
个性化推荐系统旨在根据用户的行为数据提供「定制化」的产品体验,精准的推荐系统模型也是很多互联网产品的核心竞争力。作为一款国民级短视频 App,快手每天都会为数亿用户推荐上百亿的视频,这就涉及到一个挑战:推荐系统模型如何精准地描述与捕捉用户的兴趣?
如今业内采用的解决方案通常为结合大量数据集和拟合参数来训练深度学习模型,如此一来让模型更加逼近现实情况。Google 日前发布了首个万亿级模型 Switch Transformer,参数量达到 1.6 万亿,其速度是 Google 之前开发的最大语言模型(T5-XXL)的 4 倍。
实际上,快手万亿参数精排模型总的参数量超过 1.9 万亿,规模更大,且已经投入实践。这篇文章将正式介绍快手精排模型的发展史,感兴趣的可以戳原文。
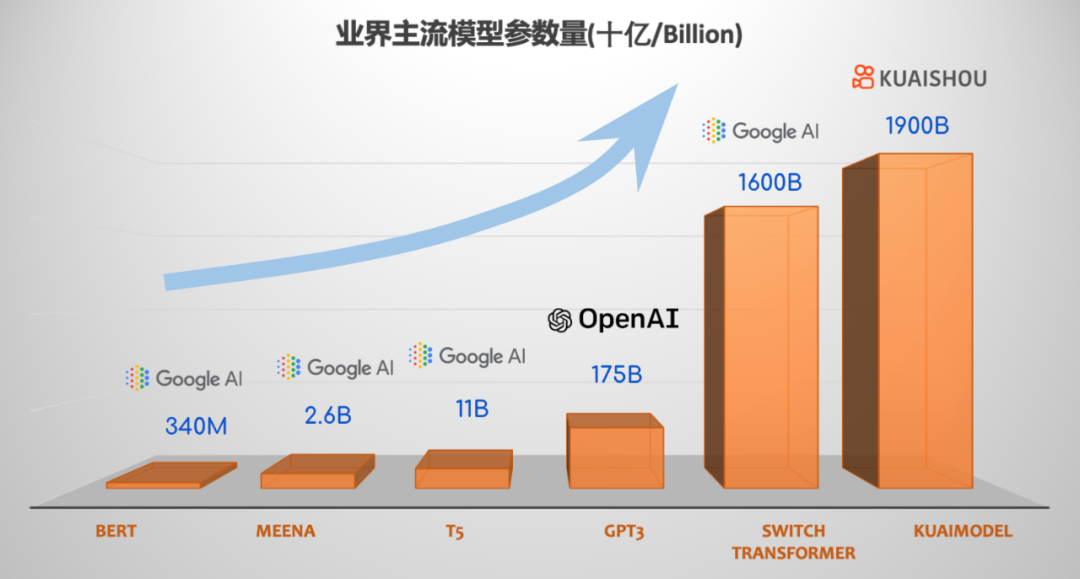
上面这张对比图中,从左到右分别是:
- Google BERT-large NLP 预训练模型: 3.4 亿参数量
- Google Meena 开域聊天机器人:26 亿参数量
- Google T5 预训练模型:110 亿参数量
- OpenAI GPT3 语言模型:1750 亿参数量
- Google Switch Transformer 语言模型: 16000 亿参数量
- 快手精排排序模型:19000 亿参数量
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢