
【论文标题】Unlearnable Examples: Making Personal Data Unexploitable
【作者团队】Hanxun Huang,Xingjun Ma,Sarah Monazam Erfani,James Bailey,Yisen Wang
【发表时间】ICLR2021 Spotlight
【论文链接】https://arxiv.org/pdf/2101.04898.pdf
【推荐理由】我们提出了一种最小化错误的噪声,它可以创建不可学习的例子,以防止个人数据被深度学习模型自由利用。论文收录于ICLR2021 Spotlight。
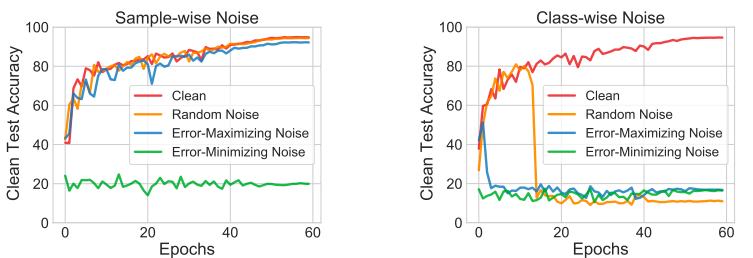 互联网上大量的“免费”数据是当前深度学习取得成功的关键。然而,它也引发了人们对未经授权利用个人数据来培训商业模型的隐私担忧。因此,开发防止未经授权的数据利用的方法至关重要。本文提出了一个问题:对于深度学习模型,数据是否可以变得不可学习?我们提出了一种最小化错误的噪声,它确实会使训练示例变得不可学习。为了使一个或多个训练示例的误差接近于零,故意产生了误差最小化噪声,这可以欺骗模型,使其相信从这些示例中“没有什么”可以学习。噪声被限制在人眼无法察觉的范围内,因此不会影响正常的数据使用。我们以经验验证在样本和类两种形式的误差最小噪声的有效性。并以人脸识别为例,论证了该方法的灵活性和实用性。我们的工作为使个人数据无法被深度学习模型利用迈出了重要的第一步。
互联网上大量的“免费”数据是当前深度学习取得成功的关键。然而,它也引发了人们对未经授权利用个人数据来培训商业模型的隐私担忧。因此,开发防止未经授权的数据利用的方法至关重要。本文提出了一个问题:对于深度学习模型,数据是否可以变得不可学习?我们提出了一种最小化错误的噪声,它确实会使训练示例变得不可学习。为了使一个或多个训练示例的误差接近于零,故意产生了误差最小化噪声,这可以欺骗模型,使其相信从这些示例中“没有什么”可以学习。噪声被限制在人眼无法察觉的范围内,因此不会影响正常的数据使用。我们以经验验证在样本和类两种形式的误差最小噪声的有效性。并以人脸识别为例,论证了该方法的灵活性和实用性。我们的工作为使个人数据无法被深度学习模型利用迈出了重要的第一步。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢