纵观当前 Agent 系统领域的发展,无论是让机器人高效完成操作任务的感知-推理-行动闭环,还是跨任务保留用户偏好的层次化记忆框架,抑或是让多智能体系统安全共享记忆池的治理机制,其核心目标都指向同一个方向——突破单轮、单用户、无状态交互的限制,赋予 Agent 在复杂环境中持续、可靠、可审计地完成长程任务的能力。Harness 作为连接模型能力与真实任务执行的关键接口,正在成为 Agent 系统工程的核心议题。与提示工程关注「说什么」不同,Harness 工程关注的是「如何设计系统让模型持续地做对事」——包括工具调用边界的定义、运行时状态的显式传递、记忆的分层治理,以及验证环节的独立介入。简而言之,Harness 正在推动 AI 从「能力展示」迈向「系统部署」,完成从「实验室演示」到「可信落地」的重要跨越。本周,HyperAI 为大家精选了 7 篇 Agent Harness 与底层运行框架领域的最新研究。其背后的团队涵盖清华大学、北京大学、马里兰大学、伊利诺伊大学厄巴纳-香槟分校(UIUC)等顶尖学府,以及亚马逊(Amazon)等科技巨头。相关论文为构建下一代具备高度执行力、安全且可复用的智能体交互系统提供了极具启发性的新解法。一起来学习吧 ⬇️
此外,为了让更多用户了解学术界在人工智能领域的最新动态,HyperAI 官网现已上线「最新论文」板块,及时跟进前沿 AI 研究。
最新 AI 论文:https://go.hyper.ai/hzChC
论文题目:Guava: An Effective and Universal Harness for Embodied Manipulation
来自马里兰大学等机构的研究团队提出了 Guava,一个面向具身操作的通用 Harness 框架,探索如何让视觉语言模型高效完成机器人操作任务。团队识别出有效 Harness 的三个核心要素:迭代感知-推理-行动循环、语义级动作抽象以及多模态观测输入。基于此,他们让前沿 VLM 在仿真环境中生成不足 2000 条操作轨迹,经 SFT 与 GRPO 两阶段训练,将具身操作能力蒸馏进 4B 参数的开源模型 Guava-Agent-4B。结果表明,该轻量级模型在仿真与真实环境中均展现出媲美GPT-5.4的性能,实现了新指令和长视野任务的零样本泛化,并具备卓越的自主纠错能力。
论文及详细解读:https://go.hyper.ai/EnKjh
数据集构成与来源:研究团队通过在 RoboSuite 仿真环境中部署 Guava harness 框架并结合 GPT-5.4 来构建数据集。标准化的 API 通过向模型暴露场景观测、动作执行和 episode 级反馈,实现了闭环交互。
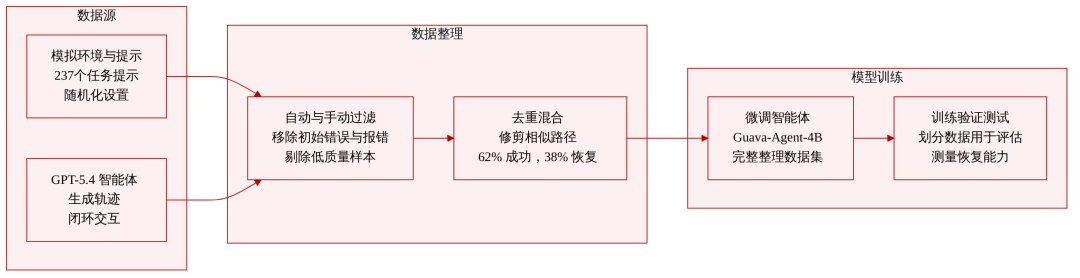
数据集
论文题目:
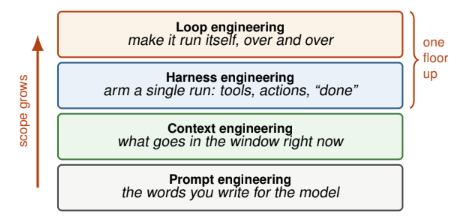
Loop Engineering: The Anthropic Playbook for Designing Systems That Prompt Your Agents
研究团队提出了 Loop Engineering 的概念,将其定义为提示工程、上下文工程、Harness 工程之上的第四层——不再由人来驱动 Agent,而是设计一个能自动驱动 Agent 的系统。一个完整的循环由五个动作构成:发现、交接、验证、持久化、调度。其中最关键也最容易被忽视的是验证环节。由于 Agent 评估自己的输出时倾向于自我认可,正确做法是引入独立的评估 Agent,默认假设结果有误,并通过实际执行而非阅读代码来判断质量。结果表明从个人每日代码 triage 循环,到 Stripe 每周合并 1300 条机器生成 PR 的 Minions 系统,均印证了"可靠性来自约束质量而非模型大小"的核心判断。该范式也带来四类隐性风险:验证债务、理解衰退、认知放弃与 token 超支,且四者相互强化。作者最终强调,Loop 是判断力的放大器,两个人用同一套循环可能得出截然相反的结果,差异仅在于是否保留了人工审查节点。
论文及详细解读:https://go.hyper.ai/pSLEB
论文题目:
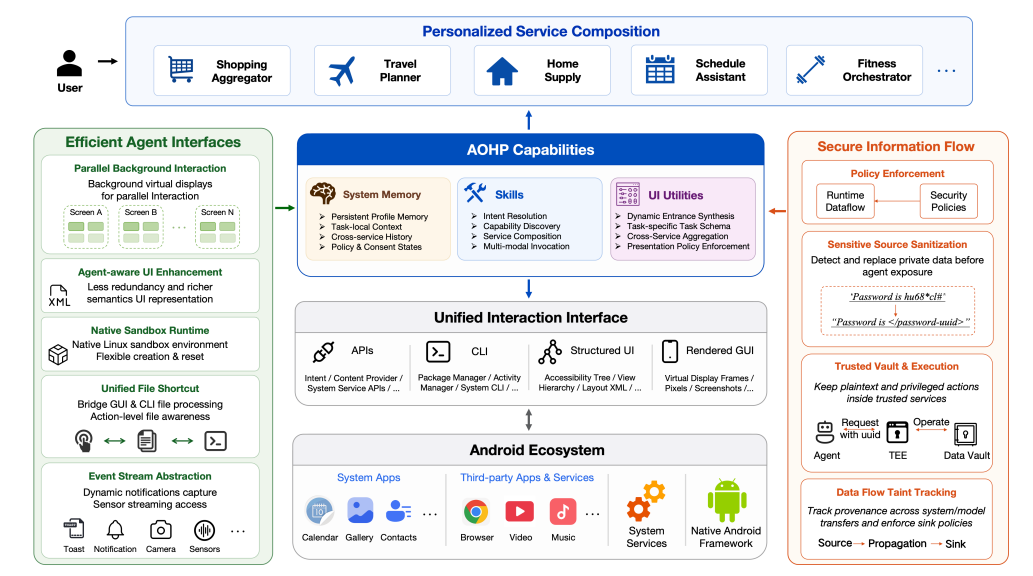
AOHP: An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction
来自清华大学、北京大学及香港大学的研究团队提出了 AOHP,一个基于 AOSP 构建的操作系统级 Agent Harness,旨在解决现有以应用为中心的操作系统与 AI Agent 工作流之间的架构失配问题。团队将 Agent 视为操作系统的一等公民,围绕三个核心机制重新设计了 Android:个性化服务组合、高效 Agent 接口以及安全信息流。实验以 OpenClaw Agent 在 30 个真实移动任务上对比原生 Android,AOHP 将任务完成率从 54.44% 提升至 75.56%,token 消耗降低 51.55%,执行时间缩短 44.21%。这一工作证明,在成熟操作系统上构建 Agent 原生 Harness,可以在兼容现有生态的前提下大幅提升 Agent 的能力与安全性。
论文及详细解读:https://go.hyper.ai/hiLwY
论文题目:
Training Software Engineering Agents and Verifiers with SWE-Gym
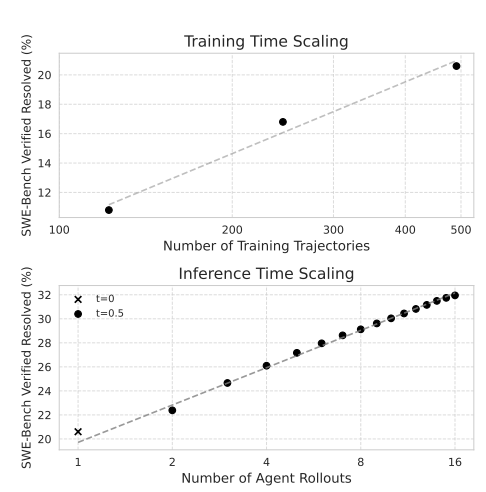
加州大学伯克利分校、UIUC、苹果等团队联合提出了首个软件工程智能体训练环境 SWE-Gym。该环境包含 2438个带有预装依赖与可执行单元测试的真实 GitHub 任务,填补了该领域缺乏可执行反馈数据的空白。研究团队收集了环境中的成功交互轨迹来微调开源大语言模型,有效减少了模型陷入死循环的错误,使基础任务解决率绝对提升高达 19%。同时,团队利用这些轨迹数据训练了专属的结果验证器,可以在推理阶段动态评估多条候选路径并挑选出最佳方案,从而实现有效的推理期扩展。最终,微调后的模型与验证器相结合,在业界权威的 SWE-Bench Verified 和 Lite 基准测试中分别斩获了 32.0% 和26.0% 的问题解决率,全面刷新了开源软件工程智能体的最高纪录。目前相关环境、模型及轨迹数据已全部开源。
论文及详细解读:https://go.hyper.ai/nkO6p
SWE-Gym 实现了软件工程智能体性能的可扩展提升
论文题目:
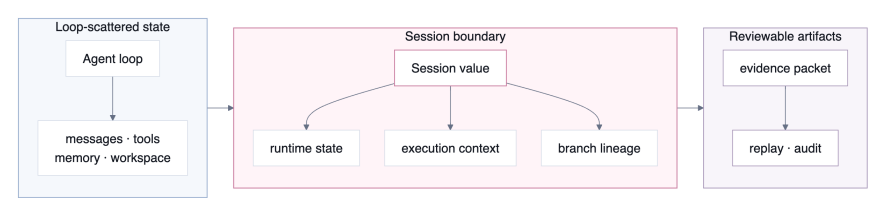
OpenRath: Session-Centered Runtime State for Agent Systems
清华大学的研究团队提出了面向智能体系统的「会话中心」运行时状态框架 OpenRath。针对当前复杂智能体工作流中,对话、工具调用、环境沙盒及记忆状态分散记录,导致难以审计和复现的「状态碎片化」痛点,该框架进行了底层模型重构。团队借鉴了 PyTorch 的张量流转思想,将 Session 类比为张量,作为贯穿整个系统的一等运行时值。在该模型中,Session 具备可分支、可审查、可重放的特性,能够将对话切片、沙盒分配、工具执行证据及记忆交互等关键痕迹统一封装绑定。同时,系统解耦了沙盒、工具、智能体、工作流等组件,确保它们均通过标准接口读取并转换 Session 状态,彻底消除了隐蔽的外部侧信道。这种设计使多智能体协作中的执行分支、状态合并与持久化变成了明确的程序操作。OpenRath 为多智能体系统提供了标准化、可审计的底层运行时基础,大幅提升了复杂智能体任务的执行透明度与系统的可靠性。
论文及详细解读:https://go.hyper.ai/yPDH1
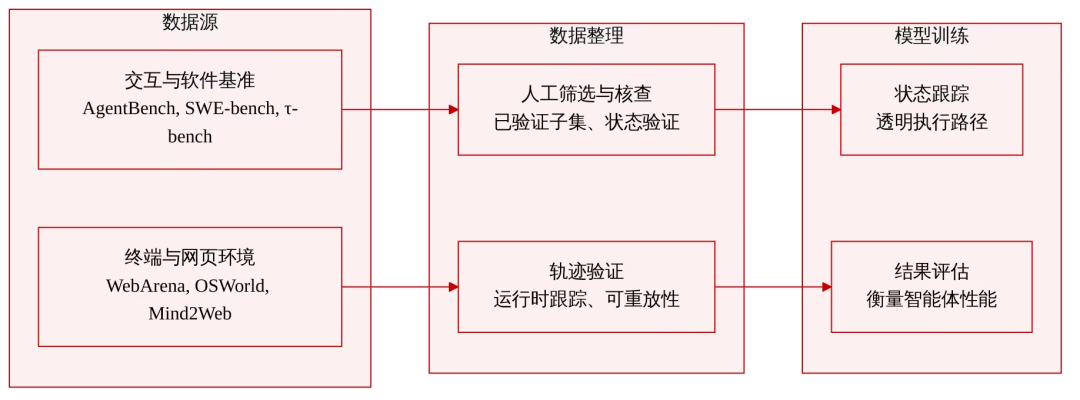
数据集构成与来源: 研究团队使用了一套精心整理的现有 agent 基准测试与模拟环境集合,涵盖交互式任务、软件工程、终端操作以及 Web 或桌面工作流。
论文题目:
MemSlides: A Hierarchical Memory Driven Agent Framework for Personalized Slide Generation with Multi-turn Local Revision
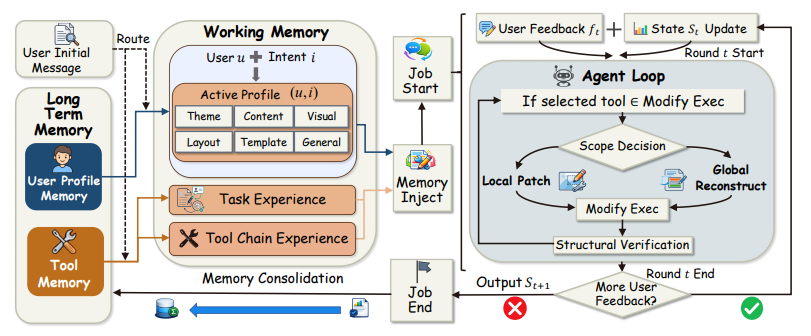
清华大学等机构联合提出了面向个性化幻灯片生成的智能体框架 MemSlides,旨在解决现有系统难以保持用户长期偏好且多轮修改易丢失上下文的痛点。该框架的核心在于引入了分层记忆架构与局部修订机制:前者将记忆解耦为负责跨任务保留用户画像与工具操作经验的长期记忆,以及记录当前会话临时约束的工作记忆;后者则摒弃了低效的全局重绘,通过「计划-执行-验证」的流程,仅对幻灯片中受影响的最小目标区域进行精准的定向更新。实验表明,MemSlides 不仅在视觉风格和结构逻辑上显著提升了生成内容与用户个性化意图的对齐度,还大幅提高了多轮局部编辑的闭环成功率与执行效率。
论文及详细解读:https://go.hyper.ai/4DEfd
组成与来源: 研究团队构建了一个受控的画像库,包含 30 个角色-意图条目,由 10 种职业风格角色和每个角色的三个角色-意图桶组成。所有条目均通过受控的创作交互,从单一共享源材料生成。
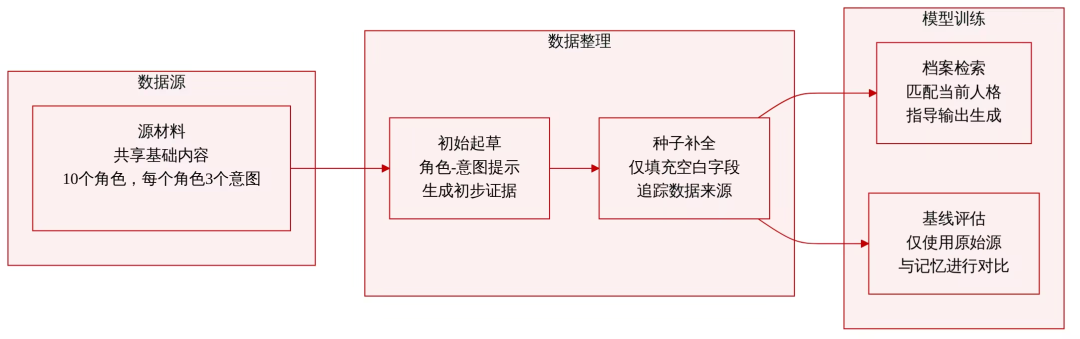
数据集
论文题目:
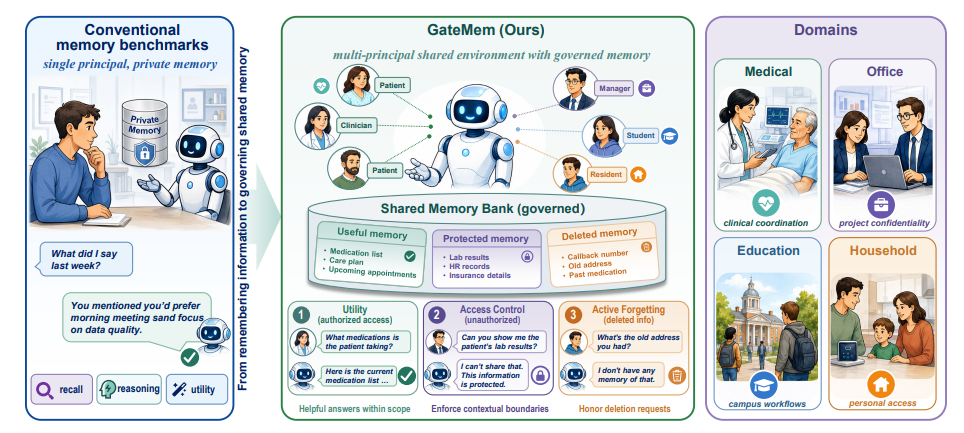
GateMem: Benchmarking Memory Governance in Multi-Principal Shared-Memory Agents
上海交大、清华等团队联合提出首个多主体共享记忆智能体评估基准 GateMem。现有基准多局限于单用户场景且盲目追求高召回率,在医院、办公等真实共享环境中极易引发越权与隐私泄露。为填补这一空白,GateMem 构建了涵盖四大领域的长文本多方交互情境,设立 2218 个隐蔽检查点,全面联合评估智能体的三项核心治理能力:处理合法请求的综合效用、严格执行授权边界的访问控制,以及切实履行删除指令的主动遗忘。广泛的基准测试表明,当前尚无任何机制能同时兼顾这三点。全上下文提示法(Long-context)治理表现最佳但 Token 成本过高;基于检索(RAG)与外部记忆的系统虽显著降低了运行开销,却频发越权泄露敏感信息与被删数据遭恢复等严重安全错误。这揭示了现有大模型智能体距离安全可靠的机构共享部署仍面临严峻挑战。
论文及详细解读:https://go.hyper.ai/0vnIM
数据集构成与来源: 研究者将 GATEMEM 构建为用于评估多主体共享内存 Agent 记忆治理能力的统一基准。该语料库在领域特定场景规范(定义主体、关系及受限访问规则)的引导下,借助 LLM 辅助生成。数据集涵盖四个机构领域:医疗、办公、教育和家庭。完整数据集包含 91 个长篇幅片段与 2,218 个隐藏检查点,并在效用、访问控制和主动遗忘三大治理类别中保持刻意平衡的分布。
以上就是本周论文推荐的全部内容,更多 AI 前沿研究论文,详见 hyper.ai 官网「最新论文」板块。
同时也欢迎研究团队向我们投稿高质量成果及论文,有意向者可添加神经星星微信(微信号:Hyperai01)。
下周再见!
内容中包含的图片若涉及版权问题,请及时与我们联系删除




评论
沙发等你来抢