
DRUGONE
GPT-5、Gemini 等大型前沿模型已经在多种健康 AI 应用基准测试中表现出很强能力。然而,在这些看似令人鼓舞的结果背后,仍存在明显的成长空间,尤其是在多模态医学推理等前沿任务中。研究人员系统性地设计并整合了一系列对抗性压力测试,用于评估旗舰模型和健康基准测试本身的稳健性。
研究人员发现,当前领先模型在面对简单对抗性变化时普遍表现脆弱。模型有时即使关键输入被移除,例如医学图像被删除,也仍能猜中正确答案;但另一方面,轻微提示变化或选项顺序调整又可能使模型困惑。更值得关注的是,当模型被要求解释其判断时,它们可能生成看似有说服力但实际上存在错误的推理过程。研究人员进一步使用临床医生指导的评价准则分析常用健康基准,发现这些基准在真实测量内容上差异很大。总体而言,该研究揭示了基准成绩与支持健康应用中多模态医学推理可靠性所需证据之间的显著差距。

大型语言模型在健康应用中已经展示出令人印象深刻的能力,例如通过医学考试、在诊断基准上取得高分,以及在医学问答任务中接近甚至超过人类专家表现。由此,许多人开始对大型前沿模型在健康 AI 中的应用前景保持乐观。然而,这些高分并不必然意味着模型具备真实临床场景所需的稳健性、可解释性和可靠推理能力。
现有研究已经指出大型语言模型存在幻觉、错误推理、过度自信和对提示敏感等问题,但许多研究主要集中在文本模态。相比之下,多模态医学推理仍然研究不足。随着多模态生成式 AI 成为生物医学人工智能的重要方向,评估模型是否真正理解图像、文本和临床上下文之间的关系变得十分关键。
研究人员借鉴对抗学习领域揭示早期深度学习脆弱性的思路,对医学多模态基准中的测试样本进行系统扰动,从而测试大型前沿模型是否真正依赖医学图像、是否能抵抗格式变化、是否会被无关干扰项影响,以及其生成的推理解释是否可信。结果显示,模型在标准基准上看似稳定进步,但在压力测试下暴露出完全不同的行为图景。模型可能在没有图像的情况下仍然答对,也可能在答案选项被打乱后表现下降,还可能为一个正确答案编造不存在的视觉依据。
这些发现进一步促使研究人员反过来审视医学 AI 基准本身。研究人员提出临床医生参与的评价准则,尝试拆解一个测试题究竟在测量什么:是图像感知、医学知识、临床推理、答案格式识别,还是某种记忆性关联。结果表明,不同多模态医学基准的测量目标差异很大,却常常被当作可互换的“模型能力分数”。因此,研究人员认为,单纯依赖排行榜分数不足以证明大型前沿模型已经具备健康 AI 应用准备度。
方法
研究人员选取多个常用多模态医学基准和代表性大型前沿模型,构建了一套由六类压力测试组成的评估框架。前两类测试关注输入模态是否必要,包括移除医学图像并观察模型是否仍能回答,以及构建必须依赖视觉信息的 NEJM 子集来检验模型是否会在缺失图像时仍然猜测。第三和第四类测试关注快捷线索和格式依赖,包括打乱答案选项顺序、替换错误干扰项,以及加入 “Unknown” 选项来观察模型是否将其当作可排除线索而非不确定性表达。第五类测试替换医学图像,使图像支持不同诊断而文本和选项不变,用于检验模型是否真正根据视觉证据更新判断。第六类测试评估模型生成推理的可信度,包括链式思维提示是否提高准确率,以及模型解释是否包含真实图像证据、合理医学逻辑和与最终答案一致的推理。研究人员还设计了临床医生指导的基准画像准则,从推理复杂度、视觉复杂度、文本可解性、不确定性处理和多视角整合等维度对九个代表性医学基准进行分析。
结果
压力测试揭示大型语言模型的稳健性缺口
大型语言模型在多模态医学基准中常常取得较高分数,这些分数容易被解读为临床能力稳健的证据。然而,聚合准确率可能掩盖模型在输入不完整、提示扰动、图像冲突或选项变化下的脆弱性。为了超越单纯准确率,研究人员设计了六类压力测试,考察模型在退化输入、结构变化、干扰项、视觉替换和推理要求下的行为。
这些测试并不只关注模型是否答对,还关注模型是否知道何时应该拒答、是否能表达不确定性、是否在输入变化后稳定调整判断,以及生成的推理解释是否真实可靠。通过这种方式,研究人员不仅捕捉性能下降,还揭示了模型输出变化背后的原因,例如依赖表面线索、忽视图像输入、使用记忆性关联、在错误视觉理解上继续推理,或用流畅语言包装错误结论。
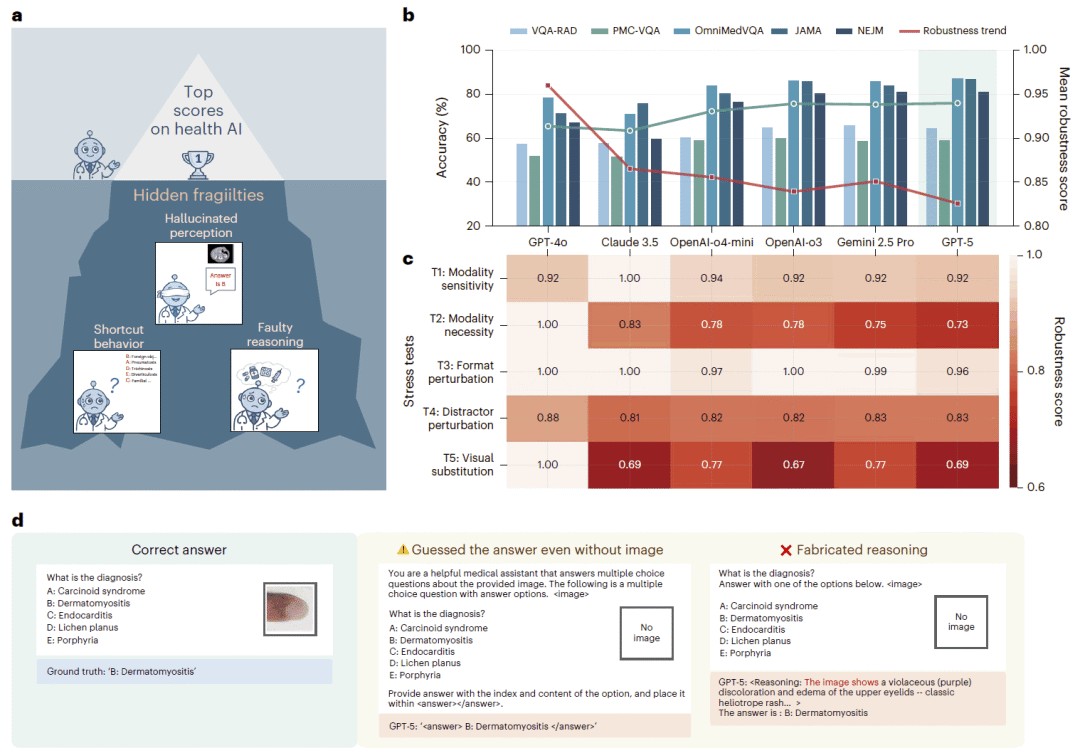
图1:压力测试揭示健康 AI 多模态应用中大型语言模型的隐藏脆弱性与稳健性缺口。
模态敏感性与输入省略
研究人员首先测试移除医学图像后模型表现如何变化。在 NEJM 和 JAMA 两个多模态医学基准中,每个问题通常由简短临床描述和一张或多张诊断图像组成。如果模型真正依赖图像进行诊断,那么删除图像后性能应明显下降,并且模型应当表达不确定或拒绝作答。
在 NEJM 数据中,大多数模型在移除图像后准确率明显下降。例如,GPT-5 和 Gemini 2.5 Pro 在完整输入下表现较高,但去掉图像后均下降十多个百分点。这说明 NEJM 中许多问题确实需要视觉信息。但在 JAMA 数据中,移除图像后的下降较小,提示部分 JAMA 问题可能主要由文本线索即可回答,而不是强依赖图像理解。
为了进一步测试视觉输入是否真正必要,研究人员构建了 NEJM 视觉必需子集。该子集由临床标准筛选,包含文本线索少、诊断高度依赖图像特征的病例。在完整输入下,模型能达到中等到较高准确率,说明这些题目在图像可见时是可解的。然而,在文本-only 条件下,多数模型仍远高于随机猜测水平。也就是说,即使图像对诊断至关重要,模型仍可能依赖非视觉线索、疾病流行率、选项模式或训练中记忆的关联来猜测答案。
GPT-4o 在缺失图像时表现出更高拒答率,因此总体准确率较低;但如果排除拒答项,其答题准确率接近其他模型。这提示 GPT-4o 的低分并不一定代表更少快捷学习,而可能反映更保守的不确定性处理。研究人员认为,理想模型在关键输入缺失时不应盲目猜测,而应明确说明图像缺失使判断不可靠,或选择拒答。
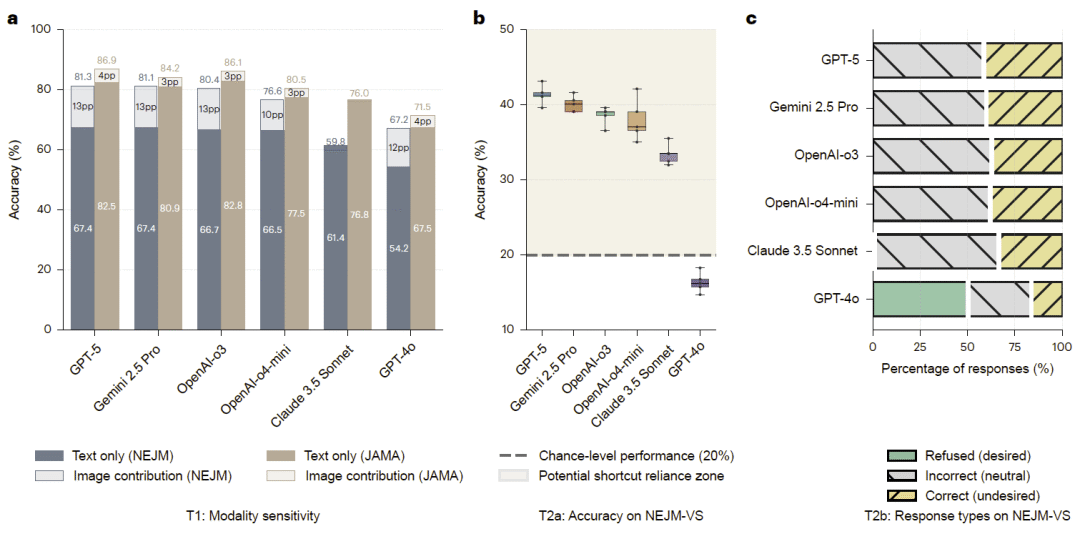
图2:模态敏感性和输入省略测试揭示模型对图像缺失的异常反应。
输入扰动下的快捷线索依赖
研究人员接着考察模型是否依赖表面格式或答案选项中的快捷线索。首先,他们打乱多选题答案选项的顺序,但不改变题干内容或正确答案本身。如果模型真正理解问题,答案顺序变化不应显著影响表现。然而,在文本-only 条件下,多数模型准确率出现下降,说明模型可能部分依赖选项位置、常见答案排列或格式模式。相比之下,在图像和文本同时存在时,性能相对稳定,甚至略有提高,提示视觉信息可能在一定程度上弥补文本快捷线索被破坏带来的影响。
随后,研究人员替换错误干扰项,测试模型是否依赖熟悉干扰项进行排除。在文本-only 条件下,当越来越多错误选项被替换为无关选项时,模型准确率逐步向随机水平下降。这表明模型并不总是在真正理解诊断,而可能依赖某些熟悉选项组合中的相对关系来作答。当一个错误干扰项被替换为 “Unknown” 时,多数模型准确率反而上升,尤其是在缺失图像的文本-only 条件下更明显。研究人员认为,这说明模型往往把 “Unknown” 当作容易排除的语义选项,而不是在关键信息缺失时的合理 fallback。
总体来看,这些扰动测试揭示了大型前沿模型在健康应用基准中的脆弱性。如果模型真正理解医学图像、临床上下文和诊断知识,那么它应能抵抗答案顺序变化、错误选项替换和无关干扰项变化。当前模型在这些轻微扰动下表现不稳,说明距离临床实用所需的稳健性仍有差距。
多模态 grounding 失败
为了更直接测试模型是否真正理解图像内容,研究人员设计了视觉替换测试。他们选取 40 个诊断高度依赖图像的 NEJM 问题,将原始图像替换为临床上合理但对应某个错误选项的替代图像,同时保持题干和答案选项不变。替换图像均由临床医生确认能够支持新的诊断答案。因此,可靠模型应当根据新的视觉证据改变答案,而不是继续选择原始文本对应的答案。
结果显示,多数模型在视觉替换后性能明显下降。GPT-5、Gemini 2.5 Pro、o4-mini 和 o3 均出现显著准确率下降。这说明模型虽然常常能检测图像与任务相关,但并不能稳定地根据图像证据动态重解释诊断。它们可能仍依赖原始题干、常见图像—答案关联,或预训练中形成的静态模式,而不是在当前图像和临床文本之间进行真实整合。
研究人员指出,视觉替换测试隔离了视觉 grounding 能力,因为文本没有变化,只有诊断图像发生变化。模型如果不能随视觉证据改变而改变结论,就说明其多模态推理能力被标准基准准确率高估。残余性能可能来自对部分通用视觉特征的识别、模型过度自信,或训练中对常见图像—问题组合的记忆。无论原因如何,这种脆弱性都会削弱临床诊断场景中的可信度。
推理信号完整性
研究人员进一步评估模型在多模态医学问题中如何生成和使用推理。首先,他们在 NEJM 和 VQA-RAD 上使用链式思维提示,观察显式推理步骤是否能提高准确率。结果并不理想。在 NEJM 上,链式思维提示对所有模型都带来负向收益;在 VQA-RAD 上,推理模型只获得很小提升,非推理模型获得轻度提升。在 OmniMedVQA 上,提高推理强度的影响很小且不稳定,有时更长的推理链会增加召回,但也会引入更多幻觉细节。
随后,研究人员人工审查模型生成的解释,重点判断其事实性、视觉 grounding 以及与最终答案的一致性。审查发现三类反复出现的问题。第一类是答案正确但逻辑错误,模型给出看似合理但包含虚假视觉发现的解释。第二类是视觉误解被放大,模型在最初看错图像后,将错误感知沿着后续推理继续扩展。第三类是结构完整但内容空洞,模型生成语法流畅、层次清晰但临床上无关或不能支持答案的推理步骤。
这些结果说明,解释流畅并不等于推理有效。大型模型能够生成结构化且令人信服的医学解释,但这些解释可能包含不存在的图像特征、错误医学逻辑或与真实决策过程无关的叙述。从临床转化角度看,模型推理过程本身也需要独立验证,不能因为模型能够“解释”就认为其具有可靠可解释性。
失败模式分类
综合六类压力测试,研究人员将模型失败模式归为三个阶段:输入处理、推理与推断、输出沟通。在输入处理阶段,模型可能出现视觉误感知、拒答校准不当或忽视某个模态。在推理阶段,模型可能依赖启发式线索、生成不支持结论的解释,或在输入、输出和推理之间出现逻辑不一致。在输出沟通阶段,模型可能用流畅语言掩盖事实错误,或给出不安全、不完整的建议。
这些失败看似是技术问题,但在医疗环境中可能转化为实际临床风险。例如,视觉误感知可能导致漏诊或误报;拒答校准错误可能导致不安全猜测或延误诊疗;错误解释可能误导医生或患者;不安全建议可能导致诊断或治疗伤害。因此,研究人员强调,健康 AI 的稳健性评估必须把模型行为与潜在临床后果联系起来,而不应只报告平均准确率。
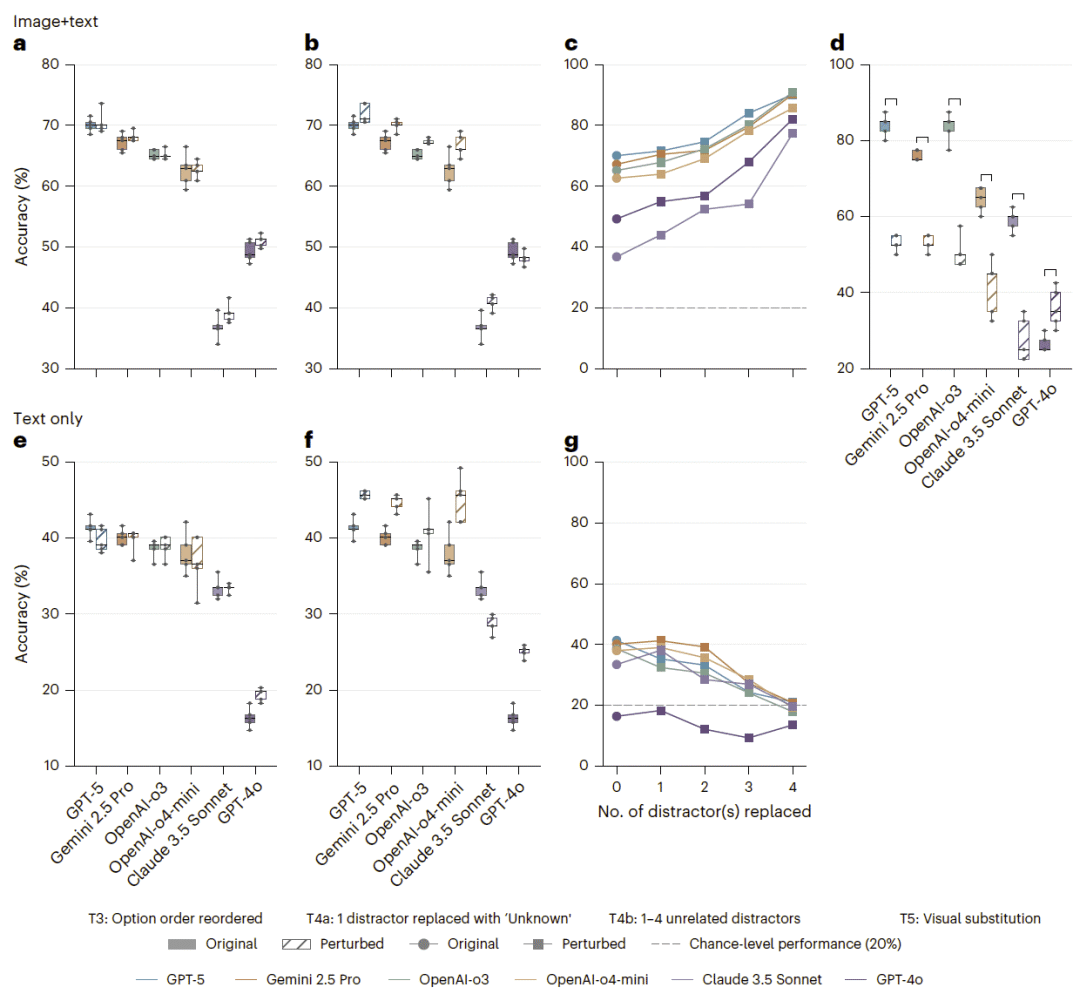
图3:输入扰动测试揭示模型对格式、干扰项和视觉替换的快捷线索依赖。
反向评估基准:我们到底在测量什么?
压力测试发现,高基准分数并不保证模型行为稳健。模型在标准条件下表现良好,但在图像移除、答案重排、干扰项替换或视觉输入误导时可能失败。更重要的是,这些失败模式在不同基准之间差异明显。例如,NEJM 在移除图像后性能下降较大,说明其更依赖视觉理解;JAMA 分数相对稳定,提示许多题目可以仅凭文本作答。类似地,不同基准对链式思维提示的反应不同,说明它们对推理复杂度的要求并不一致。
这引出一个关键问题:如果模型能在某些基准上取得高分,但在压力测试中失败,那么这些基准究竟测量了什么?它们测量的是视觉 grounding、医学推理、模式回忆、答案排除能力,还是文本线索利用?如果不理解每个基准的真实测量目标,就容易把排行榜进步误读为真实临床就绪度提升。
为此,研究人员对九个代表性健康 AI 基准进行了临床医生参与的结构化审查。研究人员设计了覆盖十个医学相关维度的评价准则,用于描述每个基准对模型提出的诊断需求。这些维度包括推理复杂度、视觉复杂度、临床上下文依赖、不确定性处理、视觉细节要求和多视角整合等。每个基准在每个维度上由三名具备资质的临床医生独立标注,并计算一致性。总体而言,标注一致性达到中等到较强水平,说明这些维度具有可操作性。
临床医生参与的基准画像
研究人员强调,每个画像维度都对应临床上有意义的诊断需求,而不是抽象数据集属性。例如,“是否仅凭文本即可回答”这一维度反映模型是否可能在不真正阅读影像的情况下依赖病史、疾病流行率或模板化推理作答。在真实临床中,这对应一种危险行为:医生或 AI 系统在影像可用时却没有充分利用影像证据,导致过度自信诊断。类似地,推理复杂度、不确定性处理和视觉细节要求则对应临床常见错误来源,例如过早下结论、不能承认模糊性,或误读细微影像发现。
通过临床医生标注,研究人员将不同基准投影到“推理复杂度”和“视觉复杂度”构成的二维空间中。结果显示,常用多模态健康 AI 基准差异显著。NEJM 在推理和视觉复杂度上都较高;JAMA 推理要求较高,但多数题目更容易通过文本解决;VQA-RAD、PMC-VQA 和 MIMIC-CXR 更依赖图像,但推理复杂度较低;OmniMedVQA 在两个维度上都相对较低。
这些差异解释了压力测试中观察到的基准特异性失败。例如,模型可能在 VQA-RAD 这类图像定位或视觉问答任务中表现良好,但在 NEJM 这类需要结合图像解释、临床背景和医学知识进行诊断推理的任务中表现脆弱。因此,不能简单地把所有医学多模态基准视为等价的模型能力指标。
对模型评估与设计的启示
研究人员认为,基准画像不应只是排行榜补充信息,而应成为解释模型表现的诊断工具。不同基准的设计假设、推理需求和视觉需求需要被明确记录。模型分数也不应简单在异质任务中求平均,而应根据医学意义维度分解报告。对于要部署到影像诊断场景的模型,仅在 JAMA 这类文本可解性较强的数据上获得高分,并不能证明其适合 NEJM 这类视觉诊断任务。
研究人员提出,基准应被看作诊断工具,而不是优化目标。排行榜分数应与基准画像一起报告,基准选择应匹配预期部署场景,评估协议应常规纳入对抗测试和压力测试。尤其对于高风险部署模型,压力测试结果应与准确率一起报告,并成为模型发布审计的一部分。否则,基准驱动的进步可能会强化狭窄优化,掩盖真实临床使用中的脆弱性。
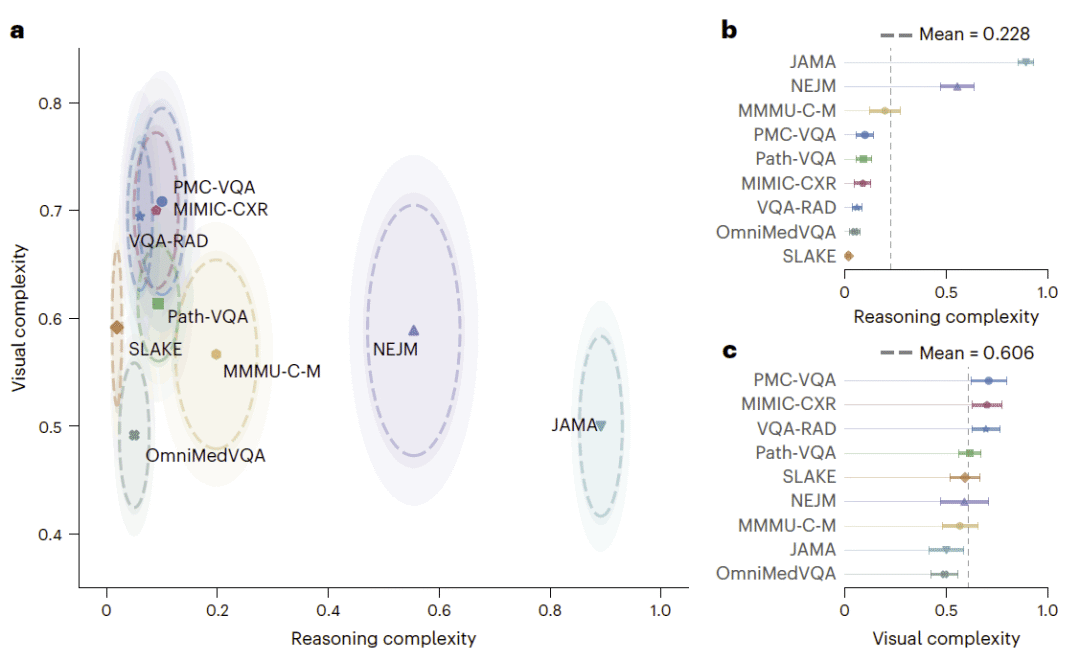
图4:多模态健康 AI 基准在推理复杂度和视觉复杂度上存在显著差异。
讨论
研究人员表明,当前健康 AI 基准可能夸大了大型前沿模型的应用准备度,因为它们没有充分捕捉模型在现实扰动、不确定性和输入冲突下的行为。尽管许多领先模型在排行榜上表现出色,但在轻微输入变化下仍会出现不一致行为、表面模式依赖和脆弱推理。这挑战了“基准成功等于医学可用”的常见假设。
当前基准提供了方便但不完整的能力窗口。许多基准强调答案正确性,却没有检验答案是否来自医学上有效的推理、多模态理解和稳健泛化。很多任务采用多选题格式,而这种格式本身与真实健康应用中的开放式决策、纵向病史整合和医患互动存在差距。因此,该研究结果应被理解为对当前基准实践的批判,而不是对所有临床场景中模型行为的完整评估。
研究人员指出,模型可以通过浅层线索获得高分,例如答案选项位置偏好、常见选项组合、模板化回答或训练中记忆的图像—答案关联。推理模型可能提高基准分数,却仍然生成幻觉式或不合理解释。强化学习方法也可能优化 token 层面的奖励信号,而不是忠实医学推理。最终可能出现一种误导性进步:数字分数提高了,但行为可靠性并没有相应提高。
健康 AI 的稳健评估是多维的。模型需要能处理缺失或噪声数据,需要在不确定性下表达谨慎,需要能够跨时间、模态和上下文进行推理,还需要给出临床可解释且事实可信的理由。医学不同于数学或编程,因为真实医疗问题往往没有单一清晰输入,常常包含模糊性、缺失信息、罕见情况和情境依赖。将链式思维或多智能体规划等通用推理策略直接迁移到医学场景,并不一定能解决这些问题。
研究人员还强调,健康 AI 就绪度不仅取决于模型能力,还取决于部署可行性。闭源 API 模型可能在基准上表现强劲,但在医疗机构中会面临数据驻留、审计可见性、持续运营成本、监管流程整合和模型更新透明度等限制。开源或本地部署模型则可能在数据治理和系统检查方面更可控。因此,模型就绪度声明必须结合具体机构、监管和运行环境来解释。
该研究也存在限制。研究人员评估的是健康基准和压力测试中的模型行为,而不是前瞻性真实临床工作流表现。许多任务采用多选题格式,不能覆盖开放式诊断、长期病程、真实医患互动和临床决策链条。压力测试只覆盖若干典型失败模式,不能穷尽健康应用中的所有不确定性。私有 X 光数据集规模较小且模态范围有限,只能作为支持性证据。随着前沿模型和基准持续更新,这类评估需要反复进行。
总体而言,研究人员提出了一种模块化压力测试框架,每一类测试都针对一个不同脆弱性,例如模态忽视、错误快捷线索、视觉 grounding 不稳或过度自信推理。通过隔离这些行为,压力测试能够在模型和任务之间进行系统比较,揭示单一准确率指标掩盖的问题。研究人员建议,未来健康 AI 基准应附带推理和视觉复杂度元数据,评估协议应纳入压力测试,基准应被用作揭示模型能力与限制的工具,而不是排行榜优化终点。随着大型前沿模型继续发展,健康应用中的评估体系也必须同步升级。
整理 | DrugOne团队
参考资料
Gu, Y., Fu, J., Liu, X. et al. Evaluating the robustness and readiness of large frontier models in health AI applications. Nat Med (2026).
https://doi.org/10.1038/s41591-026-04501-8

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢