
—— 从“预测一个分数”走向“解释一个患者的肿瘤免疫状态”
COMPASS 概念瓶颈架构以“漏斗”意象呈现——将高维基因表达逐层汇聚为可解释的肿瘤免疫概念。(来源:由Daniel Marbach 博士设计与提供)
COMPASS 概念瓶颈架构以“漏斗”意象呈现——将高维基因表达逐层汇聚为可解释的肿瘤免疫概念。
近日,哈佛医学院、罗氏(Roche)与浙江大学联合在 Nature Medicine 发表研究论文,发布面向肿瘤免疫治疗响应预测的泛癌种 AI 模型 COMPASS。
免疫检查点抑制剂(ICI)已成为多种癌症的重要治疗方式,但并非所有患者都能从中获益。传统生物标志物如 TMB、PD-L1 和 CD8 T 细胞浸润具有一定指导价值,但在不同癌种、不同药物和不同临床队列之间的泛化能力仍然有限。COMPASS 正是为解决这一难题而提出:它不仅预测患者是否可能响应免疫治疗,更试图解释其背后的肿瘤免疫微环境(TIME)机制。

基于“概念瓶颈”的可解释建模
COMPASS 的核心思想是:不把肿瘤转录组作为黑箱输入,而是让患者的bulk RNA-seq表达谱先经过一层“人类可读的生物学概念”,再由这些概念给出预测。这一 concept bottleneck transformer 架构,把预测过程强制“路由”到具有明确免疫学含义的中间变量上,从而使每一步都可被追溯与解释。
具体而言,模型将 上万个蛋白编码基因的表达信息,经由多个免疫基因签名,逐级汇聚为 44 个患者级免疫概念(43 个生物学概念 + 1 个癌种 token)。这些概念覆盖 T 细胞、B 细胞、NK 细胞、巨噬细胞、IFNγ 通路、TGFβ 通路、血管内皮排斥、基因组完整性与细胞增殖等关键肿瘤免疫过程,构成对肿瘤免疫动态的可解释表征。
训练分两步:先在 TCGA数据集上(33 个癌种)进行自监督对比学习预训练,学习泛癌种肿瘤免疫表征;再迁移到真实免疫治疗临床队列进行参数高效微调(提供 FFT/PFT/LFT/NFT 四种模式),以适配从数十到数百例不等的小样本队列。
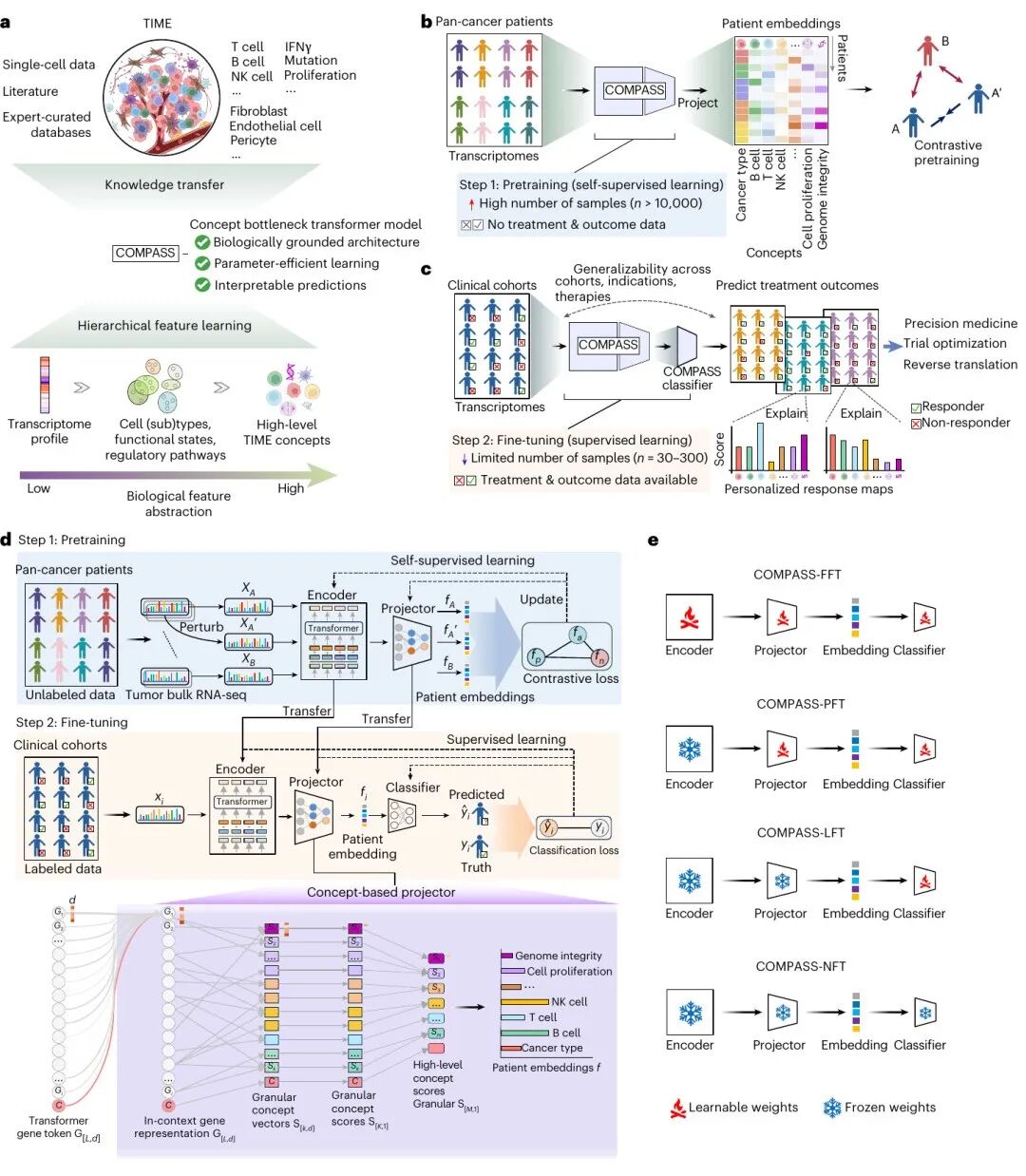
图 1|COMPASS 概念瓶颈基础模型。(a) 通过分层概念学习迁移免疫肿瘤学知识;(b) 泛癌种自监督预训练;(c) 临床队列微调与个体化响应图谱;(d) 由基因编码器、分层概念投影器与分类器组成的模型架构;(e) 四种微调策略(FFT/PFT/LFT/NFT)。(来源:原文 Fig. 1)
为什么不用 ssGSEA?—— 可学习概念 vs 固定打分
一个自然的问题是:既然要把基因映射到通路/细胞类型,为何不直接使用 ssGSEA 或几何平均等传统基因集打分?论文在 Extended Data Fig. 2 中给出了清晰回答。
传统打分方法(Average、ssGSEA)对基因集采用固定、不可学习的聚合规则:每个基因贡献相同,概念之间彼此独立,无法根据下游任务自适应地调整权重。COMPASS 则通过可学习的注意力聚合(gene → gene set → concept),让模型自行学习每个基因、每个基因集对概念的贡献强度。
结果颇具启发性:以“细胞毒性 T 细胞(Cytotoxic T cell)”与“耗竭T细胞(Exhausted T cell)”两个概念为例,在 Average 与 ssGSEA 下二者呈现强正相关(r ≈ 0.54–0.56),因为两组基因高度重叠、固定打分难以区分二者;而 COMPASS在微调后学到二者的负相关(r ≈ −0.45 / −0.35),更符合“杀伤功能”与“功能耗竭”应当此消彼长的免疫学先验。这说明可学习概念不是简单复刻基因集平均,而是能捕捉传统打分所遗漏的功能性免疫状态。
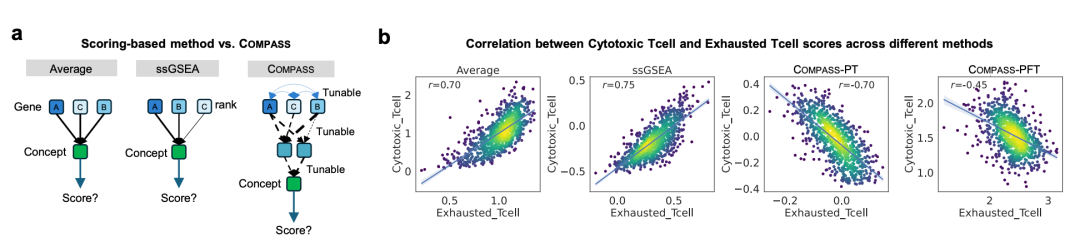
Extended Data Fig. 2|COMPASS 与传统基因集打分方法(几何平均、ssGSEA)的对比。(a) 打分范式示意:传统方法聚合规则固定,COMPASS 各层可学习;(b) 细胞毒性 T 细胞与耗竭 T 细胞得分的相关性——固定打分呈正相关,COMPASS 学到负相关。(来源:原文 Extended Data Fig. 2)
跨队列、跨癌种、跨药物的泛化预测
研究系统整合了16 个免疫治疗临床队列、1,133 名患者,覆盖 7 类癌种与多种免疫检查点抑制剂(anti-PD-1、anti-PD-L1、anti-CTLA-4 及联合治疗),队列在活检部位、测序平台与分析流程上差异显著。
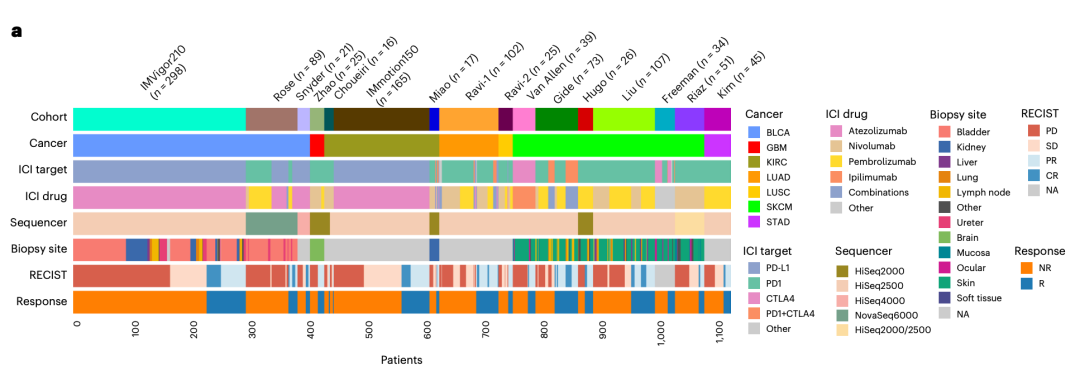
图 2a|16 个临床队列概览:涵盖 BLCA、SKCM、KIRC、LUAD 等 7 个癌种,多种 ICI 靶点、药物与测序平台。(来源:原文 Fig. 2a)
在留一队列(leave-one-cohort-out)验证中,COMPASS 取得 22 种已有方法中的最优平均表现:相比次优方法,准确率提升8.5%,AUPRC提升 15.7%,MCC提升 12.3%。更关键的是,它能推广到训练中未出现的癌种、药物与靶点——例如仅用 PD-1/PD-L1 队列训练即可预测 CTLA-4 治疗响应(准确率 70.8%),仅用单药队列训练即可预测“伊匹木单抗 + 帕博利珠单抗”联合治疗响应(准确率 85.3%),提示不同免疫治疗策略之间存在 可迁移的肿瘤免疫规律。
多阶段微调(MSFT):面向新药与新癌种的域适应
在真实药物研发中,早期临床试验往往只有极少的目标药物数据,使得指导适应症选择、患者富集十分困难。为此,COMPASS 设计了多阶段微调(multi-stage fine-tuning, MSFT)策略,把"域适应"拆解为层层递进的三步:先在泛癌 TCGA 上自监督预训练学习通用的肿瘤免疫表征,再在异质的泛 ICI 队列上做粗粒度微调,最后在特定药物(或联合方案)的小队列上精调——将共享的免疫响应规律逐级迁移到具体治疗场景。
作者据此构建了三种药物特异性模型并系统对比:SSFT1(仅用药物特异队列的单阶段微调)、SSFT2(仅用泛 ICI 队列的单阶段微调)与 MSFT(先泛 ICI、再药物特异的两阶段微调)。为严格防止数据泄漏,粗调阶段会排除与目标药物共享靶点的所有队列(例如构建帕博利珠单抗模型时,排除全部 anti-PD-1 药物)。
结果表明:两阶段的 MSFT 优于任何单阶段策略。。以阿替利珠单抗(anti-PD-L1)为例,在留出的肾癌(KIRC)上 MSFT 达 73.7% 准确率,高于仅用药物队列的 SSFT1(70.3%)与仅用泛癌数据的 SSFT2(60.7%);帕博利珠单抗与纳武利尤单抗模型同样以 MSFT 最佳(82.9% / 73.0%)。在更极端的小样本场景下——仅 33 例 LUAD 帕博利珠单抗患者——MSFT 准确率高达 91%,而单阶段 SSFT1 仅 67%。
这意味着:即便某个新药、新癌种只有数十例数据,也能借助 COMPASS 预训练得到的通用免疫表征,快速搭建可用的药物特异性预测模型,为适应症选择、临床试验入组与反向转化提供了一条参数高效、抗过拟合的域适应路径。
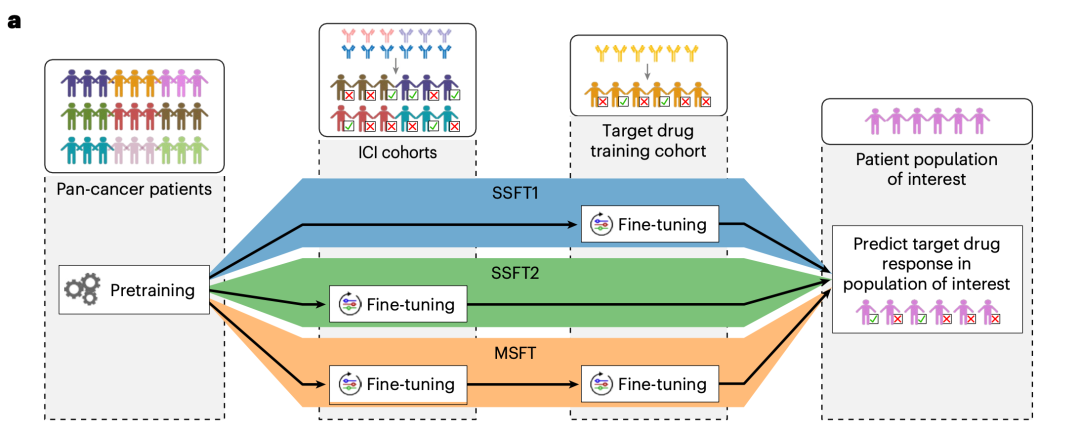
图 4|多阶段微调(MSFT)。(a) 三种策略示意:SSFT1 仅用药物特异队列、SSFT2 仅用泛 ICI 队列、MSFT 为"泛 ICI → 药物特异"的两阶段微调)。
零样本预测:COMPASS-NFT 无需微调的原型推理
当目标队列极小、甚至完全没有响应标签时,即便是轻量微调也可能过拟合。为此,COMPASS 在 FFT/PFT/LFT 三种参数化微调之外,还提供了第四种模式——NFT(no fine-tuning,零样本):它冻结全部预训练权重、不做任何梯度更新,直接在 44 维概念空间中以原型推理(prototypical inference)完成预测。
其机制如下图所示(以 2-way 4-shot 支持集为例):从少量带标签的参考患者出发,响应者(CR/PR)与非响应者(SD/PD)经冻结的编码器 f 映射为各自的 TIME 概念特征向量,按类取均值并做 L2 归一化,得到两个类原型 μ₁(响应)与 μ₂(非响应)。对于一位新的查询患者,先得到其归一化概念向量 μᵢ,再分别与两个原型计算余弦相似度,相似度更高的一方(如 0.8 对 0.2)即决定其 CR/PR 或非响应标签。
由于完全复用预训练概念空间、无需任何训练,NFT 特别适合样本量最小(约 30 例以下)与真正标签稀缺 / 零样本迁移的场景。实际上,在最小队列的组内验证中,NFT 反而表现最佳——因为此时额外微调只会带来过拟合。这样,COMPASS 就形成了从零样本(NFT)到全量适配(FFT)的完整策略谱系,可根据队列规模与标签可得性灵活选择。
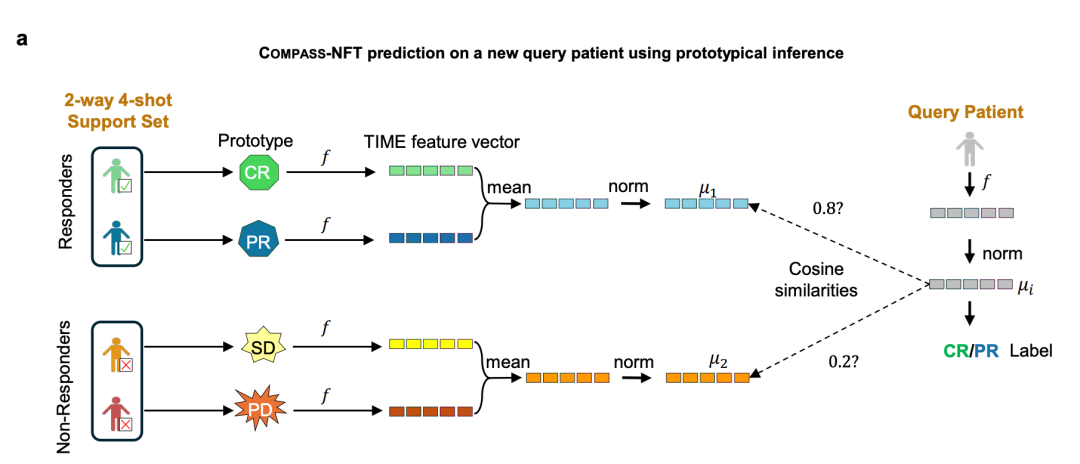
图 S1|COMPASS-NFT 基于原型推理的零样本预测。以 2-way 4-shot 支持集为例:响应者(CR/PR)与非响应者(SD/PD)经冻结编码器 f 映射为 TIME 特征向量,按类取均值并归一化得到原型 μ₁、μ₂;新患者概念向量 μᵢ 与各原型计算余弦相似度,取更高者(如 0.8 vs 0.2)判定标签。(来源:原文 Fig. S1)
不止预测响应,更能预测生存与揭示耐药机制
在IMvigor210 转移性尿路上皮癌队列(阿替利珠单抗)中,COMPASS 预测为响应者的患者具有显著更长的总生存期(HR = 4.37,P = 1.0 × 10⁻⁶),且优于 TMB、PD-L1 IHC 与免疫表型等传统指标。
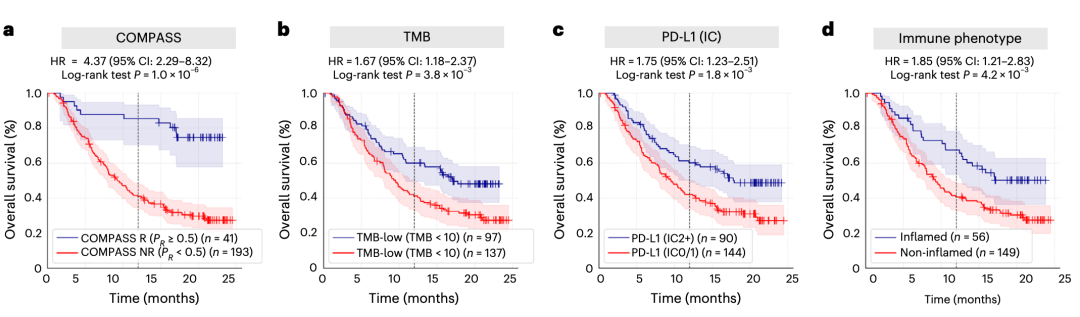
图 5a–d|IMvigor210 队列生存分析。COMPASS 预测响应者的生存获益(HR = 4.37)明显优于 TMB(1.67)、PD-L1 IC(1.75)与免疫表型(1.85)。(来源:原文 Fig. 5a–d)
借助可解释的免疫概念,COMPASS 进一步揭示了传统免疫表型难以解释的现象。例如,一部分 “免疫炎症型”肿瘤虽有 T 细胞浸润却仍不响应:模型提示这些患者往往同时存在 TGFβ 信号激活、血管内皮排斥、CD4 T 细胞功能异常或 B 细胞缺陷等耐药机制;而某些“免疫荒漠型”非响应者则以免疫缺陷特征为主。
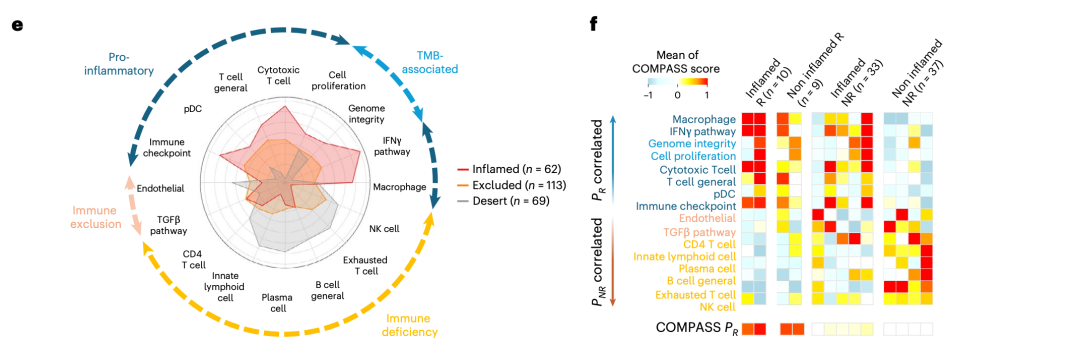
图 5e–f|免疫表型特异的概念图谱。雷达图(e)显示炎症型、排斥型与荒漠型肿瘤在促炎、TMB 相关、免疫排斥与免疫缺陷四类概念上的差异;热图(f)刻画不同响应—表型亚组的概念激活模式。(来源:原文 Fig. 5e–f)
可解释的个体化响应图谱
COMPASS 最具特色的能力,是为每一位患者生成个体化响应图谱(personalized response map)。它把预测结果沿概念瓶颈逐层拆解为五个层级——基因表达 → 编码器表征 → 细粒度免疫概念 → 高层 TIME 概念 → 最终响应概率,并用注意力权重标注每条连接的重要性,从而回答“这位患者为什么响应 / 为什么耐药”。
如下图所示,四位代表性患者呈现截然不同的免疫“路径”:免疫炎症型响应者(a)以广泛的 IFNγ 与细胞毒活性驱动、几乎无免疫抑制信号(P_R = 1.0);免疫荒漠型响应者(b)主要由基因组完整性与适度 IFNγ 驱动,符合 TMB 相关机制(P_R = 0.8);免疫炎症型非响应者(c)则表现为 TGFβ 信号与 B 细胞缺陷共激活(P_R = 0.22);免疫荒漠型非响应者(d)以免疫缺陷特征为主导(P_R = 0)。这类图谱把“黑箱评分”转化为可核查、可生成假设的机制线索,可支持生物标志物驱动的患者富集与联合治疗靶点发现。
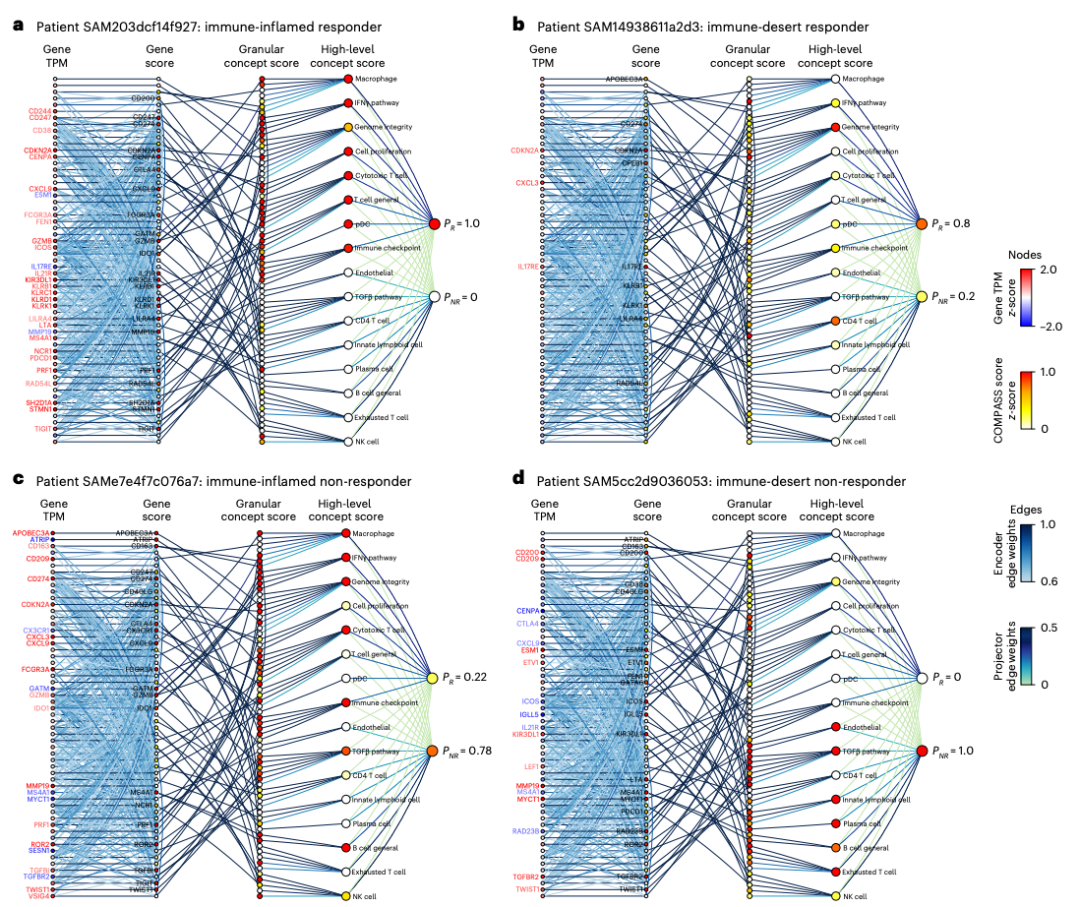
图 6|个体化响应图谱解释单个患者的预测。(a) 炎症型响应者;(b) 荒漠型响应者;(c) 炎症型非响应者;(d) 荒漠型非响应者。颜色编码基因表达 z-score 与概念得分,连线粗细/深浅表示注意力权重。(来源:原文 Fig. 6;交互式工具见 immuno-compass.com)
概念之上再做注意力:COMPASS × Clinical Transformer 的模块化增强
COMPASS 学到的 44 个概念不仅能自己做预测,更是一种"即插即用"的模块化表征,可以去增强其他下游预测器。作者以近期发表于 Nature Communications 的 Clinical Transformer (一种在概念/特征维度上做自注意力的临床转录组生存模型)为例,验证了这一思路——把 COMPASS 的概念接进去,在概念维度上再叠一层注意力,性能还能继续提升。
具体对比了四种整合策略(下图 a–d):标准 Clinical Transformer 以 ssGSEA 打分得到的免疫签名作为输入 token,在这些概念维度上做注意力(ssGSEA-29 用 29 个免疫签名;ssGSEA-43 改用 COMPASS 的 43 个概念作为基因集,但仍用 ssGSEA 打分)。而 COMPASS + Clinical Transformer 则把输入替换为 COMPASS 编码器-投影器学到的 44 维可学习概念分数,再让 Clinical Transformer 在这些概念之上做跨概念自注意力,显式建模概念之间的相互作用;两个模块都先在 TCGA 上自监督预训练,再做迁移学习。
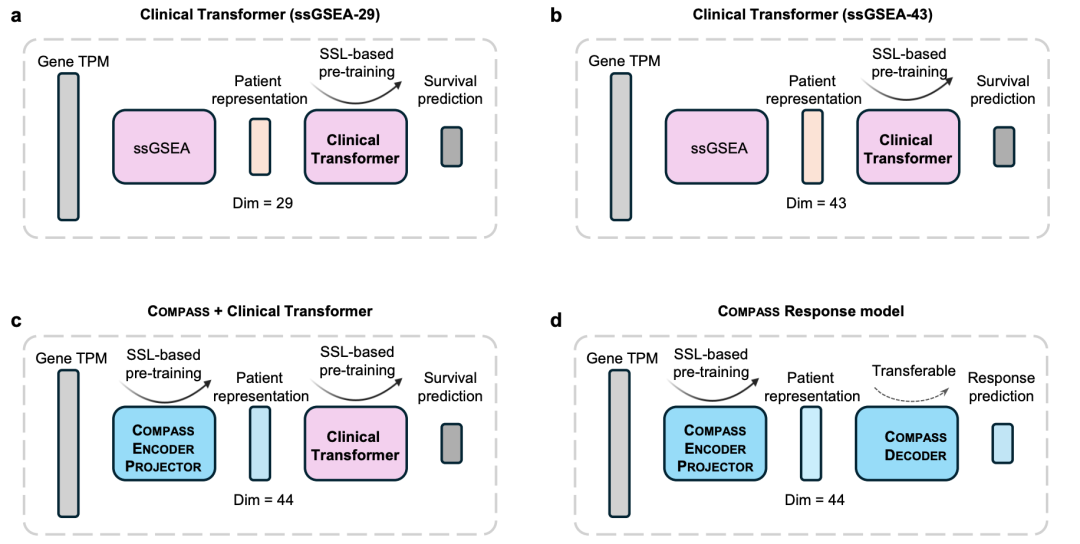
图 S29|COMPASS 与 Clinical Transformer 的四种整合策略。(a) ssGSEA-29:29 个免疫签名经 ssGSEA 打分输入;(b) ssGSEA-43:以 COMPASS 的 43 个概念为基因集、仍用 ssGSEA 打分;(c) COMPASS + Clinical Transformer:用 COMPASS 的 44 维概念分数作为输入,再在概念维度上做注意力;(d) 端到端 COMPASS 响应模型。(来源:原文 Fig. S29)
结果表明,在概念维度上叠加这层注意力能进一步提升生存预测。在迁移学习设置下,COMPASS + Clinical Transformer 的平均验证 C-index 达 0.638,高于 ssGSEA-29(0.629)与 ssGSEA-43(0.616),且提升具统计显著性(相较 ssGSEA 输入 p = 9.8×10⁻⁴、相较标准 Clinical Transformer p = 4.9×10⁻³)。
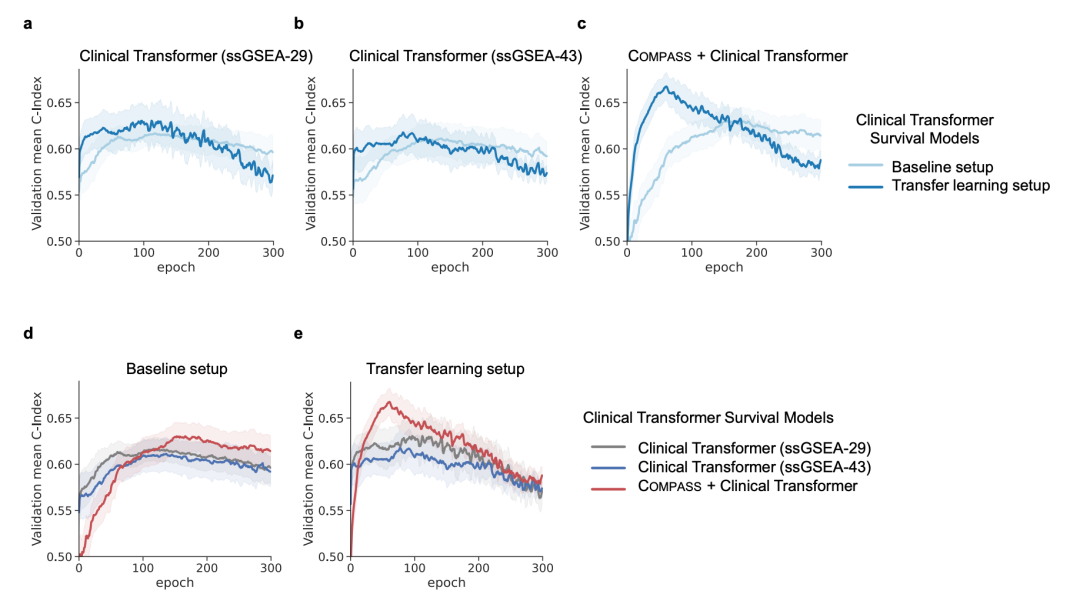
图 S31|以 IMvigor210 留出时的验证 C-index 曲线。(a–c) 三种模型在 baseline 与迁移学习下 C-index 随 epoch 的变化;(d–e) baseline 与迁移学习下三模型的直接对比。迁移学习下 COMPASS + Clinical Transformer(红色)持续取得最高 C-index。(来源:原文 Fig. S31)
在更严格的留一队列独立测试中,COMPASS 系列同样领先:COMPASS-PFT 端到端响应模型平均 C-index 0.610、COMPASS + Clinical Transformer 0.605,均优于 TMB(0.567)与 cGAS-STING 通路模型(0.556);在 IMvigor210 与 Gide 两个留出队列上,COMPASS-PFT 分别达 C-index 0.624 与 0.720。
这说明:相比固定的 ssGSEA 打分,COMPASS 学到的概念是更好的模块化底座——把它接入多模态 / Transformer 预测器,并在概念维度上再做一层注意力,便能"锦上添花"。这支持了一种模块化策略:用可解释的转录组概念编码器去增强各类下游临床预测模型,而不必推倒重来。
面向精准免疫治疗的新范式
这项工作展示了一种新的 AI 医学建模范式:从单一 biomarker 走向多维免疫概念,从队列内预测走向跨癌种泛化,从黑箱模型走向机制可解释。对于药物研发与临床转化,COMPASS 可能在三个方向产生价值:
辅助免疫治疗患者分层,提高临床试验入组效率;
支持新适应症选择,判断某一治疗策略是否可能迁移到新的癌种;
通过个体化免疫概念图谱,发现潜在耐药机制与联合治疗靶点。
当然,作者也明确指出:COMPASS 目前仍属探索性工具,不能单独用于临床决策,也不能作为拒绝患者接受免疫治疗的依据。其概念尚未经实验验证,未来仍需前瞻性临床试验、检测平台标准化与跨中心验证。
从DrugAI的角度看,COMPASS 的意义不仅在于性能更好,更在于它把 AI、转录组学、肿瘤免疫学与临床转化连接进一个可解释框架。未来的精准免疫治疗 AI 不应只“给出一个分数”,而应进一步回答:患者的免疫状态是什么?响应或耐药的机制在哪里?我们能否据此设计更合理的治疗策略?
第一作者介绍
该研究由浙江大学药学院申万祥研究员担任第一作者,罗氏制药首席科学家 Daniel Marbach 博士和哈佛医学院 Marinka Zitnik 教授担任共同通讯。
AIDDPM Lab 长期招聘博士后、科研助理与研究生,欢迎具有计算机、人工智能、自动化、计算生物学、计算化学、生物信息学、机器学习、药物化学、肿瘤免疫、转化医学等背景的优秀青年加入。(http://www.aiddpm.com)长期招聘博士后、科研助理与研究生,欢迎具有计算机、人工智能、自动化、计算生物学、计算化学、生物信息学、机器学习、药物化学、肿瘤免疫、转化医学等背景的优秀青年加入。) 课题组聚焦 AI for Drug Discovery 与 AI for Precision Medicine,重点开展以下方向研究:AI驱动的药物发现与分子设计、多组学基础模型与生物医学大模型、肿瘤免疫治疗响应预测与精准用药、单细胞与空间组学建模、免疫治疗耐药机制解析、mRNA/LNP 设计与递送、AI辅助新型治疗策略开发等。课题组提供开放交叉的研究环境、具有临床转化潜力的数据与科学问题,以及面向高水平论文产出、模型平台建设和应用转化的系统支持。
参考资料
Shen W., Moon I., Nguyen T.H., Li M.M., Huang Y., Nair N., Marbach D. & Zitnik M. Generalizable AI predicts immunotherapy outcomes across cancers and treatments. Nature Medicine,2026. DOI: 10.1038/s41591-026-04502-7.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢