
首个专为工业软件场景打造的统一代码基座模型,320亿参数,在14项通用基准和9项工业基准上全面验证。由北京航空航天大学、IQuest Research、澜舟科技、人大联合研发,已开源。

引言:代码大模型很强,但“工业场景”依然水土不服
近年来,代码大模型(Code LLMs)的进步有目共睹——DeepSeek、Qwen、Claude、GPT等系列模型已经能在算法题、Web开发、脚本编写等通用任务上达到甚至超越人类程序员的水平。然而,当你真的试图用它们去写一个Verilog硬件模块、调优一个CUDA核函数、编写STM32的嵌入式固件,或者生成一个可制造的CAD脚本时,现有模型的表现往往会让人大跌眼镜。
硬件语义:Verilog中的always块、posedge,以及时序约束,不是简单的逻辑描述; 资源限制:CUDA的gridDim.y上限是65535,超出即报错,而通用模型可能浑然不觉; 严格验证:工业代码必须经过仿真、综合、形式验证,才能流片或部署; 领域语言:Triton、CadQuery、SystemVerilog、ARM汇编……这些在公开代码库里占比极低。

什么是 InCoder-32B?
其核心设计理念是:工业代码的正确性只能通过真实执行环境来验证。因此,团队在数据合成与后训练中,构建了与生产环境完全一致的模拟/仿真工具链:

关键洞察:训练信号必须来自真实的编译、仿真、执行反馈,而不是模型自己打分或语法检查。
三阶段训练:怎么"教"出这个模型?
从15T token的通用代码+工业代码数据起步,采用三重召回策略(规则过滤 + FastText分类 + 语义检索)大幅提升Verilog、CUDA、Triton、嵌入式C等稀缺语料的覆盖率。 使用Fill-in-the-Middle(FIM)目标,学习代码的结构理解。
上下文扩展:从8K → 32K → 128K token,分两阶段进行,让模型能处理大型硬件项目(多文件依赖、完整调试会话)。 工业推理QA合成:由一线硬件/系统工程师设计场景,生成带自动验证(执行、静态分析、逻辑一致性)的推理问答对。 代理轨迹(Agent Trajectories):捕获“思考-行动-观察”闭环,包含仿真器、编译器、验证工具的反馈。 工业工件:包括SystemVerilog/UVM测试台、SDC时序约束、GPU剖析日志等。
构建250万条基于真实工业任务的SFT样本,全部经过执行验证(编译、仿真、运行、性能评测)。 反馈驱动修复:对失败候选方案,捕获完整错误上下文(编译错误、波形差异、瓶颈),生成“失败-反馈-修复”闭环轨迹,教会模型像资深工程师一样调试。
评测表现:通用任务不落下风,工业任务全面领先
SWE-bench Verified:74.8%,在所有开源权重模型中排名第一。 HumanEval:94.5%,与Kimi-K2-Instruct持平。 BFCL(多轮函数调用):60.99%,领先同尺寸模型。
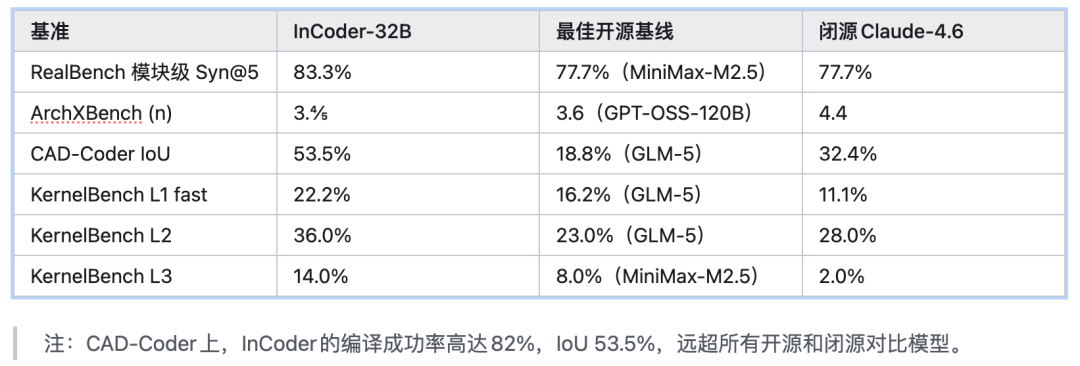
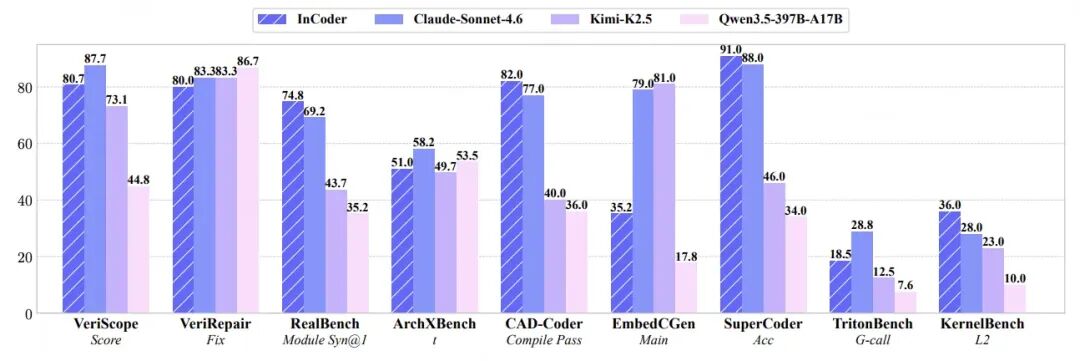
错误分析:依然存在的挑战
Verilog中位宽不匹配、端口声明错误、缺少end等(RealBench 71%失败源于此类)。 Triton中API误用(NameError 33%,TypeError 24%)。
KernelBench 33%生成正确但不够快的核函数。 SuperCoder 83%只是复制原始汇编,未做任何优化。
为什么这对开发者很重要?
统一基座,减少碎片化:以往,芯片设计、GPU编程、嵌入式开发各自为政,需要不同微调模型。InCoder-32B一个模型搞定多个领域,降低工程切换成本。 开源可用:模型已在HuggingFace和GitHub开源(链接见文末),支持商用和研究。 验证接地,减少“幻觉”:由于训练数据来自真实执行环境,模型生成的代码可编译、可仿真、可运行,显著降低“看起来对但跑不起来”的尴尬。 推理能力增强:中期训练中的代理轨迹和链式思考(CoT)数据,让模型具备“诊断-修复-优化”的工程思维。
HuggingFace:https://huggingface.co/Multilingual-Multimodal-NLP/IndustrialCoder GitHub: https://github.com/CSJianYang/Industrial-Coder
更多推荐阅读👇
立即体验
LangClaw企业可信智能体操作系统现已开放体验,快来创建你的数字员工吧。
👉 扫码/进入官网申请产品试用:

https://www.langboat.com/portal/langclaw
👉扫码加入Agent用户群

商务合作:bd@langboat.com

关于澜舟科技
ABOUT
北京澜舟科技有限公司成立于2021年6月,孵化于创新工场,是中国最早以大模型为创业目标的企业之一,深耕认知智能领域,以全栈自研的孟子大模型为核心,基于可信智能体核心技术体系,构建起覆盖 LangClaw 企业智能体OS及智库、智会、智搭等产品的完整体系。
往期文章推荐
”
澜舟科技官方网站
澜舟科技公众号

期待您的关注!
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢