
henry 发自 凹非寺
量子位 | 公众号 QbitAI
世界模型,也能持续学习了!
刚刚,纽约大学联合LeCun初创AMI带来JEPA系列的最新成果——
AdaJEPA。

与过去在预训练结束后就冻结参数的世界模型不同,AdaJEPA能够在与环境交互中,基于测试时自适应(Test-Time Adaptation, TTA),实时调整世界模型的编码器和预测器参数,从而实现持续学习。
具体而言,AdaJEPA通过计划、执行、观测、更新、再规划的闭环,在每次交互中只执行MPC规划出的第一段动作,然后把真实观察到的下一帧状态,当成自监督信号来更新世界模型。
由此,在下一轮规划时用的就不再是刚部署时那个冻结模型,而是已经被当前环境“校准”过的模型。
这个思路有点像经典强化学习里的Dyna:
模型不是一次训练完就结束,而是在真实交互中不断修正自己对世界的理解。
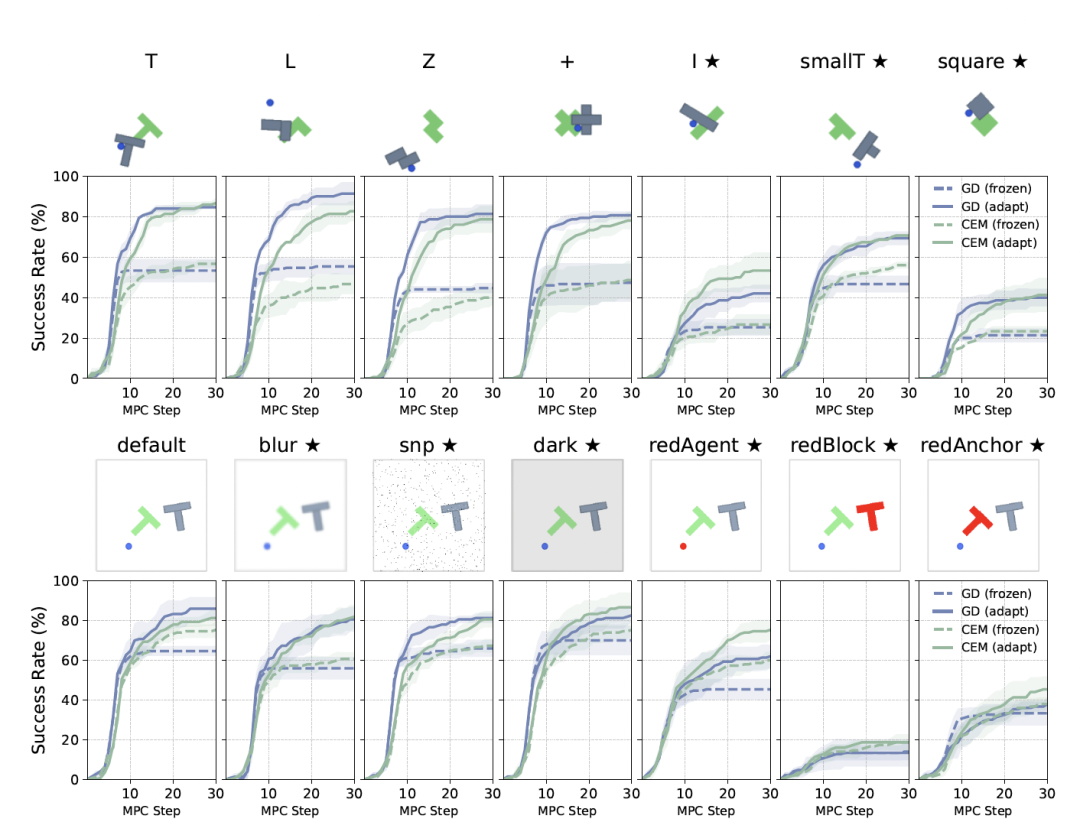
实验结果也表明,无论是在分布内环境,还是面对各类分布外偏移,AdaJEPA的规划成功率都明显优于固定世界模型。
这是怎么做到的?
计划、执行、观测、更新、再规划
一直以来,基于JEPA路线的隐空间世界模型,都有一个默认前提,就是模型训练完,就冻结参数。
整个流程大致是这样:
模型先在离线轨迹上学习把高维图像压进latent space,然后再在这个隐空间里预测未来。
到了测试阶段,MPC(Model Predictive Control,模型预测控制)就会调用这个冻结的世界模型,在隐空间里向前滚动“想象”未来,优化出一串动作,再把第一步动作拿到真实环境里执行。
(注:MPC的核心思想是每次只往前预测一小段,算出一串动作,但先只执行第一步。等真实环境反馈回来,再重新预测、重新规划)
但问题在于,环境一变,冻结世界模型就容易失准。
当系统面临测试时分布偏移(Test-time Distribution Shift)时,在latent space里看起来能到达目标的动作,落到真实环境里,可能一步都不对。
更麻烦的是,MPC本来就靠短时域滚动规划,单步误差往后滚几步,就会被放大。
为解决这一问题,论文提出AdaJEPA框架。
它的核心判断是:世界模型不该训练完就固定在那里。它应该像真正部署中的智能体一样,一边行动,一边用新经验校准自己。
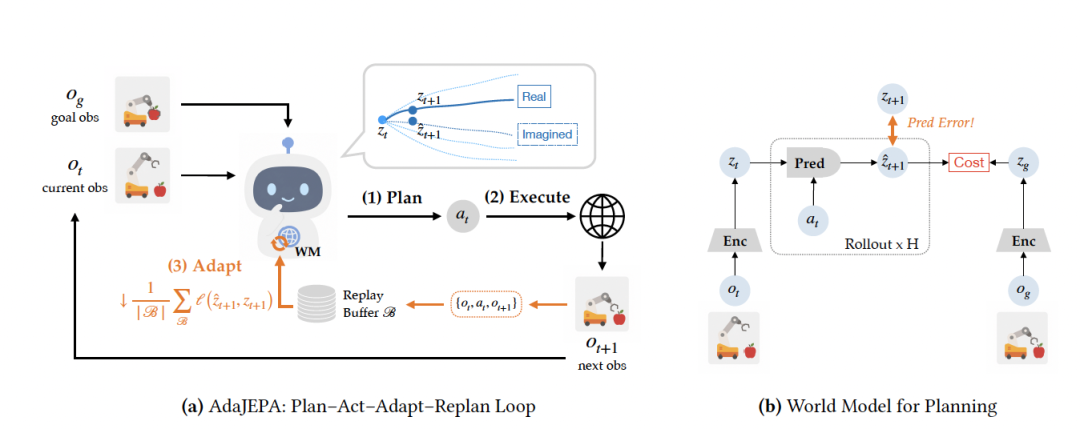
具体来说,AdaJEPA的循环可以分为四步:
规划:模型先把当前观测编码成latent state,然后用当前世界模型进行MPC,在隐空间里向前滚动预测,找出一串最接近目标状态的动作。
执行:模型不会一次性执行完整动作序列,而是只执行第一段动作。随后,真实环境返回下一帧观测。
更新:把这次真实状态转移存进在线缓存区。AdaJEPA再让模型根据观测和动作预测下一步latent state,并和真实状态预测编码出的latent state对齐。预测错在哪里,梯度就从哪里回来。
再规划:更新后的世界模型立刻进入下一轮MPC。论文里默认只更新视觉编码器和预测器的最后几层,每次重规划只做1步梯度下降。
由此,AdaJEPA的循环不再只是传统 MPC 的:规划,执行,再规划。
而是变成了:规划,执行,观测,更新,再规划。

世界模型也因此不再只是一个被动调用的“想象器”,而变成了一个会在部署过程中持续校准自己的模块。
实现细节
在实现上,AdaJEPA的底座依然是JEPA(Joint-Embedding Predictive Architectures),联合嵌入预测架构。
和传统像素级预测世界模型不同,JEPA并不直接预测未来图像,而是先把图像压进一个更紧凑的隐空间,只在latent space里预测未来状态。
具体来说,整个模型由三个核心组件组成:
状态编码器,把当前观测编码成隐状态。 动作编码器 ,把动作编码成动作嵌入。 预测器,根据当前隐状态和动作嵌入,预测下一步隐状态。
AdaJEPA的在线更新,就发生在这个隐空间里。
每次执行动作后,系统都会把真实状态转移存入在线缓存区。这个缓存区不会无限增长,论文里默认只保留最近N条转移。
更新时,AdaJEPA会让模型根据当前观测和动作预测下一时刻的隐状态,再和真实下一帧观测编码出的隐状态对齐。
为了防止在线更新把原本的表征空间拉崩,论文做了两个限制:
一是对目标表征使用stop-gradient;二是只更新少量参数。
实验默认只更新视觉编码器和预测器的最后几层,并且每次MPC重规划只进行1步梯度下降。
所以,这并不是把整个世界模型在线重训一遍。
它更像是每走一步,就用刚刚从真实环境里获得的新反馈,把世界模型往当前环境上轻轻校准一下。
实验测试
为了验证测试时自适应能否让冻结世界模型在环境变化中重新校准自己,论文在PushT/PushObj和PointMaze两个基准上做了实验。
实验表明,在 PushObj未见过形状上,AdaJEPA几乎把规划成功率翻倍。
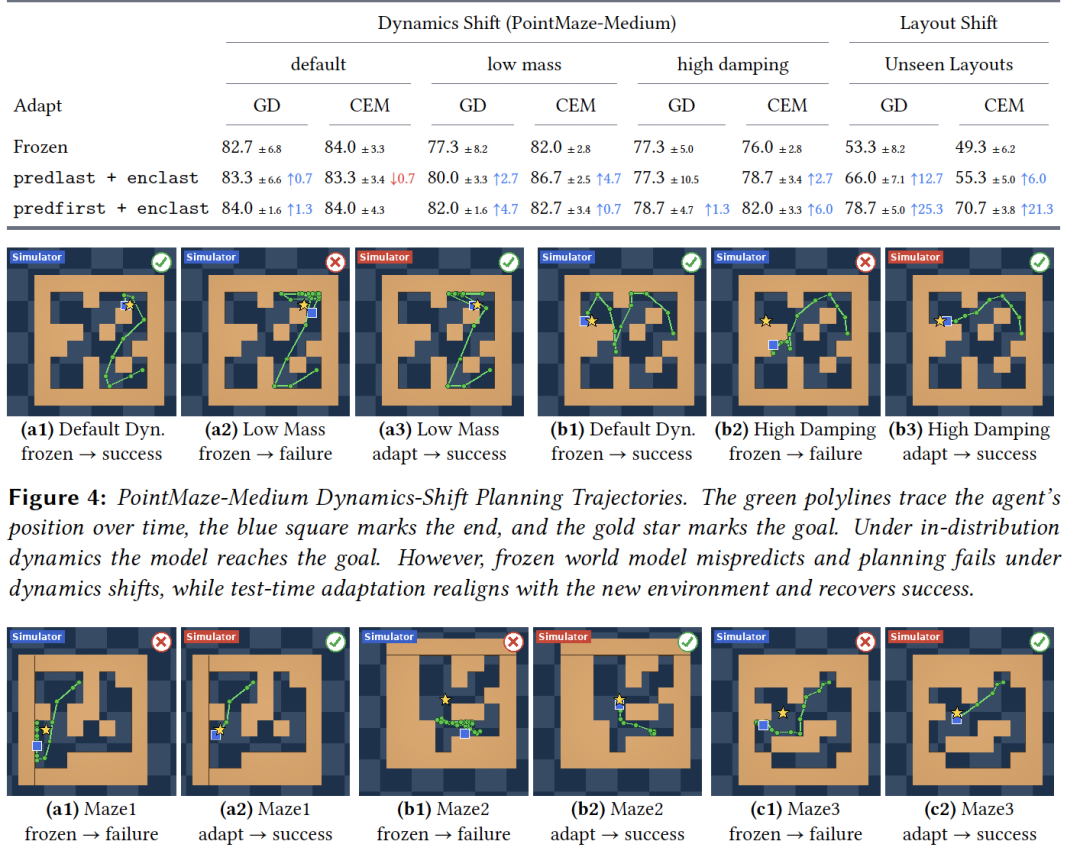
而在PointMaze的未见过布局中,提升同样明显。
其中,GD规划成功率从53.3%提到 78.7%,CEM从49.3%提到70.7%。
更关键的是,这种在线更新带来的额外延迟并不高。
论文默认只更新视觉编码器和预测器的最后几层,每次MPC重规划只做1步梯度下降,额外延迟只有 0.01到0.03秒。
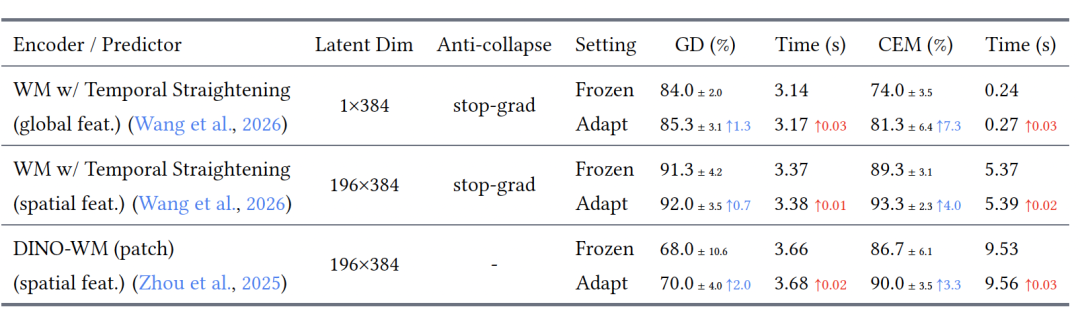
也就是说,AdaJEPA并不是用很重的在线训练,强行换来更高成功率。
它更像是在原有世界模型的基础上,加入了一个轻量的“部署时自我校准”机制。
总体来看,这篇论文想说明的是:
世界模型不必训练完就被冻结,只要让它在部署时利用真实交互结果做轻量更新,就已经能显著提升面对环境变化时的鲁棒性。
作者介绍
最后,让我们来简单介绍一下这篇论文的作者们。
作者Ying Wang目前是纽约大学数据科学中心CILVR Lab 的博士生,研究方向是世界模型,导师是Mengye Ren和Yann LeCun。

另一位作者Oumayma Bounou目前是纽约大学博士后研究员,她的研究兴趣集中在世界模型、控制和优化。
目前,她正与LeCun合作研究世界模型。

此外,纽约大学计算机科学与数据科学助理教授Mengye Ren和图灵奖获得者Yann LeCun共同担任指导作者。
参考链接[1]https://arxiv.org/pdf/2606.32026
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
💬 希望掌握最新AI资讯,欢迎加入量子位「每日AI交流群」👇
💼 这里有大厂做模型的、有创业公司跑落地的、有媒体追热点的,也有VC看项目的。
🙌 添加小助手【qbitbot13】,备注「姓名-公司-职位」,审核通过后入群。

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢