
由开发者 Aratako 于 2026 年发布的开源项目 Irodori-TTS,是一款兼具高保真音质与极强操作性的新一代日语语音合成与零样本克隆模型。其 5 亿参数的核心基础模型 Irodori-TTS-500M-v3 基于连续 DACVAE 潜在空间与 RF-DiT 架构,在保证计算效率的同时能稳定输出 48 kHz 的专业级音频。在实际应用层面,该模型实现了两大突破:一是极速「零样本声音克隆」,用户只需提供 3-10 秒的参考音频,无需微调即可精准复刻目标音色;二是「多维风格控制」,通过创新的 Emoji 注释结合自动时长预测,实现了对情绪、语调及微小非语言表达的精细调节。
目前,HyperAI超神经官网已上线了「Irodori-TTS-500M-v3:日文语音合成与 Emoji 风格控制」,快来试试吧~
在线使用:https://go.hyper.ai/pFPM5
免费领取算力福利
为了便于大家体验 HyperAI 的稳定算力服务,我们准备了丰富的「算力礼包」,内含 NVIDIA RTX 5090、PRO 6000 等 GPU 资源。
扫码添加微信(微信号:Hyperai01),备注「礼包」即可兑换福利!数量有限,手慢无~
欢迎登录官网查看更多内容:
https://hyper.ai/

6 月 27 日- 7 月 03 日,hyper.ai 官网更新速览:
* 优质教程精选:12 个
* 热门百科词条:5 条
* 7 月截稿顶会:4 个
访问官网:hyper.ai
公共教程精选
1. Irodori-TTS-500M-v3:日文语音合成与 Emoji 风格控制
Irodori-TTS 项目由开发者 Aratako 于 2026 年 5 月发布,用于日文文本转语音、零样本声音克隆和 Emoji 驱动的语音风格控制。其创新在于使用整流流扩散变压器(RF-DiT)在连续 DACVAE 潜在空间中生成 48 kHz 语音,并结合参考音频条件、自动时长预测和 Emoji 微妙来控制音色、情绪与非语言发声。
在线运行:https://go.hyper.ai/pFPM5
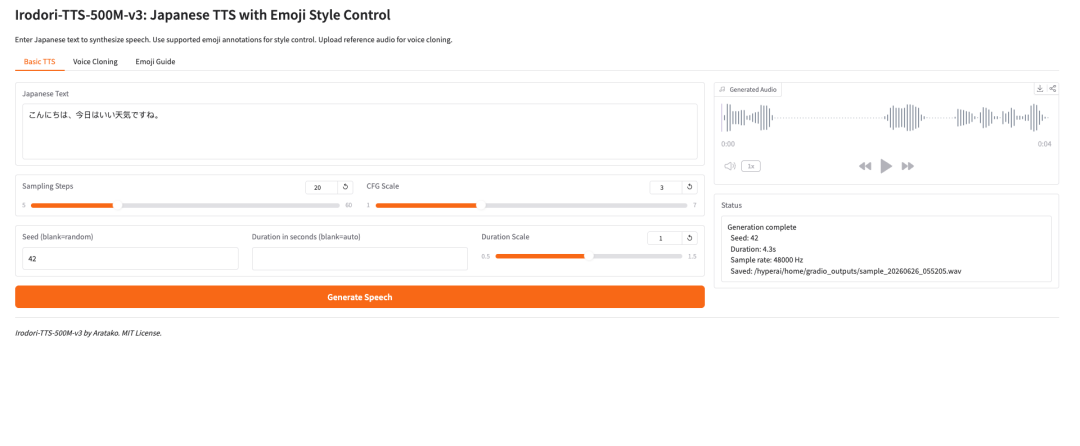
Demo 页面
2. MatAnyone 2 视频抠图模型
MatAnyone 2 项目由南洋理工大学 S-Lab 与商汤科技于 2026 年发布,用于人物视频抠图、提取人物前景与 Alpha 遮罩。其创新依靠自研质量评估器实现稳定抠图,消除画面边界伪影,精准保留发丝细节,支持多人物指定抠图。
在线运行:https://go.hyper.ai/yNeFK
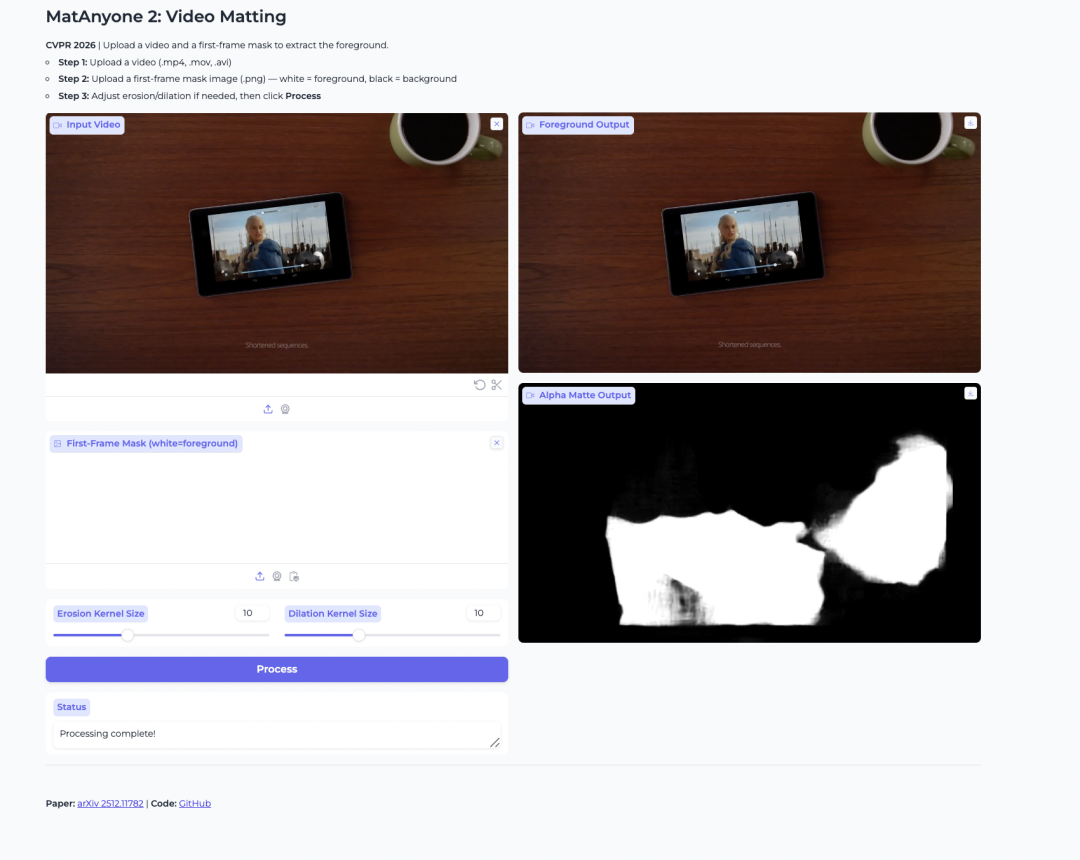
Demo 页面
3. InSpatio-World:实时 4D 世界模拟器
InSpatio-World 是由 InSpatio 团队 于 2026 年 3 月发布的一款基于时空自回归建模的实时 4D 世界模拟器,能够根据输入视频与指定的相机轨迹,生成稳定、可控的新视角视频,实现相机路径的自由控制与时序一致的世界演化。
在线运行:https://go.hyper.ai/8FRRy
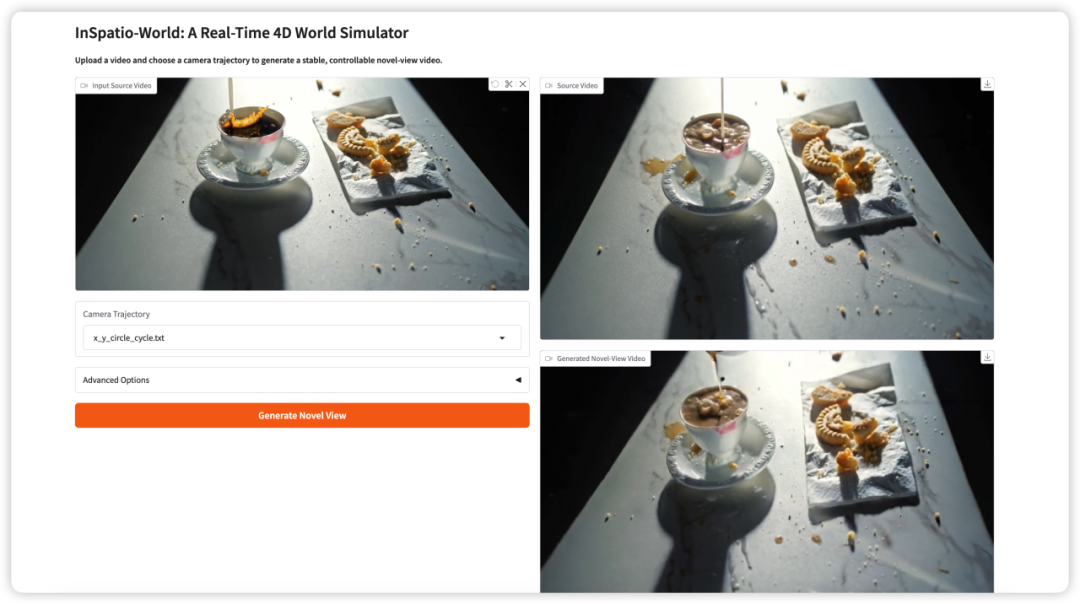
Demo页面
4. DiaMoE-TTS:基于 IPA 的多方言语音合成教程
DiaMoE-TTS 项目由 Giant AI Lab 于 2025 年 9 月发布,用于以国际音标(IPA)为统一前端的多方言语音合成。其创新在于把方言专属知识下沉到 Mixture-of-Experts(MoE)专家路由,并通过 LoRA / Conditioning Adapter 等参数高效方式实现对新方言的零样本快速适配。
在线运行:https://go.hyper.ai/wn9i5
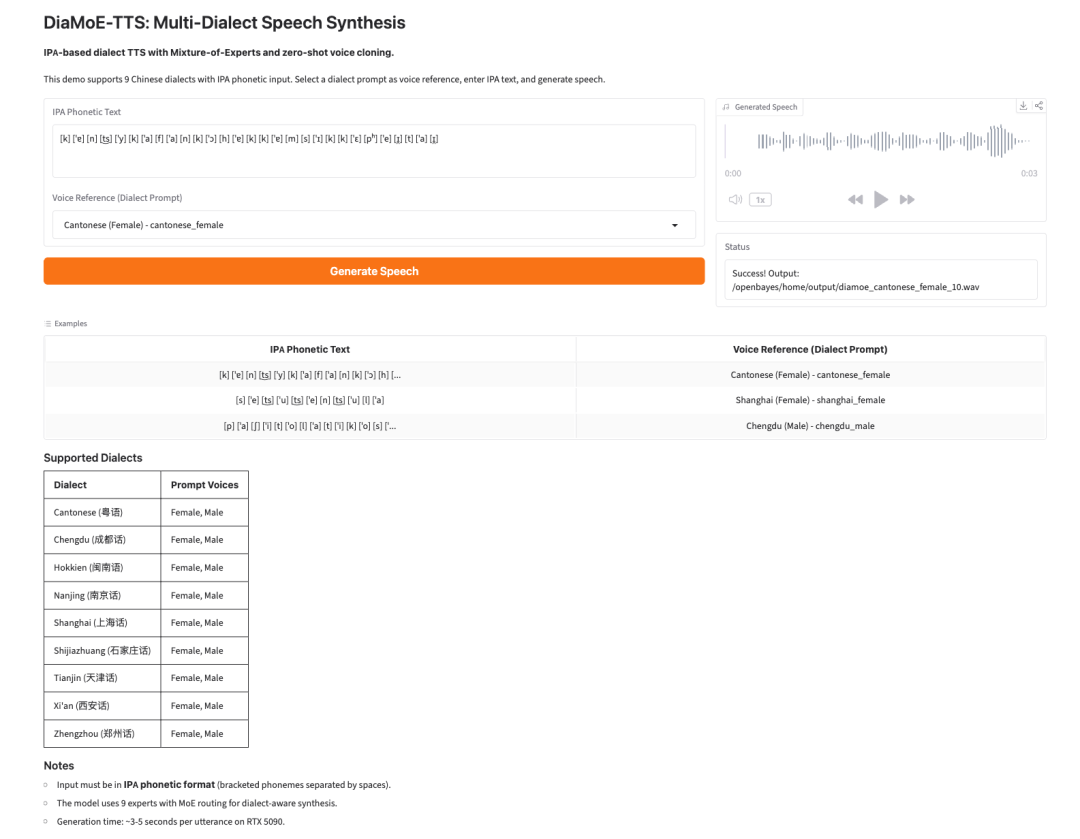
Demo 页面
5. SAM-Audio:用自然语言分离音频中的任意声音
SAM-Audio是 Meta 于 2025 年 12 月发布的音频源分离基础模型。该模型能够通过自然语言描述、视频视觉线索或时间片段等方式,从复杂的音频混合信号中分离出特定声音。
在线运行:https://go.hyper.ai/svjXe
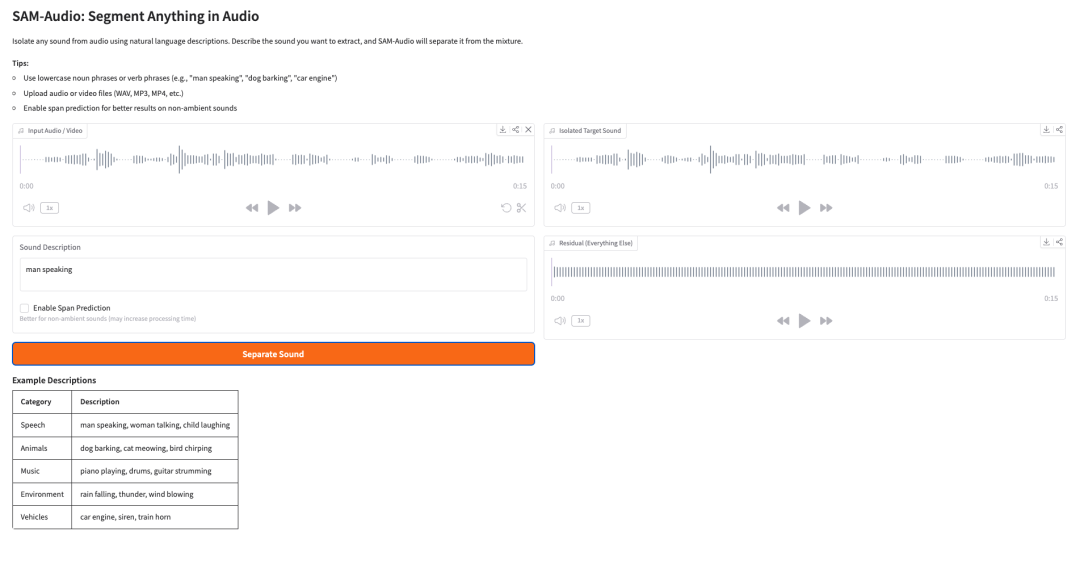
Demo页面
6. PrismAudio:基于分解 CoT 与多维奖励的 V2A
PrismAudio 是通义实验室于 2025 年 11 月发布的视频转音频(V2A)生成模型。该模型是首个将强化学习引入 V2A 生成的框架,基于 ThinkSound 的思维链(CoT)规划机制构建。该模型将单一推理过程拆分为语义、时序、美学、空间四个专项 CoT 模块,并为每个模块配备针对性奖励函数,实现多维度强化学习优化,全面提升各感知维度的推理质量。
在线运行:https://go.hyper.ai/BRGSk
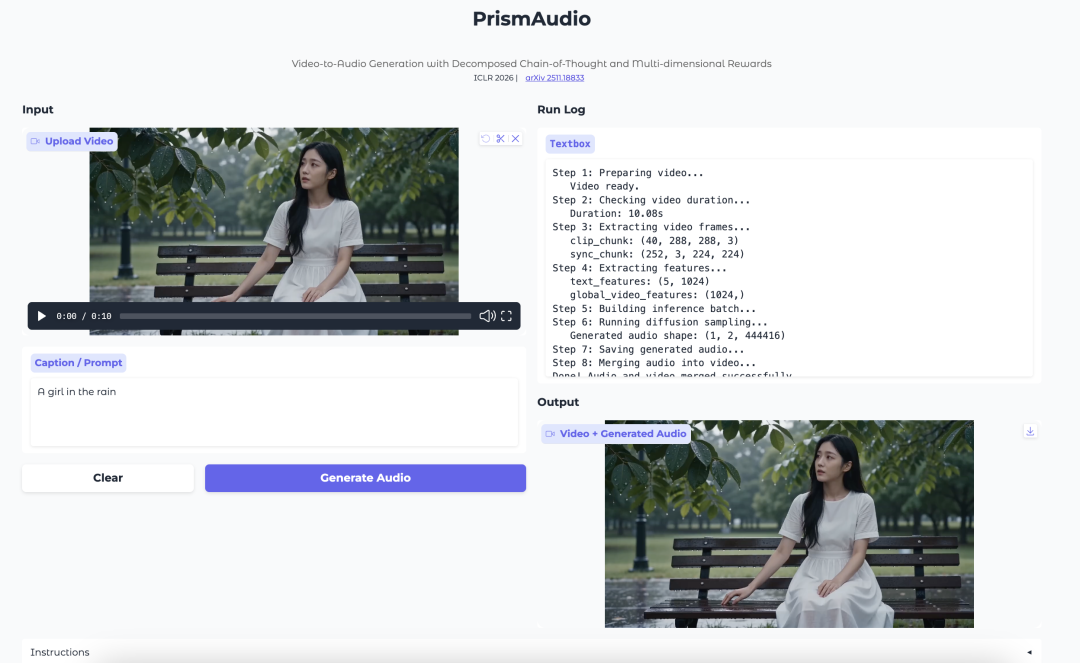
Demo 页面
7. DreamOmni2:多模态指令驱动的图像编辑与生成
DreamOmni2 是香港中文大学 JIA Lab 于 2025 年 10 月发布的多模态指令驱动图像编辑与生成模型,已被 CVPR 2026 接收为 Highlight 论文。该模型基于 FLUX.1-Kontext-dev 基础模型,并结合微调后的 Qwen2.5-VL-7B 视觉语言模型,支持通过自然语言指令结合参考图像进行图像编辑与生成。
在线运行:https://go.hyper.ai/1iqNO
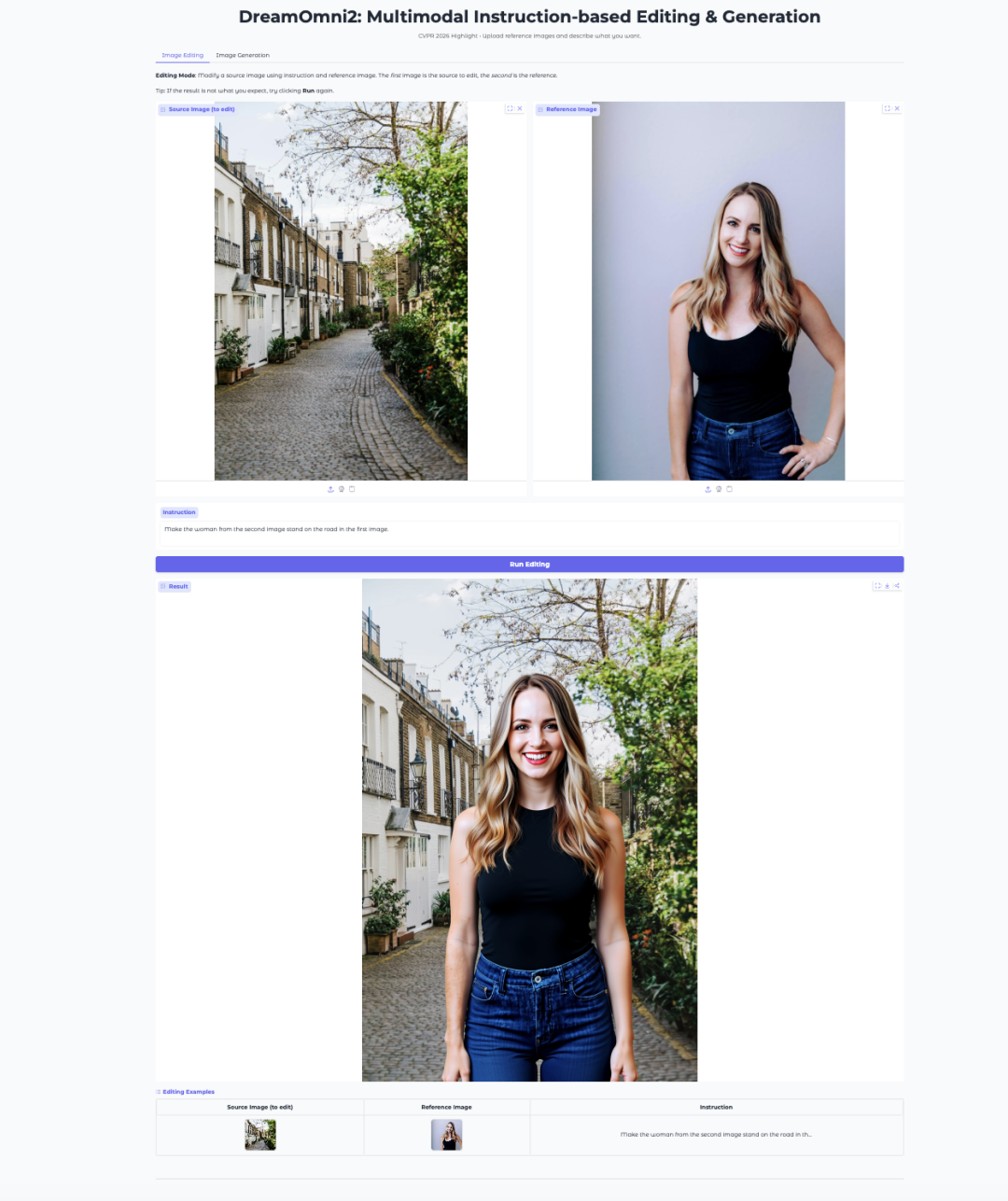
Demo 页面
8. PixelRefer:统一的图像与视频细粒度对象理解框架
PixelRefer 由阿里巴巴达摩院于 2025 年 10 月发布,旨在实现图像和视频中细粒度的对象中心指认、字幕生成和问答功能。其创新之处在于采用了统一的区域级多层线性模型框架(MLLM),并结合了尺度自适应对象分词器(SAOT)以及高效的 PixelRefer-Lite 对象专用框架,用于构建紧凑的对象表示。
在线运行:https://go.hyper.ai/ETjjw
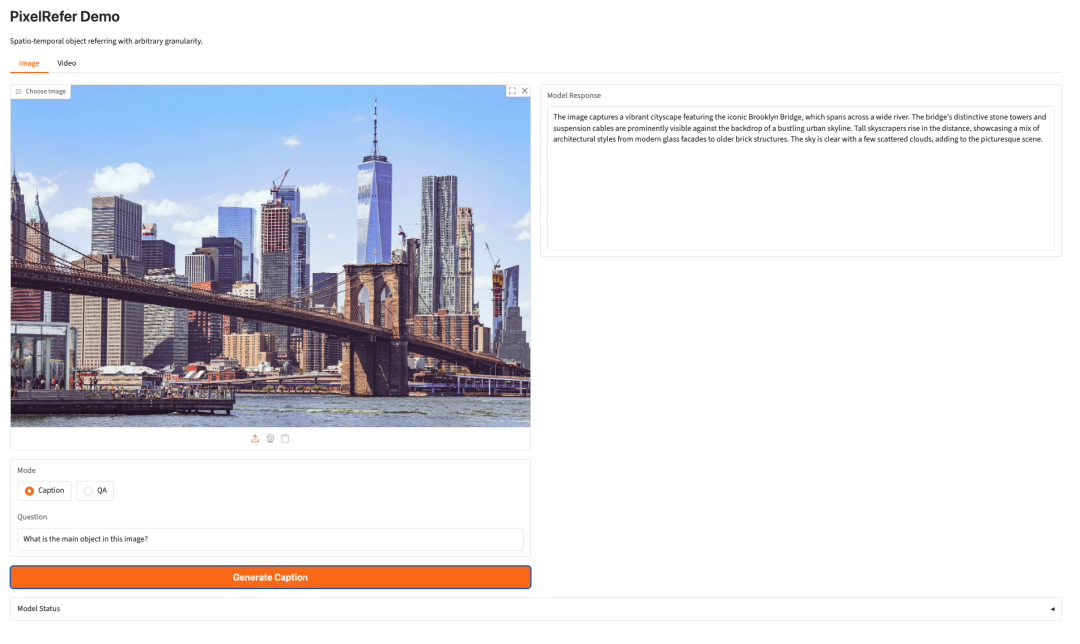
Demo页面
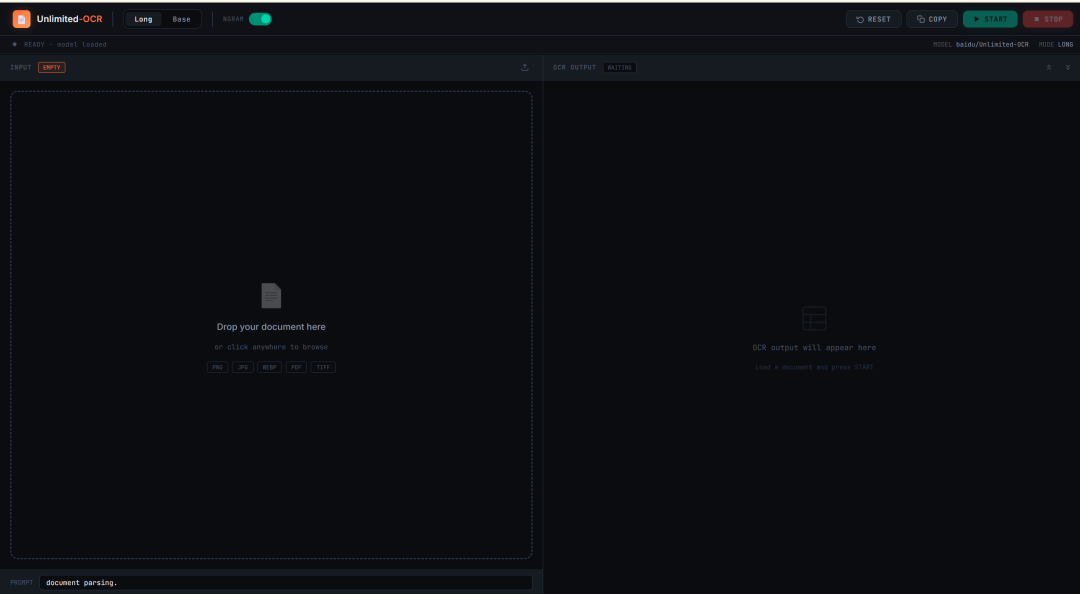
9. Unlimited-OCR:一键部署长文档 OCR 与版面解析
Unlimited-OCR 项目由百度团队于 2026 年 6 月发布。该项目面向长文档 OCR 与版面解析场景,核心目标是在较长上下文中保持稳定的解析效率,实现 One-shot Long-horizon Parsing。该模型可处理单张文档图片、多页图片以及由 PDF 转换得到的页面图片,适合用于论文、报告、扫描件、长表格与多页文档的文字识别和结构化解析。
在线运行:https://go.hyper.ai/Bp69q
Sketch-RNN 整体结构图
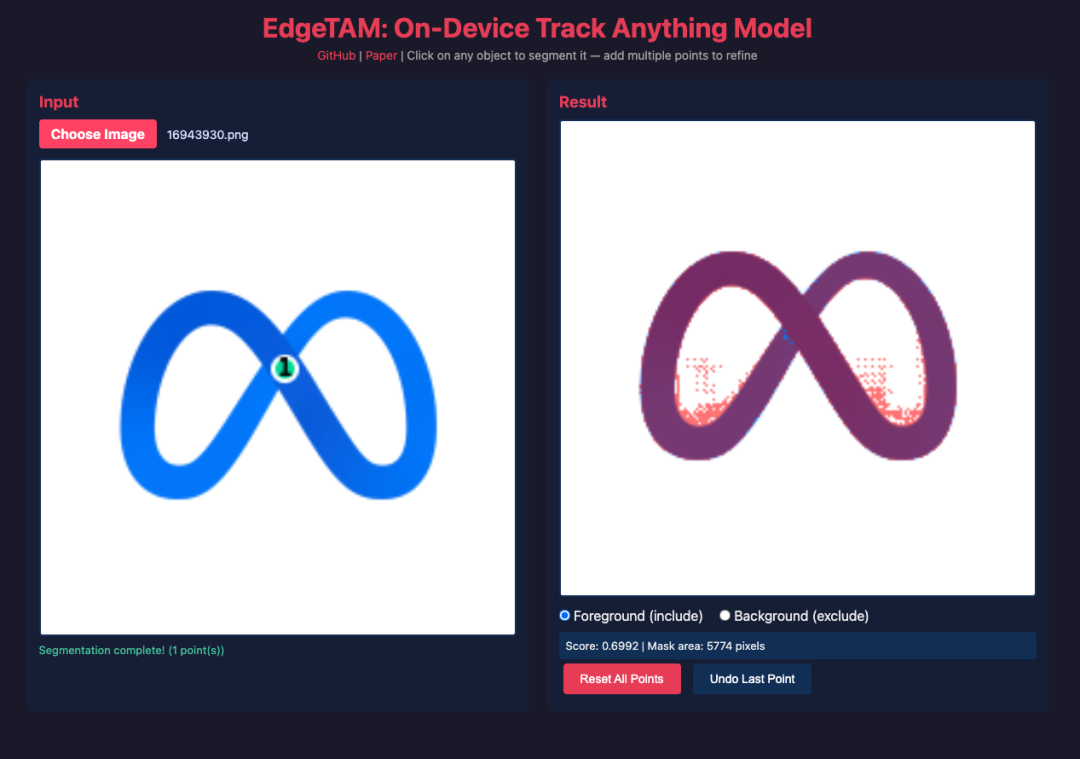
10. EdgeTAM:面向端侧设备的可提示图像与视频分割模型
EdgeTAM 项目由 Meta Reality Labs 与南洋理工大学 S-Lab 于 2025 年 1 月联合发布,面向资源受限设备上的可提示图像分割与视频目标跟踪任务。其核心创新是采用 2D 空间感知器结合蒸馏流程,在保持分割质量的同时降低了 SAM 2 的内存注意力瓶颈,从而实现了高效的设备端「任意跟踪(Track Anything)」交互。
在线运行:https://go.hyper.ai/yZoqO
Demo页面
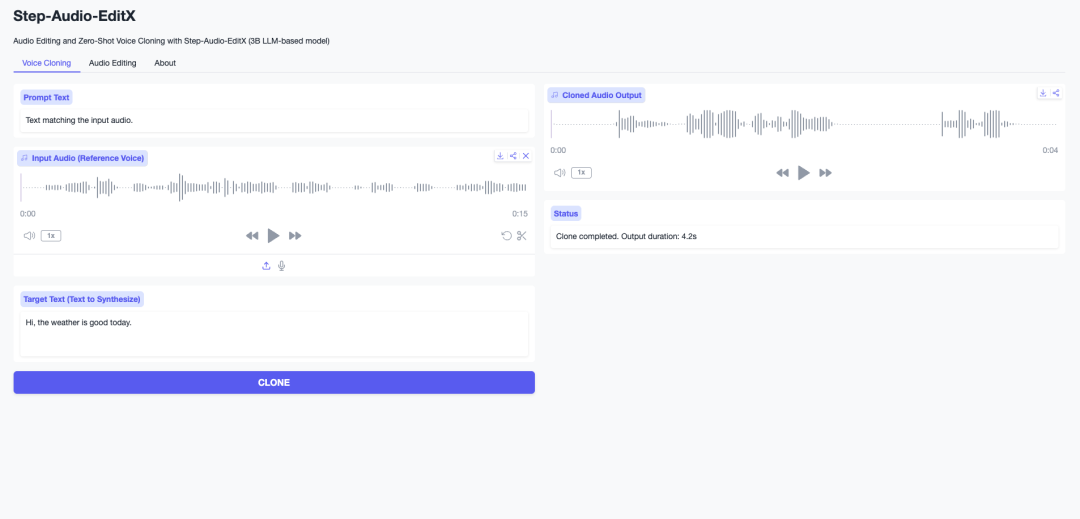
11. Step-Audio-EditX:基于 3B LLM 的零样本语音克隆与表达式音频编辑
Step-Audio-EditX 项目由阶跃星辰(StepFun)于 2025 年 11 月发布,面向零样本语音克隆与迭代式富有表现力的音频编辑任务。其创新之处在于将一个 30 亿参数的大语言模型与强化学习相结合,使情感、说话风格及副语言事件成为可组合的离散控制项;该模型支持普通话、英语、四川话、粤语、日语与韩语。
在线运行:https://go.hyper.ai/UL7Hg
Demo 页面
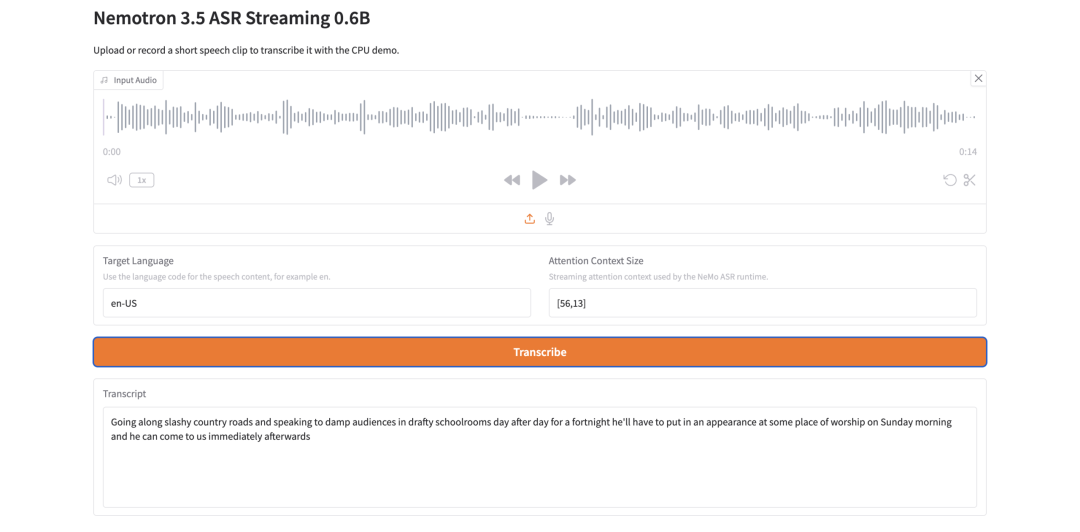
12. Nemotron 3.5 ASR Streaming 0.6B:面向流式语音识别的轻量 ASR 模型
Nemotron 3.5 ASR Streaming 0.6B 是 NVIDIA 于 2026 年 6 月发布的 0.6 亿参数的自动语音识别和低延迟流式转录模型。该模型采用缓存感知型 FastConformer-RNNT 架构,可在流式推理期间重用编码器上下文,从而减少冗余计算。它还支持语言 ID 提示条件,可跨多个语言区域进行转录。
在线运行:https://go.hyper.ai/mFejg
Demo 页面
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD教程】,入群探讨各类技术问题、分享应用效果~

热门百科词条精选
1. 大语言模型 LLM
2. 世界动作模型 WAM
3. 调和平均 Harmonic Mean
4. 虚拟筛选 Virtual Screening
5. 基于 AI 反馈的强化学习 RLAIF
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
https://go.hyper.ai/wiki
7 月截稿顶会
7 月 09 日
23:59:59
POPL 2027
7 月 10 日
23:59:59
ICSE 2027
7 月 17 日
23:59:59
SIGMOD 2027
7 月 28 日
23:59:59
AAAI 2027
* 截稿时间为 AoE 时间
一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
关于 HyperAI超神经 (hyper.ai)
HyperAI超神经 (hyper.ai) 是国内领先的人工智能及高性能计算社区,致力于成为国内数据科学领域的基础设施,为国内开发者提供丰富、优质的公共资源,截至目前已经:
* 为 2100+ 公开数据集提供国内加速下载节点
* 收录 700+ 经典及流行在线教程
* 解读 300+ AI4Science 论文案例
* 支持 700+ 相关词条查询
* 托管国内首个完整的 Apache TVM 中文文档
访问官网开启学习之旅:
https://hyper.ai/




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢