
作者:Nicholas Carlini,Google Research 研究科学家
基于机器学习的语言模型经过训练后,能够预测一句话中的下一个单词,随着能力越来越强大,这样的语言模型也变得更加普遍和实用,推动问答系统和翻译等多个应用领域取得突破性的进展。但语言模型在不断发展的同时,难以预料的新风险也随之而来,研究社区因此必须积极主动地想出新方法来缓解潜在问题。
其中一种新风险是模型可能会泄露其训练数据中的细节。尽管这可能是所有大型语言模型都存在的隐患,但如果使用私人数据训练的模型公开可用,可能还会造成其他问题。因为这些数据集的体量很大(数千亿字节)并且提取自各种来源。即便使用公开数据对模型进行训练,有时仍然可能包含敏感数据,如个人身份识别信息 (PII) :姓名、电话号码、地址等。这就会造成一种可能性,即是用此类数据训练的模型会在其输出中可能会透露一些私人信息。因此,我们有必要识别并尽可能减少此类泄漏的风险,并制定策略以解决未来可能面对的同类潜在问题。
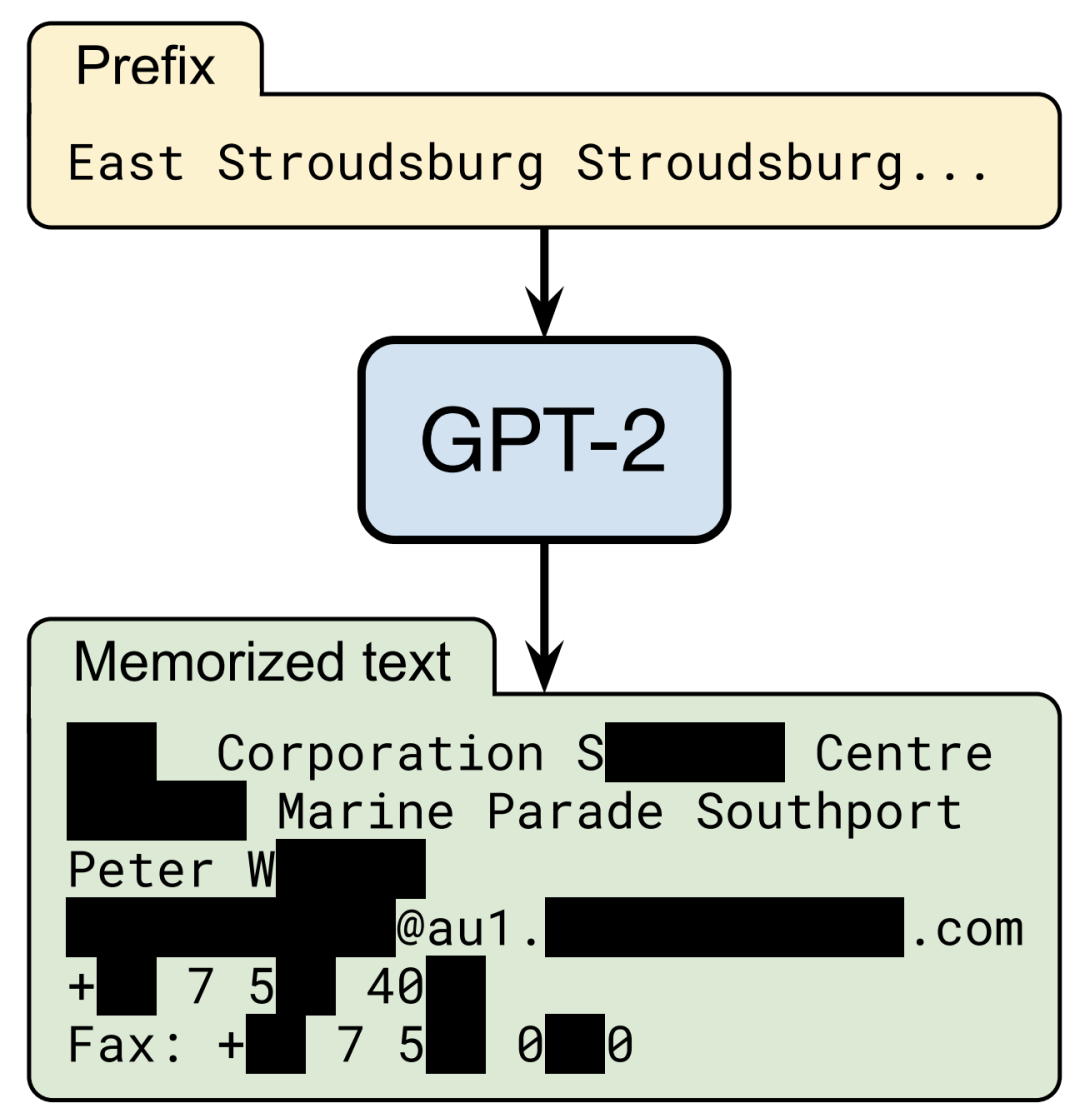
在与 OpenAI、Apple、斯坦福大学、加州大学伯克利分校以及美国东北大学合作进行的“从大型语言模型中提取训练数据 (Extracting Training Data from Large Language Models)” 研究中,研究人员证明,只需要能够查询预先训练过的语言模型,就可以从模型已记忆的训练数据中提取特定片段。由此可见, 训练数据提取攻击 (Training Data Extraction Attack) 已构成对 SOTA 大型语言模型的实际威胁。这项研究传达出关键的预警信号,让研究人员知晓这类风险,以确保他们可以采取措施来弥补漏洞。
实际上,这篇论文的相关链接之前社区里已经推过,不过本文是论文一作,Google Research 研究科学家Nicholas Carlini的亲自解读,所以不妨从作者的视角品读一下。
接下来作者将从以下几个方面进行展开描述:
- 语言模型攻击研究的道德问题
- 训练数据提取攻击
- 实验结果
- 经验教训
感兴趣的小伙伴可以戳原文。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢