察一:对齐税的“因果实锤”,Instruct模型增益全面放大
实验数据显示,Confident Decoding为Instruct模型带来了高达+2.6%的全指标平均性能飞跃(从58.3%提升至60.9%),而为Base模型带来的平均增益仅为+1.1%(从55.0%提升至56.1%)。这种系统性的增益放大,提供了几何因果证据:最末层的表征退化并非硬件或架构底子不行,而恰恰是人类偏好对齐强加的“动态税收”。
洞察二:狂飙的推理释放,冲破临门一脚的“对齐干扰”
在极度依赖严密逻辑链的硬核科学评测GPQA-Diamond上,对齐税的破坏力暴露无遗。传统解码下,Instruct模型的最后一层由于受到泛化词偏置的干扰,得分停留在76.3%;而一旦使用Confident Decoding动态锁定熵谷、切断最末层的对齐噪声,Instruct模型的得分瞬间飙升了+6.5%绝对百分点,斩获82.8%的惊人成绩。相比之下,Base模型在该任务上仅提升了+1.9%(70.3%→72.2%)。这表明,该策略成功释放了对齐模型内部被压制的隐藏推理天花板。
洞察三:安全护栏未丢,反而治好了大模型的“过度防卫”
很多人担心,绕过最后一层对齐行为会不会导致模型变坏、丧失安全底线?安全评测集Air-Bench的数据给出了答案:使用Confident Decoding后,Base模型的安全性得分提升了+2.9%(67.3%→70.2%),而Instruct模型的安全性更是提升了+3.7%(51.7%→55.4%)。这强有力地证明,斩断末期扰动并没有剥离模型的安全基因。相反,它极大地缓解了模型在最末几层由于对齐Steering向量过度激活而导致的“幻觉性拒绝”(Overly Conservative Refusal),让模型能够以更严谨的逻辑、更合规的方式去正面回应复杂指令,实现逻辑fidelity与Rigorous合规性的双赢。
此外,这种宏观表现也得到了微观Token级别的严密验证。在Instruct模型中,backward scan成功为12.8%的Token锚定非平庸熵谷,而Base模型为10.4%。最终发生实际Token替换(Substitution)的硬替换率,Instruct模型(2.60%)也高于Base模型(2.36%)。这再次印证了:对齐程度越深,最末层遭受的偏转干扰就会越严重,而Confident Decoding的精准外科手术式干预也就越具威力!
难度越大,算法越强:惊人的规模扩展律
研究人员将数学评测集(MATH和Omni-MATH)按照基线模型的成功率划分为Level 1(最简单)到Level 4(最难)四个等级。
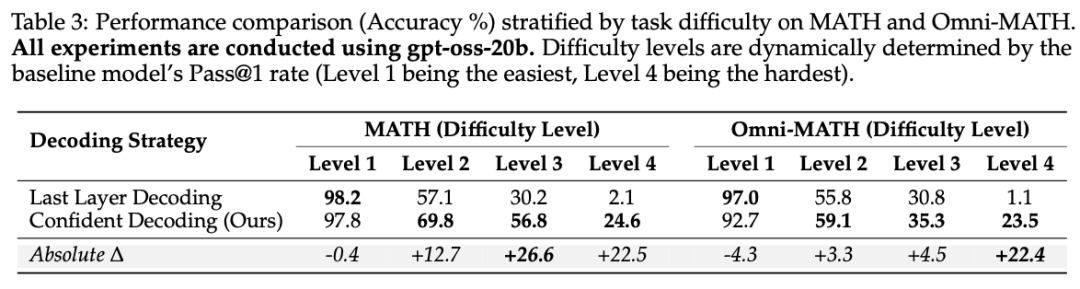
在Level 1的极简任务中,推理路径极短,天然符合通用安全分布 ,阶段III的扰动微乎其微。算法此时表现出边际效应(如MATH上微跌-0.1%到-0.4%),这符合理论预期,因为极其简单的Token在最后一层往往需要微调其表面语法和输出格式。
,阶段III的扰动微乎其微。算法此时表现出边际效应(如MATH上微跌-0.1%到-0.4%),这符合理论预期,因为极其简单的Token在最后一层往往需要微调其表面语法和输出格式。
然而,在面对Level 3和Level 4的极端难题时,模型必须深入低频、特异的专业语义子空间,对齐扰动的摧毁性达到了顶峰。在最难的Omni-MATH Level 4难题中,标准解码下的gpt-oss-20b推理能力彻底发生坍塌,正确率仅剩惨不忍睹的1.1%。然而,通过动态锁定熵谷并无情斩断阶段III扰动,Confident Decoding硬生生地将大模型从逻辑废墟中拯救了出来,取得了高达+22.4%的震撼性阶跃提升!
推向生产线:低于2%的极低工程开销
在生产级推理引擎(如vLLM)中部署任何层级干预算法,都面临着极其苛刻的延迟和图编译挑战。诸如连续批处理(Continuous Batching)、Tensor Parallelism、CUDA Graph Replay等技术,对任何动态内存分配或Python属性篡改都极度敏感。
研究团队在vLLM中通过以下三大工程原则实现了原生级别的安全适配:
完整前向传播流:完全不截断Transformer计算,L个Block全量跑完,使得KV Cache的复用、前缀缓存(Prefix Caching)以及调度器无缝平移,拥有零内存额外分配的优雅底色。 图安全(Graph-safe)候选提取:编译区只负责收集候选Tensor,将所有的归一化、Unembedding投影以及熵计算完全剥离至外层的Eager Language-Model Wrapper中。利用按形状(Shape-aware)索引的单次消费(Consume-once)协议,杜绝了CUDA Graph录制状态下的Buffer泄露或stale状态污染。 高度向量化的延迟更新:利用每Token冻结掩码(Per-token Frozen Mask),将逆向trough scan彻底坍塌为并行的Tensor融合操作,消除了任何高昂的Python逐Token循环。
在真实的FLOPs消耗和墙钟延迟审计中,该算法展现出了惊人的外科手术式外科介入特征:
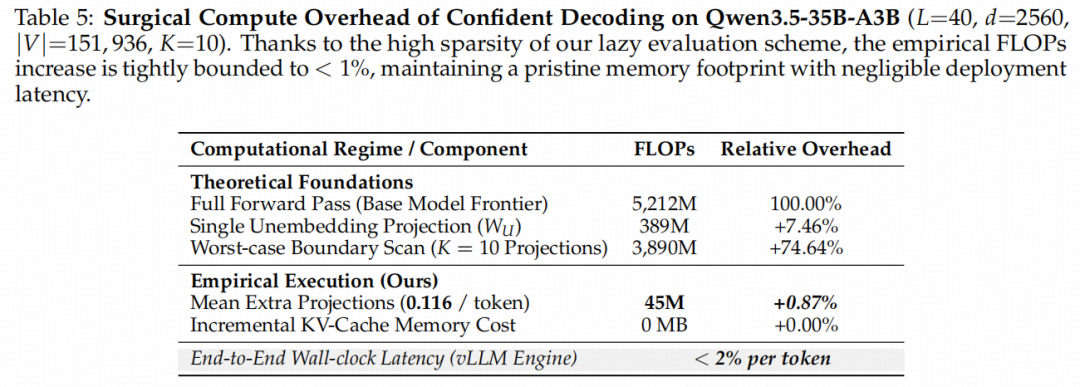
在实际运行中,由于88.5%的Token在最后一层其预测分布本就极度浓缩(预测熵H<0.01),算法会触发高度稀疏的Lazy Evaluation机制,快速跳过后续逆向扫描。
只有11.5%的扰动高危Token会启动逐层的backward scan,而其中最终发生Token实际替换(Substitution)的仅占全量生成Token的2.47%。这种极其克制的精准干预,使得端到端wall-clock推理延迟的增加被死死钉在了<2%的极低水准,完全适配高吞吐、低延迟的工业级大规模线上服务环境。
结语与展望:开启大语言模型“垂直TTC扩展”新范式
这项研究从根本上挑战了“LLM最后一层即最优表征”的常识,将后训练对齐带来的隐藏缺陷(对齐税)清晰地暴露在表示空间的几何结构中。
正如论文最后所总结的,大模型的Test-Time Compute(测试期计算扩展,TTC)不应该仅仅聚焦于在网络外部“想多久”(如Scaling CoT tokens),优化模型在网络内部的“在哪停”(Where to stop internally)同样蕴含着巨大的、尚未被充分发掘的红利。
Confident Decoding成功为对齐大模型构筑了一面垂直方向上的“架构护盾”,为估计Transformers模型的内部推理深度提供了一种可行的估计方法。未来,研究团队将进一步探索在训练期将偏好对齐专门施加于特定的专用路由头,而非污染核心残差流的底层方案;同时,利用隐层的熵几何结构来设计更为精准的强化学习(RL)奖励函数,同样是走向natively稳健、不简单向对齐妥协的下一代原生推理大模型的重要技术前沿。
论文链接:https://arxiv.org/abs/2606.21906
Github:https://github.com/QwenLM/Confident-Decoding
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
【学术投稿】请在工作日发送邮件至:ai@qbitai.com,标题注明【投稿】,并告诉我们:你是谁,从哪来,投稿内容附上项目/主页链接,以及联系方式。
🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢