
新年伊始,大规模预训练模型军备竞赛进入万亿参数时代。
Google Brain的研究人员William Fedus、Barret Zoph等1月11日在arxiv上提交了一篇新论文“Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity”,提出了稀疏激活专家模型Switch Transformer。所谓稀疏,指的是对于不同的输入,只激活神经网络权重的子集,简化和改进了来自机器翻译中流行的专家混合模型(Mixture of Experts, MoE)。引人注目的是,模型达到了1.6万亿参数规模,几乎是之前创纪录的GPT-3的十倍,应该是人类历史上发布的第一个万亿级人工智能模型。
一作Fedus是蒙特利尔大学博士生,师从 Hugo Larochelle和Yoshua Bengio。
代码已经在GitHub上开源:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py。
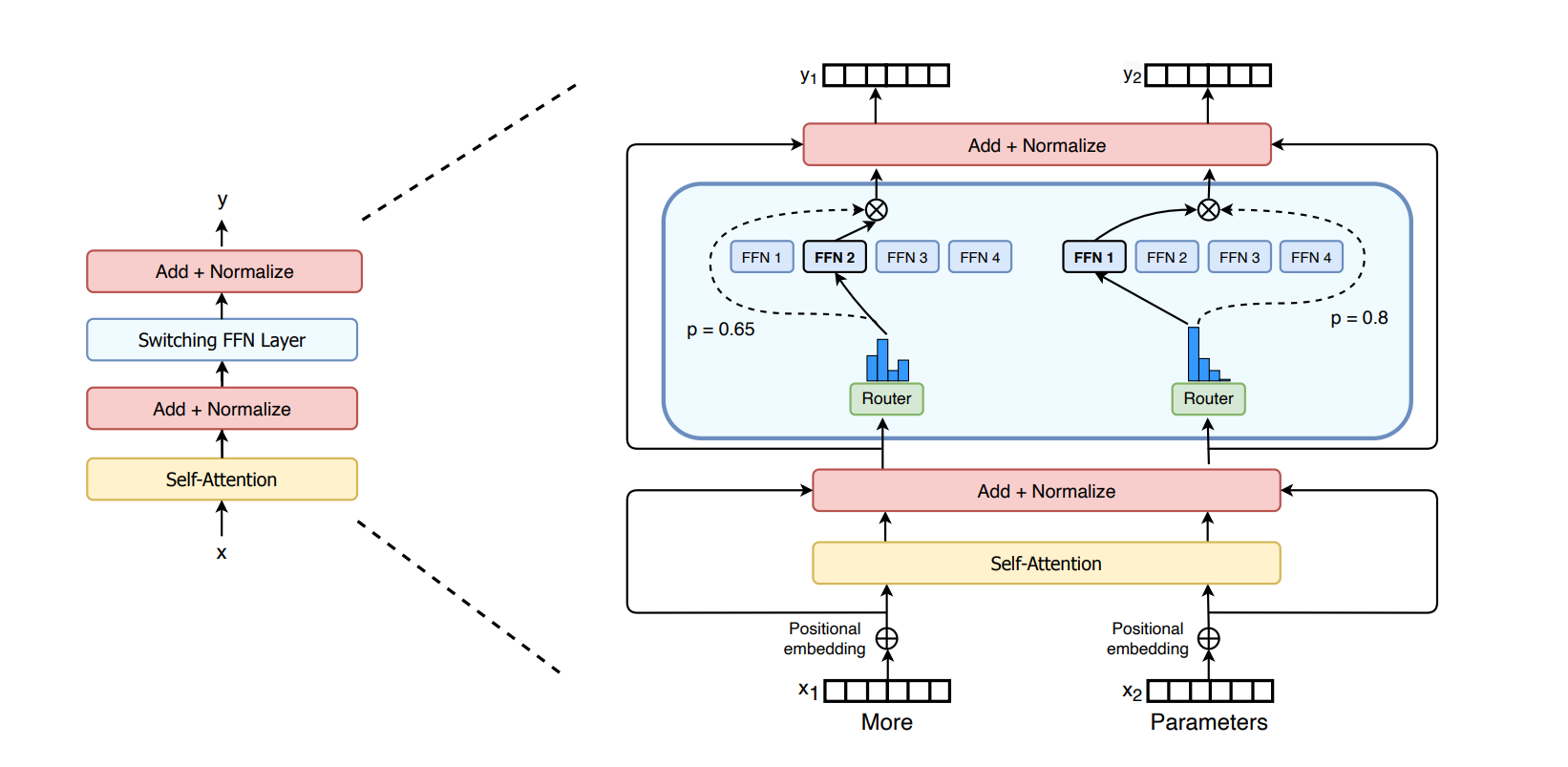
模型架构图如下(淡蓝色方框内是代替了常规前馈神经网络的Switch FFN层):
论文摘要
In deep learning, models typically reuse the same parameters for all inputs. Mixture of Experts (MoE) defies this and instead selects different parameters for each incoming example. The result is a sparsely-activated model -- with outrageous numbers of parameters -- but a constant computational cost. However, despite several notable successes of MoE, widespread adoption has been hindered by complexity, communication costs and training instability -- we address these with the Switch Transformer. We simplify the MoE routing algorithm and design intuitive improved models with reduced communication and computational costs. Our proposed training techniques help wrangle the instabilities and we show large sparse models may be trained, for the first time, with lower precision (bfloat16) formats. We design models based off T5-Base and T5-Large to obtain up to 7x increases in pre-training speed with the same computational resources. These improvements extend into multilingual settings where we measure gains over the mT5-Base version across all 101 languages. Finally, we advance the current scale of language models by pre-training up to trillion parameter models on the "Colossal Clean Crawled Corpus" and achieve a 4x speedup over the T5-XXL model. 在深度学习中,模型通常对所有输入重复使用相同的参数。专家混合模型(Mixture of Experts, MoE)则反其道而行之,为每个传入的示例选择不同的参数。结果是一个稀疏激活的模型,参数数量惊人,但计算成本恒定。然而,尽管MoE取得了一些显著成功,但复杂性、通信成本和训练不稳定阻碍了其广泛采用,这正是我们的Switch Transformer要解决的问题。我们简化了MoE路由算法,并设计了直观的改进模型,从而降低了通信和计算成本。我们提出的训练技术有助于消除不稳定性,并且我们证明大型稀疏模型可能会首次以较低的精度(bfloat16)格式进行训练。我们基于T5-Base和T5-Large设计模型,以使用相同的计算资源将预训练速度提高多达7倍。这些改进扩展到了多语言设置中,在这里我们可以测量所有101种语言在mT5-Base版本上的收益。最后,我们在C4(Colossal Clean Crawled Corpus)语料库上实现了万亿级参数的预训练模型,提升了当前语言模型的规模,速度比T5-XXL模型提高4倍。
论文最后的Future Work部分也很值得关注。

相关媒体报道:VentureBeat Reddit上的讨论
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢