
本文来自:大数据文摘编译作品 编译:周熙 来源:ONEZERO
上周,OpenAI发布了DALL-E,这是一个可以根据书面文字生成图像的AI系统。例如,针对提示 "一个牛油果形状的皮包,一个模仿牛油果的皮包",该系统可以对牛油果皮包的想法生成几十次迭代。
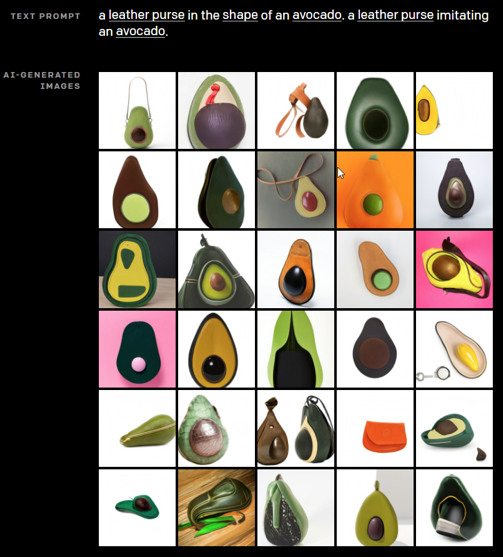
当然OpenAI公司并不是第一个尝试从文本生成图像的公司,该算法也不是它的第一次尝试。本文通过对该算法的成长历程进行可视化浏览,我们可以追溯该技术到底走了多远。这里面包括:2016年、2017年、2019、2020年的几篇重要论文。
2016 这篇来自密歇根大学和Max Planck研究所的论文被OpenAI誉为振兴当前文本到图像生成研究的论文,该论文使用生成式对抗网络,即GANs来生成图像。GANs的功能是将两种算法对立起来。一个用来生成图像,另一个如果图像看起来不够真实,就拒绝它。
论文链接: https://arxiv.org/pdf/1605.05396.pdf

2017 一年后,Rutgers大学、Lehigh大学和香港中文大学的研究人员采取了另一种GAN方法——"叠加 "成对算法。第一对算法将场景的形状和颜色铺设出来,第二对算法完善细节。
论文链接: https://arxiv.org/pdf/1710.10916.pdf

2019 2019年,另一个主要隶属于微软的团队尝试了一种不同的两步法。第一步是生成一张物体在场景中的位置图,第二步是以这张位置图为指导,生成物体,形成想要的画面。
论文链接: https://arxiv.org/pdf/1902.10740.pdf

2020 而在去年年底,Allen AI 研究所发表了一项研究,使用了一个与OpenAI相同的转换器模型。Allen研究所的研究人员没有去追求模型的纯粹大小,而是依靠 "masking"。麻省理工学院科技评论的Karen Hao在一篇解释该论文的大文章中进一步详细介绍了masking,他将masking描述为:"在句子中隐藏不同的单词,并要求模型填入空白"。通过让算法学习进行这些直观的跳跃,研究人员发现,图像生成的质量得到了极大的提高。
研究论文链接: https://arxiv.org/pdf/2009.11278.pdf 解释文章链接: https://www.technologyreview.com/2020/09/25/1008921/ai-allen-institute-generates-images-from-captions/
 通过查看这些过去研究的例子,很明显,OpenAI的DALL-E真的是一个很大的飞跃。
通过查看这些过去研究的例子,很明显,OpenAI的DALL-E真的是一个很大的飞跃。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢