

Stanford CS224W: Machine Learning with Graphs
代码下载:https://t.zsxq.com/76vr1
请索引第38个项目
 |  |

1. 引言和动机
人工智能研究近期拓展至神经算法推理(Neural Algorithmic Reasoning,NAR)领域,其任务是训练深度学习模型来复现经典算法的中间步骤。其目标是利用神经网络的灵活性,将算法逻辑应用于复杂多变的现实世界输入,而传统的算法在这些情况下可能失效。
我们的项目基于双重算法推理(Dual Algorithmic Reasoning,DAR)框架,该框架能够联合学习原始算法(例如最大流算法)及其对偶算法(例如最小割算法)以提升性能。以往的研究主要集中在Ford-Fulkerson算法上,而我们则着重研究Push-Relabel算法。据我们所知,我们是第一个尝试通过神经算法推理框架来学习Push-Relabel算法步骤的研究团队。
我们假设,通过局部更新和并行执行的推送重标记算法比全局顺序的Ford-Fulkerson算法更符合图神经网络(Graph Neural Networks,GNN)的消息传递范式。我们在合成图上验证了这一假设,并通过生成嵌入来辅助对脑血管进行分类,从而展示了该算法在实际应用中的可行性,所用数据集为血管图(VesselGraph,BVG)(https://github.com/jocpae/VesselGraph?tab=readme-ov-file#table-of-contents)。
2. 理论分析:全球化运营与本地化运营
这项工作的一个主要动机是具有全局操作的算法与 GNN 架构之间的理论不匹配。
2.1 福特-福克森模型的局限性
Ford-Fulkerson算法分两个交替阶段寻找最大流。第一阶段是路径查找阶段,旨在找到残差图中所有增广路径。这一步骤可以使用任何路径查找算法来实现。通常情况下,最短路径是理想的,因此广度优先搜索(BFS)在这里易于实现和使用。
第二阶段是更新增广路径中各边的流量值,使得沿该路径发送的最大流量得以实现。关键在于,在这一步中,算法会找到增广路径上的最小剩余容量,并基于该值更新所有流量。这一步是对整个图进行的“全局”操作。总的来说,与 Push-Relabel 算法相比,Ford-Fulkerson 算法在解决最大流问题时采用了一种更全局的方法。
我们通过反例论证,具有 L 层的标准消息传递 GNN 无法模拟 Ford-Fulkerson 的第二阶段,除非将流更新步骤拆分为多个单独的子步骤,或者通过全局虚拟节点进行额外的图增强。
考虑以下情况:增广路径的长度为 2L,形式如下:
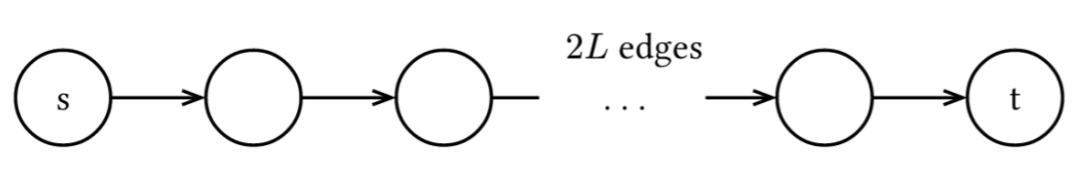
图 1:一个反例,展示了 L 层 GNN 无法基于任何一条边的信息生成正确的流量更新(涵盖所有边属性)的情况。
接下来,考虑这样一种可能性:某条 2L 边的剩余容量严格小于其他所有边。在没有其他假设的情况下,我们注意到,大约 L 条剩余边位于该边两侧任何节点的 L 跳邻域之外。因此,通过消息传递操作,我们永远无法在 L 层图神经网络 (GNN) 内传播最小剩余容量的信息。
解决此问题的几种可能方法包括以下几种:
在寻找增广路径的过程中,或许可以纳入并传播最小容量信息,但是,这种方法的具体方法和可行性取决于路径算法的具体实现。
我们可以将最小残差容量的传播分解为一系列局部操作。然而,这种方法会将样本算法轨迹的长度乘以增广路径的平均长度。这种每步最多更新两个节点值的传播方式对于完整的图神经网络来说效率也很低,需要引入第三阶段,甚至可能需要第三个处理器网络。
我们可以添加一个虚拟节点,使得所有边的节点之间的距离都在两跳以内。这会在阶段切换时引入复杂性,此外,如果处理不当,还可能导致过度平滑效应。
2.2 推送重新标记的对齐
def_push_relabel_impl(A: np.ndarray, s: int, t: int) -> _Out:
"""
Push-relabel with global relabel heuristic and batching
A: capacities for each (directed) edge
s: source node
t: sink node
"""
n = A.shape[0]
f = np.zeros_like(A) # flow assignments per edge
h = np.zeros(n, dtype=int) # height (label) per node
e = np.zeros(n) # current excess flow per node
# Preflow: saturate source edges
h[s] = n
for v inrange(n):
if A[s, v] > 0:
flow = A[s, v]
f[s, v] = flow
f[v, s] = -flow
e[v] += flow
e[s] -= flow
global_relabel_freq = n
steps_since_relabel = 0
step = 0
whileTrue:
# perform global-relabel using BFS every once in a while
if steps_since_relabel >= global_relabel_freq or step == 0:
h = run_global_relabel(A, f, h, e, s, t, n)
steps_since_relabel = 0
step += 1
# Get active nodes
active_mask = e > 0
active_mask[s] = False
active_mask[t] = False
current_active_nodes = np.where(active_mask)[0]
# Check if we are done
iflen(current_active_nodes) == 0:
break
steps_since_relabel += 1
step += 1
# Discharge stage
for u in current_active_nodes:
if e[u] <= 0:
continue
# Pushing
for v inrange(n):
residual = A[u, v] - f[u, v]
if residual > 0and h[u] == h[v] + 1:
delta = min(e[u], residual)
if delta > 0:
f[u, v] += delta
f[v, u] -= delta
e[u] -= delta
e[v] += delta
if e[u] == 0:
break
# Relabeling
if e[u] > 0:
min_h = np.inf
for v inrange(n):
residual = A[u, v] - f[u, v]
if residual > 0:
min_h = min(min_h, h[v])
if min_h != np.inf:
h[u] = min_h + 1
return f基于第 2.1 节中详述的原因,我们认为,依赖于并行局部操作的算法应该能够被具有消息传递架构的 GNN 很好地学习。
我们实现了一种“并行”的推送-重标记算法,因为基本的顺序版本每次只关注一个节点,并依次将其多余的流量推送给其邻居节点。而我们则关注一组具有多余流量的节点,并依次从这些节点推送和重标记流量。我们的目标是让图神经网络(GNN)一步学习所有这些局部操作。
此外,Push-Relabel 中常用的一个子程序是“全局重标记启发式算法”,它本质上是从汇聚节点偶尔执行一次反向广度优先搜索(BFS),以更新节点的高度(标签)。该子程序有助于跳过不必要的重标记操作,从而减少总步骤数并提高运行效率。我们决定加入该子程序,因为已有理论证明图神经网络(GNN)能够很好地学习并行 BFS 的步骤。事实上,作为我们工作的一部分,我们还进行了额外的分析,以实证证明 GNN 可以以接近完美的准确率学习 BFS。
为了证明推送重新标记与 GNN 的消息传递特性相符,我们研究了“释放”阶段中的原子操作。
推送:将多余的流量从一个节点转移到相邻节点。
邻居节点的资格取决于过剩流量节点的边属性以及两个节点的高度属性。这些步骤涉及简单的减法运算,然后是一个不等式,这应该可以用多层感知器(MLP)很好地近似。
在这种情况下,实际的聚合与简单的求和聚合非常吻合,因为我们现在只是对从符合条件的入边推送的过剩流量(节点属性)进行求和。
重新标记:根据邻居节点的高度更新节点的高度。
我们通过将节点的高度更新为其符合条件的邻居节点的最小高度(在步骤 1 中计算)加 1 来重新标记该节点。这与最大聚合算法非常吻合。
根据这一理论依据,我们在模型中使用求和聚合和最大聚合,分别执行这两种聚合,并将得到的嵌入连接起来。
3. 数据集描述和处理
为了评估我们的模型,我们使用了两个不同的数据集:一个用于算法训练的自定义合成数据集和一个用于真实世界迁移学习的 BVG 数据集。
3.1 合成图生成
我们生成了旨在挑战流量算法的合成图。
拓扑结构:我们采用了双社群分布。每个图包含两个紧密连接的社群(边存在的概率 P=0.35),这两个社群之间通过稀疏的社群间边连接(P=0.05)。
规模:训练集包含 1000 个图,每个图有 32 个节点。验证集和测试集各包含 128 个图。
容量:边缘容量从 [0.1, 0.9] 范围内均匀采样。
泛化测试:我们还生成了一个更大的图(64 个节点)测试集,以评估模型泛化到训练期间未见过的大小的能力。
3.2 轨迹生成
对于每个图,我们执行了 Push-Relabel 算法来生成真实轨迹。这些轨迹记录了图在每一步的完整状态,包括边的流量、每个节点的超额流量以及每个节点的当前整数高度/标签等信息。考虑到不同图所需的求解步骤数不同,我们将所有轨迹填充到数据集中观察到的最大长度,并在损失计算过程中使用掩码来忽略填充的步骤。
3.3 BVG 数据集
图 2:血管图示例
为了将我们的模型应用于实际场景,我们选择使用全脑血管图(BVG)数据集,目标是将脑血管图中的每条边(血管)分类为毛细血管、静脉或动脉三类之一。值得注意的是,这些图的构建方式如下:
节点:血管的分叉点(分支点)。
边缘:如上所述,就是血管本身。
特征:包括血管长度、曲率和分叉点之间的最短距离等输入特征。
该数据集在 OGB 上以 ogb-vessel 的名称提供,但是,其中的任务是连接预测(血管是否存在),而基线测试的任务是血管分类。我们项目中使用的所有数据集均从https://github.com/jocpae/VesselGraph下载。
4. 模型架构
我们使用定制架构实现了双重算法推理框架,该架构与标准的 PyTorch 几何 (PyG) 模块有所不同。我们依赖NetworkX来处理图数据结构,并实现了自定义的MPNN(消息传递神经网络)和PGN(指针图网络)层。
4.1 编码-处理-解码框架
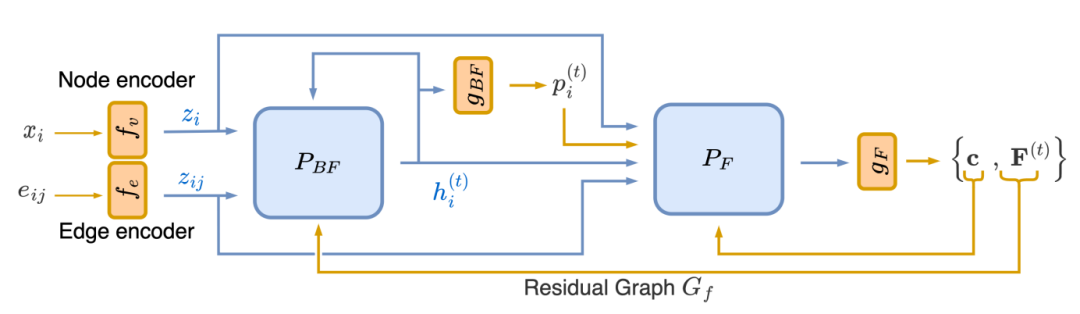
图 3:双重算法推理器 (DAR) 的高级架构
该模型由三个主要部分组成:
编码器:将输入特征(容量、电流)线性投影到潜在嵌入空间。
处理器:执行算法的核心循环图神经网络。
解码器:将最终的潜在嵌入投影回标量值(预测流)。
值得注意的是,该处理器被分为两个相互作用的流:
BFS处理器:预测中间BFS步骤。对于Ford-Fulkerson算法,输出为一条增广路径,该路径会被解码(使用g_BF)成流处理器可用的格式。对于Push-Relabel算法,我们预测从汇聚节点开始的反向BFS步骤,最终输出为每个节点的更新高度。
流处理器:对于 Ford-Fulkerson 算法,该处理器仅更新增广路径中每条边的流。对于推送-重标记算法,该处理器处理推送和重标记的释放步骤。为了整合对偶信息,我们还将生成的潜在嵌入解码为最小割预测。
这些处理器在每一步都交换潜在消息,使得流程推理能够受到切割约束的影响,反之亦然。
利用这种编码-处理-解码架构,算法步骤的学习与特定输入特征的使用解耦,从而在算法选择和迁移学习方面都提供了灵活性。
4.2 转置修改
一个重要的架构挑战是适应Push-Relabel 中使用的全局重新标记启发式算法,该算法涉及从接收器向后运行 BFS 来更新节点高度。
虽然 Ford-Fulkerson 的 BFS 处理器在普通 BFS 中运行良好,但我们的情况略有不同,因为我们从汇聚节点开始,沿着残差图的有向边反向运行 BFS。
标准图神经网络沿前向边传递消息。为了使模型能够学习这种启发式方法,我们修改了最大概率神经网络层,使其能够接受邻接矩阵的转置。
前向传递:使用标准边(u,v)模拟流体推动。
反向传播:使用转置边(v,u)来模拟反向 BFS/重新标记步骤。
这种架构上的改变对于模型区分相对于汇聚节点的“上游”节点和“下游”节点至关重要。这是一个微妙但意义重大的算法特定修改的例子,对于神经算法推理而言必不可少。在实验结果部分,我们提供了证明这一改变必要性的结果。
5.实施挑战和误差分析
虽然该架构在理论上是合理的,但实际应用却暴露出神经算法推理特有的重大挑战。
5.1 复合误差
与标准分类任务不同,NAR 涉及轨迹生成,其中前一个时间步的输出作为下一个时间步的输入。我们观察到轨迹生成本身的特性导致了严重的误差累积问题。微小的数值误差(例如,流量超出容量 0.001)就会违反物理约束。这些违反约束的情况会在数百个时间步内累积,导致出现“不可能”的图状态,进而引发梯度爆炸和 NaN 值。为了稳定这个问题,我们进行了多次归一化迭代、调整损失函数、一些超参数调优以及梯度裁剪。
在Ford-Fulkerson的基准DAR实现中,我们发现作者实际上在模拟算法的每个步骤之后都在模型中实现了一个流校正子程序,以保持流不变性。由于推送重标记放宽了流不变性,转而依赖于高度/标签约束,因此如果不添加大量算法特定的逻辑来手动重新标记和重新分配输出流,就无法简单地校正图状态。添加这些逻辑会违背神经算法推理的初衷。
5.2 排列等变性
我们发现,由于缺乏置换等变性,像 Push-Relabel 这样的并行算法很难被 GNN 模仿。
在真实算法中,如果多个节点有多余的流量,它们“推送”的顺序通常由任意的决胜因素(例如,节点索引)决定。
图神经网络(GNN)具有置换等变性,并且对所有节点一视同仁。它们无法学习这些任意的打破平局规则。
这种不匹配可能在训练过程中引入了噪声,因为模型难以预测哪个活跃节点会改变状态,导致其精度低于Ford-Fulkerson基线模型。
6. 实验结果
我们从算法保真度和现实世界迁移两个方面对该模型进行了评估。
6.1 算法模仿
反向广度优先搜索:通过转置邻接关系修改,我们的模型在模仿全局重标记启发式算法时实现了接近零误差。这表明,当架构允许访问必要的图结构(在本例中为反向边)时,图神经网络可以学习复杂的图算法。
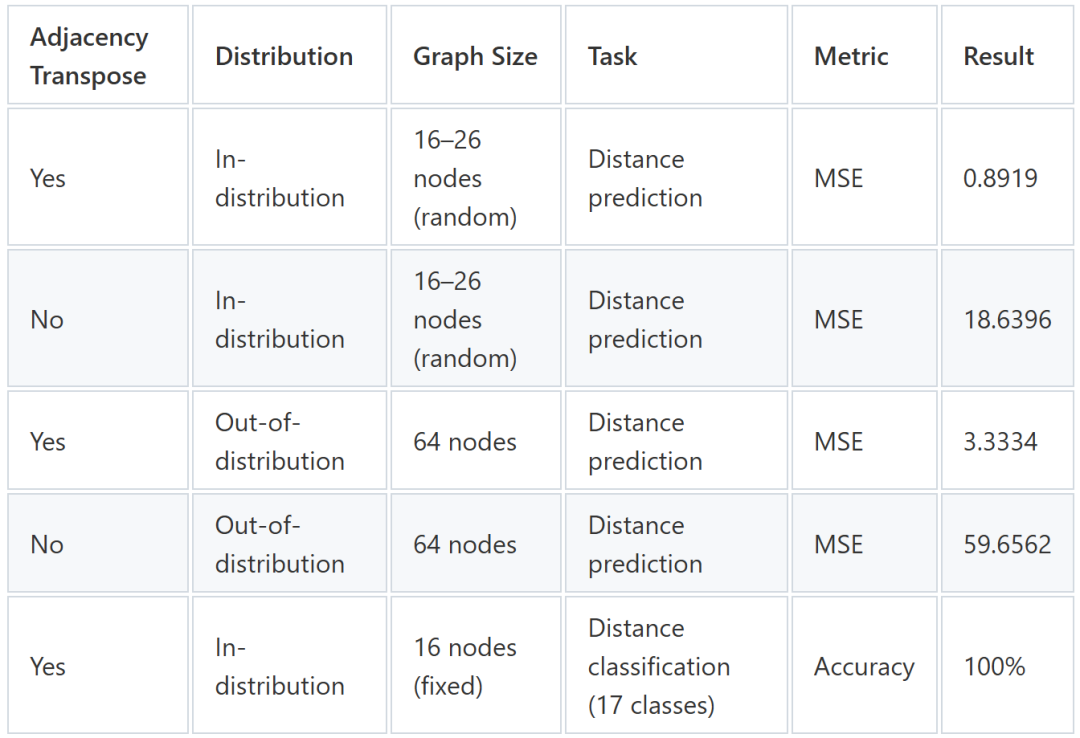
图 4:基于 100 个样本的 BFS 转置邻接性能比较
与仅省略邻接矩阵转置的相同模型相比,性能有明显提升。定性上,我们还可以验证,在模拟的反向广度优先搜索(BFS)的中间步骤中,每个节点到源节点的预测距离也更加合理,这表明模型确实学习了BFS算法。
最后,作为一项补充研究,我们探究了聚合函数的选择是否可能是模型无法正确学习广度优先搜索(BFS)的另一个因素。虽然我们在推送重标记任务中使用了求和聚合和最大聚合(连接聚合),但我们发现它们的任意组合都足以学习BFS,其中最大聚合似乎总体上略优于求和聚合。然而,从数据来看,如果邻接矩阵没有转置,聚合函数的选择对模型学习BFS的能力没有显著影响。
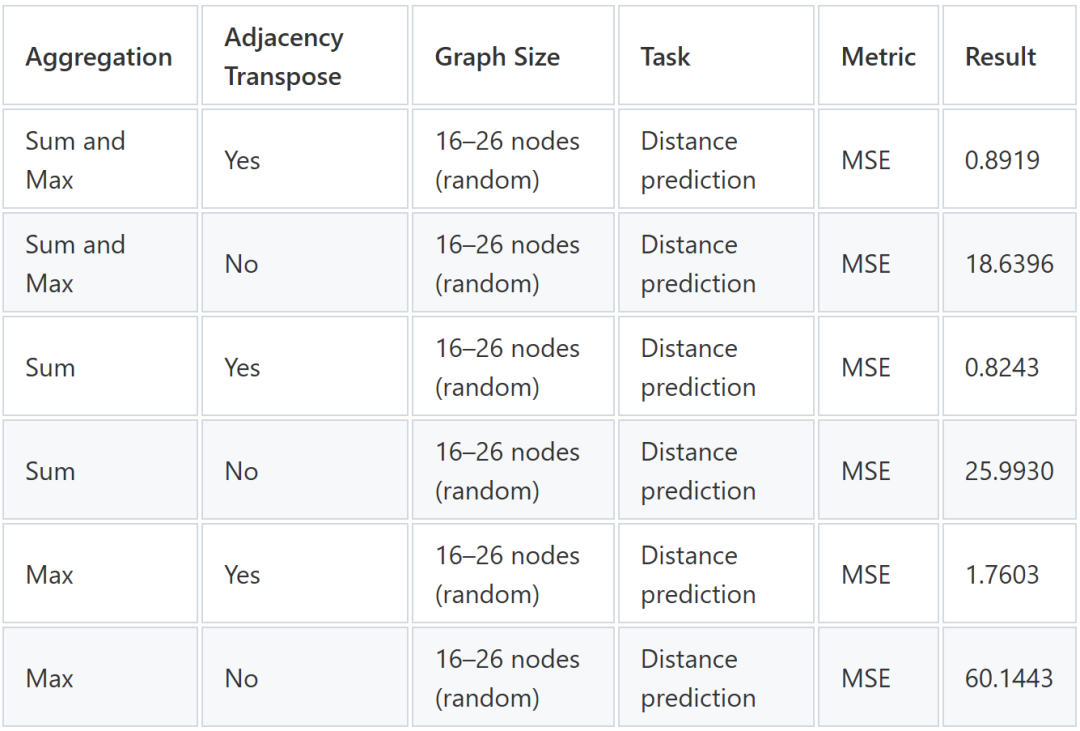
图 5:分布内聚合函数对模型学习 BFS 能力的影响比较(训练超过 1000 次迭代)
完整推送重标记算法:对于完整算法,模型已收敛并生成了有效的流分配结果,但平均绝对误差 (MAE) 高于 Ford-Fulkerson 基线模型。这可能是由于算法本身缺乏置换等变性、与必要的算法特定修改相关的其他未预见的架构缺陷,或需要进一步调整超参数所致。此外,还可以通过修改推送重标记算法来解决置换等变性问题、调整其超参数或添加额外的启发式方法来改进训练算法的轨迹。
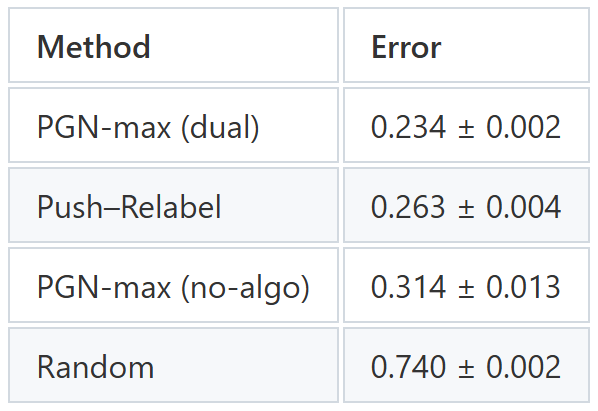
图 6:Push-Relabel 与基线方法在预测合成双社群图的流量方面的性能比较
图 7:Push-Relabel 模型经过 100 次训练迭代后的训练损失曲线,其中性能在不久后开始趋于平稳。
6.2 基于 BVG 的迁移学习
为了测试其在实际应用中的有效性,我们冻结了预训练的处理器,并为BVG血管分类任务训练了新的编码器/解码器。具体来说,我们舍弃了原有的容量编码器,并用新的编码器替换了它们,这些编码器分别表示血管段长度、弯曲度和分叉点之间的最短距离。然后,我们在合成图上重新训练了网络,并在BVG图上运行了Ford-Fulkerson算法和Push-Relabel算法,同时在新生成的边嵌入和我们的流量处理器之间建立了一个跳跃连接。通过这种迁移学习,我们得出以下结论:
Ford-Fulkerson(基线):我们成功地重现了迁移学习流程,取得了与原始 DAR 论文相当的结果。
Push-Relabel(我们的方法): Push-Relabel 编码的分类准确率略低于基线方法。我们推测,预训练期间等变性纠缠引入的噪声导致潜在嵌入的结构性降低,从而降低了其在下游任务中的效用。
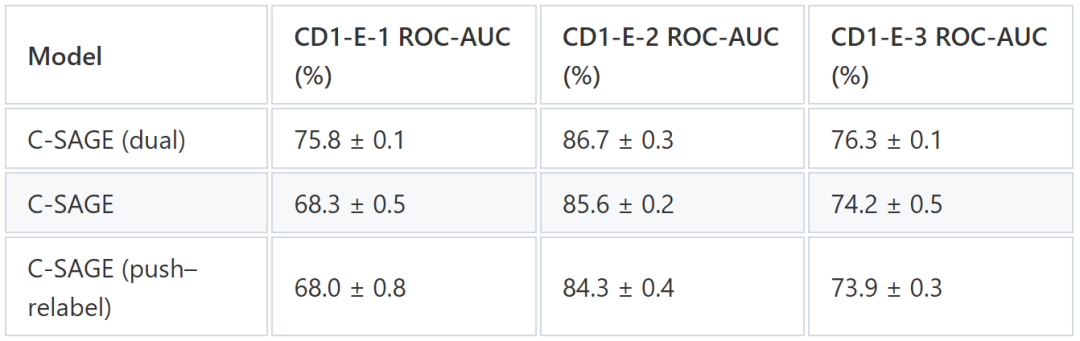
图 8:不同模型的迁移学习性能
7. 结论
我们对用于神经算法推理的推送重标记算法的研究凸显了理论一致性和实际可学习性之间的权衡。虽然我们未能构建出性能优异且优于基准模型的模型,但我们通过实验证明,图神经网络 (GNN) 可以完全解决推送重标记算法中的“全局重标记启发式”步骤,并对可能的误差来源进行了分析。我们面临的挑战可以概括如下:
对齐需要工程设计:理论拟合不足以解决问题。我们只有在显式修改架构以处理边的方向性之后,才成功学习了反向广度优先搜索步骤。
并行算法虽然看似更适合 GNN,但有可能引入非确定性的执行路径,这与 GNN 的等变性相冲突,使得它们比顺序算法更难模仿,尽管它们是“局部的”。
未来的工作应进一步探索模型和/或推送重标记算法实现的改进。此外,我们遇到了一些工程方面的挑战,这主要是由于作者对图神经网络(GNN)进行了自定义实现,其中包含许多针对Ford-Fulkerson模型的细微手工修改。如果我们将来继续这项工作,一种可能的方案是使用PyG等库进行完全重新实现。
参考文献
Veličković, P., et al. (2021). Neural Algorithmic Reasoning.
Numeroso, D., et al. (2023). Dual Algorithmic Reasoning.
Goldberg, A. V., & Tarjan, R. E. (1986). A new approach to the maximum flow problem.
Paetzold, J., et al. (2022). Whole brain vessel graphs.



内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢