

一句 “I'm fine”,真的总是表示“我很好”吗?
在真实社交中,我们几乎不会只根据这两个单词作判断。如果说话的人低着头、眼神向下、勉强微笑,肩膀也明显下垂,我们往往会意识到:这句话可能不是在报告一个事实,而是在掩饰低落、回避追问,或者尝试维持表面的平静。此时,一个合适的回应也不应只是机械地接受“我很好”,而可能是放慢节奏、表达关心,或者给对方留下更多空间。
这类判断看似自然,背后却包含一条复杂的社会认知链路:先感知表情、姿态和凝视等非语言信号,再把这些信号解释为社会状态,最后据此调整互动策略。语言、视觉与行动并不是三个彼此独立的模块,它们共同决定了我们如何“读懂现场”。
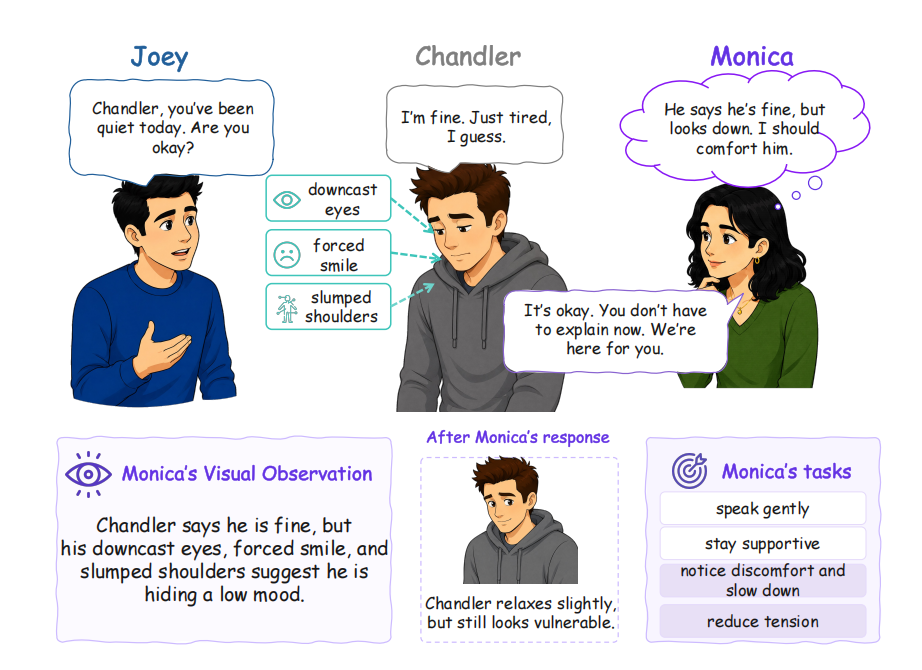
图 1:Chandler 口头表示自己没事,但表情和身体姿态透露出低落;Monica 据此调整回应。
过去的 social-agent benchmark 已经能够测试模型能否扮演角色、进行谈判、完成协商目标或保持 persona 一致。但如果视觉线索改变了语言的社会含义,仅靠文本就不足以判断一个 agent 是否真正具备社会智能。模型也许能“说得像某个角色”,却未必知道对方已经不舒服;它也许能够描述一张图片,却未必会让这些视觉信息真正影响下一步行动。
这正是 AgentViSS 要回答的问题:
当视觉线索进入多轮社会互动,多模态智能体能否把“看见”转化为“理解”,再把“理解”转化为合适的互动决策?
AgentViSS 要解决什么问题?
将文本社会模拟扩展到多模态环境,并不只是给对话附上一张图片。现有社会模拟评测主要存在三个不足。
首先,纯文本环境无法呈现真实互动中的可见状态。回避的眼神、防御性的姿态、紧张的表情或突然的沉默,都可能改变一句话的含义,也会影响下一步究竟应该推进目标、缓和冲突,还是暂停当前话题。
其次,现实中的社会场景往往包含冲突、信息不对称和策略性表达。一个角色可能口头同意,实际却明显迟疑;也可能为了避免冲突而隐藏真实态度。仅判断语言是否流畅、角色设定是否一致,很难覆盖这些复杂情况。
最后,传统评测通常把社会互动压缩成一个最终目标是否完成,却较少区分模型究竟在哪个环节失败:是没有维持自己的表达方式,还是没有追踪他人的状态?是没有及时调节互动,还是局部调节没有累积为最终结果?
因此,AgentViSS 关注的 Visual Social Intelligence 不是一般意义上的图像识别,而是更具体的能力:
持续感知他人的语言与非语言状态,并将这些状态转化为可执行的社会决策。
从文本剧本到可运行的多模态社会场景
AgentViSS 并不是简单收集“图片 + 对话”,而是构建 grounded multimodal social scenarios,让剧本文本、角色身份、视频片段和视觉证据共同指向同一个社会互动事件。
数据构建从 Friends 第一季剧本开始。先抽取包含角色、对话和局部故事背景的互动片段,再结合角色话语匹配与上下文语义匹配,将剧本对齐到字幕时间戳,并进一步定位到对应视频。得到 grounded video segment 后,系统选择能够体现角色共现关系和空间布局的 group image,同时为每个角色生成可以在模拟过程中更新的 role portrait。
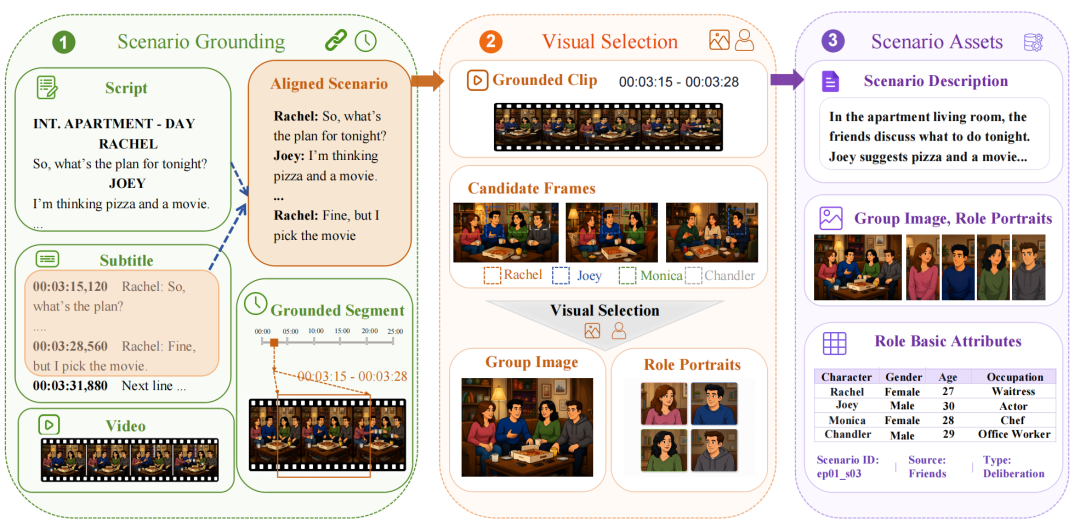
图 2:从剧本片段到字幕对齐、视频定位、视觉证据选择和角色任务构建。
最终,AgentViSS 包含 240 个社交互动场景、585 个角色实例和 2,340 个角色—任务实例,覆盖劝说型、协商型、信息寻求型和争辩型四类对话,以及 High、Medium、Low 三个冲突等级。
一个场景可以写作 I = (G,![]() , d, C,
, d, C, ![]() , T)。其中,G 表示固定的群体场景图,
, T)。其中,G 表示固定的群体场景图,![]() 表示第 t 轮的角色画像,d 是场景描述,C 是角色属性,
表示第 t 轮的角色画像,d 是场景描述,C 是角色属性,![]() 是情绪、面部表情和身体动作等动态状态,T 则表示角色级社会任务。这样的表示把“场景中发生了什么”“角色是谁”“角色当前处于什么状态”以及“角色想推动什么结果”放进同一个可运行结构中。
是情绪、面部表情和身体动作等动态状态,T 则表示角色级社会任务。这样的表示把“场景中发生了什么”“角色是谁”“角色当前处于什么状态”以及“角色想推动什么结果”放进同一个可运行结构中。
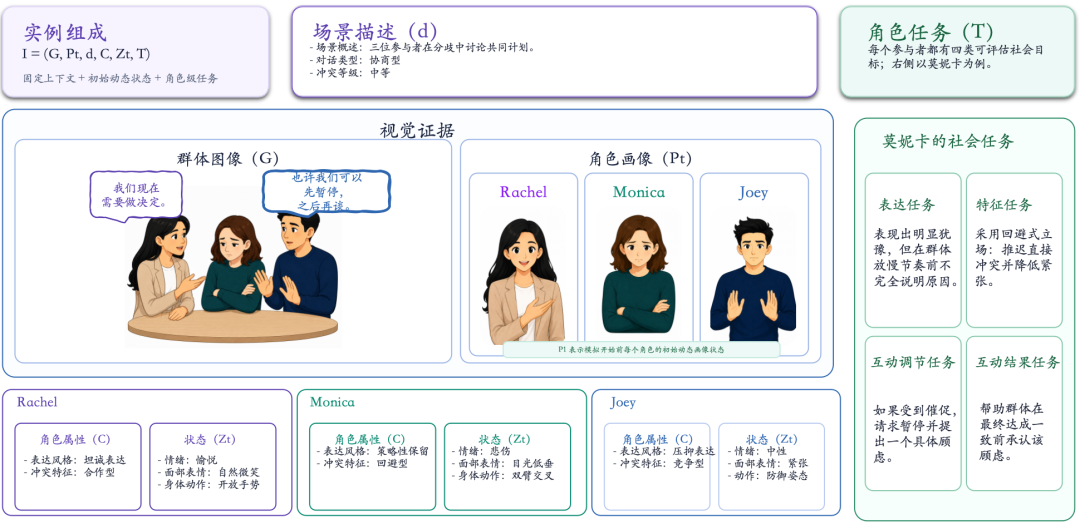
图 3:一个场景实例同时包含群体图像、角色画像、角色属性、动态状态和角色级任务。
每个角色有四类任务。Expression Task 检查角色是否保持指定的信息表达方式;Characteristic Task 检查角色是否体现预设的冲突处理倾向;Interaction Regulation Task 评估模型能否根据他人的语言与非语言状态调整策略;Interaction Outcome Task 则评估多轮互动最终是否形成预期的社会结果。
前两类任务回答“角色演得是否一致”,后两类任务回答“互动管理是否有效”。这一区分很重要,因为稳定地扮演一个回避型或合作型角色,并不等于能够判断他人的状态变化,更不等于能够在复杂互动中推动合适的结果。
多角色视觉社会模拟如何运行?
每个场景开始时,系统会初始化一个全局 simulation state,其中包含场景描述、角色资料、角色任务、对话历史、情绪状态和视觉状态。模拟采用多轮轮流发言的方式,每一轮只激活一个 active agent。
被激活的 agent 会读取自己的目标与角色属性、当前对话历史、自己和其他参与者的情绪、表情及身体动作,以及当前模式下可获得的视觉信息。随后,它不仅生成对外发言,还会输出内部想法、更新后的多模态状态、下一位发言人建议,以及是否需要更新角色图像。系统再把这些结果写回全局状态,进入下一轮。
因此,AgentViSS 测试的并非一次性的看图回答,而是一条需要在多轮中反复运行的闭环:
视觉线索 → 社会状态推理 → 互动策略调整 → 状态更新 → 结果形成
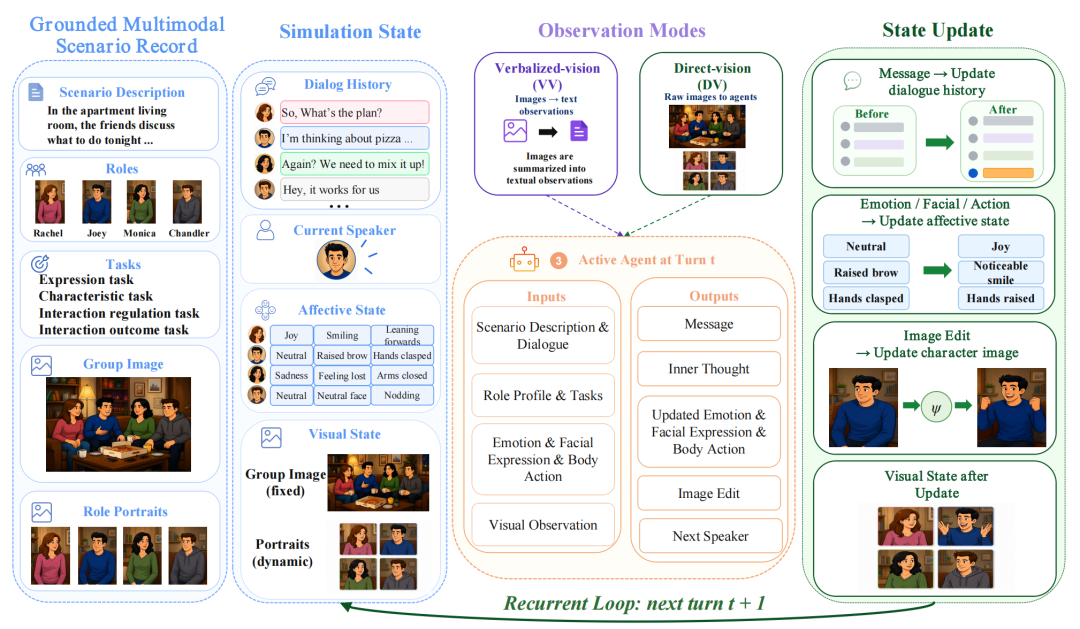
图 4:每轮激活一个 agent,读取目标、历史和视觉状态,并回写语言与多模态状态更新。
为了分析视觉信息如何进入决策,论文设置了两种 vision-enabled observation modes。Verbalized-Vision(VV) 先将图像转写为面部表情、姿态、情绪线索和注意力方向等文本化观察,再交给模型推理;Direct-Vision(DV) 则直接把群体图像和角色肖像输入模型。论文还使用 Text-only baseline,判断视觉证据是否确实提供了文本之外的信息。
VV 与 DV 的差别不是“有没有视觉”,而是视觉线索以什么形式进入决策。VV 将隐含线索显式化,更容易进入语言模型已有的推理链;DV 则要求模型从原始图像中完成视觉识别、社会含义解释和决策整合的完整过程。
实验结果:会扮演角色,不等于会管理互动
研究在 AgentViSS 上评测了七个近期多模态大语言模型,覆盖不同规模以及开源、闭源模型家族。所有结果共同指向一个核心差距:
当前模型已经比较擅长“演好自己”,但仍不擅长“读懂别人并管理互动”。
这听起来像是一个细微差别,但在社会互动里非常关键。因为“保持人设”和“读懂现场”其实是两种能力。一个模型可以稳定地扮演回避型、合作型或竞争型角色,也可以按照设定的表达风格说话。但这并不意味着它能注意到对方已经开始犹豫、紧张、防御,或者在群体互动中慢慢退出对话。
角色扮演接近饱和,互动管理仍然困难。
Role Enactment Tasks 的整体平均分达到 94.37,说明模型通常能够保持指定的表达风格和冲突特征;Interaction Management Tasks 的整体平均分则只有 57.39,而且模型之间差异更大。真正困难的并不是记住“我是谁”,而是在互动过程中持续判断别人当前是什么状态、局势是否改变,以及下一句话应该推进、缓和还是暂缓目标。
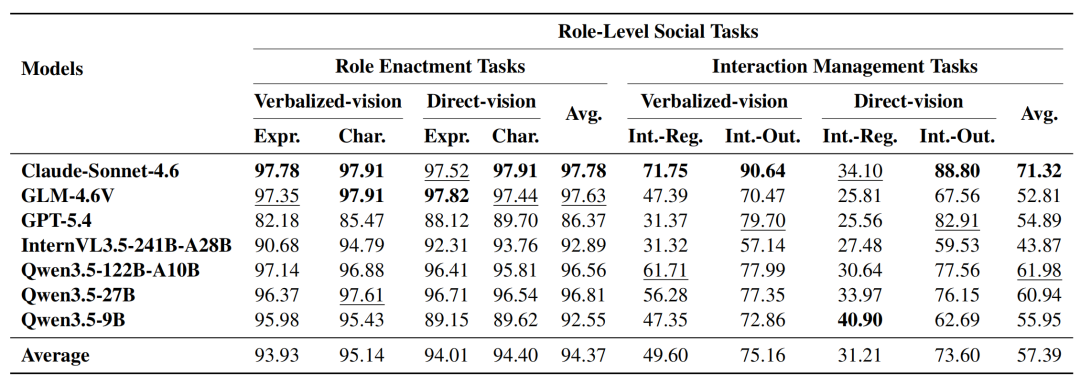
图 5:角色扮演任务已接近饱和,而互动调节和互动结果形成仍然困难。
这一结果也说明,传统角色扮演评测容易高估 agent 的社会能力。模型可以稳定地采用某种表达风格,却未必会根据他人的沉默、迟疑或防御姿态调整策略。不同模型的表现也不能单纯由参数规模解释:同一模型家族内部可能出现规模效应,但这一趋势并不能稳定跨越不同模型家族。
直接看到图像,并不等于真正使用视觉线索。
四类任务中,VV 和 DV 的最大差距出现在 Interaction Regulation Task。模型在 VV 下的平均分为 49.60,在 DV 下则为 31.21,相差 18.39 分,并且七个模型全部在 VV 下表现更好。
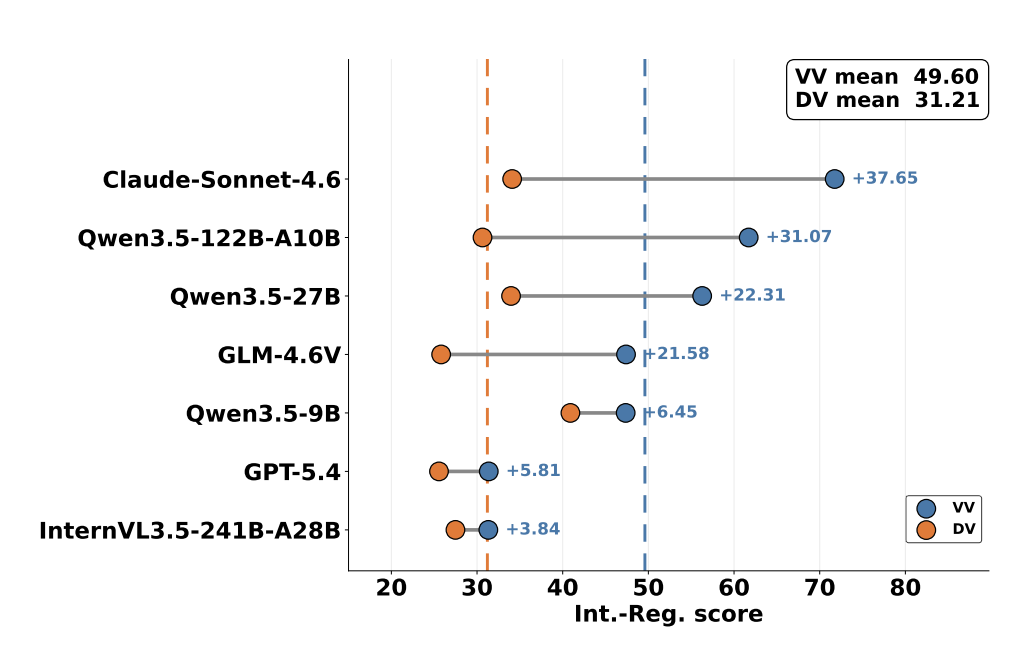
图 6:文本化视觉稳定优于直接视觉,说明视觉可达并不等于视觉利用。
论文进一步排除了“VV 只是产生了更长对话”这一简单解释:VV 和 DV 的公开发言长度非常接近,但 VV 在互动调节上的效率明显更高。人工检查也显示,这个差距不能完全归因于识别失败。以 Claude-Sonnet-4.6 为例,它的视觉描述质量已经接近满分,却仍然获得最大的 VV–DV 提升。这意味着瓶颈更可能出现在 perception-to-decision integration:模型能够识别或描述视觉线索,却没有稳定地把这些线索接入目标规划、社会推理和行动选择。
视觉信息确实有用,但难以累积为最终结果。
Interaction Regulation 关注当前一轮是否根据他人状态做出调整;Interaction Outcome 则要求这些局部调整在多轮互动中持续发挥作用,最终形成涉及其他参与者的社会结果。论文将 Interaction Outcome 分为弱视觉依赖和强视觉依赖两类,结果显示所有模型在强视觉依赖任务上都更差,平均分从 77.42 下降到 56.53。
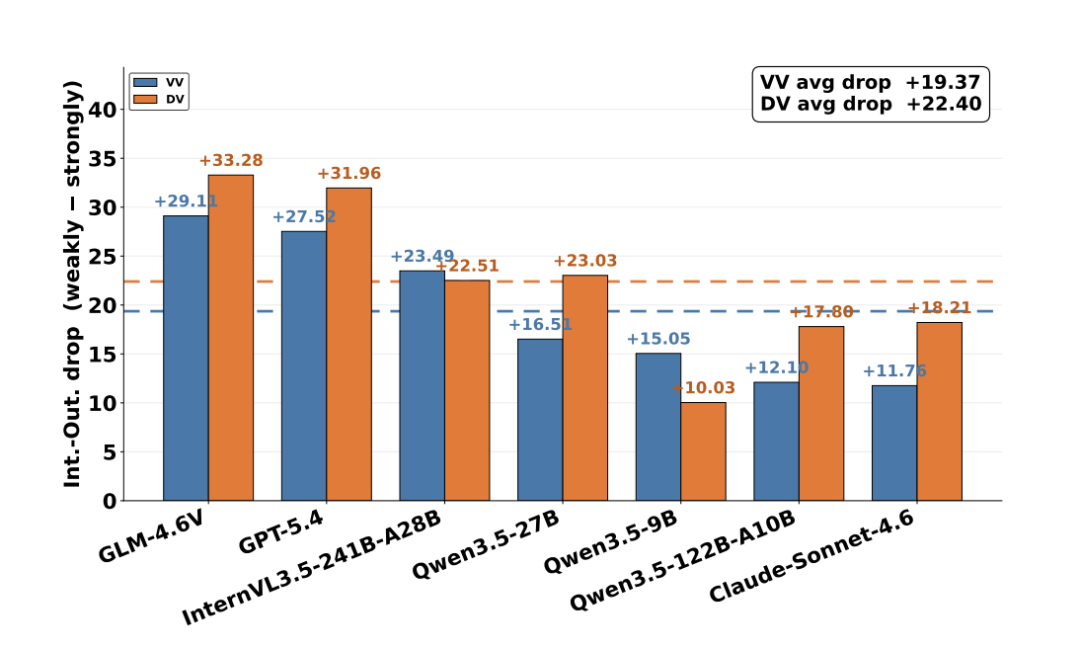
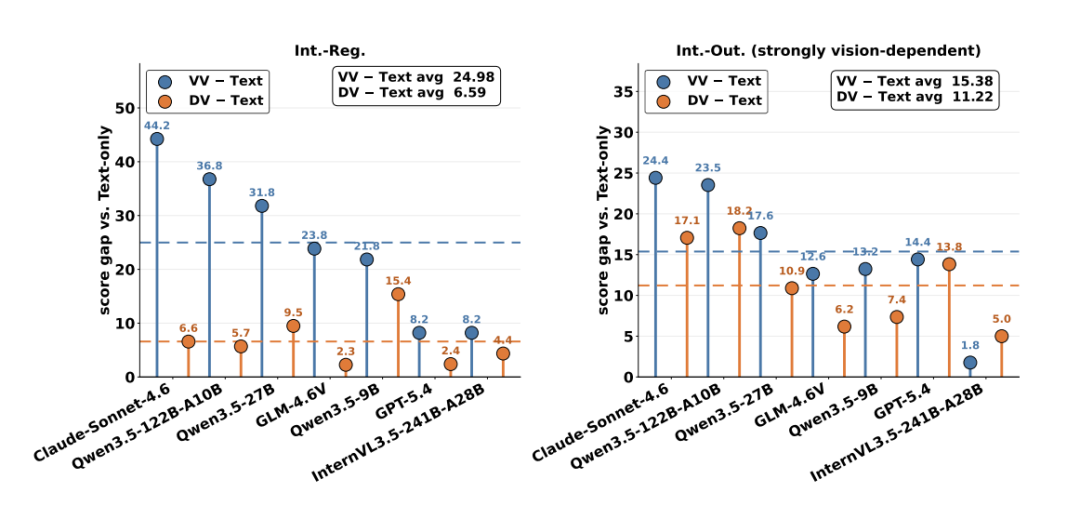
图 7:强视觉依赖的 Interaction Outcome 任务对所有模型都更困难。
图 8:视觉证据提供了文本之外的社会信号,但模型仍难以将其持续转化为最终结果。
与 Text-only baseline 的比较同时表明,视觉信息并不是无用的装饰:VV 和 DV 都能在互动调节及强视觉依赖的结果任务上带来收益。更准确的结论是,视觉证据确实提供了额外社会信号,但当前模型难以长期保存并持续利用这些状态。模型可能在某一轮看懂了对方,也做出一次合理回应,却无法保证后续策略始终围绕这一社会状态展开。
此外,互动管理难度还会随场景结构变化。information-seeking 场景包含更多提问、澄清和信息不对称,互动调节通常更困难;参与角色增加后,模型还需要同时追踪多个人的语言状态、视觉状态和相互关系。场景越复杂,越需要结构化的社会状态管理,而不能把任务简化成“图像理解 + 单轮对话生成”。
这些结果意味着什么?
AgentViSS 把多模态社会模拟的评测目标,从“能不能说得像一个角色”推进到了“能不能在视觉社会场景中做出合适的互动决策”。它揭示的关键问题也不只是视觉识别准确率,而是视觉社会状态能否真正进入行动。
从模型能力看,感知、理解和决策是三个不同层次。模型能够描述“对方低头、表情紧张”,不代表它理解这些状态对当前关系意味着什么;即使某一轮作出合适回应,也不代表它能在之后的互动中持续保持正确策略。未来系统需要更可靠地把视觉信息接入目标规划、多轮记忆、状态追踪和行动选择。
从评测角度看,只检查 persona 一致性或最终目标会掩盖大量中间失败。AgentViSS 的四类任务能够进一步定位:模型是否维持自身角色状态,是否追踪其他参与者,是否在局部调节互动,以及这些调节是否最终形成预期结果。
这对虚拟陪伴、教育训练、心理支持、客户服务、数字人互动和社会行为仿真等场景尤其重要。真正具有社会智能的 agent 不仅要知道“自己应该说什么”,还要知道对方是否已经不舒服、当前冲突是否正在升级、目标是否应该继续推进,以及什么时候需要从完成任务转向维护关系。
总结
AgentViSS 表明,当前多模态大语言模型已经能够相对稳定地扮演角色,却仍难以把表情、姿态、凝视和情绪变化等视觉线索持续转化为互动调节和结果形成。视觉输入确实有用,但原始图像的可达性并不能自动保证这些线索被用于社会决策。
看见,不等于读懂;读懂,也不等于会行动。
这正是多模态社会模拟下一步需要解决的核心问题。
Paper: https://arxiv.org/abs/2606.15152
Code: https://github.com/JunsWan/AgentViSS
Dataset: https://huggingface.co/datasets/JunsWan/AgentViSS
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢