
本文主要介绍刚刚被IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI)录用的一篇文章:Regularizing Deep Networks with Semantic Data Augmentation 地址:https://arxiv.org/abs/2007.10538 其会议版本发表在NeurIPS 2019:https://arxiv.org/abs/1909.12220 代码和预训练模型已开源:https://github.com/blackfeather-wang/ISDA-for-Deep-Networks。 知乎链接:https://zhuanlan.zhihu.com/p/344953635
在计算机视觉任务中,数据扩增是一种基于较少数据、产生大量训练样本,进而提升模型性能的有效方法。传统数据扩增方法主要借助于图像域的翻转、平移、旋转等简单变换,如图1中第一行所示。我们的工作则提出了一种隐式语义数据扩增算法:ISDA,意在实现对样本进行更为「高级」的、「语义」层面的变换,例如改变物体的背景、颜色、视角等,如图1中第二行所示,注意这些变换并不改变任务标签。具体而言,ISDA具有几个重要的特点:
- 与传统数据扩增方法高度互补,有效地增进扩增多样性和进一步提升性能
- 巧妙地利用深度神经网络长于学习线性化表征的性质,在特征空间完成扩增过程,无需训练任何辅助生成模型(如GAN等),几乎不引入任何额外计算或时间开销
- 直接优化无穷扩增样本期望损失的一个上界,最终形式仅为一个全新的损失函数,简单易用,便于实现
- 可以广泛应用于全监督、半监督图像识别、语义分割等视觉任务,在ImageNet、Cityscapes等较大规模的数据集上效果比较明显。
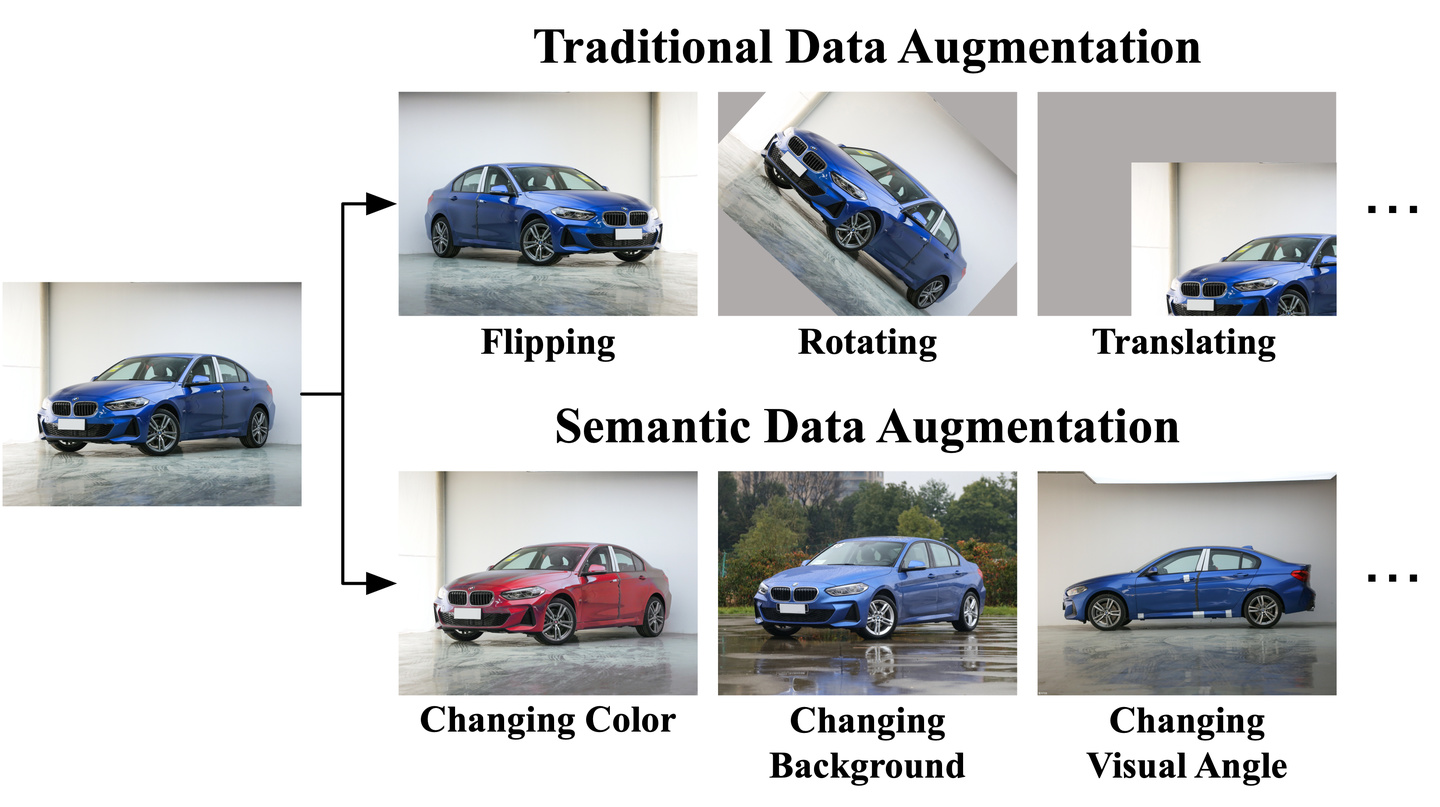 图1:传统数据扩增与语义数据扩增的比较
图1:传统数据扩增与语义数据扩增的比较
阅读详细论文介绍,点击下面的“阅读原文”链接。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢