

浙江大学-阿里巴巴集团人工智能安全联合实验室专场
直播回顾

张涵容
谷歌学生研究员,伊利诺伊大学芝加哥分校计算机博士生,师从 Philip S. Yu 教授;硕士毕业于浙江大学计算机专业

与依赖人工专家编写Skill来完成任务不同,关注的核心问题是:如何让Agent逐步生成、修正并优化自身所需的Skill,从而提升任务性能。具体分为两个层次:第一层是CoEvoSkills,解决一个相对可控的问题——在给定任务和上下文的条件下,Agent如何精炼好一个Skill;第二层是Open Skill,进一步探讨在真实环境中连上下文和验证信号都不具备的情况下,Agent如何自主在开放世界中寻找信息、构造验证依据,进而进化出Skill。本次分享围绕两篇论文展开。
全文结构分为三个部分:第一部分介绍研究动机(Motivation),阐述为何自动化Skill进化具有重要意义,以及人工编写Skill为何并非理想方案;第二部分介绍第一篇工作CoEvoSkills,将Skill优化转变为一个验证驱动的进化过程;第三部分介绍Open Skill,让Agent从开放世界中搜索知识,并将这些知识转化为学习和验证的信号。
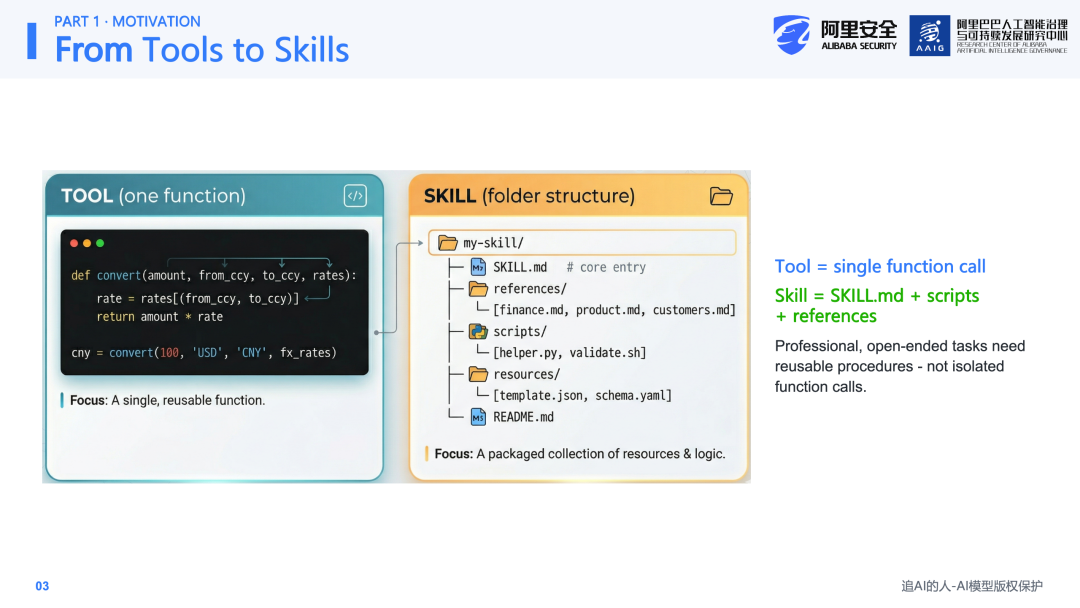
首先需要明确Tool与Skill的主要区别。Tool本质上是一个函数调用,结构非常简单,仅包含输入和输出。而Skill则是一种更为复杂的结构化载体,它可以包含Markdown文档、脚本以及资源资料等,形成一个混合式的结构,供Agent作为完成任务时的参考依据。这是两者之间的核心区别。
Skill的核心作用在于将一套流程化的知识进行沉淀。例如,当步骤出错时Agent应如何恢复、结果应如何检查、哪些步骤可以自动化等。它将Agent的零散能力组织为一个可反复执行和迭代的程序化流程。

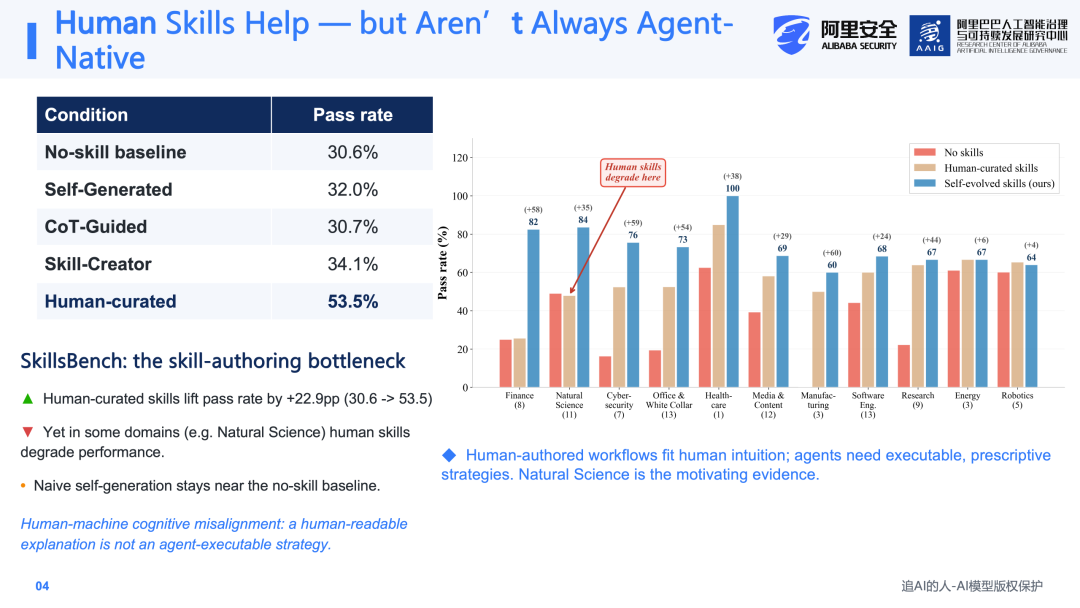
已有大量研究证实了Skill的有效性。以SkillsBench为例,在没有Skill的条件下,Agent的平均任务完成率为30.6%;而在加入人工精心编写的Skill之后,配合Agent的完成率可提升至53.5%。这充分说明Skill本身确实具有很高的实用价值。

然而进一步分析可以发现,问题也比较明显。首先,人工编写Skill需要耗费大量时间。SkillsBench背后有上百人的团队手写Skill并进行验证,但最终仅将完成率提升至53%,时间成本与性能收益之间并不令人满意。其次,研究团队尝试通过one-pass的方式,即通过prompt直接让Agent一次性生成Skill,但效果并不显著,即使加入Chain-of-Thought(COT)或一些元提示策略,提升幅度依然有限。
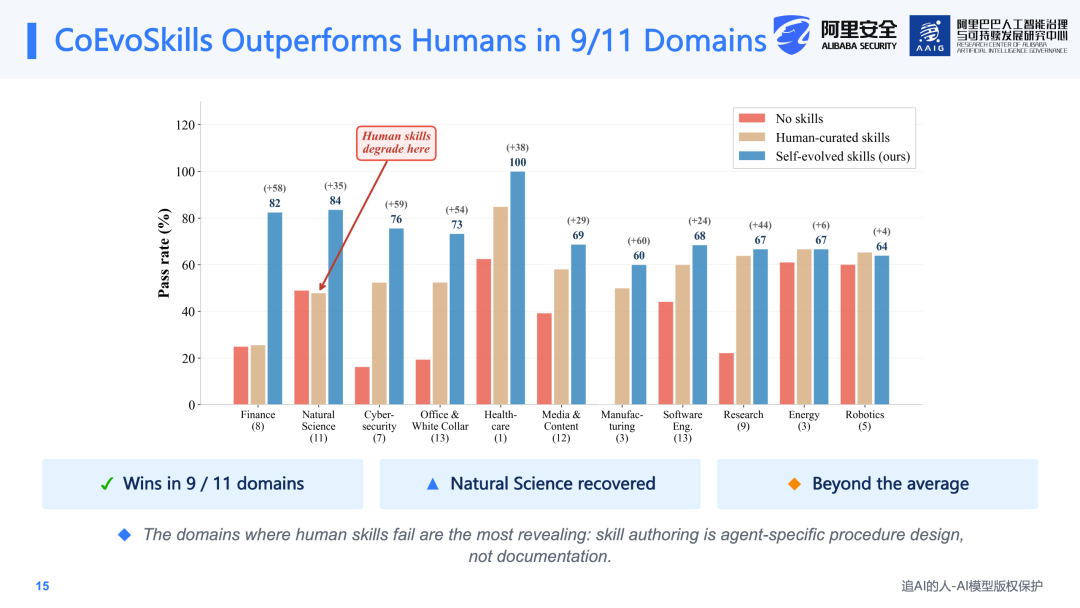
更为关键的是,人工编写的Skill并非在所有领域都有效。如图中所示,在Natural Science领域,手写Skill反而降低了Agent的表现。这反映了一种"人机认知不匹配"(Human-Machine Native Mismatch)的问题:人类认为表述清楚的内容,并不一定能够转化为Agent可以稳定执行的策略。换言之,Skill不是面向人类阅读的教程,而应当以Agent-native的方式来设计执行流程。这正是需要研究自动化Skill进化的原因所在。
接下来审视现有的self-evolving相关工作。当前已有不少此类研究,但其中大部分并不能直接应用于Skill的进化。
Self-evolving Skill面临两个主要挑战。第一是Tool-Skill Gap:现有许多工作优化的对象,虽然可能被称为"Skill",但更准确的定义是它们仍在优化单个tool或单个文档。而实际使用的Skill是一个复杂的混合结构,可能包含多个文件、多个脚本以及多个workflow,是多文件、多组件耦合在一起的完整包。因此,现有的自动化方法无法直接迁移到真正的Skill进化中,因为Skill的复杂度要高得多。
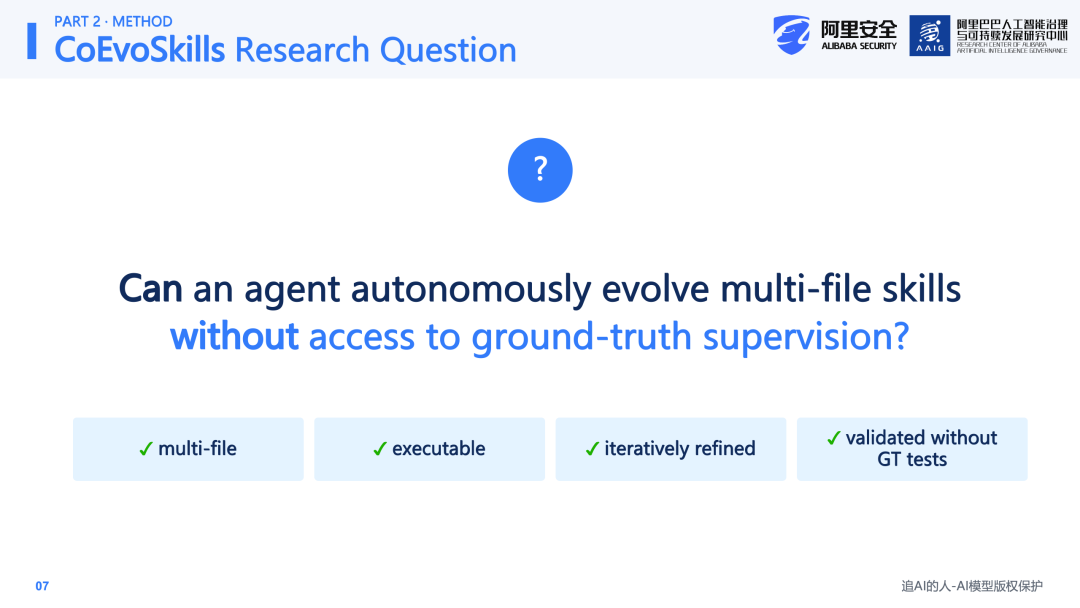
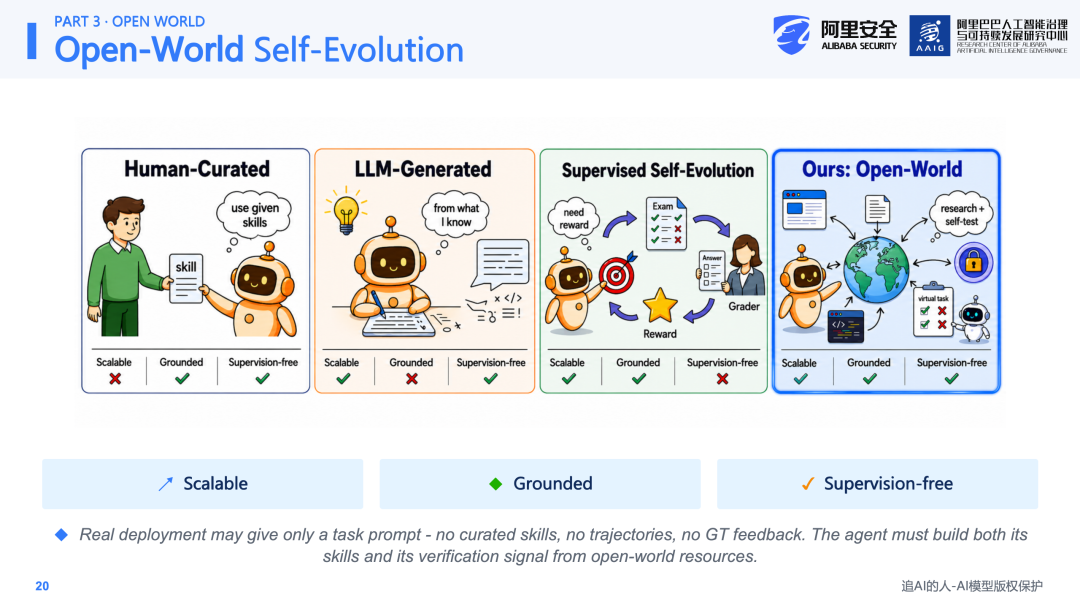
第二是Ground Truth Dependency:不少self-evolving方法需要依赖真实的奖励信号、人工反馈或专家演示轨迹等,作为进化的参考依据。但在实际场景中,这些信号往往不可获取,或者至多是稀疏且带有噪声的。因此,核心研究问题是:在缺乏监督信号的条件下,如何让Agent在给定任务的情况下,自主进化出可执行、可复用的Skill。

带着上述问题,进入第二部分——方法论的核心介绍。CoEvoSkills的核心思想是将Skill进化从一次性生成,转变为由验证信号驱动的迭代进化过程。本文的研究问题可以凝练为一句话:Agent在无法访问ground truth测试的情况下,能否自主进化出multi-file、executable、可迭代优化的Skill包?
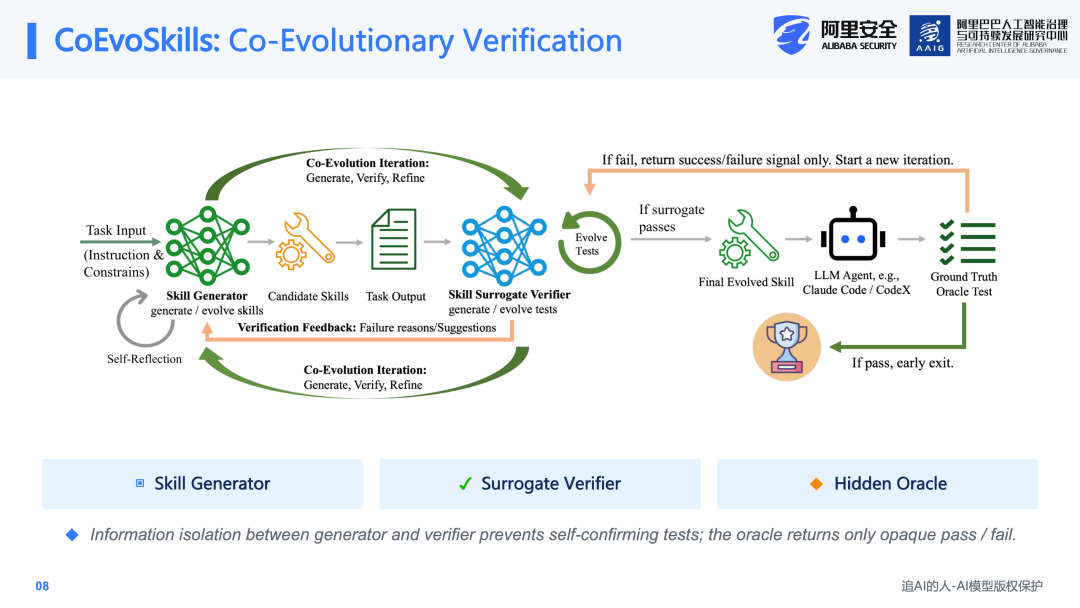
这里有两个关键点:第一,输出不能仅仅是单个tool或几句建议,而必须是一个真正可执行的multi-file Skill包;第二,验证过程中不能泄露真实测试的test case,否则就无法判断Agent是否真正学会了解决任务。整体方法思路是:既然无法获取现实世界中的ground truth测试,就为其设计一个Surrogate Verifier(代理验证器),由它代替真实世界的ground truth测试,为进化过程提供反馈信号。
整体框架设计了三个角色。第一个是Skill Generator,负责Skill的生成与修改。第二个是Surrogate Verifier,它是一个独立的验证器,负责生成确定性的测试用例,并在任务失败时提供结构性的诊断信息。
第三个角色是最终的Benchmark评测文件,即检验Skill是否帮助Agent完成任务的test case。在流程上形成了一个内外双循环结构:在内循环中,Generator针对Surrogate Verifier给出的具体诊断,不断修正Skill,直至通过所有代理测试用例;当Surrogate Verifier的测试全部通过后,才进入外循环的ground truth测试。如果Surrogate Verifier的测试通过了,但Oracle Test仍然失败,则进一步进行测试升级,思考是否存在未被覆盖的场景,或者此前的test case过于简单,需要进一步优化。
由此形成了一个共同进化(Co-evolution)的过程。Skill Generator和Surrogate Verifier之间是协同进化的关系:Skill Generator生成的Skill在原有版本基础上,根据修改建议和反馈意见进行迭代优化,使Skill不断改善;Surrogate Verifier也会根据当前的Skill版本,生成更贴近现实场景的测试用例。
将上述过程形式化为算法:系统的输入包括任务指令、Background Context,以及一个Meta Skill(即Skill Creator,系统预定义的关于如何构建Skill的Skill)。首先生成一个初始Skill,根据当前任务和上下文在环境中执行,获得输出结果。然后将这些输出通过Surrogate Verifier进行测试,这些测试用例也是根据上下文生成的,力求尽可能全面地覆盖各种情况。
当测试失败时,Surrogate Verifier不仅指出错误,还会提供断言结果、失败原因以及修改建议,反馈给Skill Generator。Generator根据这些诊断信息,在上一版本基础上继续修正Skill,此时测试用例是锁定的。只有当Agent完全通过了所有代理测试之后,才进入Oracle Test(最终测试)。如果Oracle Test通过则停止进化;如果失败,则仅泄露一个哈希值(即只告知失败,不透露具体原因),然后重新进入下一轮进化。这一设计目标是尽可能利用可解释的代理反馈,避免真实测试的信息泄露。
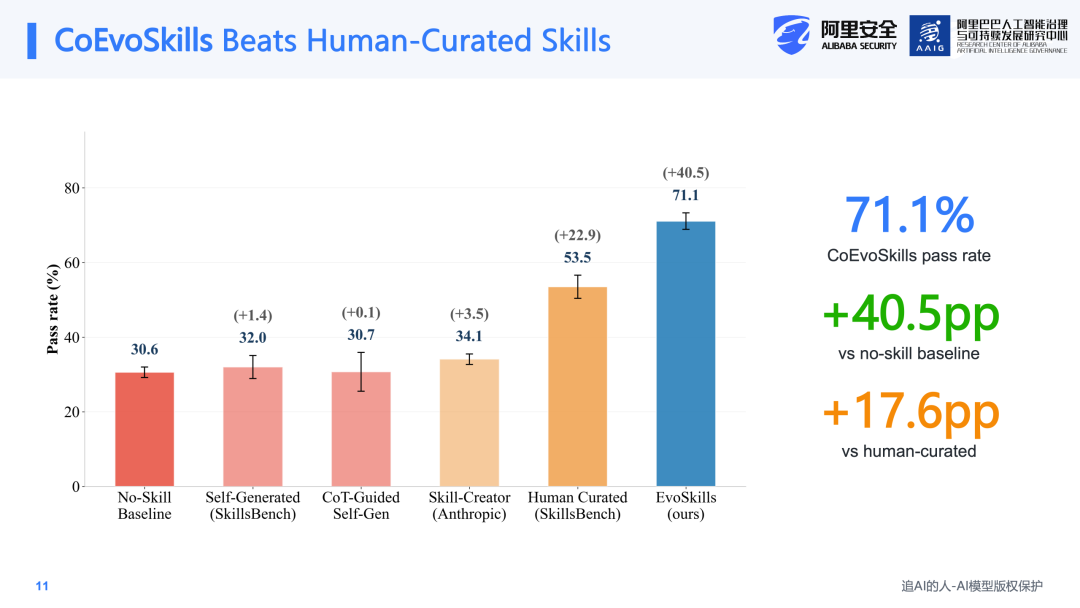
从实验结果来看,我们的方法在SkillsBench的pass rate上有较为明显的提升。首先,它比无Skill的baseline高出约40%的完成率,并且比人工手写Skill还高出17个百分点。这一结果表明,Agent并非只能模仿人工编写的Skill;只要验证信号设计得足够好,它就能够发现更适合自身执行方式的流程,甚至超越人工编写的版本。

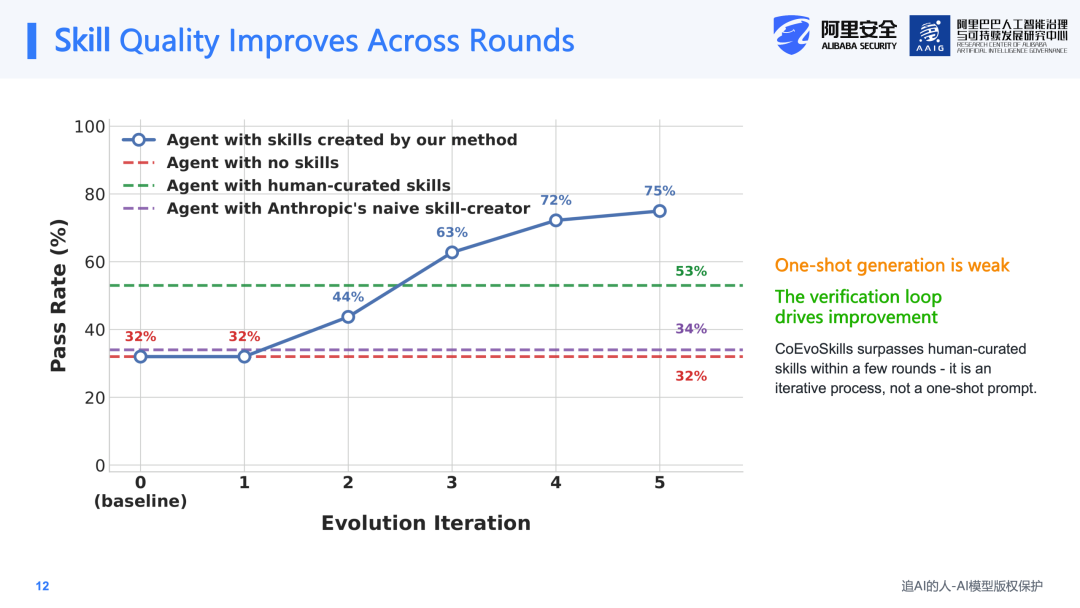
进一步观察进化过程可以发现,一次性进化的起点并不理想,与无Skill的baseline基本持平。但通过五轮迭代进化,完成率持续上升,充分说明对于Skill这样的复杂结构,one-pass的生成方式是不够的,必须通过迭代式的进化途径才能使Skill不断优化。值得注意的是,在第三轮迭代时,自动进化的Skill就已经超越了人工编写的Skill。这进一步证明,真正重要的是"生成测试—诊断—修复"这一持续迭代的闭环机制。

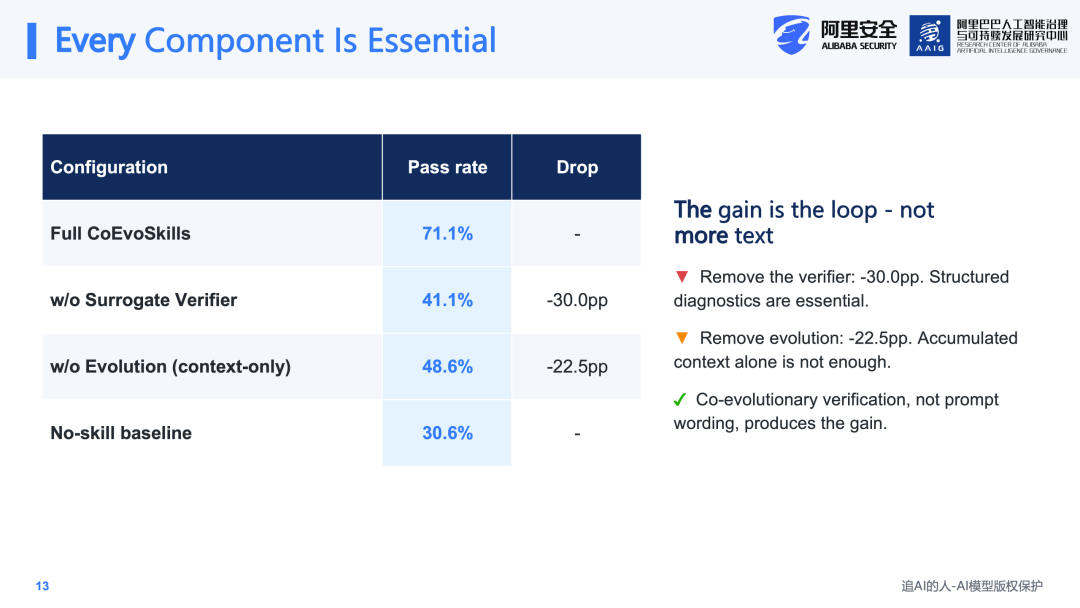
在消融实验中,移除Verifier和Evolution过程后,性能分别下降了30个和22个百分点。这说明仅仅将上下文信息提供给Agent是不够的,仍然需要通过这套方法来定位失败的具体原因和位置,然后由Generator根据这些反馈信息进行针对性修复。
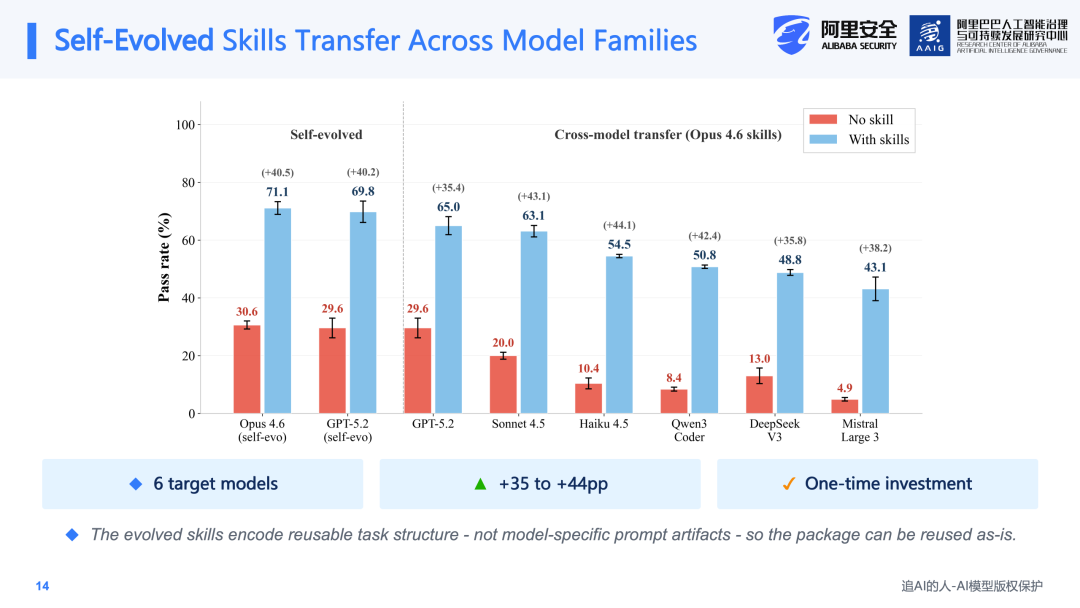
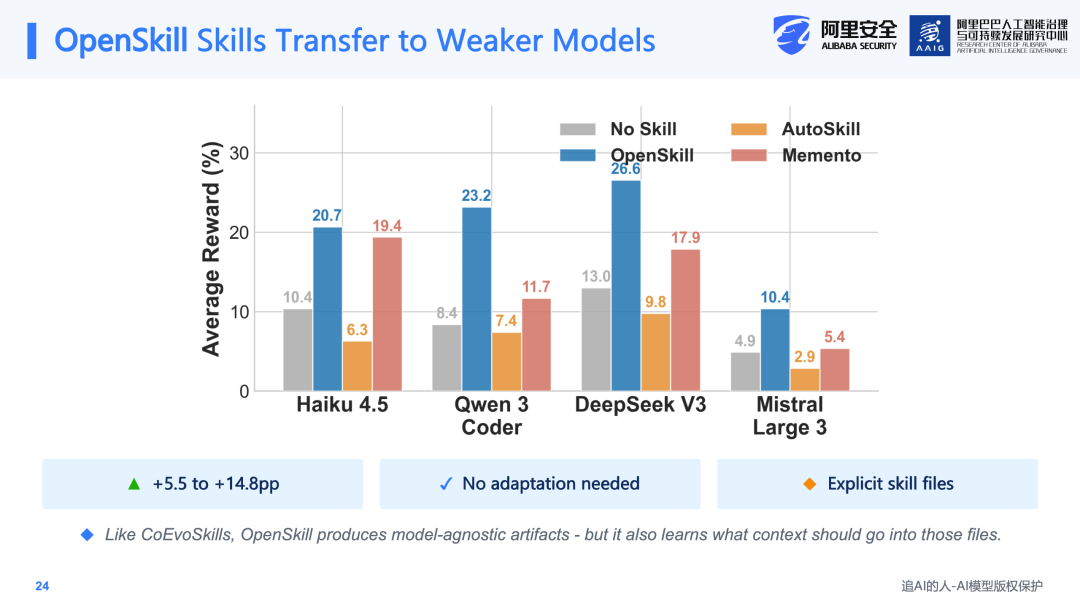
将强模型(如Claude 4.6或GPT 5.2)生成的Skill应用于其他较小的模型上,例如Claude 4.5、Haiku 4.5、Qwen 3、DeepSeek V3等,均获得了35%到44%的性能提升。这说明自动进化得到的Skill并非某个模型专属的prompt trick,而是更具通用性的任务结构和执行流程。尽管进化过程存在一定的迭代成本,但这些Skill包可以作为显式的artifact被不同模型直接复用。
最具代表性的是Natural Science领域:人工编写的Skill在该领域往往会失效,但自动化进化的Skill能够将性能重新拉升。这再次说明,Skill的本质不是编写一份文档,而是面向Agent设计一套可执行的程序(procedure)。
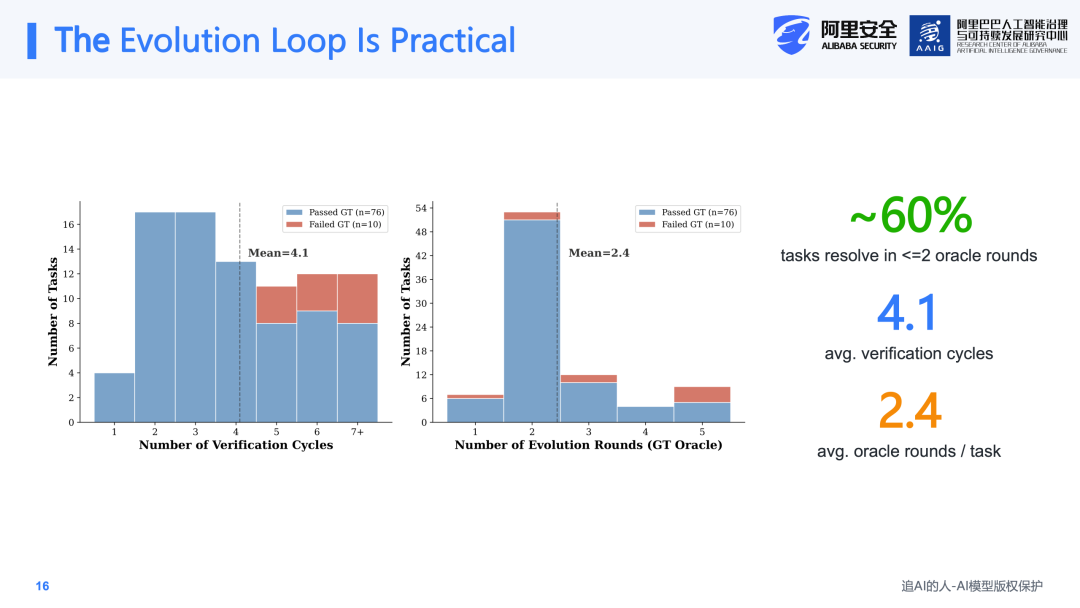
在进化成本方面,大约60%的任务在两到三轮迭代中即可解决,平均进化轮次为4.14个cycles。也就是说,在进入最终测试之前,Surrogate Verifier已经吸收了大量的错误,使Agent通过轻量级的迭代达到了相对较好的状态。由于Oracle Test的成本较高,这一机制确保了Oracle Test不需要频繁介入。
小结:CoEvoSkills解决了Skill自动化中的一个核心问题——在给定上下文的条件下,Agent可以通过验证驱动的进化过程,生成比人工编写更适合自身执行的Skill,且这些Skill可以跨模型迁移。然而,这里存在一个现实问题:在开放世界中,这些上下文从何而来?这就自然引出了Open Skill的研究。
Open Skill关注的是更加开放的场景。假设Agent不再具备任何背景知识——在真实部署环境中,Agent可能只有一句任务描述,而没有可供参考的背景信息,也没有ground truth反馈,更没有真实的执行轨迹。

Open Skill旨在让Agent完成两件事情:第一,从开放世界的资源中搜索完成任务所需的知识;第二,将这些知识通过进化的形式转化为可自我检验的验证信号。可以将其理解为面向Skill进化的Deep Research,但它并非查完信息就结束,而是将搜索结果转化为可执行、可复用的Skill。
Open Skill的流程分为三步。第一步是Open-world Acquisition:系统搜索网页、文档和代码库,同时对查询进行清理,例如去除benchmark相关信息,以避免直接搜索到标准答案。
第二步是Leakage-free Evolution:基于搜索获取的材料,通过前述的迭代进化形式生成Skill,再由一个独立的Verifier基于这些信息构建Surrogate Test。如果测试失败,系统会判定问题根源是代码存在bug还是知识存在缺口。如果是bug,则直接修正Skill中的代码或流程;如果是知识缺口,则触发新一轮的检索(Retrieval),即通过搜索的方式在网上查找所需的相关资料,继续进化过程。
第三步是Zero-shot Evaluation:Skill被冻结后部署到目标Agent上,真实的ground truth仅在最终评估时出现。这样,目标监督信号在Skill构造过程中被完全排除,不会介入进化过程。
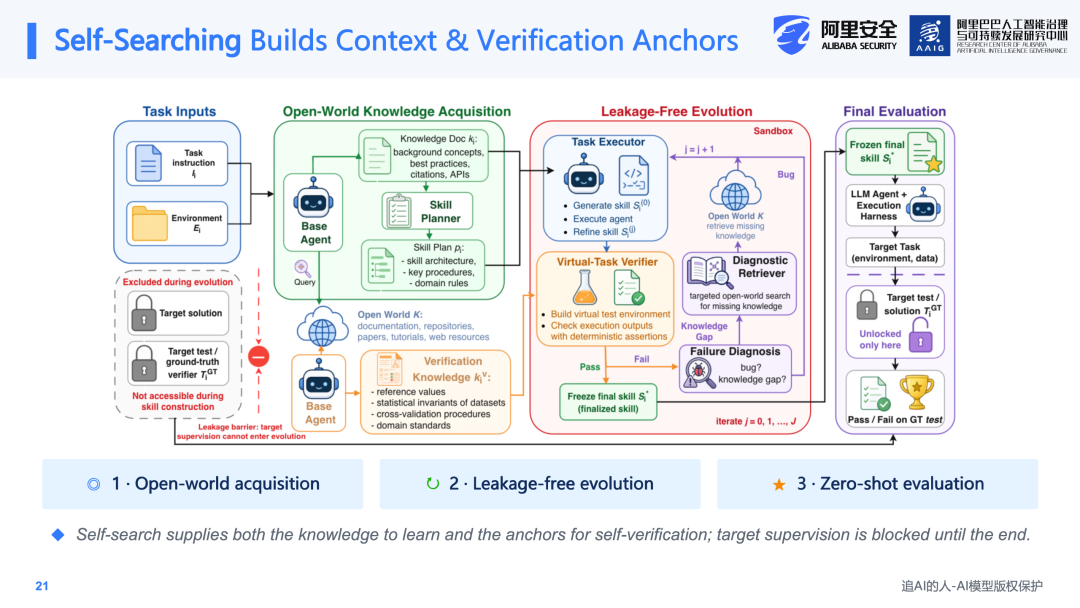
从实验结果来看,在SkillsBench(基于Claude 4.6)上,无Skill的baseline完成率为25%,Open Skill可以达到接近人工编写Skill的水平,结果为43.6%,相对于baseline提升了近20个百分点。在GPT 5.2上也取得了同等的提升效果。
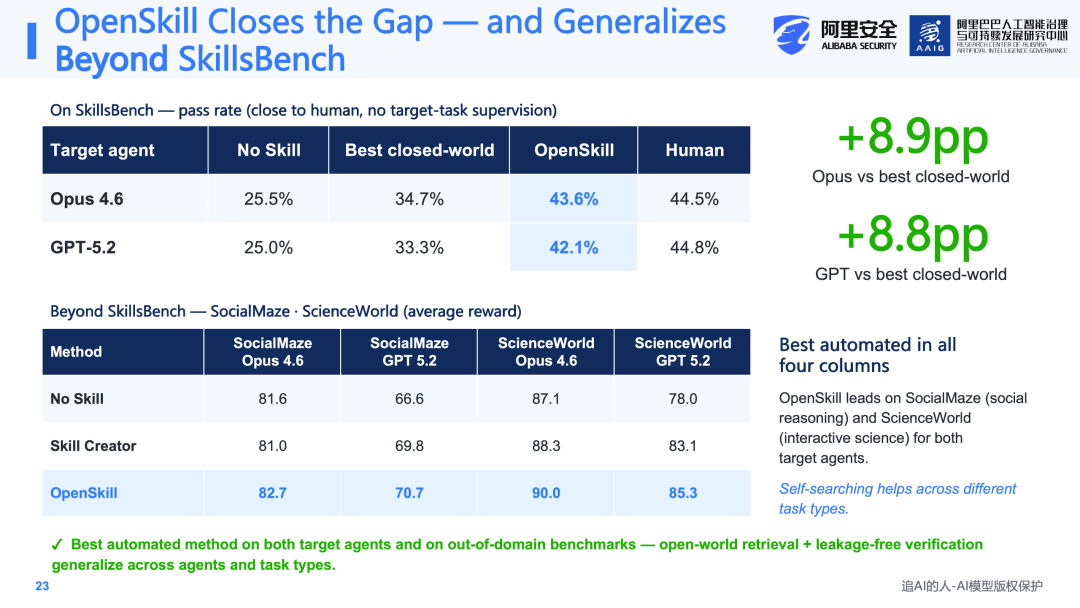
更为重要的是,Open Skill不仅在SkillsBench上有效,在Social Science和Social World等领域也获得了out-of-domain的泛化提升效果。这说明该方法可以在不同模型和不同任务类型上实现泛化。此外,Open Skill生成的Skill同样可以迁移到更弱的模型上——由强模型构造的Skill可以直接供弱模型使用,仍然能够带来5.5%到14.8个百分点的提升,且无需额外的适配工作。这一结论与CoEvoSkills的发现是一致的:通过这种方式获得的Skill是显性的、可搬运的。
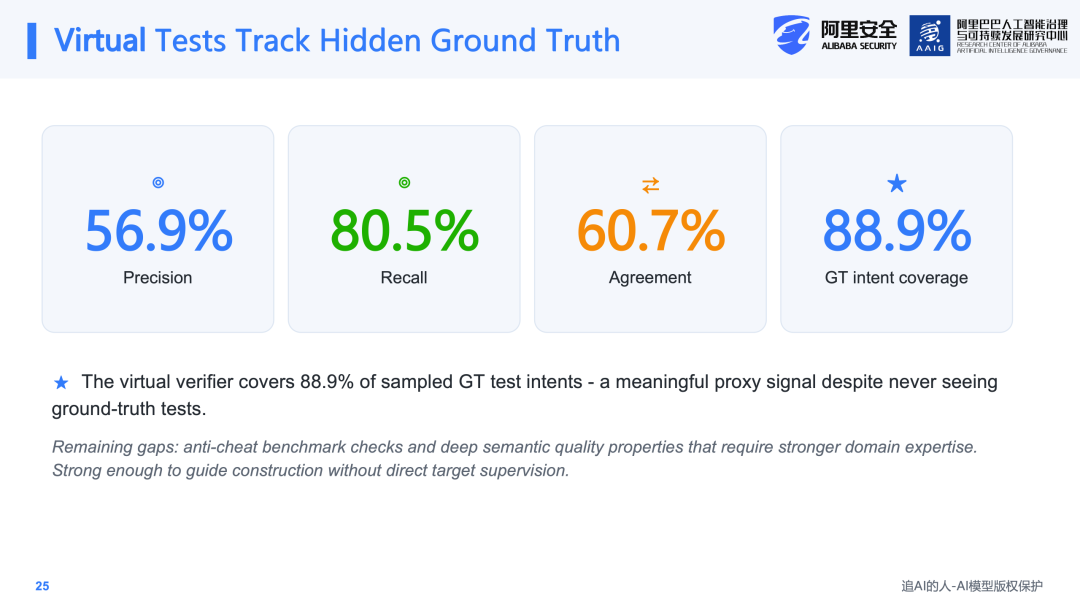
还有一个关键问题需要回答:在没有ground truth的情况下,所构造的Virtual Test质量是否可信?为此进行了分析性实验,对比进化产生的Virtual Test与ground truth test之间的相似度。实验结果显示,Precision可以达到57%,Recall可以达到80%。也就是说,Virtual Test能够覆盖大部分ground truth test所需检测的关键点,可以作为ground truth的有效替代品,捕捉到大部分需要检测的意图。因此,它可以作为修正信号,为Skill Generator提供进化指导。
综合总结:第一,Skill优化需要大量人力,且人工编写的Skill表现不稳定,模型难以直接生成高质量的Skill。第二,可以通过Surrogate Verification的方式,将人工编写Skill转变为让Agent自主进化Skill,通过迭代方式使Skill不断修复和完善。第三,Agent可获取的上下文构成了其能力的上限。如果需要某些背景上下文,仍然会涉及人工干预的过程。Open Skill正是为解决这一问题而提出的——让Agent自主搜索开放世界的知识,并构造相应的验证信号。最后一页列出了本次分享所涉及的相关工作和benchmark。


📌往期推荐








AAIG课代表,获取最新动态就找她👇
 关注公众号发现更多干货❤️
关注公众号发现更多干货❤️


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢